一、vector和list
1.vector
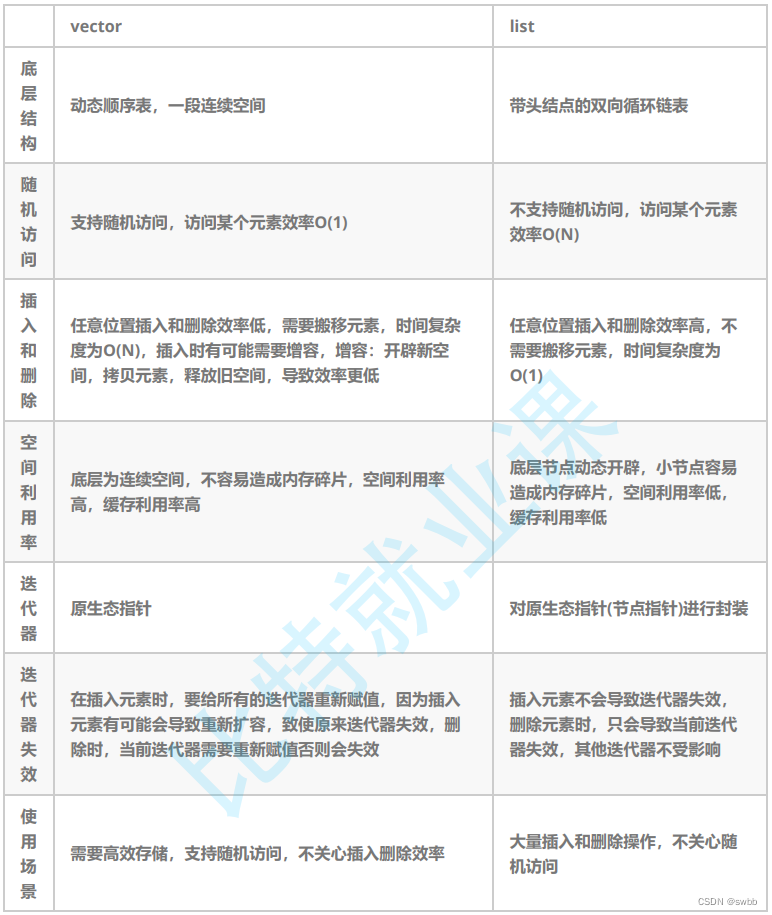
vector是可变大小数组的序列容器,拥有一段连续的内存空间,并且起始地址不变,因此能高效的进行随机存取,时间复杂度为o(1);但因为内存空间是连续的,所以在进行插入和删除操作时,会造成内存块的拷贝,时间复杂度为o(n)。
注:当数组中内存空间不够时,会重新申请一块内存空间并进行内存拷贝。vector使用动态分配数组来存储它的元素,当新元素插入时候,这个数组需要被重新分配大小,为了增加存储空间,其做法是,分配一个新的数组,然后将全部元素移到这个数组。就时间而言,这是一个相对代价高的任务,但是每当一个新的元素加入到容器的时候,vector并不会每次都重新分配大小。vector分配空间策略:vector会分配一些额外的空间以适应可能的增长(vs下capacity是按1.5倍增长的,g++是按2倍增长的),因为存储空间比实际需要的存储空间更大。
resize( ):改变vector的size
reserve( ):改变vector的capacity
vector 迭代器(随机访问迭代器)失效问题
迭代器的主要作用就是让算法能够不用关心底层数据结构,其底层实际就是一个指针,或者是对指针进行了封装,比如:vector的迭代器就是原生指针T* 。迭代器失效,实际就是迭代器底层对应指针所指向的空间被销毁了,而使用一块已经被释放的空间,造成的后果是程序崩溃(即如果继续使用已经失效的迭代器, 程序可能会崩溃)。
对于vector可能会导致其迭代器失效的操作有:
- 会引起其底层空间改变的操作,都有可能是迭代器失效,比如:resize、reserve、insert、assign、push_back等以上操作,都有可能会导致vector扩容,也就是说vector底层原理旧空间被释放掉, 而在打印时,it迭代器还使用的是释放之前的旧空间,在对it迭代器操作时,实际操作的是一块已经被释放的空间,而引起代码运行时崩溃。 解决方式:在以上操作完成之后,如果想要继续通过迭代器操作vector中的元素,只需给it重新赋值即可。
- 指定位置元素的删除操作erase,erase删除pos位置元素后,pos位置之后的元素会往前搬移,没有导致底层空间的改变,理论上讲迭代器应该不会失效,但是如果pos刚好是最后一个元素,删完之后pos刚好是end的位置,而end位置是没有元素的,那么pos就失效了。因此删除vector中任意位置上元素时,vs就认为该位置迭代器失效了。
- Linux(SGI)的STL中,迭代器失效后,代码并不一定会崩溃,但是运行结果肯定不对,如果it不在begin和end范围内,肯定会崩溃的。
2.list
list是由双向链表实现的,因此内存空间是不连续的,只能通过指针访问数据,所以list的随机存取的效率低,时间复杂度为o(n);但由于链表的特点,能高效地进行插入和删除,并且该容器可以前后双向迭代(begin与end为正向迭代器,对迭代器执行++操作,迭代器向后移动;rbegin()与rend()为反向迭代器,对迭代器执行++操作,迭代器向前移动)。list与forward_list非常相似:最主要的不同在于forward_list是单链表,只能前向迭代,使其更简单高效。
list迭代器(双向迭代器)失效问题
- 迭代器失效即迭代器所指向的节点的无效,即该节点被删除了。因为list的底层结构为带头结点的双向循环链表,因此在list中进行插入时是不会导致list的迭代器失效的,只有在删除时才会失效,并且失效的只是指向被删除节点的迭代器,其他迭代器不会受到影响。
list中有一个base node,此node并不存储数据,从C++11开始,此node中包含一个size_t类型的成员变量,用来记录list的长度。所以说从C++11开始,size()的时间复杂度是O(1),在此之前是O(N)。每个node都包含一个记录长度的成员变量吗?不是,GCC中的实现只有在header node上记录了长度信息,其它node并没有记录。
vector和list的区别
std::sort()和list成员函数sort()有什么区别吗?
