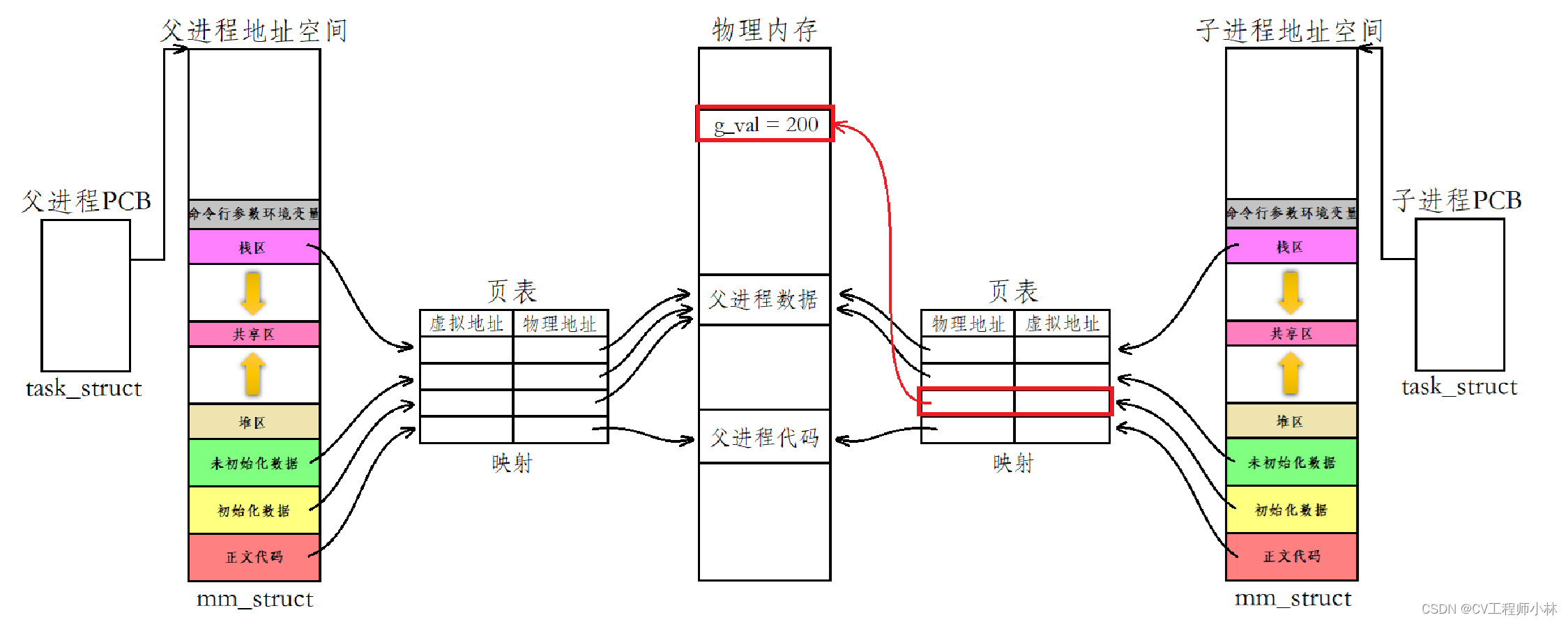
1. 引言
说到数据可视化,Seaborn就像一颗隐藏的宝石!在进行探索性数据分析时,我们通常从Matplotlib 开始,而对 Seaborn 的探索相对较少!但是,只要你了解 Seaborn 的全部潜力,你就会惊奇地发现,我们可以在数据中探索出更多有趣的东西。
闲话少说,我们直接开始吧!
2. 安装
在深入学习示例之前,让我们先确保Seaborn已安装。如果尚未安装,请使用以下命令:
pip install seaborn
现在我们已经安装了Seaborn,让我们通过一系列高级 Python 代码示例来探索它的用法。
3. 简单直方图
首先,让我们创建一个简单的数据分布直方图:
