目录
1.前言
2.hadoop 1.X的缺点和优化方向
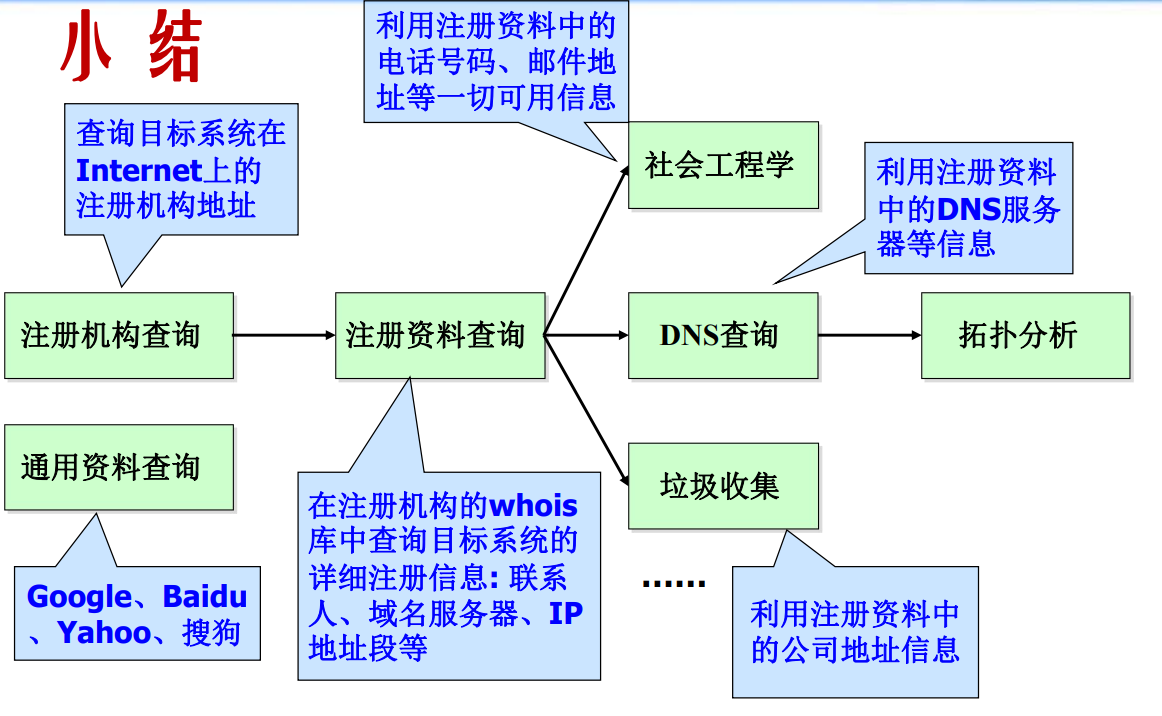
3.解决NameNode的局限性
3.1.Hadoop HA
3.2.Haddop federation
4.yarn
5.周边组件
1.前言
本文是作者大数据系列中的一文,专栏地址:
https://blog.csdn.net/joker_zjn/category_12631789.html?spm=1001.2014.3001.5482
前文中我们从大数据的概论入手、分别聊了分布式文件系统的鼻祖GFS、分布式数据库的鼻祖Big Table、hadoop中的分布式文件系统HDFS、计算引擎Map Reduce、分布式数据库HBase。以上关于Hadoop的内容都是基于hadoop 1.X来聊的,Hadoop 1.X作为推出的第一个版本经过实战的检验发现还有诸多很需要优化的地方,本文就会来聊一下hadoop 2.X中对hadoop 1.X做了哪些优化。
2.hadoop 1.X的缺点和优化方向
hadoop1.0版本有几个待优化点:
-
NameNode是单节点的,存储上会有上限,容错上也会有局限性。
-
抽象层次低,需要大量的底层操作,即大量指令操作、大量代码编写。
-
计算引擎有局限性限
-
mapreduce能解决的问题有限
-
资源利用率地,由于没有很好的资源调度机制,而是粗略的将不同作业之间的资源直接相互独立开来,会导致各个job的资源只有自己能用,就算已经到了reduce阶段,自身的map资源也不能被别的job用到。
-
效率很低,MapReduce的单个计算任务的结果会存入HDFS中,也就是落了磁盘,因此如果是进行迭代计算(上一个job的输出是下一个job的输入)就要来回读HDFS。
-
