社交网络分析
上节课有同学希望能讲一些设备指纹的内容,所以这节课我们先讲一下设备指纹,作为反欺诈图谱的基础。
设备指纹
可以把手机设备理解成一个人,像人一样有身份证号和名字(设备序列号等),没有化妆(篡改)、没有被假冒(设备账户被盗用、冒用)等,是用于唯一标识出该设备的设备特征或者独特的设备标识。
一般都是基于某些设备信息,通过一些设备指纹算法会将这些信息组合起来,通过特定的hash算法得到一个最后的ID值,作为该设备的唯一标识符。常见的元素有:
- sim卡信息
- wifi信息
- 硬盘信息
- 内存信息
- 屏幕信息
- 设备的传感器特征,比如麦克风、加速传感器、摄像头等信息
- 浏览器本身的特征,包括UA,版本,操作系统信息等
- 浏览器中插件的配置,主要是插件的类型与版本号等
- 设备操作系统的特征,比如是否越狱等
- 浏览器的Canvas特征,影响该特征的因素有GPU特性造成的渲染差异,屏幕的分辨率以及系统不同字体的设置等
主动式设备指纹技术需要在客户端上植入自己的Javascript或SDK代码,主动收集设备相关的特征,用以标识设备和用户。在特征的选取上,需要考虑特征的稳定性和准确度。理想的特征应该在一定的时间段内不会因为外界的条件变化、或是用户的操作行为而发生变化,同时在不同的设备上具有显著的差异。
最基础的反欺诈做法呢,就是收集一定的数据,定义一些规则,不过主要看经验。但是很多时候是很难单一发现问题的,比如是否同一个手机号映射多个姓名,同一个手机,映射多个申请订单,等等。
这种一方面采用大数据的手段,建立宽表,然后定义一些规则,判断是否欺诈,去过滤掉一些客群。但有时候又有很多误判,比如,同一个手机号映射多个人名我们无法判断哪个是真还是假,只能全部拦截。可是很多公司的获客成本都比较高,放掉损失很大,这时候就可以用到我们现在反欺诈的主要手段–知识图谱。
知识图谱
知识图谱(Knowledge Graph/Vault)又称为科学知识图谱,2012年由谷歌提出,如今已经成为人工智能领域的热门问题之一,吸引了来自学术界和工业界的广泛关注,在一系列实际应用中取得了较好的落地效果,产生了巨大的社会与经济效益,其中包括金融领域。
知识图谱基于二元关系的知识库,构成网状结构。基于图的数据结构,以图的方式存储知识并向用户返回经过加工和推理的知识。它由“节点”和“边”组成,节点表示现实世界中存在的“实体”,边表示实体与实体之间的“关系”,其基本组成单位是“实体-关系-实体”的三元组,实体之间通过关系相互联结。
主要应用场景:
- 反欺诈
- 风险预测
- 催收
- 精准营销
- 智能搜索
举个例子来说明构建知识图谱的流程,此处我们采用个人信息(也可以是设备指纹,总之有可能是虚假的数据)进行一个场景构建。
1)通过对数据进行清理,抽取,构建知识图谱的节点,比如工作地址,姓名,身份证,GPS,工作地点,单位,IP,联系人手机号,等等。
2)比较好的方式是建立基础信息表,然后不断更新,这种方式比较好的原因是可以防止异常,可以保证数据最终一致性。这个就会根据不同情况,构建不同基础数据表,少则十几个,二十几个,多的可以成百上千。
3)基于清洗后的信息,进入图数据库,构建出整个知识图谱。
4)基于图算法进行相关的特征抽取或者通过网络结构进行负样本挖掘
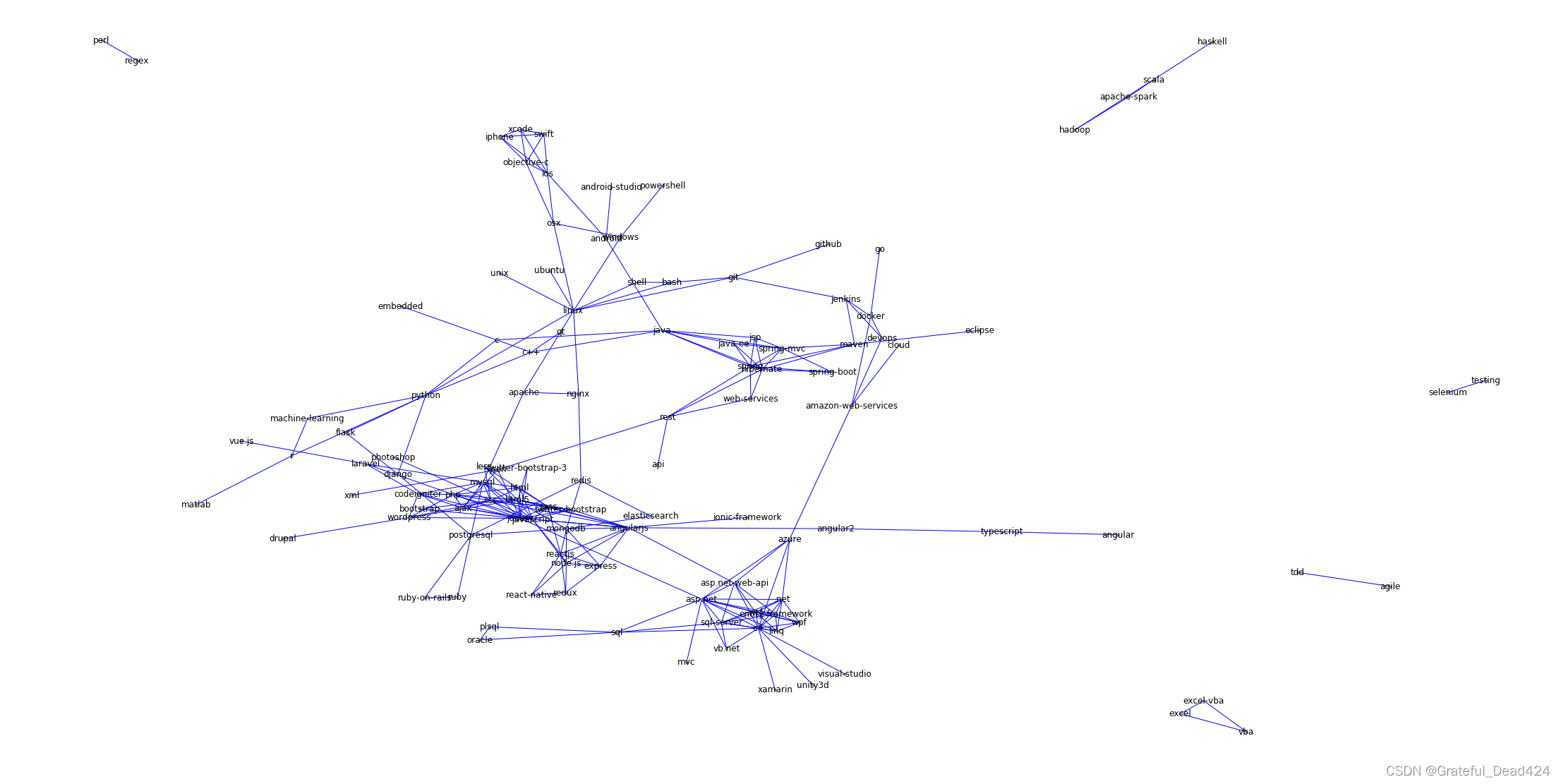
import networkx as nx
import pandas as pd
