引言
今天带来论文Corrective Retrieval Augmented Generation的笔记,这是一篇优化RAG的工作。
大型语言模型(LLMs) inevitable(不可避免)会出现幻觉,因为生成的文本的准确性不能仅仅由其参数化知识来确保。尽管检索增强生成(RAG)是LLMs的一个可行补充,但它严重依赖于检索文档的相关性,这引发了如果检索出现问题模型会如何行为的担忧。
作者提出了纠正式检索增强生成(CRAG)来提高生成的鲁棒性。具体来说,设计了一个轻量级的检索评估器,用于评估针对查询的检索文档的整体质量,根据返回的置信度程度来触发不同的知识检索操作。由于从固定和有限的语料库中检索只能返回次优的文档,因此利用大规模网络搜索作为扩展来增强检索结果。此外,还设计了一个分解-重组算法,用于对检索文档进行选择性关注关键信息并过滤掉其中的无关信息。CRAG是即插即用的,可以与各种基于RAG的方法无缝耦合。
总体介绍
先前的研究引入了检索技术来整合相关知识并增强生成,例如检索增强生成(RAG)。在这个框架中,模型的输入通过在外部知识语料库中检索到的相关文档被前置以增强(RAG)。虽然RAG作为LLMs的一个可行补充,但其有效性取决于检索文档的相关性和准确性。
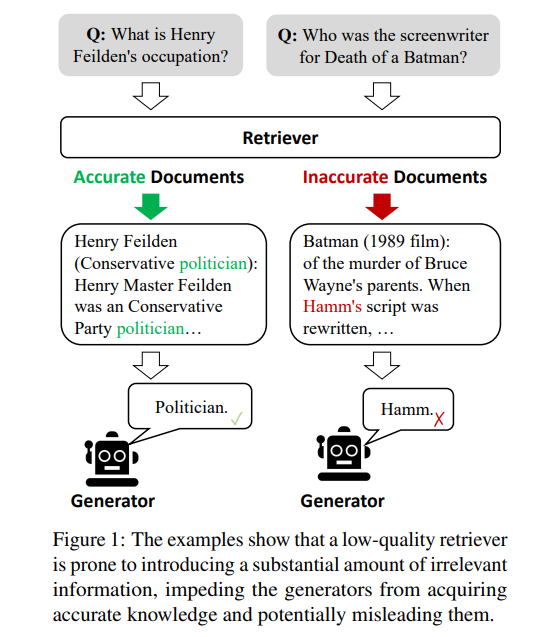
生成对检索知识的严重依赖引发了关于模型在检索失败或返回不准确结果的情况下的行为和表现的重大担忧。如图1所示,低质量的检索器容易引入大量无关信息,阻碍模型获取准确知识,可能误导其产生幻觉。然而,大多数传统的RAG方法都会不加区别地整合检索到的文档,无论这些文档是否相关。此外,当前方法大多将完整文档视为参考知识,在检索和利用过程中都如此。但这些检索文档中的文本中有相当一部分通常对生成没有帮助,不应被平等地参考和纳入到RAG中。
鉴于上述问题,本篇工作特别研究了检索器返回不准确结果的情况。提出了一种名为纠正式检索增强生成(Corrective Retrieval-Augmented Generation,CRAG)的方法,用于自我纠正检索结果并改善利用文档来增强生成的过程。
设计了一个轻量级的检索评估器,用于评估查询的检索文档的整体质量。这在RAG中扮演着重要角色,通过审查和评估检索文档的相关性和可靠性,为信息丰富的生成做出贡献。根据置信度来量化,基于这个置信度可以触发{正确,不正确,模糊}等不同的知识检索操作。
对于后两种操作,整合了大规模网络搜索作为一种战略性扩展,因为从静态和有限的语料库中检索只能以范围和多样性方面返回次优文档。这种增强实施旨在扩展检索信息的广度,利用网络的广阔和动态性来补充和丰富最初获得的文档。
此外,为了消除检索文档中包含的对RAG无用的冗余上下文,一个分解-重组算法在整个检索和利用过程中被精心打造。这一算法确保了检索信息的优化,优化了关键见解的提取,并最小化了不必要元素的参与,从而增强了检索数据的利用。
本篇工作的贡献有三个方面:
