目录
一 实验环境
二 部署 CoreDNS
1,所有node加载coredns.tar 镜像
2,在 master01 节点部署 CoreDNS
3, DNS 解析测试
4, 报错分析
5,重新 DNS 解析测试
三 master02 节点部署
1,从master01 传etcd 目录到 master02 节点
2,从master01 传 kubernetes 目录到 master02 节点
3,从master01传/root/.kube到 master02 节点
4, 从master01 传服务管理文件到 master02 节点
5,修改配置文件kube-apiserver中的IP
6, master02 节点上启动各服务并设置开机自启
7, master02 将 可执行文件都做软连接
8,验证 master02 是否安装成功
四 负载均衡部署
1,架构图
2,k8s 集群做 nginx +keepalive 负载均衡高可用 的必要性
3, 部署两台nginx 负载均衡服务器
3.1,配置nginx的官方在线yum源,配置本地nginx的yum源
3.2, 安装nginx
3.3,修改nginx配置文件,配置四层反向代理负载均衡,指定k8s群集2台master的节点ip和6443端口
3.4 检查配置文件语法
3.5 启动nginx服务,查看已监听6443端口
4,部署keepalived服务 解决nginx 单点故障
4.1 安装keepalived
4.2 修改keepalived配置文件
4.3 创建nginx状态检查脚本
4.4 启动keepalived服务
5, 使用一个VIP把node节点与master节点都关联起来
5.1 修改node节点上的bootstrap.kubeconfig 配置文件为VIP
5.2 修改node节点上的kubelet.kubeconfig 配置文件为VIP
5.3 修改node节点上的kube-proxy.kubeconfig配置文件为VIP
5.4 重启kubelet和kube-proxy服务
6, 查看nginx 和 node 、 master 节点的连接状态
7,测试创建pod
7.1 测试创建pod
7.2 查看Pod的状态信息
7.3 curl命令访问
7.4 查看nginx日志
7.5 查看service
五 部署 Dashboard
1,Dashboard 介绍
2, 准备Dashboard 和 metrics-scraper.tar
3,master01 节点上传 recommended.yaml 文件到 /opt/k8s 目录中
4, 执行 ymal 文件
5,创建service account并绑定默认cluster-admin管理员集群角色
6, 查看token 令牌
7, 浏览器登录Dashboard
8,在Dashboard 创建6台pod
六 总结
一 实验环境
k8s集群master01:192.168.217.66 kube-apiserver kube-controller-manager kube-scheduler etcd
k8s集群master02:192.168.217.77
k8s集群node01:192.168.217.88 kubelet kube-proxy docker
k8s集群node02:192.168.217.99
etcd集群节点1:192.168.217.66 etcd
etcd集群节点2:192.168.217.88 etcdetcd集群节点3:192.168.217.99 etcd
负载均衡nginx+keepalive01(master):192.168.217.22
负载均衡nginx+keepalive02(backup):192.168.217.44
二 部署 CoreDNS
CoreDNS:可以为集群中的 service 资源创建一个域名 与 IP 的对应关系解析
node加载coredns.tar 镜像
master 执行ymal 文件
1,所有node加载coredns.tar 镜像
拖入压缩包

docker load -i coredns.tar 载入镜像

2,在 master01 节点部署 CoreDNS
上传 coredns.yaml 文件到 /opt/k8s 目录中,部署 CoreDNS
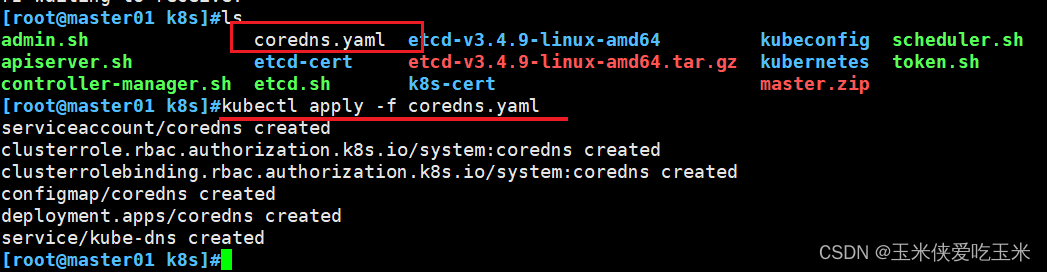
查看 kube-system 的命名空间

