文章目录
- 模型文件下载
- 训练模型
- 准备数据
- 转化成 doc_bin 格式
- 模型训练配置
- 生成初始配置
- 补全完整配置
- 开始训练
- 测试模型
- 参考文献
模型文件下载
https://github.com/explosion/spacy-models/releases?q=zh&expanded=true

简单测试一下ner效果,发现根本不能用

训练模型
准备数据
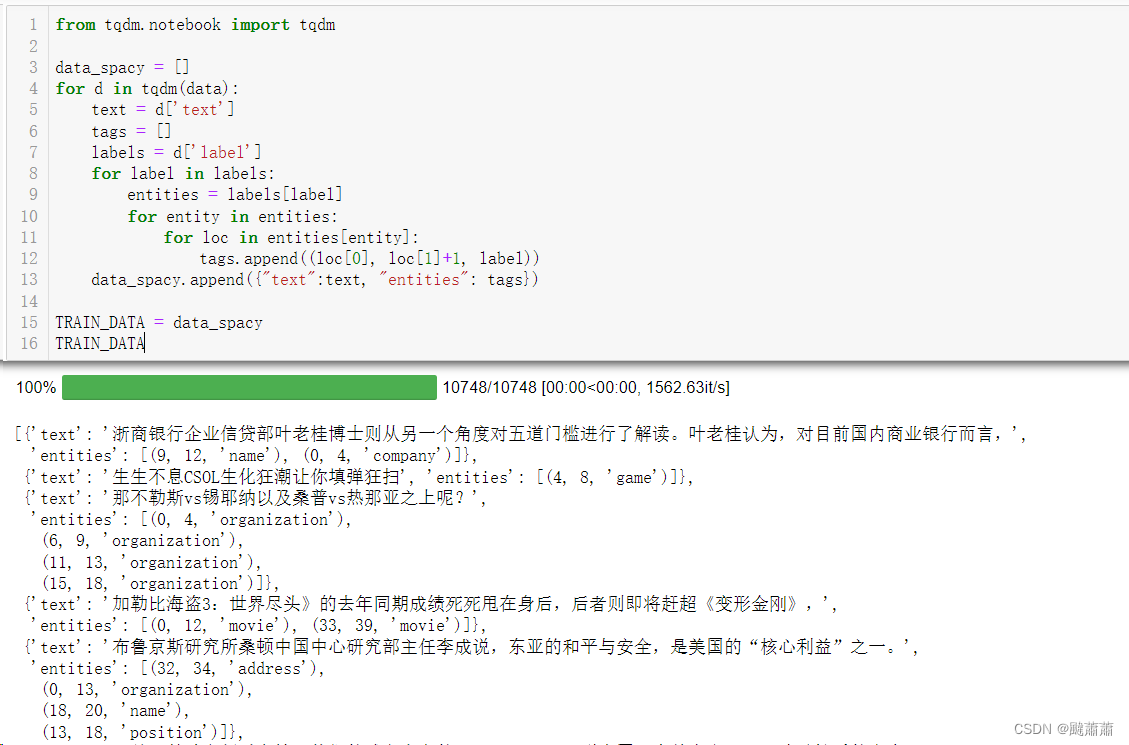
转化成 doc_bin 格式
from spacy.tokens import DocBin
from tqdm import tqdm
from spacy.util import filter_spansnlp = spacy.blank('zh') # 选择中文空白模型
doc_bin = DocBin()
for training_example in tqdm(TRAIN_DATA):text = training_example['text']labels = training_example['entities']doc = nlp.make_doc(text)ents = []for start, end, label in labels:span = doc.char_span(start, end, label=label, alignment_mode="contract")if span is None:print("Skipping entity")else:ents.append(span)filtered_ents = filter_spans(ents)doc.ents = filtered_entsdoc_bin.add(doc)doc_bin.to_disk("train.spacy")
train.spacy 和 dev.spacy 分别用来训练和测试
模型训练配置
生成初始配置
模型配置文件不用自己写,直接到官网上点击配置:https://spacy.io/usage/training#quickstart