import seaborn as sns
import matplotlib.pyplot as plt# Load the "tips" dataset
tips = sns.load_dataset("tips")
print(tips.head())
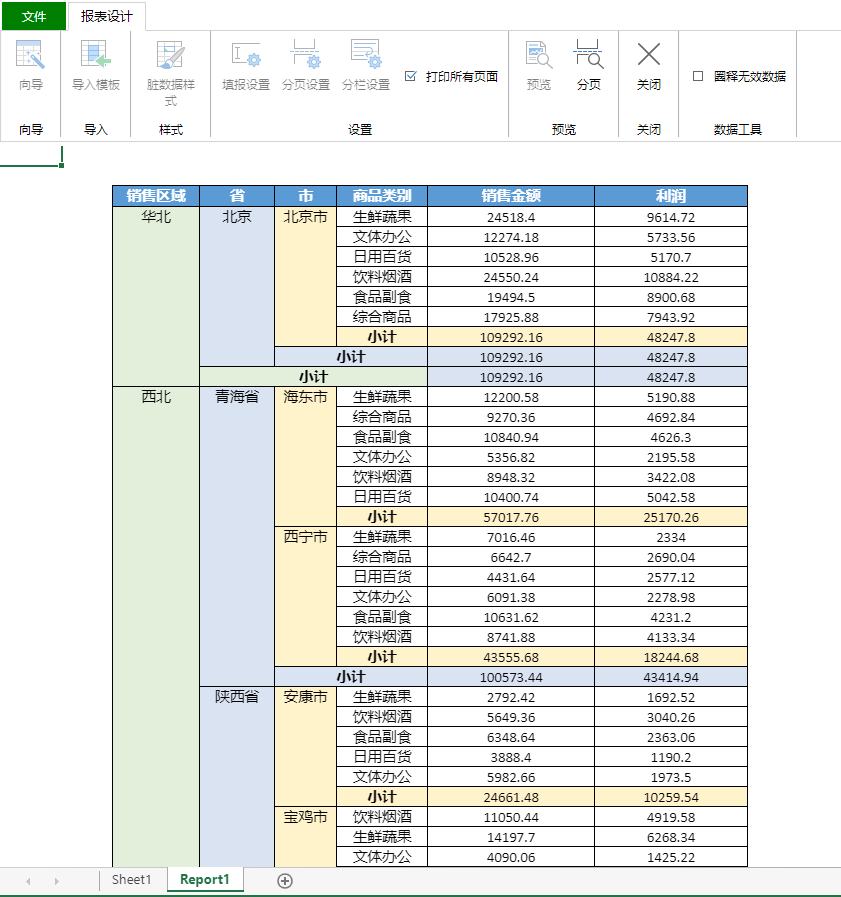
# Count Plot
plt.figure(figsize=(8, 5))
sns.countplot(x="day", data=tips, palette="Set3")
plt.title("Count of Tips by Day of the Week")
plt.show()
运行后得到如下:


本示例使用函数countplot创建一个简单的直方图。小费数据集是关于人们在餐厅中给出的小费,首先展示了数据集中的前五行的样例数据,接着进行了直方图的绘制。通过上述直方图,可以观察人们付小费的次数随工作日变化的计数图。
4. 分簇散点图
分簇散点图Swarm Plot 通常在 x 轴上显示分类变量,在y轴上显示数值变量,并沿着每个类别显示单个数据点。现在,正如你所猜测的那样,这可以让我们直观地看到类别内数据点的分布和密度。
我们来看个示例如下:
import seaborn as sns
import matplotlib.pyplot as plt
# Load the "tips" dataset
tips = sns.load_dataset("tips")
# Swarm Plot
plt.figure(figsize=(8, 5))
sns.swarmplot(x="day", y="total_bill", data=tips, palette="viridis")
plt.title("Total Bill Distribution by Day of the Week")
plt.xlabel("Day of the Week")
plt.ylabel("Total Bill ($)")
plt.show()
运行后得到结果如下:

在本例中,我们使用 swarmplot 创建了一个分簇散点图。通过该图,有助于了解数据点的密度,因为它们能清楚地显示数据点的集中和稀疏位置。
5. 点阵图
点阵图Point Plot通常在 x 轴上显示分类变量,在 y 轴上显示数值变量,可以深入了解每类数据的分布和中心点倾向。
绘制点阵图的示例代码如下:
import seaborn as sns
import matplotlib.pyplot as plt
# Load the "tips" dataset
tips = sns.load_dataset("tips")
# Point Plot
plt.figure(figsize=(8, 5))
sns.pointplot(x="day", y="total_bill", data=tips, ci="sd", palette="pastel")
plt.title("Average Total Bill by Day of the Week")
plt.xlabel("Day of the Week")
plt.ylabel("Average Total Bill ($)")
plt.show()
运行后得到结果如下:

在上述代码中,这条线或每个点代表每个类别中数值变量的平均值或中值。因此,使用它可以快速直观地查看不同类别的平均值或中值是否存在明星差异。
6. 小提琴图
分类变量通常控制组或类别,而数值变量则用于在每个类别中创建小提琴图。小提琴图中某一点的宽度表示该值所在数据点的密度,小提琴图的中心部分就像一把小提琴,因此被称为小提琴图。通常使用函数 sns.violinplot 绘制小提琴图。
我们不妨来看个示例如下:
import seaborn as sns
import matplotlib.pyplot as plt
# Load the "tips" dataset
tips = sns.load_dataset("tips")
# Categorical Violin Plot
plt.figure(figsize=(8, 5))
sns.violinplot(x="day", y="total_bill", data=tips, palette="Set2")
plt.title("Total Bill Distribution by Day of the Week")
plt.xlabel("Day of the Week")
plt.ylabel("Total Bill ($)")
plt.show()
运行后,得到结果如下:

小提琴图是比较不同类别数字数据分布的有效工具。通过它,大家不仅可以看到分布的中心倾向和分布范围,还可以看到分布的形状和密度。
7. 二维变量回归图
回归图(Regression Plot)的重点是突出两个数字变量之间的关系:自变量(通常在x轴上)和因变量(在 y 轴上)。单个数据点以点的形式显示,回归图的中心元素是回归线或曲线,它代表了描述变量之间关系的最佳拟合数学模型。
我们来看个示例:
import seaborn as sns
import matplotlib.pyplot as plt
# Load the "tips" dataset
tips = sns.load_dataset("tips")
# Regression Plot
plt.figure(figsize=(8, 5))
sns.regplot(x="total_bill", y="tip", data=tips, scatter_kws={"color": "blue"}, line_kws={"color": "red"})
plt.title("Regression Plot of Total Bill vs. Tip")
plt.xlabel("Total Bill ($)")
plt.ylabel("Tip ($)")
plt.show()
运行后,得到结果如下:

上图中,绘制的回归线表示根据账单总额预测小费的最佳拟合线性模型。散点表示单个数据点,我们可以观察到这些数据点是如何聚集在回归线周围的。该图有助于了解这两个变量之间的线性关系。
8. 联合分布图
联合分布图(Joint Plot)结合了散点图、直方图和密度图来直观显示两个数值变量之间的关系。散点图是联合图的核心元素,它将两个变量的数据点相对应地显示出来,沿着散点图的x轴和 y 轴,每个变量都有直方图或核密度估计图。这些边际图分别显示每个变量的分布情况。
我们来看个示例:
import seaborn as sns
import matplotlib.pyplot as plt
# Load the "tips" dataset
tips = sns.load_dataset("tips")
# Joint Plot
sns.jointplot(x="total_bill", y="tip", data=tips, kind="scatter")
plt.show()
运行后,得到结果如下:

我们可以看到,通过散点图显示了两个变量之间的关系,而边际直方图则分别显示了每个变量的分布情况。
9. 六边形图
六边形图(Hexbin plot)是六边形分隔图的简称,它将数据点分组到六边形箱中,使大家能够更有效地直观显示数据密度和模式。当单个点的散点图变得过于拥挤且难以解读时,六边形分隔图对于这类大型数据集尤为重要!
在Seaborn中,我们可以自定义颜色图、网格大小和其他绘图参数,以微调六边形绘图的外观。绘制六边形图的示例代码如下:
import seaborn as sns
import matplotlib.pyplot as plt
# Load the "tips" dataset
tips = sns.load_dataset("tips")
# Hexbin Plot
plt.figure(figsize=(8, 5))
sns.jointplot(x="total_bill", y="tip",kind='hex', data=tips, gridsize=15, cmap="Blues")
plt.title("Hexbin Plot of Total Bill vs. Tip")
plt.xlabel("Total Bill ($)")
plt.ylabel("Tip ($)")
plt.show()
运行后得到结果如下:

在这里,对于大型数据集而言,六边形图比简单的散点图更加清晰。图中的每个六边形都用颜色标注,以表示该分区中数据点的密度。
10. 关系图
通过关系图,大家可以直观地看到两个数值变量之间的关系,以及其他分类或数值维度。一般使用函数sns.relplot()进行绘制,大家可以使用色调参数根据分类变量为数据点着色,使用大小参数根据数值变量改变标记大小,使用样式参数根据分类变量区分标记或线条。
我们来看个例子,如下:
import seaborn as sns
import matplotlib.pyplot as plt
# Load the "tips" dataset
tips = sns.load_dataset("tips")# Create a scatterplot using a Relational Plot (relplot)
sns.relplot(x="total_bill", y="tip", data=tips, hue="time", style="sex", size="size", palette="Set1", height=6)
plt.title("Relational Scatter Plot for Tips Dataset")
plt.xlabel("Total Bill ($)")
plt.ylabel("Tip ($)")
plt.savefig('relplot_with_mv.png')
plt.show()
运行后得到结果如下:

在本例中,数据集中的time列用于使用色调参数对数据点着色,size列用于使用大小参数改变不同的尺寸,sex列用于不同的标记参数。
11. 面网格图
面网格图是Seaborn的一项功能,它允许大家创建一个子网格,每个子网格代表数据集中的一个不同子集。通过这种方式,面网格图可用于比较不同类别中多个变量之间的关系。
一般来说,使用函数sns.FacetGrid() 来创建面网格图,并返回网格对象。创建网格对象后,我们需要将其映射到我们选择的任何绘图中。
示例代码如下:
import seaborn as sns
import matplotlib.pyplot as plt
# Load the "tips" dataset
tips = sns.load_dataset("tips")
# Create a Facet Grid of histograms for different days
g = sns.FacetGrid(tips, col="day", height=4, aspect=1.2)
g.map(sns.histplot, "total_bill", kde=True)
g.set_axis_labels("Total Bill ($)", "Frequency")
g.set_titles(col_template="{col_name} Day")
plt.savefig('facet_grid_hist_plot.png')
plt.show()
运行后得到结果如下:

12. 配对图
配对图(Pair Plot)提供了一个由散点图和直方图组成的网格,其中每个图都显示了两个变量之间的关系,因此也被称为配对图或散点图矩阵。
绘制配对图的示例代码如下:
import seaborn as sns
import matplotlib.pyplot as plt
# Load the "iris" dataset
iris = sns.load_dataset("iris")# Pair Plot
sns.set(style="ticks")
sns.pairplot(iris, hue="species", markers=["o", "s", "D"])
plt.show()
运行后得到结果如下:

在配对图中,对角线单元格通常显示单个变量的直方图或核密度分布图。网格中的非对角线单元格通常显示为散点图,表示两个变量之间的关系。配对图对于了解数据中多个维度的模式、相关性和分布特别有用。
13. 总结
Seaborn是一个通用且功能强大的 Python 数据可视化库。本文介绍了一系列高级示例,展示了各种绘图类型。请尝试使用所提供的代码示例,深入了解 Seaborn的功能,提高大家数据可视化的技能。
您学废了嘛?