3, DNS 解析测试
kubectl run -it --rm dns-test --image=busybox:1.28.4 sh####################
--rm: 这个选项告诉 Kubernetes 当Pod中的容器终止时,自动删除该Pod。这对于一次性任务特别有用,可以避免遗留不再需要的Pod。dns-test: 这是给新创建的 Pod 指定的名字sh: 这部分指定了在容器启动后要执行的命令。在这里,sh 是Shell的命令,意味着启动容器后会直接进入一个Shell环境。用户可以通过这个Shell与容器内部进行交互,执行各种命令等4, 报错分析
如果出现以下报错

需要添加 rbac的权限 直接使用kubectl绑定 clusteradmin 管理员集群角色 授权操作权限
在master01:
kubectl create clusterrolebinding cluster-system-anonymous --clusterrole=cluster-admin --user=system:anonymous############
返回结果
clusterrolebinding.rbac.authorization.k8s.io/cluster-system-anonymous created
kubectl create clusterrolebinding命令用于在 Kubernetes 集群中创建一个新的 ClusterRoleBinding 资源。ClusterRoleBinding 将ClusterRole(一组权限)绑定到用户、组或其他实体,决定了这些实体在集群范围内能够执行的操作。下面是给定命令的详细解释:
kubectl create clusterrolebinding: 指令部分,表示要创建一个新的 ClusterRoleBinding 对象。
cluster-system-anonymous: 这是新创建的 ClusterRoleBinding 的名称。你可以自定义此名称,以便于管理和识别该ClusterRoleBinding的目的或作用。
--clusterrole=cluster-admin: 这个选项指定了要绑定的ClusterRole。在这个例子中,使用的是
cluster-admin,这是Kubernetes内置的ClusterRole,拥有对整个集群的完全管理权限。这意味着通过此ClusterRoleBinding关联的用户或组将拥有所有可能的权限。--user=system:anonymous: 这个选项指定了ClusterRoleBinding将应用到的用户。在这个命令中,用户是
system:anonymous。在Kubernetes中,system:anonymous是一个特殊用户,代表未认证的请求者,即任何未提供有效认证信息的访问尝试都会被视为这个用户。通过这种方式,此命令实际上是在赋予所有未经身份验证的访问者集群管理员权限,这是一个非常危险的配置,通常不推荐在生产环境中使用,因为这会极大地降低集群的安全性。总结起来,这条命令创建了一个名为
cluster-system-anonymous的ClusterRoleBinding,将集群管理员(cluster-admin)权限赋予了匿名用户(system:anonymous)。这是一种极端情况下的配置,实际操作中应谨慎使用此类权限分配,以免造成安全风险。
5,重新 DNS 解析测试

三 master02 节点部署
在企业里 master最少3台 有个leader
大体思路 是传 master需要的
etcd kubernetes 目录 以及/root/.kube(kubectl 的配置文件以及缓存) 以及所有服务的system 单元文件
最后一个一个启动
1,从master01 传etcd 目录到 master02 节点

2,从master01 传 kubernetes 目录到 master02 节点

3,从master01传/root/.kube到 master02 节点

cache: 这个目录通常用于存放由
kubectl命令行工具缓存的各种数据,比如API资源的本地副本或者上次查询的结果,以便提高后续命令的执行速度。这些信息帮助减少不必要的API服务器查询,提升交互效率。config: 这是一个非常重要的文件,全名为
config.yaml或config(取决于操作系统显示设置),它包含了Kubernetes配置信息,尤其是与集群连接相关的设置。这个文件定义了如何连接到Kubernetes API服务器(apiserver)、认证凭据(如token或client证书)、上下文(clusters)、用户(users)以及默认的命名空间(namespace)等。当你使用kubectl命令行工具时,它会默认查找这个文件来确定如何与Kubernetes集群进行通信。简而言之,
.kube/cache是kubectl用于缓存数据以提高效率的目录,而.kube/config则是一个关键的配置文件,用于存储与Kubernetes集群交互所需的认证和配置细节
4, 从master01 传服务管理文件到 master02 节点
scp /usr/lib/systemd/system/{kube-apiserver,kube-controller-manager,kube-scheduler}.service root@master02:/usr/lib/systemd/system/

5,修改配置文件kube-apiserver中的IP
去master02
vim /opt/kubernetes/cfg/kube-apiserver
将第5行 7行 改成自己的ip