import matplotlib.pyplot as plt
edge_list=pd.read_csv('./data/stack_network_links.csv')
edge_list.head()

G=nx.from_pandas_edgelist(edge_list,edge_attr='value' )plt.figure(figsize=(30,15))nx.draw(G,with_labels=True,edge_color='blue',node_color='grey',node_size=10,pos=nx.spring_layout(G,k=0.1,iterations=40))
特征抽取:
- 不一致性检验
- 静态分析
- 动态分析
- 关联特征提取
网络信息挖掘:
- 社区发现
负样本生成:
- 染色
不一致性检验
在团簇中,如果用户的信息与我们的正常理解有严重偏差,那么这种团簇很可疑;如两个用户拥有同个家庭wifi,但所填家庭地址相差甚远,显然与现实不符。这里需要大量的人工干预,因为我们不能通过欺诈标签做相关的统计分析,更多的要靠经验判断。当然如果标签得当,我们其实可以通过做相似性度量来进行筛选重要的关联特征,作为规则的。
关联特征提取
对网络特征的直接提取,提取出中心度或一度二度关联特征可供上层规则系统或风险评估模型使用。基本思想仍然是在网络中社交越广泛,越有可能是一个坏人。
反欺诈对于实时决策的需求很高,这些指标都需要实时提取。其中一些指标,比如二度关联度, 在一般的情况下计算复杂度是很高的。在动态图的情形下,一般会采取一些近似的算法并进行预计算。
静态分析
给定时间节点,去尝试发现图形结构的异常子图。
动态分析
分析结构网络|随着时间变化的趋势
失联模型
挖掘更多的潜在的可触达联系人。
社区发现
社区发现(Community Detection)算法用来发现网络中的社区结构,也可以看做是一种聚类算法。
染色
染色本质就是一种基于关联图谱的半监督学习方法,我们知道在反欺诈的场景下,一个典型的困境就是欺诈标注非常少,获得的代价非常高,而我们要做一些监督式的机器学习,却又非常依赖于标注。因此如果能用少量的欺诈标注样本产生出更多的标注,就能最大程度利用欺诈样本。这就是染色的初衷,欺诈标注会沿着网络里的边从一个节点传播到另一个节点。
染色从直觉上比较容易理解,我们经常说近朱者赤,近墨者黑。一个用户和坏用户有关联,其实很有可能他本身就是有问题的。这里放一个数据,根据分析得到,一个客户一旦出现在某个坏客户的通讯录中,就有70%的概率会变坏。
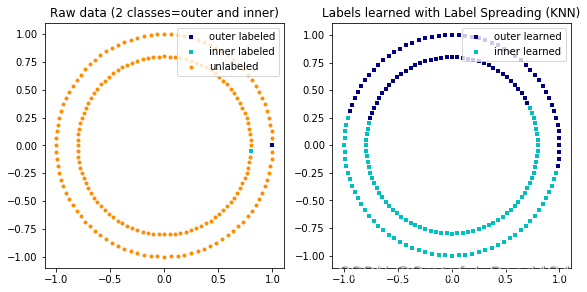
#基于sklearn标签传播算法示例
import numpy as np
import matplotlib.pyplot as plt
from sklearn.semi_supervised import label_propagation
from sklearn.datasets import make_circles# generate ring with inner box
n_samples = 200
X, y = make_circles(n_samples=n_samples, shuffle=False)
outer, inner = 0, 1
labels = np.full(n_samples, -1.)