通过简单勾选,得到一个初始配置文件 base_config.cfg
# This is an auto-generated partial config. To use it with 'spacy train'
# you can run spacy init fill-config to auto-fill all default settings:
# python -m spacy init fill-config ./base_config.cfg ./config.cfg
[paths]
train = null
dev = null
vectors = "zh_core_web_lg"
[system]
gpu_allocator = null[nlp]
lang = "zh"
pipeline = ["tok2vec","ner"]
batch_size = 1000[components][components.tok2vec]
factory = "tok2vec"[components.tok2vec.model]
@architectures = "spacy.Tok2Vec.v2"[components.tok2vec.model.embed]
@architectures = "spacy.MultiHashEmbed.v2"
width = ${components.tok2vec.model.encode.width}
attrs = ["NORM", "PREFIX", "SUFFIX", "SHAPE"]
rows = [5000, 1000, 2500, 2500]
include_static_vectors = true[components.tok2vec.model.encode]
@architectures = "spacy.MaxoutWindowEncoder.v2"
width = 256
depth = 8
window_size = 1
maxout_pieces = 3[components.ner]
factory = "ner"[components.ner.model]
@architectures = "spacy.TransitionBasedParser.v2"
state_type = "ner"
extra_state_tokens = false
hidden_width = 64
maxout_pieces = 2
use_upper = true
nO = null[components.ner.model.tok2vec]
@architectures = "spacy.Tok2VecListener.v1"
width = ${components.tok2vec.model.encode.width}[corpora][corpora.train]
@readers = "spacy.Corpus.v1"
path = ${paths.train}
max_length = 0[corpora.dev]
@readers = "spacy.Corpus.v1"
path = ${paths.dev}
max_length = 0[training]
dev_corpus = "corpora.dev"
train_corpus = "corpora.train"[training.optimizer]
@optimizers = "Adam.v1"[training.batcher]
@batchers = "spacy.batch_by_words.v1"
discard_oversize = false
tolerance = 0.2[training.batcher.size]
@schedules = "compounding.v1"
start = 100
stop = 1000
compound = 1.001[initialize]
vectors = ${paths.vectors}
补全完整配置
接下来,需要用命令 spacy init fill-config [初始配置] [完整配置] 把上述初始配置补全为完整的训练配置
python -m spacy init fill-config spacy/base_config.cfg spacy/config.cfg
得到 config.cfg 文件如下,其中做了一些人工改动,例如 paths.vectors 默认选的是 zh_core_web_lg,我改成了 zh_core_web_md
[paths]
train = null
dev = null
vectors = "zh_core_web_md"
init_tok2vec = null[system]
gpu_allocator = null
seed = 0[nlp]
lang = "zh"
pipeline = ["tok2vec","ner"]
batch_size = 1000
disabled = []
before_creation = null
after_creation = null
after_pipeline_creation = null
vectors = {"@vectors":"spacy.Vectors.v1"}[nlp.tokenizer]
@tokenizers = "spacy.zh.ChineseTokenizer"
segmenter = "char"[components][components.ner]
factory = "ner"
incorrect_spans_key = null
moves = null
scorer = {"@scorers":"spacy.ner_scorer.v1"}
update_with_oracle_cut_size = 100[components.ner.model]
@architectures = "spacy.TransitionBasedParser.v2"
state_type = "ner"
extra_state_tokens = false
hidden_width = 64
maxout_pieces = 2
use_upper = true
nO = null[components.ner.model.tok2vec]
@architectures = "spacy.Tok2VecListener.v1"
width = ${components.tok2vec.model.encode.width}
upstream = "*"[components.tok2vec]
factory = "tok2vec"[components.tok2vec.model]
@architectures = "spacy.Tok2Vec.v2"[components.tok2vec.model.embed]
@architectures = "spacy.MultiHashEmbed.v2"
width = ${components.tok2vec.model.encode.width}
attrs = ["NORM","PREFIX","SUFFIX","SHAPE"]
rows = [5000,1000,2500,2500]
include_static_vectors = true[components.tok2vec.model.encode]
@architectures = "spacy.MaxoutWindowEncoder.v2"
width = 256
depth = 8
window_size = 1
maxout_pieces = 3[corpora][corpora.dev]
@readers = "spacy.Corpus.v1"