- 本文研究检索器返回不准确结果的情形,首次尝试为RAG设计纠正策略以提高其鲁棒性。
- 提出了一种即插即用的方法称为CRAG,旨在提高自动纠正能力和有效利用检索文档的能力。
- 实验证明CRAG适用于基于RAG的方法,对短篇和长篇生成任务具有很好的泛化性能。
相关工作
幻觉 虽然LLM表现出了理解指令和生成流畅语言文本的令人印象深刻的能力,但LLM仍然面临的最严重问题之一是幻觉。许多研究发现,激活过时信息或不正确知识会严重导致幻觉。大规模不受监管的训练数据收集、高质量采样数据比例低、输入空间中数据分配不完美等现实因素都会影响LLM,并恶化问题。因此,显而易见,缺乏准确和具体的知识会导致误导甚至不准确的生成,这将严重损害用户在大多数实际应用中的体验。
检索增强生成 RAG被认为是解决上述问题的一种有用方法,它通过从特定语料库(如维基百科)提供检索文档来增强生成式LLM的输入问题。通常情况下,它为生成式LLM提供了来自特定语料库的额外知识来源,这极大地提高了LLM在各种任务中的性能,特别是在知识密集型任务中。先前的研究通常在预先训练语言模型的响应生成前端使用稀疏或密集检索器,以专门针对检索提供包含相关知识的文档。尽管如此,上述方法通常忽略了一个问题,即如果检索出现问题怎么办?由于引入检索的目的是确保生成式LLM能够获取相关和准确的知识。如果检索的文档与问题无关,检索系统甚至可能加剧LLM的事实错误。
高级RAG 近年来开发了许多从原始RAG发展而来的高级方法。考虑到对一些查询来说检索有时是不必要的,相反,在许多情况下,不经过检索的响应甚至更准确。Self-RAG1提出了有选择性地检索知识,并引入了一个评论模型来决定是否检索。Yoran等人设计了一个NLI模型来识别无关上下文并改善鲁棒性。SAIL在指令下调整,以在指令前插入检索文档。而Toolformer则是针对调用维基百科等API进行预训练的。此外,在一些长文本生成任务中,需要外部知识多次,需要考虑何时检索。姜等人2主动预期未来内容,并决定长篇生成中何时以及检索什么。
任务公式化
在之前的工作的基础上,给定输入 X \mathcal X X和包含大量知识文档的可访问语料库 C = { d 1 , . . . , d N } \mathcal C = \{d_1,...,d_N\} C={d1,...,dN},系统预计生成输出 Y \mathcal Y Y。整个框架通常分为检索器 R \mathcal R R和生成器 G \mathcal G G。检索器 R \mathcal R R旨在从语料库 C \mathcal C C中检索与输入 X \mathcal X X相关的前K个文档 D = { d r 1 , . . . , d r k } \mathcal D = \{d_{r1},...,d_{rk}\} D={dr1,...,drk}。基于输入 X \mathcal X X和检索结果 D \mathcal D D,生成器 G \mathcal G G负责生成输出 Y \mathcal Y Y。这个框架可以表述为:
