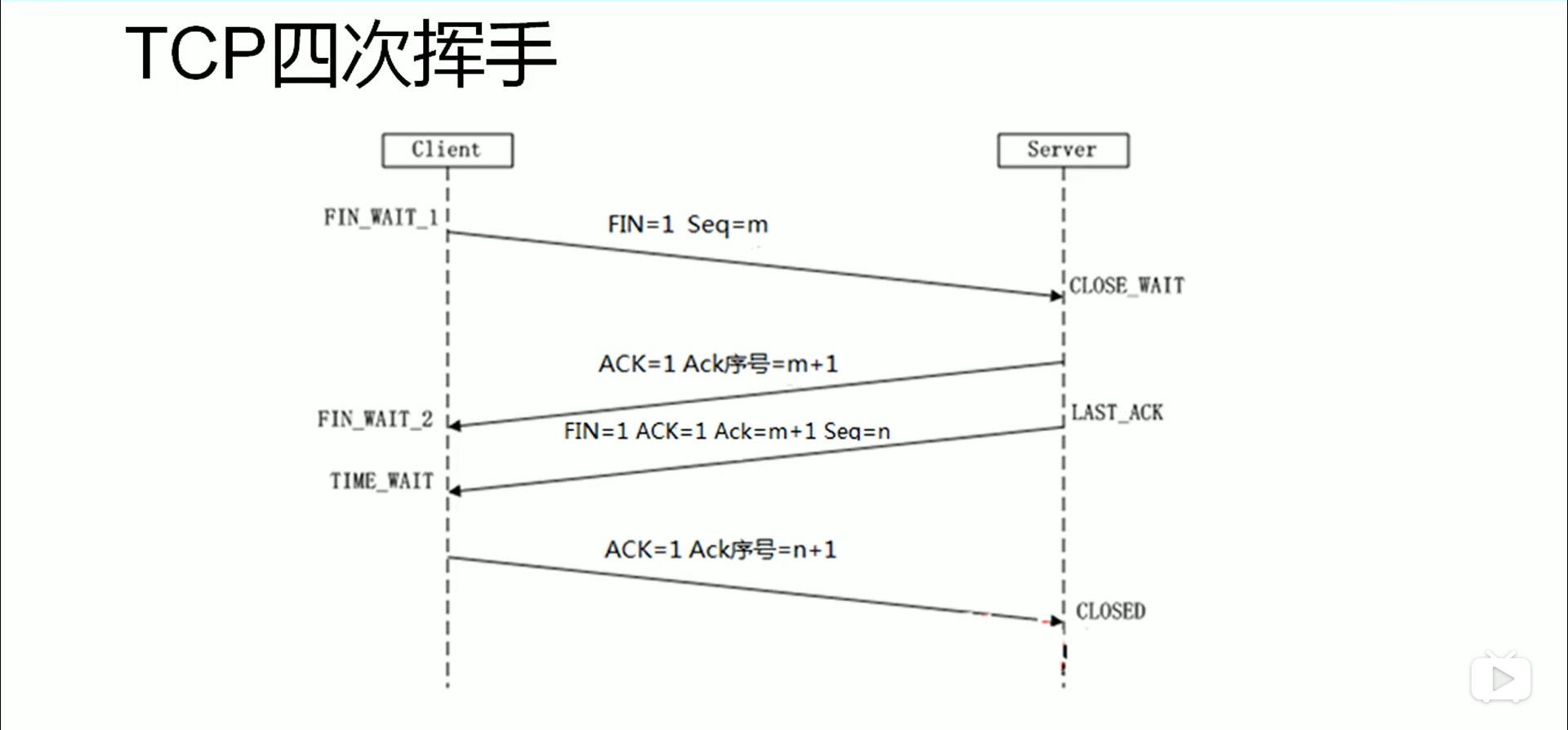
1、HDFS中名称节点的启动过程
- 名称节点在启动时,会将FsImage 的内容加载到内存当中,此时fsimage是上上次关机时的状态。
- 然后执行 EditLog 文件中的各项操作,使内存中的元数据保持最新。
- 接着创建一个新的FsImage 文件和一个空的 Editlog 文件,名称节点启动成功。
- 在运行过程中,HDFS 中的更新操作都会被写人 EditLog,而不是直接被写入Fslmage,所以在本次关机时,fsimage的内容仍是上次关机时的状态,只有下次开机时才会一步步执行editlog,更新fsimae为本次关机时的状态。
2、三级寻址
当要访问数据时,客户端首先在自己的缓存中查找是否有所需region的位置信息,若有则直接前往访问,若没有则三级寻址:首先访问 ZooKeeper,获取-ROOT表的所在Region服务器的位置信息,然后访的-ROOT-表,获得.META.表所在Region服务器的信息,接着访问.META.表,找到所需的 Region 具体位于哪个 Regio服务器,最后到该 Region 服务器读取数据。
**读写数据:
读:先在memstore查找,没有找到再去storefile查找
写:先写入memstore和hlog,memstore缓存满时才刷新写入磁盘
3、HLog的工作原理
- 每个region服务器配置了个HLog文件
- 写入:用户更新数据必须首先被记入HLog日志才能写入 MemStore 缓存。
- 刷新:直到 MemStore缓存内容对应的HLog日志已经被写入磁盘之后,该缓存内容才会被刷新写入磁盘。
- 故障:
- Master 主服务器首先会处理该故障 Region 服务器上面遗留的 HLog 文件
- 根据HLog每条日志记录所属的 Region 对象对 HLog 数据进行拆分
- 将失效的 Region与该 Region 对象相关的HLog日志记录重新分配到可用的 Regien 服务器中。
- Region服务器接收到region及与之相关的hlog日志后会重新做一遍日志记录中的操作,把日志记录中的数据写入MemStore缓存,然后刷新到磁盘的StoreFile 文件中,完成数据恢复。