6, master02 节点上启动各服务并设置开机自启
systemctl start kube-apiserver.service
systemctl enable kube-apiserver.service
systemctl start kube-controller-manager.service
systemctl enable kube-controller-manager.service
systemctl start kube-scheduler.service
systemctl enable kube-scheduler.service
7, master02 将 可执行文件都做软连接

8,验证 master02 是否安装成功
查看node节点状态


-o=wide:输出额外信息;对于Pod,将输出Pod所在的Node名
//此时在master02节点查到的node节点状态仅是从etcd查询到的信息,而此时node节点实际上并未与master02节点建立通信连接,因此需要使用一个VIP把node节点与master节点都关联起来
四 负载均衡部署
1,架构图
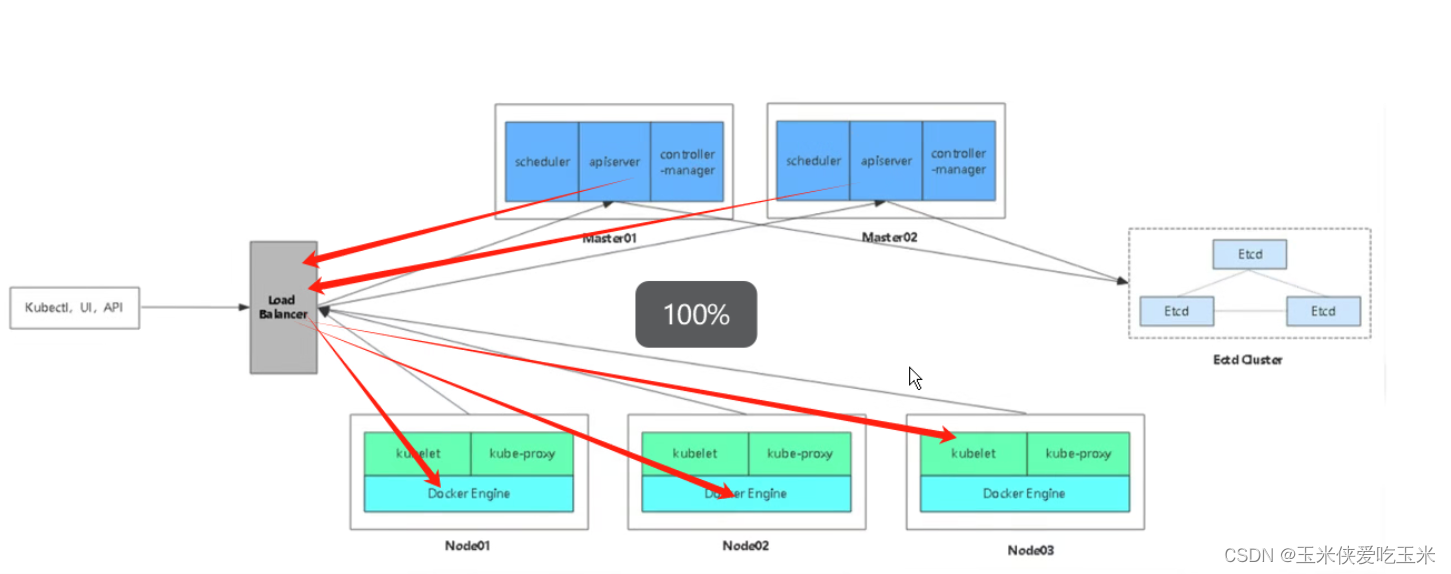
2,k8s 集群做 nginx +keepalive 负载均衡高可用 的必要性
负载均衡器 :
分摊master流量
且 node回包的时候 也是经过负载均衡器
所有master 不需要指向node
3, 部署两台nginx 负载均衡服务器
3.1,配置nginx的官方在线yum源,配置本地nginx的yum源
两个nginx服务器

cat > /etc/yum.repos.d/nginx.repo << 'EOF'
[nginx]
name=nginx repo
baseurl=http://nginx.org/packages/centos/7/$basearch/
gpgcheck=0
EOF
3.2, 安装nginx
两个nginx服务器