P ( Y ∣ X ) = P ( D ∣ X ) P ( Y , D ∣ X ) (1) P(\mathcal Y|\mathcal X ) = P(\mathcal D|\mathcal X )P(\mathcal Y, \mathcal D|\mathcal X ) \tag 1 P(Y∣X)=P(D∣X)P(Y,D∣X)(1)
这表明检索器和生成器是无缝耦合的,展示了低风险容忍度。任何未成功的检索都可能导致不令人满意的响应,而不管生成器的出色能力如何。这正是本篇工作关注的重点,即改善生成的鲁棒性。
CRAG
模型推理概览
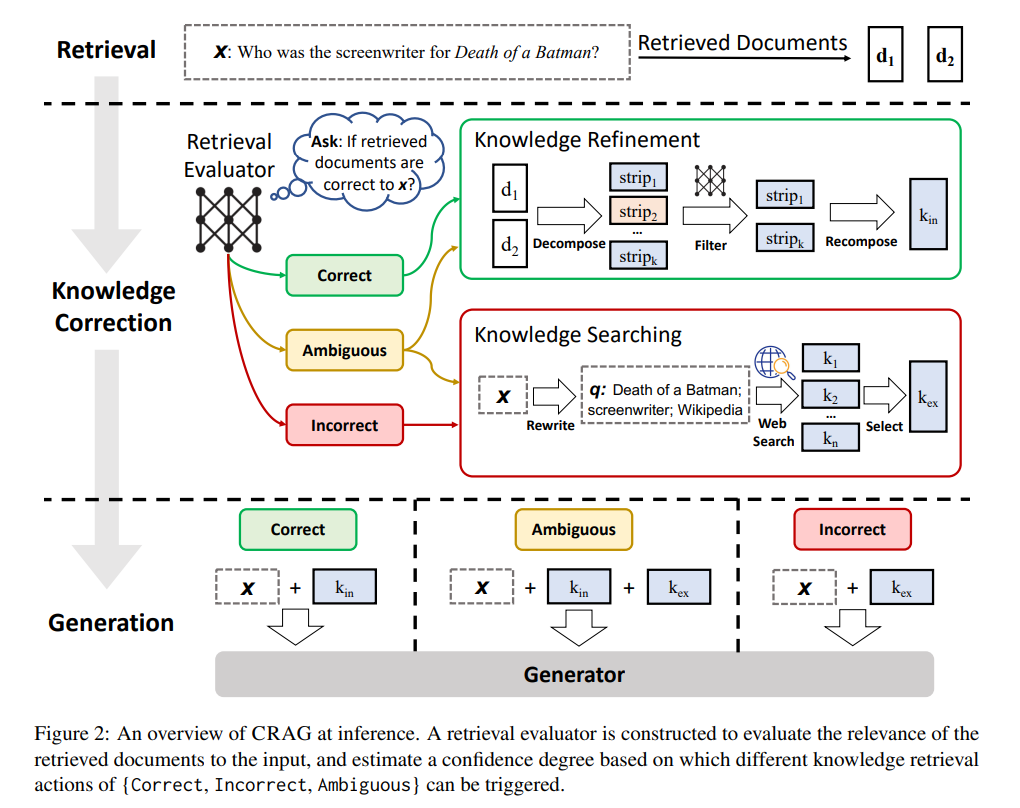

图2和算法1展示了CRAG在推理过程中的概述,该模型设计了纠正策略来改善生成的鲁棒性。给定一个输入查询和来自任何检索器的检索文档,构建了一个轻量级的检索评估器,用于估计检索文档与输入查询的相关性分数。相关性分数被量化为三个置信度度量,并触发相应的操作:{正确,错误,模糊}。
如果触发了“正确”操作,则检索到的文档将被精细化为更精确的知识片段。这种精炼操作涉及知识分解、过滤和重组。如果触发了“错误”操作,则检索到的文档将被丢弃。相反,将采用网络搜索,并被视为用于更正的补充知识来源。最终,当无法自信地做出正确或错误的判断时,触发一种软性平衡的“模糊”操作,结合了两者。在优化检索结果后,可以采用任意的生成模型。
检索评估器
在使用检索到的文档之前,自然会想知道这些文档是否准确,这一点非常重要,因为通过这种方式可以识别出不相关或误导性的信息。检索评估器的准确性在塑造整体系统性能方面无疑起着关键作用,因为它影响了后续流程的结果。我们的目标是在检索到的文档不相关时进行纠正。具体来说,作者采用T5-large来初始化检索评估器并进行微调。可以从现有数据集中收集用于微调评估器的相关性信号。有关此微调步骤的更多细节,请参考附录B.2。通常情况下,每个问题会检索到约10个文档。将问题与每个单独的文档连接作为输入,评估器分别为每个问题-文档对预测相关性分数。祖宗还尝试促使ChatGPT识别检索相关性以进行比较,但其表现不佳。基于这些计算的相关性分数,将最终确定检索是否与动作触发相关。与Self-RAG的批评模型和经过指令调整的LLaMA-2 (7B)相比,CRAG中设计的评估器表现出非常轻量级的优势(0.77B)。
动作触发
为了根据需要纠正不相关的文档并对目标文档进行精细化处理,应当有针对性地执行动作。根据每个检索到的文档的上述置信度评分,设计了三种类型的动作,并相应地触发,其中设置了上限和下限阈值。如果置信度评分高于上限阈值,则将检索到的文档标识为正确,如果低于下限阈值,则标识为错误。否则,执行模糊操作。每个检索到的文档都会单独进行处理,最终集成起来。
