文章目录
- 一、背景介绍
- 二、模型介绍
- 2.1 模型结构
- 2.2 模型超参数
- 2.3 SwiGLU
- 三、代码分析
- 3.1 模型结构代码
- 3.2 FairScale库介绍
- 四、LLaMA家族模型
- 4.1 Alpaca
- 4.2 Vicuna
- 4.3 Koala(考拉)
- 4.4 Baize (白泽)
- 4.5 Luotuo (骆驼,Chinese)
- 4.6 其他
- 参考资料
LLaMA(Large Language Model Meta AI)模型,是由 Meta AI 发布的一个开放且高效的大型基础语言模型,
LLaMA-1 共有
7B、
13B、
33B、
65B(650 亿)四种版本。其数据集来源都是公开数据集,无任何定制数据集,保证了其工作与开源兼容和可复现,整个训练数据集在 token 化之后大约包含 1.4T 的 token。
关于模型性能,LLaMA 的性能非常优异:具有 130 亿参数的 LLaMA 模型「在大多数基准上」可以胜过 GPT-3( 参数量达 1750 亿),而且可以在单块 V100 GPU 上运行;而最大的 650 亿参数的 LLaMA 模型可以媲美谷歌的 Chinchilla-70B 和 PaLM-540B。
关于训练集,其来源都是公开数据集,无任何定制数据集,保证了其工作与开源兼容和可复现。整个训练数据集在 token 化之后大约包含 1.4T 的 token。其中,LLaMA-65B 和 LLaMA-33B 是在 1.4万亿个 token 上训练的,而最小的模型 LLaMA-7B 是在 1万亿个 token 上训练的。
一、背景介绍
Hoffmann 等人(2022)最近的工作表明了,在给定的计算预算下,最佳性能不是由最大的模型实现的,而是基于更多数据上的训练较小模型实现的。
和之前的工作相比,本论文的重点是 基于更多 tokens 的训练集,在各种推理预算下,训练出性能最佳的一系列语言模型,称为 LLaMA ,参数范围从 7B 到 65B 不等,与现有最佳 LLM 相比,其性能是有竞争力的。比如,LLaMA-13B 在大多数基准测试中优于 GPT-3,尽管其尺寸只有 GPT-3 的十分之一。作者相信,LLaMA 将有助于使 LLM 的使用和研究平民化,因为它可以在单个 GPU 上运行!在规模较大的情况下,LLaMA-65B 也具有与最佳大型语言模型(如 Chinchilla 或 PaLM-540B)相竞争的能力。
LLaMA 优势在于其只使用公开可用的数据,这可以保证论文的工作与开源兼容和可复现。 之前的大模型要么使用了不公开的数据集去训练从而达到了 state-of-the-art,如 Chinchilla、PaLM 或 GPT-3;要么使用了公开数据集,但模型效果不是最佳无法和 PaLM-62B 或 Chinchilla 相竞争,如 OPT、GPT-NeoX、BLOOM 和 GLM。
