初级爬虫的总结一之百度网页爬虫
- 一、寻找正确的sugrec
- 二、url拼接出问题,解决办法
我遇到的问题:
1、没有找对网页sugrec,导致connect-type没有找对,以及一些小问题
2、url拼接时候出现乱码
一、寻找正确的sugrec
1、打开百度网址,看看进行搜索时候,该网页标签是否在进行变化
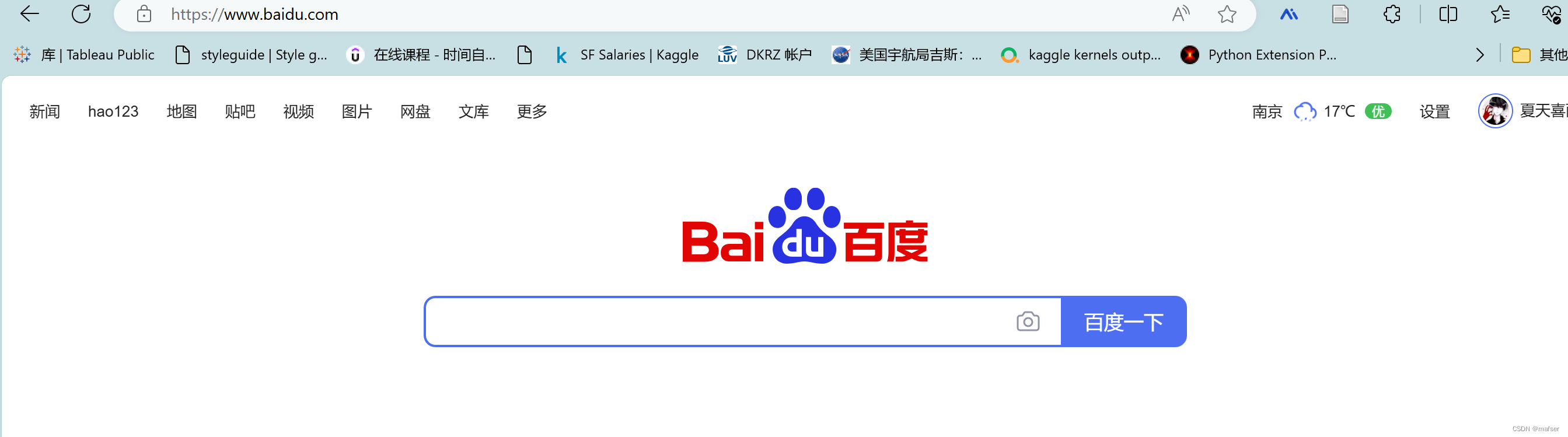
2、右键点开查找
3、点击网络,再点击下面的fetch/XHR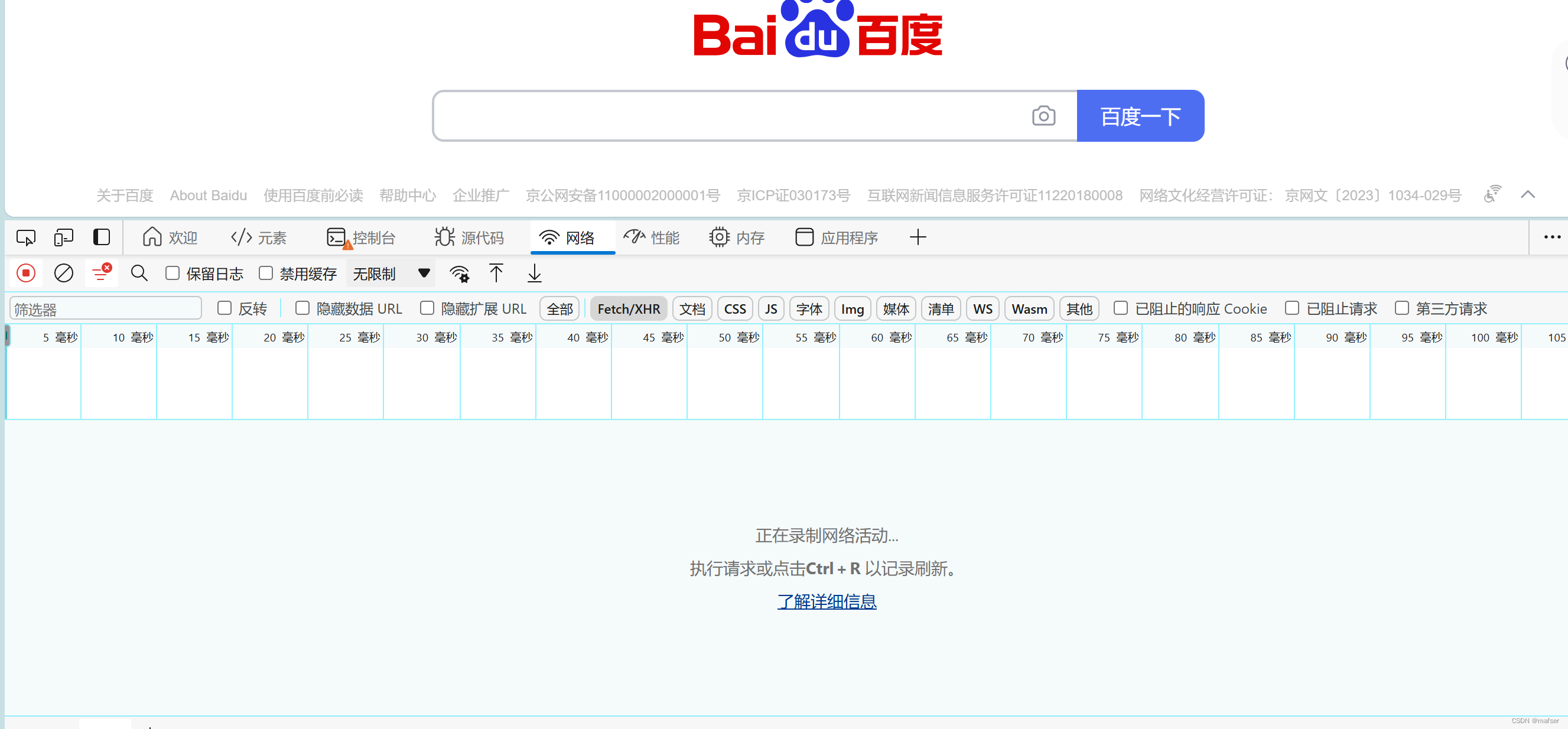
4、点击百度一下,请注意出现的这个sugrec,之后会用到的
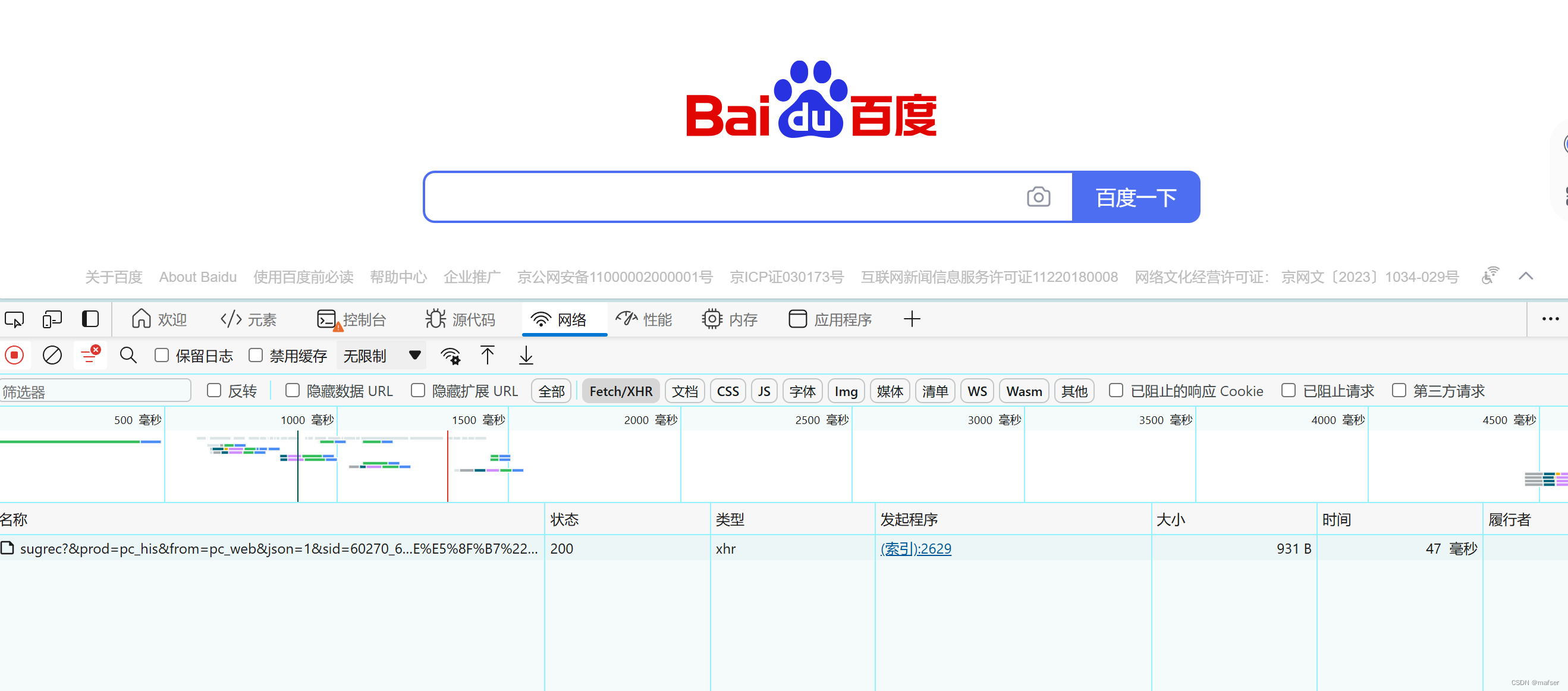