4、NoSQL四大类型的特点及代表产品
都具有良好的可扩展性
- 键值数据库:使用key,value键值对存储,由key可以定位value,只可以通过键来进行查询。优点是大量写操作的性能好,缺点是条件查询效率低,无法存储结构化数据。可分为内存键值数据库和持久化键值数据库,代表产品redis就是一种内存键值数据库。
- 文档数据库:通过键来定位一个文档,不仅可以通过键来构建索引,也可以通过文档内容也就是值来构建索引,两个特点,一个是文档自描述,文档自身包含了其结构或模式的信息如xml,jason,html,第二个是文档自包含,文档自己包含了与其相关的所有信息,方便迁移。优点是复杂性低,灵活性高,缺点是缺乏统一的查询语言。MongoDB
- 列族数据库:以列族为单位进行存储,每行数据包含多个列族,优点是复杂性低,查找速度快,缺点是大多不支持强事务一致性。HBase,BigTable
- 图数据库:图作为数据模型来存储数据,处理高度相互关联的数据,有些甚至完全兼容ACID(原子性,一致性,隔离性,持久性)如代表产品Neo4J,优点是灵活,支持复杂图计算,缺点是复杂性高,只能支持一定的数据规模。
5、Map端的shuffle过程并画图展示
- 1. 输入数据(来自分布式文件系统)执行map任务,将输入的一个键值对转化为输出的多个键值对
- 将输出结果写入缓存
- 当缓存满时,启动溢写操作将缓存的数据写入磁盘,包含对键值对的分区(用哈希进行分区),排序(根据key进行排序),合并(可选的,将具有相同键的值加起来)
- 在map任务全部结束之前,将所有溢写文件进行归并(将具有相同键的值归在一起形成新的值),形成一个大的磁盘文件(本地),通知相应的reduce任务来领取属于自己分区的数据
6、Reduce端的shuffle过程并画图展示
- 从不同map机器领取回来所有属于自己分区的数据
- 对多个数据文件进行归并(如果缓存被占满也会像map端一样执行溢写,最终将所有溢写文件进行归并)
- 把数据输入给reduce任务
- 输出结果保存到分布式文件系统
7、Mapreduce的6个执行阶段