二、模型介绍
2.1 模型结构
主流的大语言模型都采用了Transformer架构,它是一个基于多层Self-attention的神经网络模型。
原始的Transformer由编码器(Encoder)和解码器(Decoder)两个部分构成,同时,这两个部分也可以独立使用。
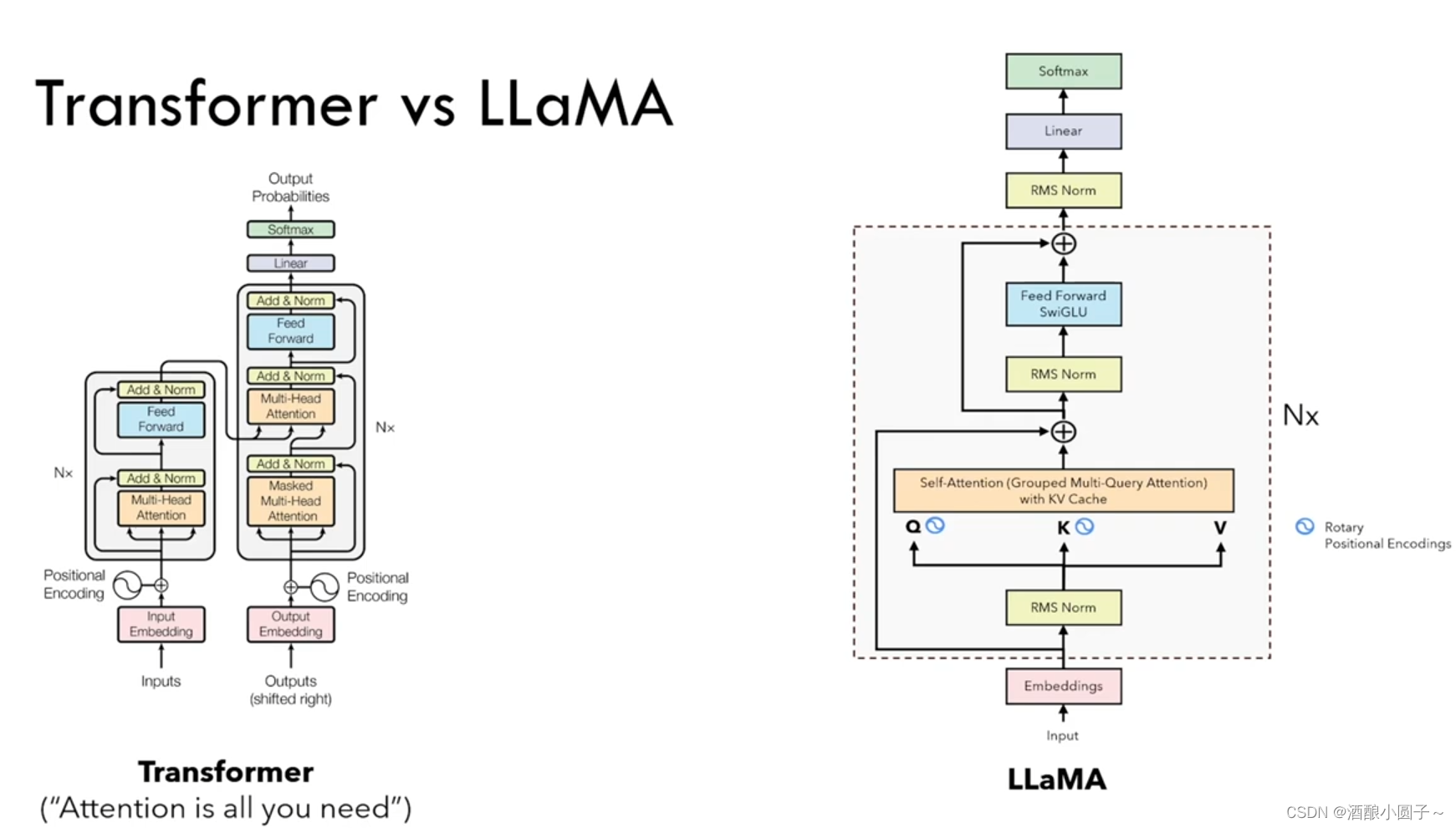
和 GPT 系列一样,LLaMA 模型也是 Decoder-only 架构,但结合前人的工作做了一些改进,比如:
- Pre-normalization [GPT3]。为了提高训练稳定性,LLaMA 对每个 transformer 子层的输入进行归一化,使用 RMSNorm 归一化函数,Pre-normalization 由Zhang和Sennrich(2019)引入。
- SwiGLU 激活函数 [PaLM]。将 ReLU 非线性替换为 SwiGLU 激活函数,且使用 2 / 3 ∗ 4 d 2/3 *4d 2/3∗4d 而不是 PaLM 论文中的 4d,SwiGLU 由 Shazeer(2020)引入以提高性能。
- Rotary Embeddings [GPTNeo]。模型的输入不再使用 positional embeddings,而是在网络的每一层添加了 positional embeddings (RoPE),RoPE 方法由Su等人(2021)引入。
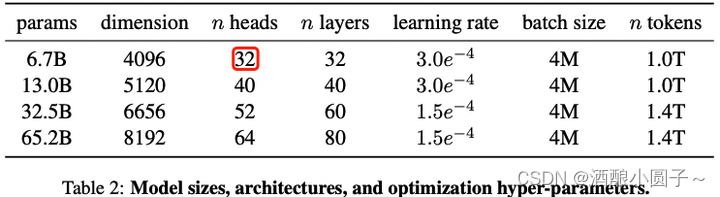
2.2 模型超参数
不同模型的超参数详细信息在下表中给出:
2.3 SwiGLU
Feed Forward 层全称是 Position-wise Feed-Forward Networks(FPN),FFN 接收一个向量 x(序列中特定位置的隐藏表示),并将其通过两个可学习的线性变换(由矩阵 W1 和 W2 以及偏置向量 b1 和 b2 表示)进行处理,在两个线性变换之间应用修正线性(ReLU)激活函数。计算过程用数学公式可表达为:
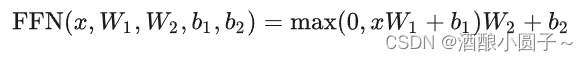
在 T5 模型的实现中,使用是没有偏置 bias 的版本,数学公式表达如下:
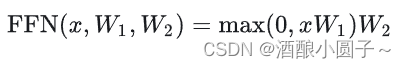
后续的研究提出了用其他非线性激活函数替换ReLU,如高斯误差线性单元 (Gaussian Error Linear Units):
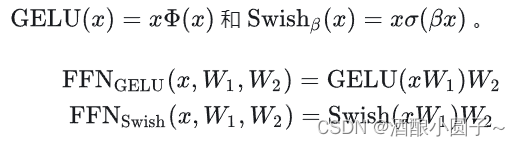
[Dauphin et al., 2016] 提出了门控线性单元(GLU),定义为输入的两个线性变换的逐元素乘积,其中一个经过了 sigmoid 激活。另外,他们还建议省略激活函数,称之为“双线性”(bilinear)层。
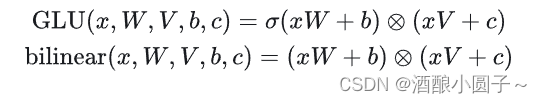
