我们今天介绍一下神经网络中的归一化方法~
之前学到的机器学习中的归一化是将数据缩放到特定范围内,以消除不同特征之间的量纲和取值范围差异。通过将原始数据缩放到一个特定的范围内,比如[0,1]或者[-1,1],来消除不同特征之间的量纲和取值范围的差异。这样做的好处包括降低数据的量纲差异,避免某些特征由于数值过大而对模型产生不成比例的影响,以及防止梯度爆炸或过拟合等问题。
神经网络中的归一化用于加速和稳定学习过程,避免梯度问题。
神经网络的学习其实在学习数据的分布,随着网络的深度增加、网络复杂度增加,一般流经网络的数据都是一个 mini batch,每个 mini batch 之间的数据分布变化非常剧烈,这就使得网络参数频繁的进行大的调整以适应流经网络的不同分布的数据,给模型训练带来非常大的不稳定性,使得模型难以收敛。
如果我们对每一个 mini batch 的数据进行标准化之后,强制使输入分布保持稳定,从而可以加快网络的学习速度并提高模型的泛化能力。参数的梯度变化也变得稳定,有助于加快模型的收敛。
机器学习中的正则化分为L1和L2正则化,sklearn库中的Lasso类和Ridge类来实现L1正则化和L2正则化的线性回归模型。通过调整alpha参数,可以控制正则化的强度。
import numpy as np
from sklearn.linear_model import Lasso
from sklearn.datasets import make_regression
from sklearn.model_selection import train_test_split
from sklearn.metrics import mean_squared_error# 生成模拟数据集
X, y = make_regression(n_samples=100, n_features=2, noise=0.1)# 划分训练集和测试集
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)# 创建Lasso回归模型,并设置alpha参数为0.1(正则化强度)
lasso = Lasso(alpha=0.1)# 拟合模型
lasso.fit(X_train, y_train)# 预测测试集数据
y_pred = lasso.predict(X_test)# 计算均方误差
mse = mean_squared_error(y_test, y_pred)
print("Mean Squared Error:", mse)
Ridge回归模型,fit方法的作用是使用提供的输入特征矩阵X_train和对应的目标值y_train来训练模型,即确定模型的权重参数。这个过程涉及到最小化一个包含L2正则化项的损失函数,以找到最佳的参数值,使得模型在训练集上的表现最优,同时通过正则化避免过拟合。- 在模型拟合完成后,可以使用
predict方法来进行预测。这个方法将使用fit方法中学到的参数来对新的输入数据X_test进行预测,输出预测结果y_pred。因此,fit方法本身并不直接产生预测结果,而是为后续的预测准备了必要的模型参数。
批量归一化公式
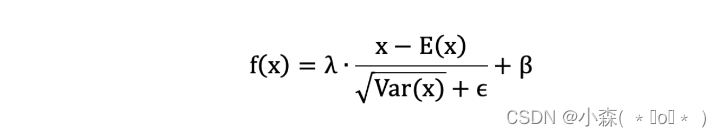
- λ 和 β 是可学习的参数,它相当于对标准化后的值做了一个线性变换,λ 为系数,β 为偏置;
- eps 通常指为 1e-5,避免分母为 0;
- E(x) 表示变量的均值;
- Var(x) 表示变量的方差;
通过批量归一化(Batch Normalization, 简称 BN)层之后,数据的分布会被调整为均值为β,标准差为γ的分布。
批量归一化通过对每个mini-batch数据进行标准化处理,强制使输入分布保持稳定:
- 计算该批次数据的均值和方差:这两个统计量是针对当前批次数据进行计算的。
- 利用这些统计数据对批次数据进行归一化处理:这一步将数据转换为一个近似以0为中心,标准差为1的正态分布。
- 尺度变换和偏移:为了保持网络的表达能力,通过可学习的参数γ(尺度因子)和β(平移因子)对归一化后的数据进行缩放和位移。
BN 层的接口
torch.nn.BatchNorm2d(num_features, eps=1e-05, momentum=0.1, affine=True)
-
num_features: 这是输入张量的特征数量,即通道数。它指定了要进行归一化的特征维度。 -
eps: 这是一个小的常数,用于防止除以零的情况。默认值为1e-05。 -
momentum: 这是动量值,用于计算移动平均值。默认值为0.1。 -
affine: 这是一个布尔值,表示是否启用可学习的缩放和位移参数。如果设置为True,则在训练过程中会学习这些参数;如果设置为False,则使用固定的缩放和位移参数。默认值为True。
我们通过一个代码案例来理解一下工作原理 :
import torch
import torch.nn as nn# 定义输入数据的形状
batch_size = 32
num_channels = 3
height = 64
width = 64# 创建输入张量
input_data = torch.randn(batch_size, num_channels, height, width)# 创建批量归一化层
bn_layer = nn.BatchNorm2d(num_features=num_channels, eps=1e-05, momentum=0.1, affine=True)# 将输入数据传入批量归一化层
output_data = bn_layer(input_data)# 打印输出数据的形状
print("Output shape:", output_data.shape)