std::sort()是STL算法的一部分,它排序的容器需要有随机访问迭代器,所以只能支持vector和deque。list成员函数sort()用于list排序,时间复杂度是O(N * logN)。
二、字节序、大端小端
字节序分类以及大端小端概念
字节序指字节在内存中存储的顺序。比如一个int32_t类型的数值占用4个字节,这4个字节在内存中的排列顺序就是字节序。
字节序有两种:
- 小端字节序/主机字节序(Little endinan),数值低位存储在内存的低地址,高位存储在内存的高地址;
- 大端字节序/网络字节序(Big endian),数值高位存储在内存的低地址,低位存储在内存的高地址。
记忆方式:网络的范围很大,所以大端是网络字节序。
采用大端方式进行数据存放符合人类的正常思维,而采用小端方式进行数据存放利于计算机处理。
如果将一个32位的整数0x12345678存放到一个整型变量(int)中,这个整型变量采用大端或者小端模式在内存中的存储由下表所示。为简单起见,使用OP0表示一个32位数据的最高字节MSB(Most Significant Byte),使用OP3表示一个32位数据最低字节LSB(Least Significant Byte)。
地址偏移 大端模式 小端模式
0x00 12(OP0) 78(OP3)
0x01 34(OP1) 56(OP2)
0x02 56(OP2) 34(OP1)
0x03 78(OP3) 12(OP0)
如何具体判断本机的主机字节序呢?参考如下代码:
//@ret:返回0小端字节序,返回1大端字节序
int dGetHostByteOrder()
{uint32_t a = 0x12345678; uint8_t *p = (uint8_t *)(&a); if(*p==0x78){return 0}else{return 1;}
}
网络字节序是TCP/IP中规定好的一种数据表示格式,它与具体的CPU类型、操作系统等无关,从而可以保证数据在不同主机之间传输时能够被正确解释。
网络字节序与主机字节序的相互转换
常用系统调用
Linux socket网络编程中,经常会使用下面四个C标准库函数进行字节序间的转换。
#include <arpa/inet.h>uint32_t htonl(uint32_t hostlong); //把uint32_t类型从主机序转换到网络序
uint16_t htons(uint16_t hostshort); //把uint16_t类型从主机序转换到网络序
uint32_t ntohl(uint32_t netlong); //把uint32_t类型从网络序转换到主机序
uint16_t ntohs(uint16_t netshort); //把uint16_t类型从网络序转换到主机序
三、socket 的阻塞模式和非阻塞模式
阻塞模式:当某个函数“执行成功的条件”当前不能满足时,该函数会阻塞当前执行线程,程序执行流在达到设定的超时时间或“执行成功的条件”满足后恢复继续执行。
非阻塞模式:即使某个函数的“执行成功的条件”当前不能满足,该函数也不会阻塞当前执行线程,而是立即返回,继续执行程序。
我们常讨论的具有不同行为表现的 socket 函数一般有如下几个:
- accept()在阻塞模式下,没有新连接时,线程会进入睡眠状态;非阻塞模式下,没有新连接时,立即返回WOULDBLOCK错误。
- connect在阻塞模式下,仅TCP连接建立成功或出错时才返回;非阻塞模式下,该函数会立即返回INPROCESS错误(需用select检测该连接是否建立成功)。
- send()/writre()
- recv()/read()
如何将 socket 设置成非阻塞模式
在 Linux 上,可以使用fcntl()函数给创建的 socket 增加O_NONBLOCK标志来将 socket 设置成非阻塞模式。
int oldSocketFlag = fcntl(sockfd, F_GETFL, 0);
int newSocketFlag = oldSocketFlag | O_NONBLOCK;
fcntl(sockfd, F_SETFL, newSocketFlag);当然,Linux 下的 socket() 创建函数也可以直接在创建时将 socket 设置为非阻塞模式