我们还可以使用其他激活函数定义 GLU 变体,如下所示:
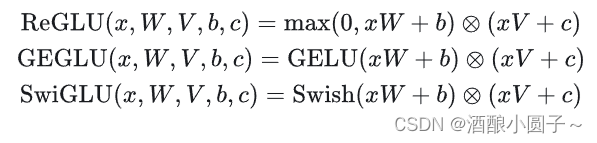
在本论文中,作者提出了 Transformer FFN 层的其他变体,这些变体使用 GLU 或其变体代替第一个线性变换和激活函数。同样也省略了偏差项。
SwiGLU 激活函数是 Gated Linear Units (GLU) 变体之一,来源于论文 GLU Variants Improve Transformer。SwiGLU 数学表达式如下:
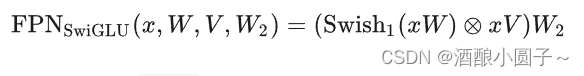
其中激活函数 Swish 的定义如下:

原始的的 FPN 层只有两个权重矩阵,但 F P N S w i G L U FPN_{SwiGLU} FPNSwiGLU 的线性变换层有三个权重矩阵。为了保持参数数量和计算量的恒定,需要将隐藏单元的数量 d_ff(W 和 V 的第二个维度以及 W2 的第一个维度)缩小 2/3。实现代码如下所示:
# -*- coding : utf-8 -*-import torch
import torch.nn as nn
import torch.nn.functional as Fclass FFNSwiGLU(nn.Module):def __init__(self, input_dim: int, hidden_dim: int):super().__init__()hidden_dim = int(2 * hidden_dim / 3)self.gate_proj = nn.Linear(input_dim, hidden_dim, bias=False)self.down_proj = nn.Linear(hidden_dim, input_dim, bias=False)self.up_proj = nn.Linear(input_dim, hidden_dim, bias=False) def forward(self, x):# LLaMA 官方提供的代码和模型默认是使用 F.silu() 激活函数,transformers 可通过配置指定return self.down_proj(F.silu(self.gate_proj(x)) * self.up_proj(x))layer = FFNSwiGLU(128, 256)
x = torch.randn(1, 128)
out = layer(x)
print(out.shape) # torch.Size([1, 128])
三、代码分析
- Github地址:https://github.com/meta-llama/llama
LLaMA 官方代码 只提供了模型结构和推理代码,没有提供模型训练代码。另外看了官方提供的下载脚本,是没有直接提供下载链接,是需要自己申请的!
