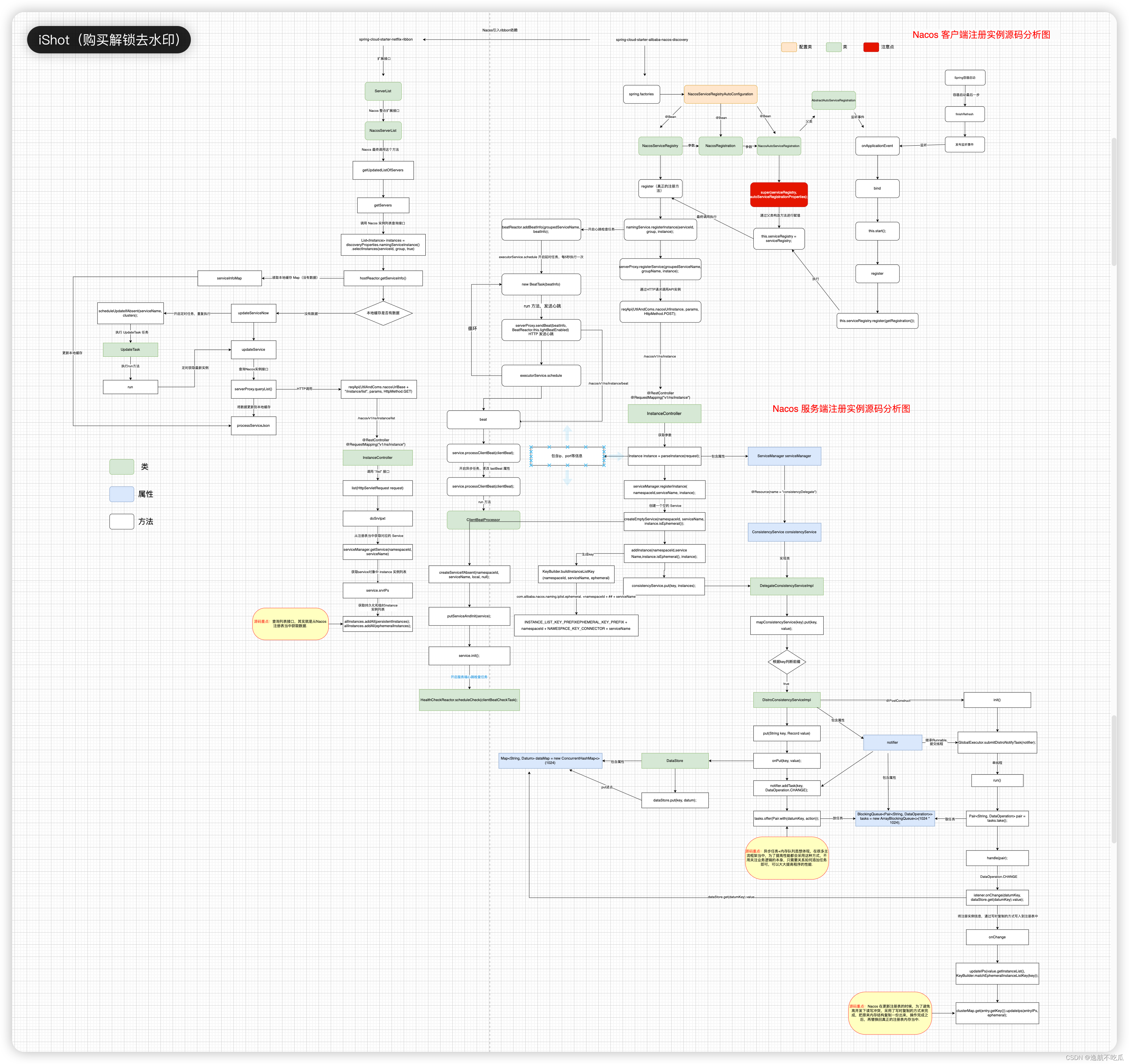
1.概述
近年来,大型语言模型(LLMs),例如ChatGPT,致力于构建能够辅助人类的个性化人工智能代理,这些代理以进行类似人类的对话为重点。在学术领域,尤其是社会科学中,一些研究报告已经指出,生成式代理具备模拟人类个性特征的能力。尽管在这一领域取得了显著进展,但关于个性化LLM如何精确且持续地再现特定人格特质的研究评估却相对匮乏。
在这种背景下,本文介绍了一项研究论文。该论文通过让LLMs模拟基于五大人格特质的角色,并通过从生成的内容中提取心理语言特征、进行人类评分和人格预测,来探究LLMs是否能够再现人格特征。这项研究为我们提供了对LLMs在个性化方面的潜力和挑战的深入理解。
源码地址:https://github.com/hjian42/personallm
论文地址:https://arxiv.org/pdf/2305.02547.pdf
2.五大人格特质
本文探讨了"五大"人格特质理论,这是由美国心理学家刘易斯·戈德堡提出的一个框架,用于描述和理解人的个性差异。该理论认为,人的个性可以通过五个基本维度来分类,这五个维度共同构成了人格的框架。
"五大"人格特质,也被称为五因素模型(Five-Factor Model),是心理学中一个广泛接受的人格特质理论。这个模型认为人格可以通过五个基本维度来描述,这五个维度通常被缩写为OCEAN:
- 开放性(Openness):与创造性、好奇心、想象力和对新体验的开放态度相关。
- 责任心(Conscientiousness):涉及组织性、坚持、自律、成就导向和可靠性]。
- 外向性(Extraversion):与社交性、活跃度、乐观和对外界刺激的需求相关。
- 宜人性(Agreeableness):与合作性、信任、利他、谦逊和对他人的同情相关。
- 神经质(Neuroticism):与情绪稳定性相反,涉及情绪波动、焦虑、抑郁和自我意识。
此外,本文还介绍了一个实验,其中让大型语言模型(LLM)根据上述五大人格特质之一来模拟角色。随后,利用大五人格量表(Big Five Inventory,BFI)对LLM模拟的角色进行了评估。通过这种方式,本文旨在探索LLM是否能够准确地再现和模拟特定的人格特质,这对于构建更加个性化和人性化的AI代理具有重要意义。
3. 实验概述
项目部署:
conda activate audiencenlp