**正确 **这里,当至少一个检索到的文档的置信度评分高于上限阈值时,将假定检索是正确的。如果确实如此,这意味着在检索结果中存在相关的文档。即使可以找到相关的文档,在这些文档中不可避免地会有一些嘈杂的知识片段。为了提取出这些文档中的最关键知识片段,进一步设计了一种知识精炼方法。
错误 另外,当所有检索到的文档的置信度评分都低于下限阈值时,将假设检索是错误的。这表明所有检索到的文档都被认为是不相关的,对生成没有帮助。因此,我们需要寻找新的知识来源进行更正。在这里,介绍了从网络上搜索的网络搜索。这种更正性的动作有助于克服无法参考可靠知识的尴尬挑战。
模糊 除了上述两种情况外,其余情况将被分配给一种中间的模糊动作。由于检索评估器对其判断不太自信,因此将正确和错误中处理的两种类型的知识相结合互补。实施这样一种缓和和柔性策略可以显著有助于增强系统的鲁棒性和弹性,促进更灵活的框架以实现最佳性能。
知识精炼
针对检索到的相关文档,设计了一种分解-重组知识精炼方法,以进一步提取其中最关键的知识片段。首先,通过启发式规则将每个检索到的文档分割成细粒度的知识片段,更多细节请参考附录B.2。然后,利用前面介绍的微调的检索评估器来计算每个知识片段的相关性分数。根据这些分数,将不相关的知识片段进行过滤,而将相关的知识片段按顺序重新组合,即内部知识。
网络搜索
如果认为检索到的结果都是不相关的,那么寻找补充的外部知识就变得极为重要。由于从静态和有限的语料库中检索只能返回范围和多样性方面的次优文档,因此将大规模网络搜索整合作为RAG的战略扩展至关重要。具体而言,ChatGPT将输入重写为由关键词组成的查询,以模拟搜索引擎的日常使用。重写的提示见附录A。在CRAG中,采用公开且可访问的商业网络搜索API为每个查询生成一系列URL链接。此外,我们利用这些URL链接浏览网页,转录其内容,并使用与前面相同的知识精炼方法提取相关的网页知识,即外部知识。
实验
略
消融研究
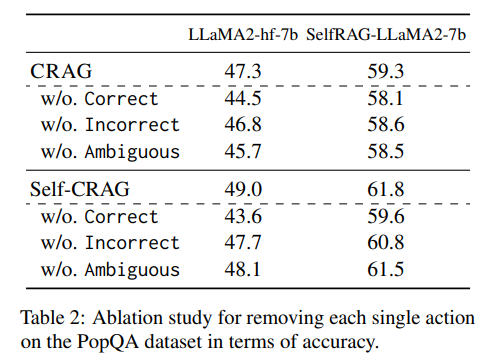
每个触发动作的影响 为了进一步验证检索评估器中设计的触发动作的有效性,在提出的方法中进行了移除每个单独动作的消融测试,如表2所示。在PopQA数据集上进行了评估,以展示准确性方面的性能变化。具体来说,当移除动作Correct或Incorrect时,将其合并为Ambiguous,以便原本会触发Correct或Incorrect的比例将触发Ambiguous。另一方面,当移除动作Ambiguous时,只有一个阈值可以清楚地触发所有输入查询为Correct或Incorrect。从这些结果可以看出,无论移除哪个动作,性能都会下降,说明每个动作都有助于提高生成的鲁棒性。
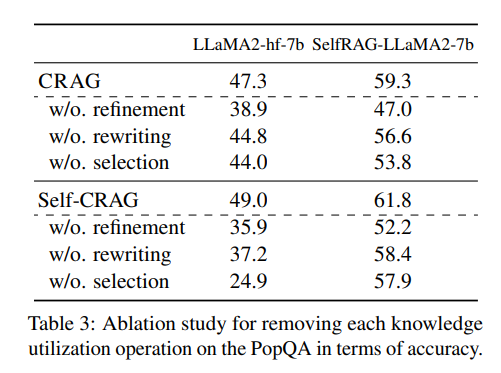
每个知识利用操作的影响 表3说明了如果移除一个关键的知识利用操作,性能会发生怎样的变化。在PopQA数据集上,通过分别移除文档精炼、搜索查询重写和外部知识选择这些知识利用操作,进行了准确性方面的评估。移除文档精炼意味着原始检索到的文档直接馈送给后续生成器,类似于大多数现有工作。此外,移除搜索查询重写意味着在知识搜索过程中问题不会被重写成由关键词组成的查询。最终,移除知识选择意味着将所有网页搜索内容都视为外部知识,没有进行筛选。这些结果表明,无论移除哪个知识利用操作,最终系统的性能都会下降,揭示了每个知识利用操作对提高知识利用的贡献。