5、输入你要查找的词汇,在网址栏中喜欢后面的删除,回车一下,将会得到,我们需要的sugrec
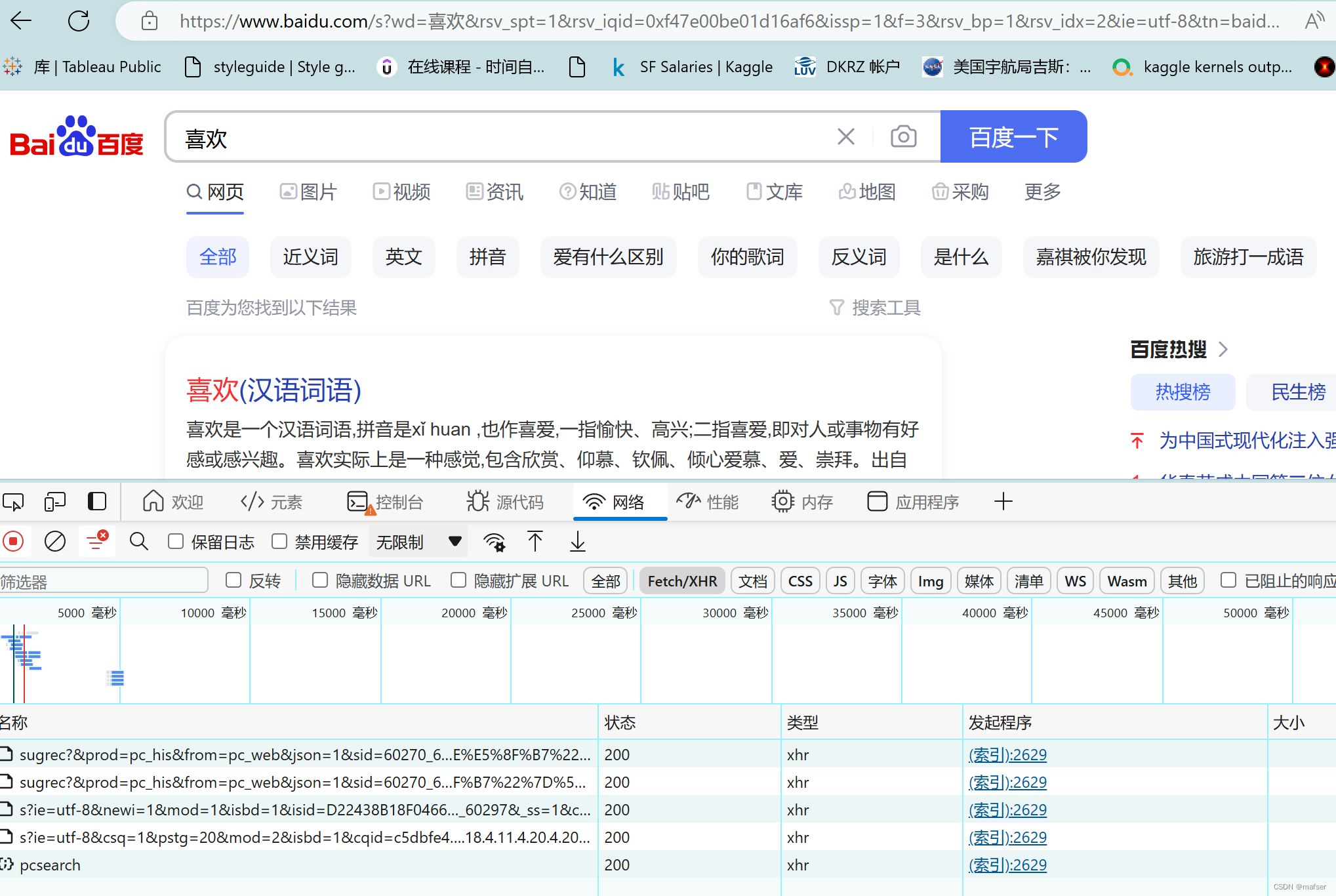
6、得到要用的sugrec
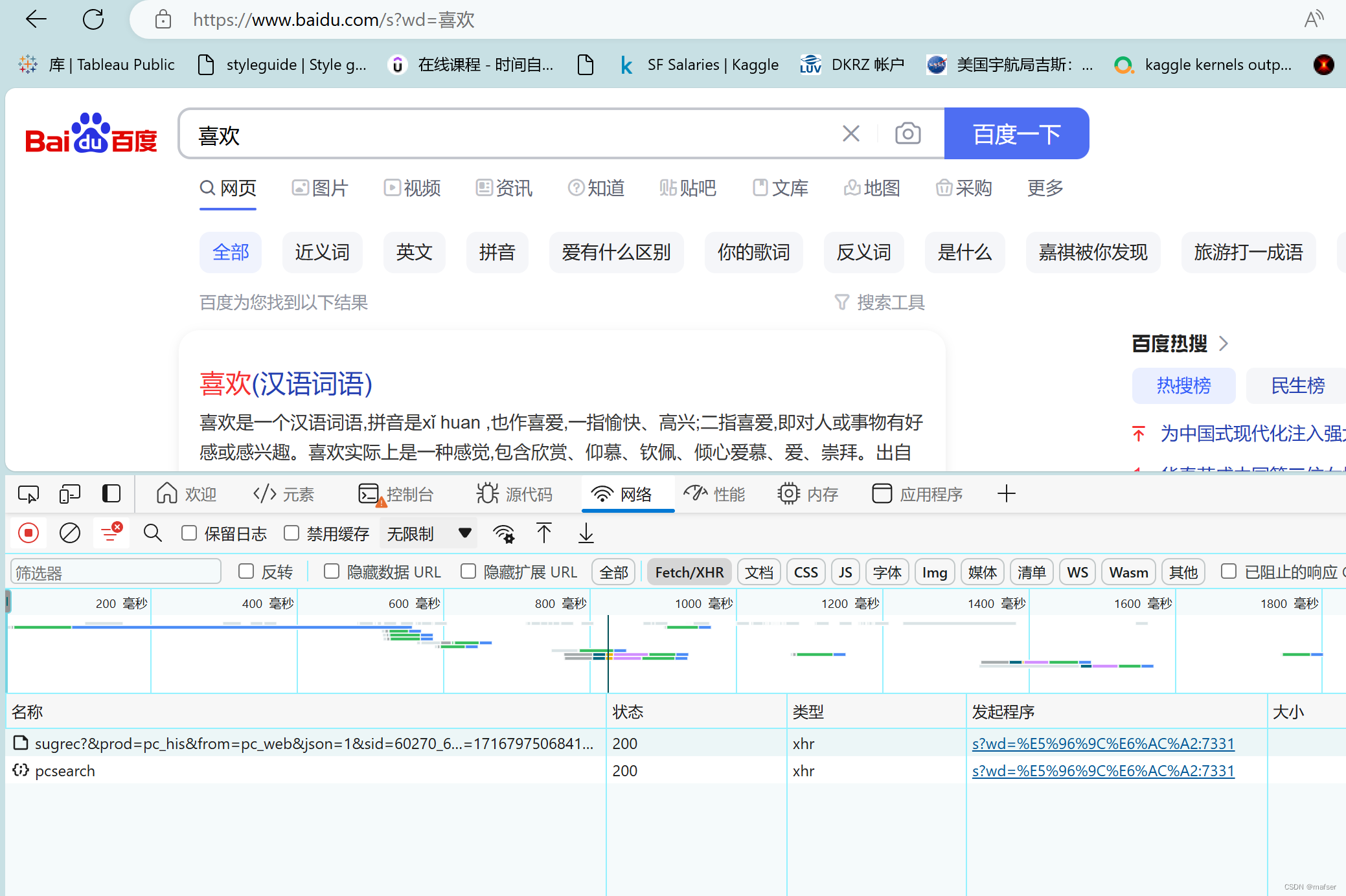
二、url拼接出问题,解决办法
当 response = requests.get(url=url,params=param,headers=headers) 中无法出现正确的地址时
采用:
#!/usr/bin/env python
# -*- coding: utf-8 -*-
import requests
rom urllib.parse import urljoin, quote, urlencodeif __name__ =="__main__":headers={"User-Agent":"填你自己的"}base_url = "https://www.baidu.com/"# 拼接URLurl = urljoin(base_url, 's?wd=')#检查URL是否拼接正确print(url)# 动态查询kw = input('enter a word:')url=url+kw# response = requests.get(url=url,params=param,headers=headers)response = requests.get(url=url, headers=headers)#print(response.status_code) #检查response是否查询成功 200(成果)page_text = response.textfilename =kw+'.html'with open(filename,'w',encoding='utf-8') as fp:fp.write(page_text)print(filename,'over!')
一点点的拓展关于json:
不知道json代码哪里出问题了,可以采用以下的代码:
try:dic_obj = response.json()except json.JSONDecodeError:print('JSON解析错误,响应内容可能不是有效的JSON格式')except requests.exceptions.RequestException as e:print(f'请求发生错误:{e}')else:print(dic_obj)fileName=kw+'.json'fp = open('fileName','w',encoding='utf-8')json.dump(dic_obj,fp=fp,ensure_ascii=False)print('over!')






![[论文笔记]Chain-of-Thought Prompting Elicits Reasoning in Large Language Models](https://img-blog.csdnimg.cn/img_convert/f07ca721596ddecc95cfeabc075ca37f.png)
![[数据集][目标检测]伤口检测数据集VOC+YOLO格式2760张1类别](https://img-blog.csdnimg.cn/direct/e8183c297607446ca74905b3b0c70fb6.png)