path = ${paths.dev}
max_length = 0
gold_preproc = false
limit = 0
augmenter = null[corpora.train]
@readers = "spacy.Corpus.v1"
path = ${paths.train}
max_length = 0
gold_preproc = false
limit = 0
augmenter = null[training]
dev_corpus = "corpora.dev"
train_corpus = "corpora.train"
seed = ${system.seed}
gpu_allocator = ${system.gpu_allocator}
dropout = 0.1
accumulate_gradient = 1
patience = 1600
max_epochs = 0
max_steps = 20000
eval_frequency = 200
frozen_components = []
annotating_components = []
before_to_disk = null
before_update = null[training.batcher]
@batchers = "spacy.batch_by_words.v1"
discard_oversize = false
tolerance = 0.2
get_length = null[training.batcher.size]
@schedules = "compounding.v1"
start = 100
stop = 1000
compound = 1.001
t = 0.0[training.logger]
@loggers = "spacy.ConsoleLogger.v1"
progress_bar = false[training.optimizer]
@optimizers = "Adam.v1"
beta1 = 0.9
beta2 = 0.999
L2_is_weight_decay = true
L2 = 0.01
grad_clip = 1.0
use_averages = false
eps = 0.00000001
learn_rate = 0.001[training.score_weights]
ents_f = 1.0
ents_p = 0.0
ents_r = 0.0
ents_per_type = null[pretraining][initialize]
vectors = ${paths.vectors}
init_tok2vec = ${paths.init_tok2vec}
vocab_data = null
lookups = null
before_init = null
after_init = null[initialize.components][initialize.tokenizer]
pkuseg_model = null
pkuseg_user_dict = "default"
开始训练
python -m spacy train spacy/config.cfg --output ./spacy/ --paths.train ./train.spacy --paths.dev ./dev.spacy
参数:
- output 输出目录
- paths.train 训练集文件
- paths.dev 验证集文件
训练日志:
>>> python -m spacy train spacy/config.cfg --output ./spacy/ --paths.train ./train.spacy --paths.dev ./dev.spacy
ℹ Saving to output directory: spacy
ℹ Using CPU
ℹ To switch to GPU 0, use the option: --gpu-id 0=========================== Initializing pipeline ===========================
✔ Initialized pipeline============================= Training pipeline =============================
ℹ Pipeline: ['tok2vec', 'ner']
ℹ Initial learn rate: 0.001
E # LOSS TOK2VEC LOSS NER ENTS_F ENTS_P ENTS_R SCORE
--- ------ ------------ -------- ------ ------ ------ ------0 0 0.00 49.29 0.00 0.00 0.00 0.000 200 609.43 3515.82 6.61 7.99 5.63 0.070 400 1104.85 3590.05 10.22 10.26 10.19 0.100 600 1120.82 5038.80 16.23 17.95 14.81 0.160 800 1071.70 5578.76 10.95 14.11 8.95 0.110 1000 1151.26 6506.03 20.62 23.73 18.23 0.210 1200 1100.93 6840.94 26.60 32.95 22.30 0.270 1400 2058.58 7959.36 34.93 39.60 31.25 0.350 1600 1642.29 9632.10 40.32 45.09 36.46 0.401 1800 2580.55 11209.10 38.82 47.18 32.98 0.391 2000 2907.86 13187.84 44.31 52.42 38.38 0.441 2200 3575.63 15214.04 42.97 50.06 37.63 0.432 2400 4790.03 18126.32 48.39 51.29 45.80 0.482 2600 5653.69 17209.21 51.27 54.42 48.47 0.51
测试模型
nlp = spacy.load("spacy/model-best")
text = "我的名字是michal johnson,我的手机号是13425456344,我家住在东北松花江上8幢8单元6楼5号房。我叫王大,喜欢去旺角餐厅吃牛角包, 今年买了阿里巴巴的股票,我家住在新洲花园3栋4单元 8988-1室"
doc = nlp(text)for ent in doc.ents:print({"start": ent.start,"end": ent.end,"text": ent.text,"entity_group": ent.label_,})

参考文献
- https://ubiai.tools/fine-tuning-spacy-models-customizing-named-entity-recognition/
- https://spacy.io/usage/training
- https://ner.pythonhumanities.com/03_02_train_spacy_ner_model.html







![[单机]完美国际_V155_GM工具_VM虚拟机](https://img-blog.csdnimg.cn/img_convert/55d11bea6d96a129f7a0c2dcb8bb4ca9.webp?x-oss-process=image/format,png)