3.3,修改nginx配置文件,配置四层反向代理负载均衡,指定k8s群集2台master的节点ip和6443端口
两个nginx服务器
vim /etc/nginx/nginx.conf
stream {log_format main '$remote_addr $upstream_addr - [$time_local] $status $upstream_bytes_sent';access_log /var/log/nginx/k8s-access.log main;upstream k8s-apiserver {server 192.168.217.66:6443;server 192.168.217.77:6443;}server {listen 6443;proxy_pass k8s-apiserver;}
}
解释:
这段配置是Nginx的一个配置片段,用于设置一个反向代理和负载均衡,特别是针对Kubernetes(k8s)API服务器的流量管理。下面逐行解释各部分:
stream: 这里其实有一个小误解,正确的配置应该是放在
http块中而非stream,因为log_format,access_log,upstream, 和server配置都是HTTP相关的,而不是TCP/UDP流处理。stream模块用于处理四层协议(TCP/UDP)的负载均衡,而这里明显是在配置HTTP七层协议的负载均衡。因此,下面的解释基于它是HTTP配置的假设。log_format main ...: 定义了名为
main的日志格式,用于记录客户端IP地址(remote_addr),上游服务器地址(remoteaddr),上游服务器地址(upstream_addr),请求时间(time_local),HTTP响应状态码(timelocal),HTTP响应状态码(status),以及发送给客户端的字节数($upstream_bytes_sent)。access_log /var/log/nginx/k8s-access.log main;: 指定了访问日志的存储位置为
/var/log/nginx/k8s-access.log,并且使用前面定义的main日志格式来记录日志。upstream k8s-apiserver {...}: 定义了一个名为
k8s-apiserver的上游服务器组(可以理解为真实服务器),包含两个Kubernetes API服务器的地址:192.168.10.80:6443 和 192.168.10.20:6443。Nginx会根据负载均衡策略(默认是轮询)将请求分发到这两个地址之一。server {...}: 定义了一个监听在6443端口上的Nginx服务器块。
- listen 6443;: 指定该Nginx服务器监听在6443端口,这通常是Kubernetes API服务器的默认端口。
- proxy_pass k8s-apiserver;: 设置代理传递目标为之前定义的
k8s-apiserver上游服务器组,这意味着所有到达Nginx此端口的请求会被转发到这两个Kubernetes API服务器之一。总结来说,这段配置的作用是设置了一个Nginx作为Kubernetes API服务器的反向代理和负载均衡器,它监听在6443端口,接收对Kubernetes API的请求,并将这些请求透明地分发到两个Kubernetes API服务器实例上,同时记录相关访问日志。这样不仅提升了Kubernetes API服务的可用性和响应能力,还便于日志审计和故障排查。
3.4 检查配置文件语法
两个nginx服务器

3.5 启动nginx服务,查看已监听6443端口
两个nginx服务器

4,部署keepalived服务 解决nginx 单点故障
4.1 安装keepalived
两个nginx服务器

4.2 修改keepalived配置文件
ng01
vim /etc/keepalived/keepalived.conf
注意此处vip 地址 需要与master01 /opt/k8s/k8s-cert/k8s-cert.sh 中的vip 一致
vim /etc/keepalived/keepalived.conf
! Configuration File for keepalivedglobal_defs {# 接收邮件地址notification_email {acassen@firewall.locfailover@firewall.locsysadmin@firewall.loc}# 邮件发送地址notification_email_from Alexandre.Cassen@firewall.locsmtp_server 127.0.0.1smtp_connect_timeout 30router_id NGINX_MASTER #ng01节点的为 NGINX_MASTER,ng02节点的为 NGINX_BACKUP
}#添加一个周期性执行的脚本
vrrp_script check_nginx {script "/etc/nginx/check_nginx.sh" #指定检查nginx存活的脚本路径
}vrrp_instance VI_1 {state MASTER #ng01节点的为 MASTER,ng02节点的为 BACKUPinterface ens33 #指定网卡名称 ens33virtual_router_id 51 #指定vrid,两个节点要一致priority 100 #ng01节点的为 100,ng02节点的为 90advert_int 1authentication {auth_type PASSauth_pass 1111}virtual_ipaddress {192.168.217.100/24 #指定 VIP}track_script {check_nginx #指定vrrp_script配置的脚本}
}
ng02
vim /etc/keepalived/keepalived.conf
! Configuration File for keepalivedglobal_defs {# 接收邮件地址notification_email {acassen@firewall.locfailover@firewall.locsysadmin@firewall.loc}# 邮件发送地址notification_email_from Alexandre.Cassen@firewall.locsmtp_server 127.0.0.1smtp_connect_timeout 30router_id NGINX_BACKUP #ng01节点的为 NGINX_MASTER,ng02节点的为 NGINX_BACKUP
}#添加一个周期性执行的脚本
vrrp_script check_nginx {script "/etc/nginx/check_nginx.sh" #指定检查nginx存活的脚本路径
}vrrp_instance VI_1 {state BACKUP #ng01节点的为 MASTER,ng02节点的为 BACKUPinterface ens33 #指定网卡名称 ens33virtual_router_id 51 #指定vrid,两个节点要一致priority 90 #ng01节点的为 100,ng02节点的为 90advert_int 1authentication {auth_type PASSauth_pass 1111}virtual_ipaddress {192.168.217.100/24 #指定 VIP}track_script {check_nginx #指定vrrp_script配置的脚本}
}
4.3 创建nginx状态检查脚本
两个nginx服务器
vim /etc/nginx/check_nginx.sh
#!/bin/bash
#egrep -cv "grep|$$" 用于过滤掉包含grep 或者 $$ 表示的当前Shell进程ID,即脚本运行的当前进程ID号
count=$(ps -ef | grep nginx | egrep -cv "grep|$$")if [ "$count" -eq 0 ];thensystemctl stop keepalived
fi
加执行 权限