检索评估器的准确性

检索评估器的质量显著影响整个系统的性能。在给定文档检索结果的情况下,评估检索评估器是否能准确确定这些结果的整体质量。在PopQA数据集上评估了我们的检索评估器和商用LLM ChatGPT对文档检索结果的评估准确性,结果如表4所示。实验中使用的ChatGPT、ChatGPT-CoT和ChatGPT-few-shot的提示可参考附录A。结果显示,基于轻量级T5的检索评估器在所有设置中明显优于竞争对手ChatGPT。
检索性能的鲁棒性

为进一步验证所提方法对检索性能的鲁棒性,研究了在不同检索性能条件下生成性能的变化。有意从准确的检索结果中随机删除一部分,模拟低质量的检索器,并评估性能的变化。图3展示了Self-RAG和Self-CRAG在PopQA数据集上的性能变化。可以看出,随着检索性能下降,Self-RAG和Self-CRAG的生成性能也下降,表明生成器在很大程度上依赖于检索器的质量。此外,随着检索性能的下降,Self-CRAG的生成性能相对于Self-RAG的下降幅度更小。这些结果暗示了Self-CRAG在增强对检索性能的鲁棒性方面优于Self-RAG。
结论
本篇工作研究了一个问题,即当检索出现错误时,基于RAG的方法会面临挑战,从而向生成式语言模型呈现不准确和误导性的知识。提出了 CRAG方法来提高生成的鲁棒性。本质上,一个轻量级的检索评估器用于有选择地评估和触发三种知识检索动作。通过进一步利用网络搜索和优化知识利用,CRAG显著提高了自动自我校正和检索文档的高效利用能力。实验证明其适用于基于RAG的方法,并且在短文和长文生成任务中具有泛化能力。
限制
虽然作者主要提出了从纠正的角度改进RAG框架,但如何更准确、有效地检测并纠正错误的知识仍需要进一步研究。尽管CRAG可以与各种基于RAG的方法无缝结合,但微调检索评估器是不可避免的。此外,网络搜索引入的潜在偏见也值得关注。互联网资源的质量差异可能显著,未经充分考虑地整合这些数据可能会向生成的输出引入噪音或误导性信息。
附录
A 任务提示
生成知识关键词作为网络搜索查询的提示如下:
Extract at most three keywords separated by comma from
the following dialogues and questions as queries for the
web search, including topic background within dialogues
and main intent within questions.question: What is Henry Feilden’s occupation?