python3.9 run_bfi.py --model "GPT-3.5-turbo-0613"
python3.9 run_bfi.py --model "GPT-4-0613"
python3.9 run_bfi.py --model "llama-2"
本文的实验工作流程如下图所示。

如图所示,本实验按照以下步骤进行。
A. 首先,运行提示,生成具有独特个性特征的LLM角色
B. 然后让生成的 LLM 角色完成故事写作任务
C. 使用 “语言探究和字数统计”(LIWC)框架,研究 "LLM角色 "所描述的故事是否包含表明指定个性特征的语言模式
D. 评估 LLM 角色(人类角色和 LLM 角色)所描述的故事。
E. 让人类和 LLM 完成从故事中预测作家 LLM 角色性格特征的任务
3.1 LLM角色模拟
实验使用了两个 LLM 模型(GPT-3.5 和 GPT-4),分别针对五大人格特质模拟了 10 个 LLM 角色,总共生成了 320 个角色。
然后,使用上述的 "BFI "对所生成的 "LLM 角色 "进行了评估,以检查它们是否充分再现了 “五大角色”。
3.2故事写作
然后,320 个LLM**"角色 "被要求 "请分享一个 800 字左右的个人故事。 请不要在故事中明确提及你的性格特征**。**不要在故事中明确提及你的性格特征。不要在故事中明确提及你的性格特征。**要求参与者撰写一个文本故事用于分析,并提示 "不要在故事中明确提及您的个性特征。
3.2 LIWC 分析
接下来,我们使用LIWC(语言调查和字数统计)框架从 "角色 "所描述的故事中提取心理语言特征,这是一种通过对文本中的词汇进行抽象和分类来对属性进行归类的方法。
这项分析旨在通过研究故事中的性格特征与分配给LLM的性格特征之间的相关性,找出与性格特征的性格特征相对应的语言模式。
3.3 故事评价
然后,人类和本地语言学家根据以下标准对本地语言学家角色所描述的故事进行评分
- 可读性:故事是否易读、结构合理、流畅自然?
- 个性:故事是否独特,是否清楚地表达了作者的思想和情感?
- 冗余:故事简明扼要,没有不必要的内容
- 凝聚力:故事写得好吗?
- 可读性:阅读是否有趣?
- 可信度:故事是否引人入胜,是否符合实际情况?
3.4 性格预测
最后,支持每个人和 LLM 从给定的故事中预测作家 LLM 角色的个性特征,评分标准为 1 到 5 分。本实验的目的是评估 LLM 角色所描述的故事是否能有效地展示人类和 LLM 都能识别的人格特质。