4.4 启动keepalived服务
两个nginx服务器
(一定要先启动了nginx服务,再启动keepalived服务)

查看VIP是否生成 ng01

5, 使用一个VIP把node节点与master节点都关联起来
所有node
5.1 修改node节点上的bootstrap.kubeconfig 配置文件为VIP
vim bootstrap.kubeconfig

5.2 修改node节点上的kubelet.kubeconfig 配置文件为VIP
vim kubelet.kubeconfig

5.3 修改node节点上的kube-proxy.kubeconfig配置文件为VIP
vim kube-proxy.kubeconfig
5.4 重启kubelet和kube-proxy服务

6, 查看nginx 和 node 、 master 节点的连接状态
ng01
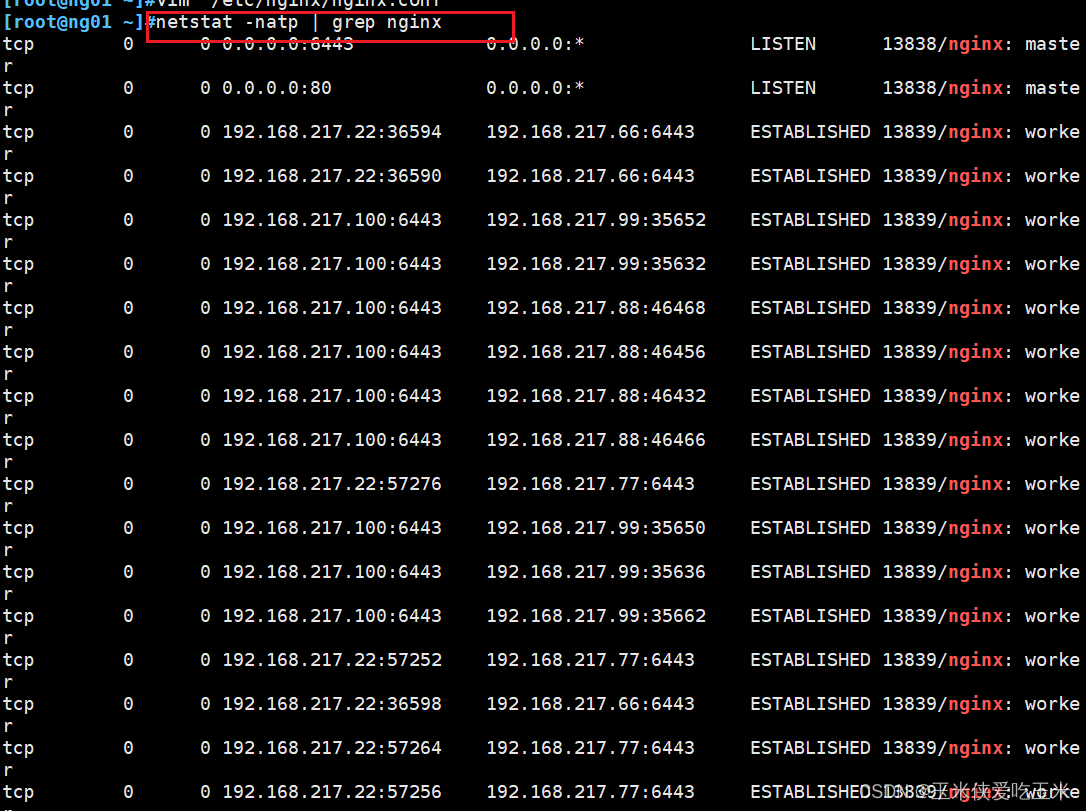
ng02