labels[0] = outer
labels[-1] = inner
# Learn with LabelSpreading
label_spread = label_propagation.LabelSpreading(kernel='rbf', alpha=0.8)
label_spread.fit(X, labels)# Plot output labels
output_labels = label_spread.transduction_
plt.figure(figsize=(8.5, 4))
plt.subplot(1, 2, 1)
plt.scatter(X[labels == outer, 0], X[labels == outer, 1], color='navy',marker='s', lw=0, label="outer labeled", s=10)
plt.scatter(X[labels == inner, 0], X[labels == inner, 1], color='c',marker='s', lw=0, label='inner labeled', s=10)
plt.scatter(X[labels == -1, 0], X[labels == -1, 1], color='darkorange',marker='.', label='unlabeled')
plt.legend(scatterpoints=1, shadow=False, loc='upper right')
plt.title("Raw data (2 classes=outer and inner)")plt.subplot(1, 2, 2)
output_label_array = np.asarray(output_labels)
outer_numbers = np.where(output_label_array == outer)[0]
inner_numbers = np.where(output_label_array == inner)[0]
plt.scatter(X[outer_numbers, 0], X[outer_numbers, 1], color='navy',marker='s', lw=0, s=10, label="outer learned")
plt.scatter(X[inner_numbers, 0], X[inner_numbers, 1], color='c',marker='s', lw=0, s=10, label="inner learned")
plt.legend(scatterpoints=1, shadow=False, loc='upper right')
plt.title("Labels learned with Label Spreading (KNN)")plt.subplots_adjust(left=0.07, bottom=0.07, right=0.93, top=0.92)
plt.show()
#图谱中的标签传播算法
#生成一个连续连通图
G = nx.path_graph(5)
G.node[0]['label'] = 'A'
G.node[3]['label'] = 'B'
G.nodes(data=True)plt.figure(figsize=(20,10))nx.draw(G,with_labels=True,edge_color='blue',node_color='grey',node_size=10,pos=nx.spring_layout(G,k=0.1,iterations=40))

predicted = nx.node_classification.local_and_global_consistency(G)
predicted
#['A', 'B', 'B', 'B', 'B']
关键特征提取
#度
nx.degree(G)
#DegreeView({0: 1, 1: 2, 2: 2, 3: 2, 4: 1})
#度中心性 m/(n-1)
nx.degree_centrality(G)
#{0: 0.25, 1: 0.5, 2: 0.5, 3: 0.5, 4: 0.25}
nx.betweenness_centrality(G)
#{0: 0.0, 1: 0.5, 2: 0.6666666666666666, 3: 0.5, 4: 0.0}
nx.closeness_centrality(G)
#{0: 0.4,
# 1: 0.5714285714285714,
# 2: 0.6666666666666666,
# 3: 0.5714285714285714,
# 4: 0.4}
nx.katz_centrality(G)
#{0: 0.4204672617767119,
# 1: 0.4628997071494082,
# 2: 0.4667572021832897,
# 3: 0.4628997071494082,
# 4: 0.4204672617767119}
#连通子图
list(nx.connected_components(G))[0]
#{0, 1, 2, 3, 4}
# 取出网络的最大子图
Sub_G=G.subgraph(list(nx.connected_components(G))[0])
#计算节点的聚类系数
nx.clustering(Sub_G)
#{0: 0, 1: 0, 2: 0, 3: 0, 4: 0}
#计算网络的聚类系数
nx.average_clustering(Sub_G)
#0.0
#计算网络的平均路径
#只能在连通子图中求解
nx.average_shortest_path_length(Sub_G)
#2.0




![[项目管理-6]:软硬件项目管理 - 项目沟通管理(渠道、方法)](https://img-blog.csdnimg.cn/img_convert/25ef0e6b1528f105a1ebd38f2302883c.jpeg)