query: Henry Feilden, occupationquestion: In what city was Billy Carlson born?
query: city, Billy Carlson, bornquestion: What is the religion of John Gwynn?
query: religion of John Gwynnquestion: What sport does Kiribati men’s national
basketball team play?query: sport, Kiribati men’s national basketball team play
question: [question]
query:
直接指导ChatGPT3.5作为评估器的提示:
Given a question, does the following document have exact
information to answer the question? Answer yes or no
only.
Question: [question]
Document: [document]
增加COT指导ChatGPT3.5作为评估器的提示:
Given a question, does the following document have exact
information to answer the question?
Question: [question]
Document: [document]
Think Step by step, and answer with yes or no only
指导GPT-3.5 Turbo作为评估器的few-shot提示:
Given a question, does the following document have exact
information to answer the question? Answer yes or no
only.Question: In what city was Abraham Raimbach born?
Document: Bancroft was born on November 25, 1839
in New Ipswich, New Hampshire to James Bancroft and
Sarah Kimball. At an early age he was cared for by Mr.
and Mrs. Patch of Ashby, Massachusetts, the neighboring
town. While not legally adopted, they named him Cecil
Franklin Patch Bancroft, adding Franklin Patch after the
son Mr. and Mrs. Patch had who recently died. He
attended public schools in Ashby as well as the Appleton
Academy in New Ipswich. He entered Dartmouth College
in 1856 at the age of sixteen and graduated in 1860 near
the top of his class. Bancroft continued his education as he
began his career in teaching. He took classes at the Union
Theological Seminary in New York City during the 1864-
65 academic year. While there he was a member of the
United States Christian Commission, traveling to support
soldiers during the Civil War. He then transferred to the
Andover Theological Seminary where he would graduate
in 1867.
Answer: No.Question: In what country is Wilcza Jama, Sokółka
County?
Document: Wilcza Jama is a village in the administrative
district of Gmina Sokółka, within Sokółka County,
Podlaskie Voivodeship, in north-eastern Poland, close to
the border with Belarus.
Answer: Yes.Question: What sport does 2004 Legg Mason Tennis
Classic play?
Document: The 2004 Legg Mason Tenis Classic was the
36th edition of this tennis tournament and was played
on outdoor hard courts. The tournament was part of the
International Series of the 2004 ATP Tour. It was held at
the William H.G. FitzGerald Tennis Center in Washington,
D.C. from August 16 through August 22, 2004.
Answer: Yes.Question: Who is the author of Skin?
Document: The Skin We’re In: A Year of Black Resistance
and Power is a book by Desmond Cole published by
Doubleday Canada in 2020. The Skin We’re In describes
the struggle against racism in Canada during the year 2017,
chronicling Cole’s role as an anti-racist activist and the
impact of systemic racism in Canadian society. Among
the events it discusses are the aftermath of the assault of
Dafonte Miller in late 2016 and Canada 150. The work
argues that Canada is not immune to the anti-Black racism
that characterizes American society. Due to an error by the
publisher, the initial printing of the book’s cover did not
include word Blackïn the subtitle. The mistake was later ¨
corrected. The book won the Toronto Book Award for 2020.
In 2021, the book was nominated for the Shaughnessy
Cohen Prize for Political Writing.