7,测试创建pod
master01 节点
7.1 测试创建pod
创建nginx pod

7.2 查看Pod的状态信息

 //READY为1/1,表示这个Pod中有1个容器
//READY为1/1,表示这个Pod中有1个容器
7.3 curl命令访问
在对应网段的node节点上操作,可以直接使用浏览器或者curl命令访问
node01

7.4 查看nginx日志
master01节点
网关访问

7.5 查看service
master01节点

五 部署 Dashboard
1,Dashboard 介绍
仪表板是基于Web的Kubernetes用户界面。您可以使用仪表板将容器化应用程序部署到Kubernetes集群,对容器化应用程序进行故障排除,并管理集群本身及其伴随资源。您可以使用仪表板来概述群集上运行的应用程序,以及创建或修改单个Kubernetes资源(例如deployment,job,daemonset等)。例如,您可以使用部署向导扩展部署,启动滚动更新,重新启动Pod或部署新应用程序。仪表板还提供有关群集中Kubernetes资源状态以及可能发生的任何错误的信息。
2, 准备Dashboard 和 metrics-scraper.tar
node01 node02
准备压缩包

加载Dashboard 镜像(可视化工具)

这是监控数据的

3,master01 节点上传 recommended.yaml 文件到 /opt/k8s 目录中
master01
#默认Dashboard只能集群内部访问,修改Service为NodePort类型,暴露到外部:
kind: Service
apiVersion: v1
metadata:labels:k8s-app: kubernetes-dashboardname: kubernetes-dashboardnamespace: kubernetes-dashboard
spec:ports:- port: 443targetPort: 8443nodePort: 30001 #添加type: NodePort #添加selector:k8s-app: kubernetes-dashboard
4, 执行 ymal 文件
master01
5,创建service account并绑定默认cluster-admin管理员集群角色
创建service account
kubectl create serviceaccount dashboard-admin -n kube-system

kubectl create serviceaccount dashboard-admin -n kube-system是一个 Kubernetes 命令,用于在 Kubernetes 集群中创建一个新的服务账户(service account)。下面是对这个命令各部分的详细解释:
kubectl: 这是 Kubernetes 的命令行工具,用于与 Kubernetes 集群进行交互,执行各种管理任务,如部署应用、检查集群状态等。
create: 这是一个 kubectl 动作,表示你要创建一个新的资源对象,如 Pod、Service、Deployment 或者在这个情况下,是 ServiceAccount。
serviceaccount: 这个关键词告诉 kubectl 你要创建的资源类型是 ServiceAccount。ServiceAccount 是 Kubernetes 中的一个特殊类型的对象,它用来为Pods提供身份和凭证,以便Pod内的进程能够与Kubernetes API进行安全通信。
dashboard-admin: 这是你要创建的服务账户的名称。在这个场景中,"dashboard-admin" 暗示这个服务账户可能被设计用来给 Kubernetes Dashboard 或其他需要访问API权限的组件提供管理员级别的访问权限,但具体权限由关联的Role或ClusterRole决定。
-n kube-system:-n或--namespace是一个选项,用于指定资源将被创建在哪个命名空间(namespace)中。在这里,命名空间是kube-system。kube-system是 Kubernetes 集群中的一个特殊命名空间,通常用于存放集群的核心组件和服务,如DNS、网络插件、监控系统等。选择kube-system表示这个服务账户将专用于该命名空间内的资源和服务。综上所述,这个命令的作用是在 Kubernetes 集群的
kube-system命名空间中创建一个名为dashboard-admin的服务账户,它可能被设计用于为Kubernetes Dashboard或类似应用提供必要的API访问权限。但请注意,实际的权限配置需要通过附加的Role或ClusterRole以及RoleBinding或ClusterRoleBinding来实现。
管理员账号 并赋权
kubectl create clusterrolebinding dashboard-admin --clusterrole=cluster-admin --serviceaccount=kube-system:dashboard-admin