int socket(int domain, int type, int protocol);给 type 参数增加一个 SOCK_NONBLOCK 标志即可,例如:
int s = socket(AF_INET, SOCK_STREAM | SOCK_NONBLOCK, IPPROTO_TCP);send 和 recv 函数在阻塞和非阻塞模式下的行为
send 函数本质上并不是往网络上发送数据,而是将应用层发送缓冲区的数据拷贝到内核缓冲区中去,至于什么时候数据会从网卡缓冲区中真正地发到网络中去要根据 TCP/IP 协议栈的行为来确定。如果 socket 设置了 TCP_NODELAY 的选项(即禁用 nagel 算法),存放到内核缓冲区的数据会被立即发出去;反之,一次放入内核缓冲区的数据包如果太小,系统会在多个小的数据包凑成一个足够大的数据包后才会将数据发出去。
recv 函数本质上也并不是从网络上收取数据,而只是将内核缓冲区中的数据拷贝到应用程序的缓冲区中,当然拷贝完成以后会将内核缓冲区中该部分数据移除。
可以用下面一张图来描述上述事实:
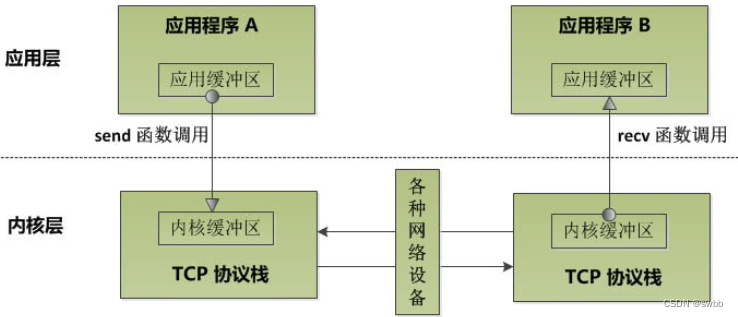
通过上图我们知道,不同的程序进行网络通信时,发送的一方会将内核缓冲区的数据通过网络传输给接收方的内核缓冲区。在应用程序 A 与 应用程序 B 建立了 TCP 连接之后,假设应用程序 A 不断调用 send 函数,这样数据会不断拷贝至对应的内核缓冲区中,如果 B 一直不调用 recv 函数,那么 B 的内核缓冲区被填满以后,A 的内核缓冲区也会被填满,此时 A 继续调用 send 函数会是什么结果呢? 具体的结果取决于该 socket 是否是阻塞模式。
- 当 socket 是阻塞模式的,继续调用 send/recv 函数会导致程序阻塞在 send/recv 调用处。
- 当 socket 是非阻塞模式,继续调用 send/recv 函数,send/recv 函数不会阻塞程序执行流,而是会立即出错返回,我们会得到一个相关的错误码,Linux 平台上该错误码为 EWOULDBLOCK 或 EAGAIN(这两个错误码值相同),Windows 平台上错误码为 WSAEWOULDBLOCK。
send 和 recv 函数的各种返回值意义:
| 返回值 n | 返回值含义 |
|---|---|
| 大于 0 | 成功发送(send)或收取(recv) n 个字节 |
| 0 | 对端关闭连接 |
| 小于 0( -1) | 出错或者被信号中断或者对端 TCP 窗口太小数据发不出去(send)或者当前网卡缓冲区已无数据可收(recv) |
阻塞的 socket 函数在调用 send、recv、connect、accept 等函数时,如果特定的条件不满足,就会阻塞其调用线程直至超时,非阻塞的 socket 恰恰相反。这并不意味着非阻塞模式比阻塞模式模式好,二者各有优缺点。
非阻塞模式一般用于需要支持高并发多的场景下(如服务器程序),但是正如前文所述,这种模式让程序执行流和控制逻辑变得复杂;相反,阻塞模式逻辑简单,程序结构简单明了,常用于一些特殊的场景,这里举两个可以使用阻塞模式的应用场景:
示例一
某程序需要临时发送一个文件,文件分段发送,每发送一段,对端都会给与一个响应,该程序可以单独开一个任务线程,在这个任务线程函数里面,使用先 send 后 recv 再 send 再 recv 的模式,每次 send 和 recv 都是阻塞式的。
示例二
A 端与 B 端之间的通信只有问答模式,即 A 每发送给 B 一个请求,B 必定会给 A 一个响应,除此以外,B 不会给 A 推送任何数据,此时 A 端就可以采用阻塞模式,A 端每次 send 完请求后,就可以直接使用阻塞式的 recv 函数去接收一定要有的应答包。






![[muduo网络库]——muduo库三大核心组件之 Poller/EpollPoller类(剖析muduo网络库核心部分、设计思想)](https://img-blog.csdnimg.cn/direct/c835e66dd7f3493e94b40369c641205e.png)