Answer: No.Question: [question]
Document: [document]
Answer:
实验
B.2 实验细节
检索评估器: 基于轻量级的T5-large预训练模型对检索评估器进行了微调。其参数尺寸比大多数当前的大型语言模型(LLM)要小。为了确保所有实验结果与Self-RAG可比,Self-RAG通过Contriever提供的相同检索结果也被用于实验中。用于微调评估器的相关信号可以从现有数据集中收集。例如,PopQA为每个问题提供了来自维基百科的真实主题标题。我们可以利用这个信息跟踪一个不完全相关但质量较高的段落。我们将其用作微调检索评估器的相关标签。另一方面,负样本采用随机抽样,使用的是Self-RAG提供的版本。具体来说,原始的PopQA数据集包含14000个样本,其中1399个样本用于遵循Self-RAG的测试,其余的用于微调以避免信息泄漏。另外,微调后的评估器在推理过程中被转移和利用于生物、Pub和ARC数据集。正样本的标签设为 1 1 1,负样本的标签为 − 1 -1 −1。在推理阶段,评估器对每个文档的相关性进行从 − 1 -1 −1到 1 1 1的打分。触发三种动作的两个置信阈值是经验性地设置的。具体来说,在PopQA中设置为 ( 0.59 , − 0.99 ) (0.59,-0.99) (0.59,−0.99),在PubQA和ArcChallenge中设置为 ( 0.5 , − 0.91 ) (0.5,-0.91) (0.5,−0.91),在Biography中设置为 ( 0.95 , − 0.91 ) (0.95,-0.91) (0.95,−0.91)。
内部知识: 为了获得细致的检索结果,将检索结果分段呈现。如果一个检索结果只有一两个句子那么它被视为独立的段落,否则,检索文档需要被分割成更小的单元,通常包含几个句子,根据总长度。该规模被假定包含一个独立的信息片段,过滤是基于这些段落的。重新采用评估器来进行知识片段的过滤,top-k设置为5,过滤阈值为-0.5。
外部知识: 采用Google搜索API搜索相关URL,top-k设置为5,并优先添加来自维基百科的页面。搜索的网页通常以HTML文件形式展示,内容使用特殊标记如<p>和</p>分割。因此,不需要额外的分段如知识细化,相应的知识段落可直接由评估器选择,就如内部知识一般。
生成器: 由于CRAG是一种即插即用的方法,所有能用于RAG中的生成模型也适用于该方法。为了与基线保持一致以进行比较,采用了LLaMA2 用于生成。首先引入了来自huggingface的LLaMA2-hf7b用于生成响应。由于Self-RAG微调了LLaMA2并在多个任务上达到了最新的最佳性能,作者进一步利用了推出的模型SelfRAG-LLaMA2-7b作为新的生成器,以便与他们的工作保持一致。
Self-CRAG: 为了证明作者的即插即用方法可以被用在其他同时进行的研究中,专门设计了将CRAG插入到Self-RAG框架中,并将其命名为Self-CRAG。Self-RAG是一个先进的RAG方法,引入了一个评论模型来决定是否检索以及哪个检索到的文档用于生成。它满足了决定触发哪一个动作的需求,因此用处理过的内部知识替换Self-RAG中的检索项作为正确、用外部知识替换为错误、以及用组合知识表示为模糊。
总结
⭐ 本篇工作提出了纠正式RAG来提高RAG生成的鲁棒性,但需要用到一个微调的检索评估器,不想进行这一步的也可以直接用LLM代替。同时对检索后的文档就行细粒度的处理,仅保留相关部分,以避免影响LLM的生成。
引用
SELF-RAG: LEARNING TO RETRIEVE, GENERATE, AND CRITIQUE THROUGH SELF-REFLECTION ↩︎
Active Retrieval Augmented Generation ↩︎

![【Linux】-Linux基础命令[2]](https://img-blog.csdnimg.cn/direct/b0d5eed8dcbb407a983768b6e5abe702.png)