kubectl create clusterrolebinding dashboard-admin --clusterrole=cluster-admin --serviceaccount=kube-system:dashboard-admin是 Kubernetes 中的一个命令,用于创建一个集群角色绑定(ClusterRoleBinding)。这个命令的目的是赋予之前创建的服务账户特定的权限。下面是各部分的详细解释:
kubectl create clusterrolebinding: 该命令用于创建一个新的集群角色绑定。ClusterRoleBinding 是 Kubernetes 中的一种授权机制,它将 ClusterRole(定义了一组权限)绑定到用户、组或服务账户上,并在整个集群范围内生效。
dashboard-admin: 这是新创建的集群角色绑定的名称。它作为一个标识符,方便后续管理和理解这个绑定的用途,这里暗示它与之前创建的dashboard-admin服务账户相关联,用于给该服务账户分配权限。
--clusterrole=cluster-admin: 这个选项指定了要绑定的 ClusterRole 名称。cluster-admin是 Kubernetes 内置的一个超级管理员角色,拥有对整个集群的完全访问权限。通过此选项,你实际上是将cluster-admin这一最广泛的权限集赋予了即将绑定的对象。
--serviceaccount=kube-system:dashboard-admin: 这个选项指定了要授予上述ClusterRole的服务账户及其所在的命名空间。格式为<namespace>:<serviceaccount-name>。在这个例子中,服务账户名为dashboard-admin,位于kube-system命名空间。这意味着kube-system命名空间下的dashboard-admin服务账户将获得cluster-admin角色所包含的所有权限。综上所述,这个命令的作用是创建一个集群角色绑定,它将
cluster-admin这个拥有集群管理员权限的角色绑定给了kube-system命名空间下的dashboard-admin服务账户,从而使该服务账户在 Kubernetes 集群中具有了非常广泛的管理权限。这通常用于需要高度访问权限的组件,比如 Kubernetes Dashboard 的后端服务,但需要注意的是,这样的设置应谨慎使用,以避免潜在的安全风险。
6, 查看token 令牌
这个就是Dashboard 令牌

查看token 令牌 复制
kubectl describe secrets -n kube-system $(kubectl -n kube-system get secret | awk '/dashboard-admin/{print $1}')

这条命令是用来查询 Kubernetes 集群中与
dashboard-admin服务账户相关的秘密(secrets)详细信息的。命令分为两部分,我们逐一解析:
获取 Secret 名称:
kubectl -n kube-system get secret: 这部分命令用于列出kube-system命名空间中的所有秘密。| awk '/dashboard-admin/{print $1}': 这里使用管道 (|) 将前一个命令的输出作为awk命令的输入。awk是一个强大的文本分析工具,这里使用的规则是,如果输出行中包含 "dashboard-admin"(这通常意味着与dashboard-admin服务账户相关的秘密),则打印该行的第一列(即Secret的名称)。描述 Secret 信息:
kubectl describe secrets -n kube-system $(...): 这部分利用上一步得到的 Secret 名称(通过命令替换$()实现),在kube-system命名空间中执行describe命令来展示这些秘密的详细信息。describe命令提供了关于资源的更详尽视图,包括其元数据、标签、选择器等属性,对于秘密来说,还会展示其类型、数据等敏感内容的加密表示。总结来说,整个命令的作用是查找
kube-system命名空间中与dashboard-admin服务账户相关的所有秘密,并详细描述这些秘密的信息。这对于调试、审计或理解服务账户认证和授权设置特别有用。
7, 浏览器登录Dashboard
谷歌好像不太行
使用输出的token登录Dashboard
https://NodeIP:30001
展示:

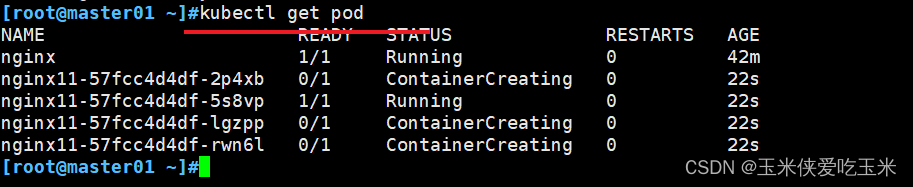
8,在Dashboard 创建6台pod

在master01 可查看到刚刚创建的pod
六 总结
多master集群架构的部署过程
首先 部署master02等其他master节点 master01配置文件拷贝(私钥、服务、执行文件)到master02
搭建nginx/Haproxy + keepalived 高可用负载均衡器对master节点
修改 node节点上kubelet kube-proxy的 kubeconfig配置文件对接VIP
kubectl 的配置文件也要对接VIP或者当前的节点