思维导图
石墨文档:https://shimo.im/mindmaps/NJkbnZV0ePINXzkR
一、SQL的执行

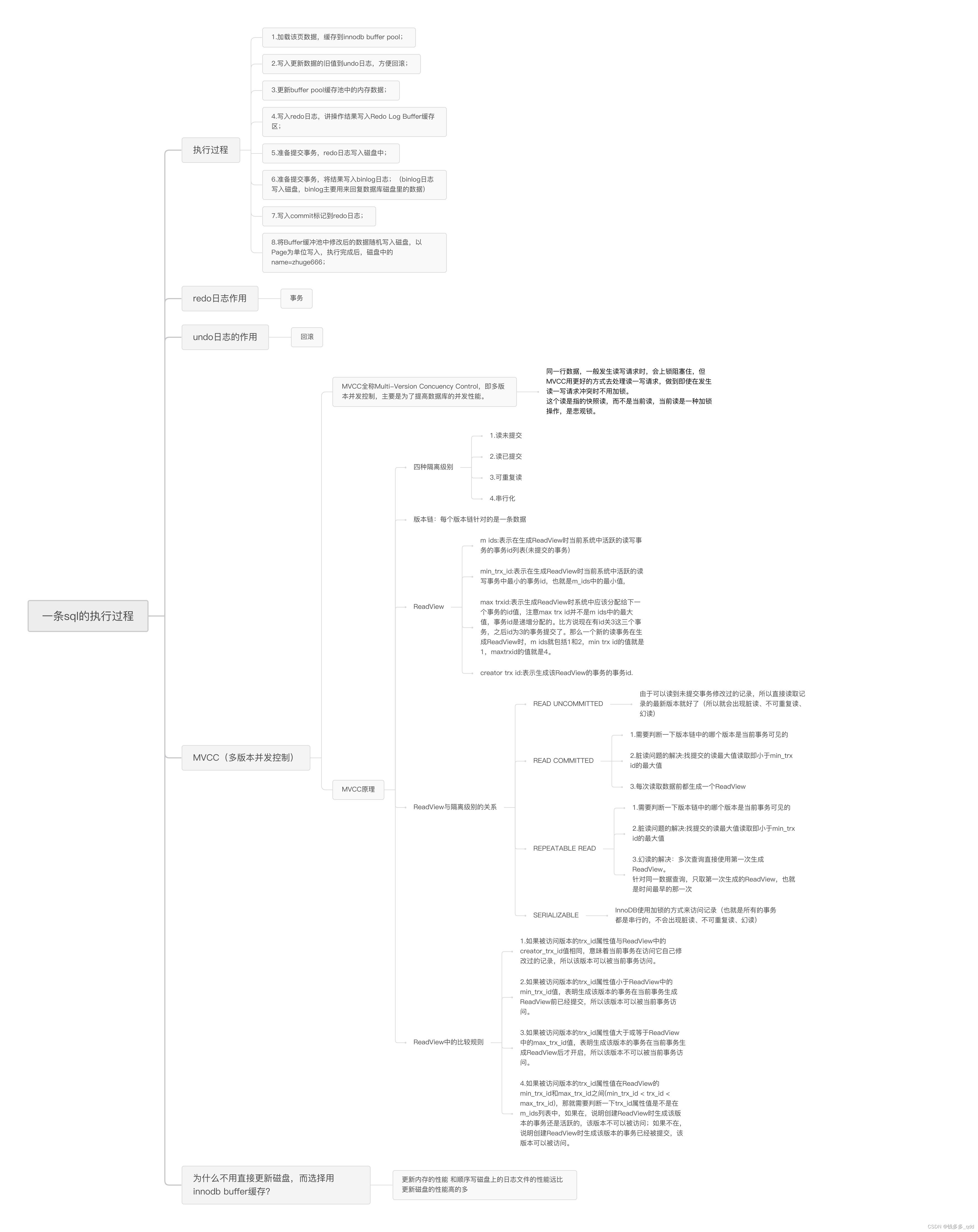
执行过程:
- 加载缓存数据,加载id为1的记录所在的整页数据(相当于索引树的一个结点,16KB);
- 写入更新数据的旧值到undo日志中,方便回滚;
- 执行器更新BufferPool缓存池中的内存数据;
- 写入redo日志,将操作结果写入Redo Log Buffer缓冲区;
- 准备提交事务,redo日志写入磁盘中;
- 准备提交事务,将结果写入binlog日志,binlog日志写入磁盘,binlog主要用来恢复数据库磁盘里的数据;
- 写入commit标记到redo日志文件里,提交事务完成,该标记为了保证事务提交后的redo与binlog数据一致;
- 将Buffer Pool缓冲池中修改后的数据随机写入磁盘,以Page为单位写入,执行完后,磁盘中的name=zhuge666;
1.1 redo日志作用
如果事务提交成功,buffer pool里的数据还没吸入磁盘,此时系统宕机,可以用redo日志里的数据恢复buffer pool里的缓存数据,再重新写入磁盘;
1.2 undo日志作用
当事务更新完数据后,执行其它操作发生错误,导致事务执行失败,MySQL会将undo日志里最新的旧值回滚,保证数据一致性;
undo日志更详细介绍的介绍在:1.3 MVCC
1.3 MVCC
参考这篇文章:MVCC是什么?有何用?原理是什么?
1.4 为什么Mysql不能直接更新磁盘上的数据而且设置这么一套复杂的机制来执行SQL了?
因为来一个请求就直接对磁盘文件进行随机读写,然后更新磁盘文件里的数据性能相当查;
因为磁盘随机读写的性能是相当差的,所以直接更新磁盘文件是不能让数据库抗住高并发请求的。
MySQL这套机制看起来复杂,但他保证每个请求都是更新内存(BufferPool),然后顺序写日志文件,同时还能保证各种异常情况下的数据一致性;
更新内存的性能 和顺序写磁盘上的日志文件的性能远比更新磁盘的性能高的多。