3.1 模型结构代码
LLaMA 模型结构也只使用 Decoder 结构。
[等待更新]
3.2 FairScale库介绍
LLaMA 模型的线性计算层都是使用了 FairScale 库的 ColumnParallelLinear 层,它是一个并行的线性层,可以在多个 GPU 上并行计算,这个计算速度比 Linear 的 nn.Linear 层速度更快。
FairScale: 用于在一台或多台机器/节点上进行高性能和大规模训练的 PyTorch库,由 Meta 发布。示例代码:
from torch import nn
import fairscalemodel = nn.Sequential(nn.Conv2d(in_channels=3, out_channels=6, kernel_size=(5,5), stride=1, padding=0),nn.MaxPool2d(kernel_size=(2,2), stride=2, padding=0),nn.Conv2d(in_channels=6, out_channels=16, kernel_size=(5,5), stride=1, padding=0),nn.MaxPool2d(kernel_size=(2, 2), stride=2, padding=0),
)
model = fairscale.nn.Pipe(model, balance=[2, 2], devices=[0, 1], chunks=8)
在 2 个 GPU 上运行 4 层模型。前两层在 cuda:0 上运行,后两层在 cuda:1 上运行。
四、LLaMA家族模型
以下这些项目都是基于 LLaMA finetune 的模型,可以算是 Meta 发布的 LLaMA(羊驼)模型的子子孙孙。
4.1 Alpaca
- Github地址:https://github.com/ymcui/Chinese-LLaMA-Alpaca/
Alpaca 是斯坦福在 LLaMA 上对 52000 条指令跟随演示进行了精细调优的模型,是后续很多中文 LLM 的基础。
对应的中文版是 Chinese-LLaMA-Alpaca。该项目在原版 LLaMA 的基础上扩充了中文词表并使用了中文数据进行二次预训练,进一步提升了中文基础语义理解能力。同时,在中文LLaMA 的基础上,本项目使用了中文指令数据进行指令精调,显著提升了模型对指令的理解和执行能力。
值得注意的是,该项目开源的不是完整模型而是 LoRA 权重,理解为原 LLaMA 模型上的一个“补丁”,两者进行合并即可获得完整版权重。提醒:仓库中的中文 LLaMA/Alpaca LoRA 模型无法单独使用,需要搭配原版 LLaMA 模型[1]。可以参考本项目给出的合并模型步骤重构模型。
4.2 Vicuna
Vicuna 是一款从 LLaMA 模型中对用户分享的对话进行了精细调优的聊天助手,根据的评估,这款聊天助手在 LLaMA 子孙模型中表现最佳,能达到 ChatGPT 90% 的效果。
4.3 Koala(考拉)
一款从 LLaMA 模型中对用户分享的对话和开源数据集进行了精细调优的聊天机器人,其表现与Vicuna 类似。
- blog: Koala: A Dialogue Model for Academic Research
- demo: FastChat
- Github地址: https://github.com/young-geng/EasyLM
4.4 Baize (白泽)
- 论文:https://arxiv.org/pdf/2304.01196.pdf
- demo: Baize Lora 7B - a Hugging Face Space by project-baize
- Github地址: https://github.com/project-baiz
4.5 Luotuo (骆驼,Chinese)
- Github地址: https://github.com/LC1332/Luotuo-Chinese-LLM
4.6 其他
另外,中文 LLM 的有影响力的模型还有 ChatGLM,通常指 ChatGLM-6B, 一个由清华团队开源的、支持中英双语的对话语言模型,基于 General Language Model (GLM) 架构,具有 62 亿参数。结合模型量化技术,用户可以在消费级的显卡上进行本地部署 ChatGLM(INT4 量化级别下最低只需 6GB 显存)。
整体使用下来,其基本任务没问题,但是涌现能力还是有限的,且会有事实性/数学逻辑错误,另外,Close QA 问题也很一般。GLM 模型架构与 BERT、T5 等预训练模型模型架构不同,它采用了一种自回归的空白填充方法,。
参考资料
- LLaMA及其子孙模型概述