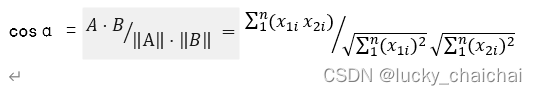一.导入外部数据
1.导入.xIs或.xIsx文件
pd.read_ excel(io,sheet_ name,header)1.1常用参数说明
●io:表示.xIs或.xIsx文件路径或类文件对象
●sheet name:表示工作表,取值如下表所示
●header:默认值为0,取第一行的值为列名,数据为除列名以外的数据,如果数据不包含列名,则设置header=None

其中,评论内容,评论时间,购买颜色,鞋码都是header

导入外部数据示例:

导入第二列数据,其中有多个列和标头时

导入多列

2.导入CSV文件
pd.read_csv(filepath_or_buffer,sep=',',header,encoding=None)
2.1常用参数说明
filepath_or_buffer:字符串、文件路径,也可以是URL链接
sep:字符串、分隔符
header:指定作为列名的行,默认值为0,即取第一行的值为列名。数据为除列名以
外的数据,若数据不包含列表,则设置header=None
encoding:字符串,默认值为None,文件的编码格式
示例如下:


3.导入txt文件
pd.read. _csvV(filepath. or_ buffer sep= \t ,header,encoding=None)
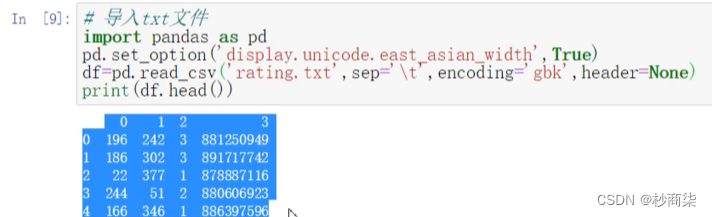
分割符号不再是" , " 而是\t,此时导入的是TXT格式sep 和 header 都要注意
4.导入HTML网页
pd.read_ html(io,match='.+ ',flavor,header,encoding)参数说明
io:字符串、文件路径,了可以是URL链接,网址不接受https
match:正则表达式
flavor: 解释器,默认为'lxml'
header:指定列标题所在的行
encoding:文件的编码格式
示例导入网页NBA球员的薪水表:

还可以进行存储,保存成CSV文件

5.数据抽取
DataFrame对象的loc属性与iloc属性
loc属性
以列名(columns)和行名(index)作为参数,当只有一个参数时,默认是行名,即抽取整行数据包括所有列。
iloc属性
以行和列位置索引(即:0,1,2,..)作为参数,0表示第一行,1表示第2行,以此类推。当只有一个参数时,默认是行索引,即抽取整行数据,包括所有列。

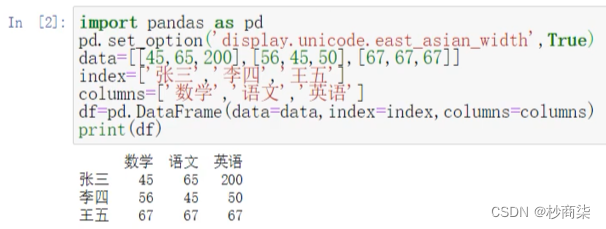
提取行数据
import pandas as pd
pd.set_option('display.unicode.east_asian_width',True)
data = [[45,65,100],[56,45,50],[67,67,67]]
index = ['张三','李四','王五']
columns = ['数学','语文','英语']
df = pd.DataFrame(data=data,index=index,columns=columns)
print(df)
print('------------------------')
# 提取行数据
print(df.loc['张三'])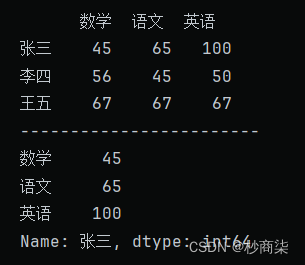
# 提取列数据
print(df.iloc[0])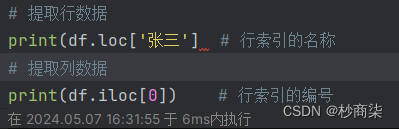
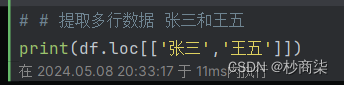
其中二者都可以使用


行索引名称,包含王五,利用切片
![]()

print(df.iloc[0,2])# 行索引序号,含0 不含2

提取连续数据可以使用切片


![[vue] nvm](https://img-blog.csdnimg.cn/direct/8d8f3c4cc22747658dcd267f9f6298a6.png)