4. 实验结果
本文使用 GPT-3.5 和 GPT4 这两个 LLM 模型生成的 320 个 LLM 角色进行了实验,以确认以下两个研究问题。
A. LLM的 "角色 "是否反映了指定的个性特征?
B. 从 "LLM 角色 "所描述的故事中,能否获得每种人格特质的语言模式?
C. LLM角色所描述的故事是否写得充分?
D. 故事能预测LLM角色的个性特征吗?
4.1 LLM的 "角色 "是否反映了指定的个性特征?
为了证实这一研究问题,本实验根据 320 个LLM角色对 BFI 的回答计算了他们的个性分数,并通过 t 检验分析了这些分数的分布与所分配的个性特征的函数关系。
结果如下。
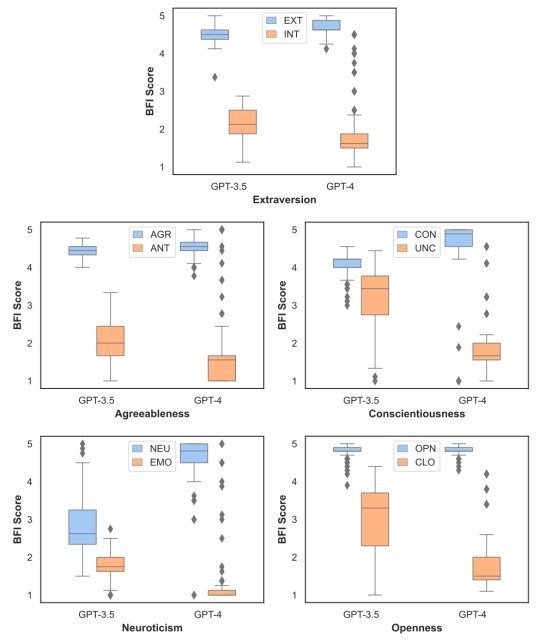
实验结果表明,在统计学上,LLM的角色****在所有性格特征上都有明显的差异,这证明他们反映了他们被赋予的角色。
4.2 LLM的 "角色 "是否反映了指定的个性特征?
为了证实这一研究问题,本实验使用 LIWC 从 LLM 角色生成的故事中提取了心理语言特征,并计算了这些特征与指定人格特质之间的点比对相关性(PBCs)。
点双项相关系数是一种适用于分析二元变量与连续变量之间关系的系数,在此用于研究指定的人格特质(=二元变量)与 LIWC 特征(=连续变量)之间的相关性。
下表概述了与个性特征有显著统计学相关性的 LIWC 特征。

实验结果表明,指定的人格特质对法学硕士角色的语言风格有显著影响,例如,当LLM被赋予神经质角色时,更倾向于使用负面词汇,如焦虑和负面语气。结果表明,所分配的人格特质对法学硕士角色的语言风格有显著影响。
此外,更重要的是,这些相关性反映了在人类描述的故事中观察到的模式,证实了人类和 LLM 角色之间用词的一致性。(与 GPT-3.5 相比,GPT-4 的结果与人类更加一致) 。
4.3 LLM角色所描述的故事是否写得充分?
为了证实这一研究问题,本实验评估了由 LLM 角色(包括人类角色和 LLM 角色)生成的故事。
评估结果见下表。
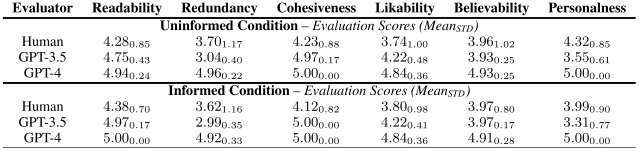
值得注意的是,GPT-4 角色所生成的故事在可读性(可读性)、内聚性(内聚性)和可信性(现实性)方面都获得了人类和 LLM 4.0 或更高的评分。重点是在以下方面获得了 4.0 或更高的评分。
结果证实,"角色 "所产生的故事不仅语言流畅、结构连贯,而且引人入胜。
4.4 故事能预测法学硕士角色的个性特征吗?
为了证实这一研究问题,本实验将每个角色的个性特征视为二元分类问题,并计算了人类和 LLM 预测个性特征的准确率。
实验结果如下图所示。
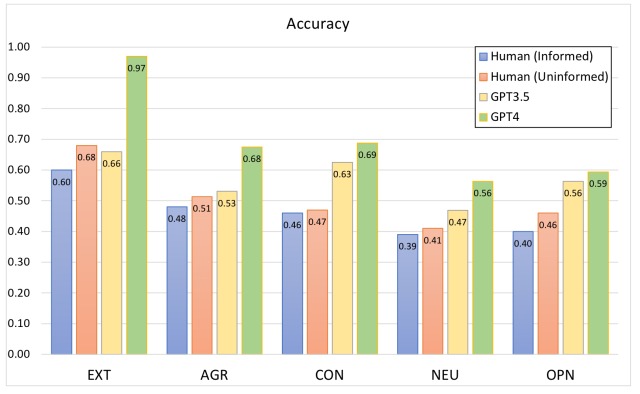
实验结果表明,人类从 GPT-4 角色描述的故事中预测性格特征的准确率在外向性和宜人性方面分别低至 68% 和 51%,这证实了人类基于文本的性格预测任务的难度。.
另一方面,GPT-4 在 “外向性”、"宜人性 "和 "自觉性 "方面的准确率分别为 97%、68%和 69%,表明它可以非常准确地预测人格特质。研究结果如下
5.总结
本论文通过模拟基于五大人格特质的角色,并通过分析生成内容中的心理语言特征、人类评价以及人格预测,深入探讨了大型语言模型(LLM)是否能够再现人格特质。
实验结果表明,LLM不仅能够成功模拟特定的人物形象,而且还能通过用词习惯反映出人格特质,进而实现对人格特质的预测。这一发现突显了LLM在模拟人类个性方面的庞大潜力。
然而,研究也指出了未来需要进一步探索的领域。例如,当前的实验并未模拟更自然的情境,如LLM角色之间的互动或协作。此外,研究主要关注英语,尚未扩展到其他语言的探索。
随着这一研究领域的持续发展,我们有理由期待,未来将能够开发出能够精确复制人类个性和行为的人工智能代理,它们的行为模式将与人类无异。