- 爬虫原理
- 爬虫需要遵守的规则
- 实际操作
爬虫
其实通俗点来讲爬虫就是一个探测机器,它的基本操作就是模拟人的行为去各个网站溜达,点点按钮,查查数据,或者把看到的信息背回来,(切记是安全的数据,允许爬的范围内)
一.爬虫的原理
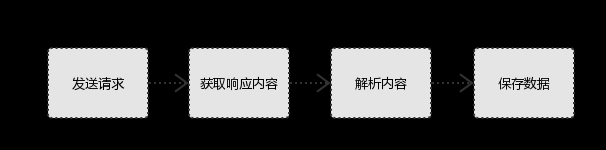
二.Python爬虫 爬虫需要遵守的规则
Robots-网络爬虫排除标准协议
Robots Exclusion Standard 网络爬虫排除标准
作用:网站告知爬虫哪些页面可以抓取,哪些不行
形式:在网站根目录下的robots.txt文件
案例:京东的robots协议
https://www.jd.com/robots.txt

Robosts协议的基本语法:
*代表所有
/代表根目录
其他网站的robots协议

robots协议的遵守方方式
网络爬虫:自动或人工识别robots.txt文件,再进行内容爬取
约束性:robots协议是建议但非约束性,网络爬虫可以不遵守,但存在法律风险
对robots协议的理解
| 爬取网页,玩转网页 | 访问量很小:可以遵守/访问量较大:建议遵守 |
|---|---|
| 爬取网页,爬取系列网站 | 非商业偶尔:建议遵守 /商业利益:必须遵守 |
| 爬取全网 | 必须遵守 |
三.爬取图片
1.环境要求
python编写代码工具:PyCharm 2021.2
python环境:python3.8 (小编这里用的是python3.8的环境)
2.导包
pip install aiohttp #这段可以下载程序所用到的包,3.编写代码
1.这里需要用到三个图片的url,首先我们打开https://umei.cc/bizhitupian/dongtaibizhi/这个网址选择三张自己喜欢的图片,单击右键复制三张图片的url(这三张图片url具体放的位置,代码里会给出的)
附上代码可供参考:
import asyncio
import aiohttpurls = ["http://kr.shanghai-jiuxin.com/file/2021/0429/11a56f6cbc984b11c49c6cfe3f755adc.jpg","http://kr.shanghai-jiuxin.com/file/2020/0608/750a0de2a8c658b16a6309a18cc56212.jpg","http://kr.shanghai-jiuxin.com/file/2020/0608/df980505591cc79141141fc361e98e49.jpg"
#这块就是刚才复制的三张图片的url,自己想放多张也可以。
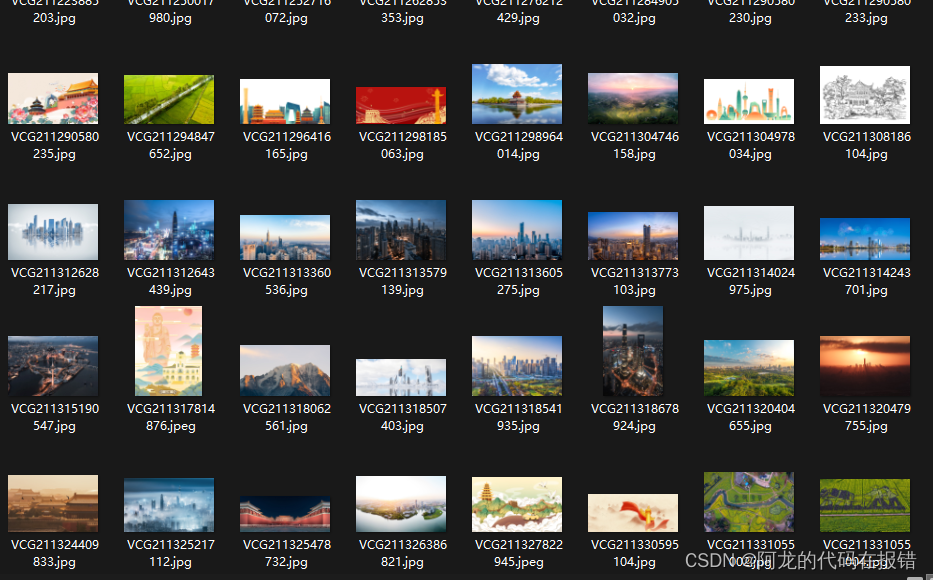
]async def aiodownload(url):name = url.rsplit("/", 1)[1] async with aiohttp.ClientSession() as seesion:async with seesion.get(url) as resp:with open(name, mode="wb") as f:f.write(await resp.content.read())await asyncio.sleep(1)print(name, "爬取完成")async def main():tasks = []for url in urls:tasks.append(aiodownload(url))await asyncio.wait(tasks)if __name__ == '__main__':loop = asyncio.get_event_loop()loop.run_until_complete(main())4.效果展示:


文件运行完成后,图片在你建python文件的根目录里,文件的后缀是jpg。点开就能看到你爬下来的图片了
总结:
python爬虫要学的还有很多,让我们一起慢慢的摸索,相互的去探讨,一起学习,各位如果有好的爬取项目,评论下来我们一起学习













![2021年中国电动牙刷销售及发展趋势分析:国产品牌崛起[图]](https://img-blog.csdnimg.cn/img_convert/26550371d64d9336e75277e28c80c457.png)