8、YARN体系结构中有哪些组件,各组件的功能
- ResourceManager,有两个组件,resourceschedule负责处理客户端请求、监控NodeManager、资源的分配与调度,applicationmanager负责applicationmaster的启动、监控、容错
- ApplicationManager,负责为应用程序申请资源并分配给内部map或reduce任务,负责任务的调度、监控、容错
- NodeManager,负责接收来自RM和AM的命令,负责单个节点上的资源管理
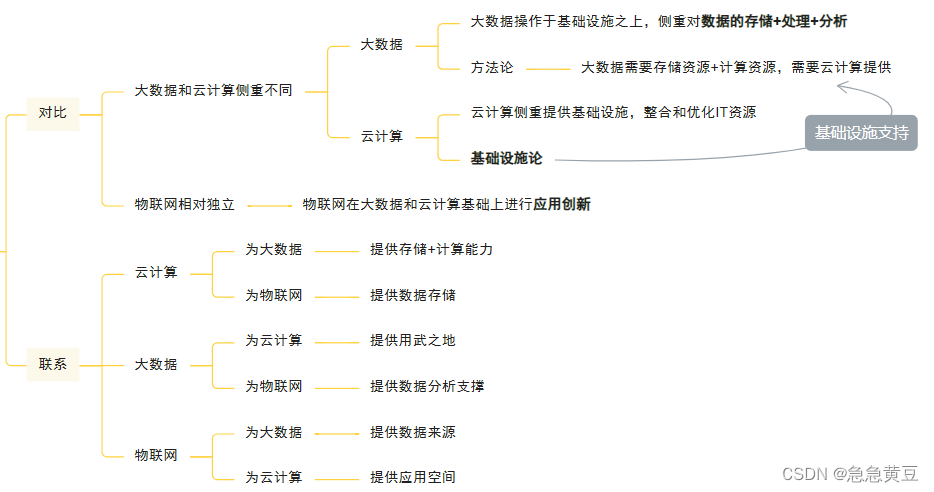
9、云计算、大数据、物联网三者的关系
10、HDFS HA实现原理
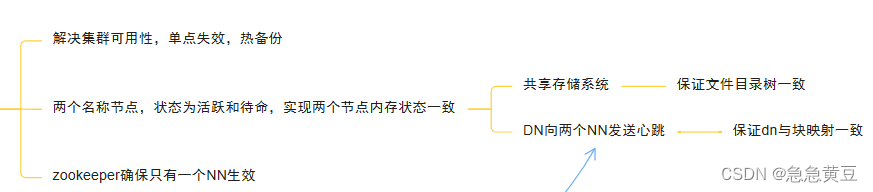
设置两个名称节点,其中一个名称节点处于“活跃”状态,另一个处于“待命”状态,在HDFS HA中,处于待命状态的名称节点提供“热备份”,也就是一旦活跃名称节点出现故障,就可以立即切换到待命名称节点,这需要两个NN内存状态一致。以下两点保证:1、借助共享存储系统,活跃NN将更新数据写入共享存储系统,待命NN一直监听该系统,一旦发现有新的写入,就立即读取这些数据并加载到自己的内存中。2、每个DN向向两个NN发送心跳,报告自己所存块的映射信息。另外ZooKeeper保证只有一个NN生效。
11、第二名称节点辅助名称节点进行fsimage和editlog合并过程
- 替换:每隔一段时间,第二名称节点会和名称节点通信,请求其停止使用 EdiLog 文件,暂时将新到达的写操作添加到一个新的文件 EditLog.new 中。
- 合并:第二名称节点把名称节点中的 Fslmage 文件和 EdiLog文件拉回本地,在内存中逐条执行EdiLog中的操作,使 Fslmage 保持最新。
- 发回:合并结束后,第二名称节点把新的 Fslmage文件发回给名称节点,名称节点用该新的FsImage替换旧的 Fslmage 文件,用 EditLog.new 文件去替换 Editog 文件,从而减小了 EditLog 文件的大小。
12、HDFS采用块block的方式来存储数据的优势有哪些?
- 支持大规模文件存储,不受单个节点容量限制
- 简化系统设计,块的大小固定简化存储管理,且元数据和文件块分开存储方便元数据管理
- 适合数据备份,每个文件块可以冗余存储到多个节点上,提高系统容错。
13、spark与hadoop对比

14、RDD运行过程简述

15、sparkstreaming和storm的对比

15、impala和hive的对比

16、hive、pig、hbase的对比
- pig是一种数据流语言,常作为ETL工具,将外部数据转换为用户需要的数据格式
- 再使用hive进行数据分析工作,生成bi报表。
- hbase数据实时访问,有自己的数据模式