hadoop在2.X版本中对这些问题从两方便做了优化:
-
优化自身的核心组件HDFS、MapReduce
-
引入其它周边的配套组件,扩展能力
首先是对核心组件的优化:
| 组件 | 1.X存在的问题 | 2.X的改进 |
| HDFS | nameNode存在单点失效问题 | 引入HDFS HA,对nameNode进行热备 |
| HDFS | 命名空间单一无法实现资源隔离 | 引入HDFS Federation,分出多个命名空间 |
| MapReduce | 资源管理、调度效率低 | 引入单独的资源管理框架YARN |
其次是扩展了周边组件,增强了能力:
| 组件 | 功能 | 所解决的问题 |
| pig | 用户只需要编写少量语句就能完成计算任务,省去MapReduce的代码编写 | 抽象层次低 |
| spark | 基于内存的计算框架,比mapreduce快,有良好实时性,迭代计算快 | 计算任务延迟高,不适合迭代计算 |
| Tez | 支持DAG作业,对作业操作进行重新分解和组合,减少不必要的操作,相当于对Map Reduce进行过程精简 | 不同Map Reduce之间存在重复此操作,拉低了效率 |
3.解决NameNode的局限性
3.1.Hadoop HA
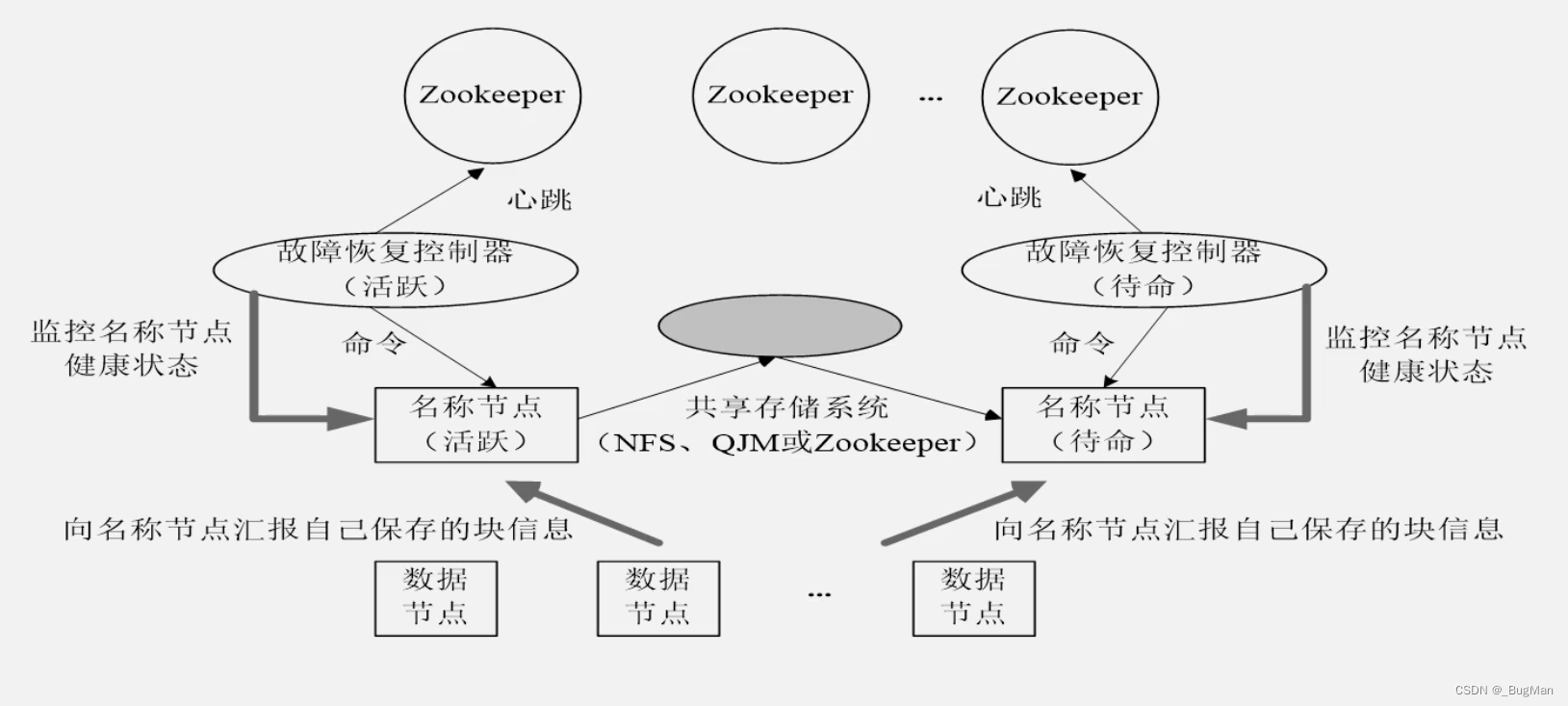
Hadoop HA属于一种架构,是对Hadoop的水平扩展,用来解决NameNode没有热备份的问题。
HA架构中将NameNode分为活跃和待命两种状态,活跃和待命节点通过共享的存储系统来同步元数据信息。就是说活跃的把元数据信息实时放到共享存储中,待命节点自己去拿,从而做到同步。
至于选哪个作为活跃名称节点对外暴露,交给zookeeper就好。
3.2.Haddop federation
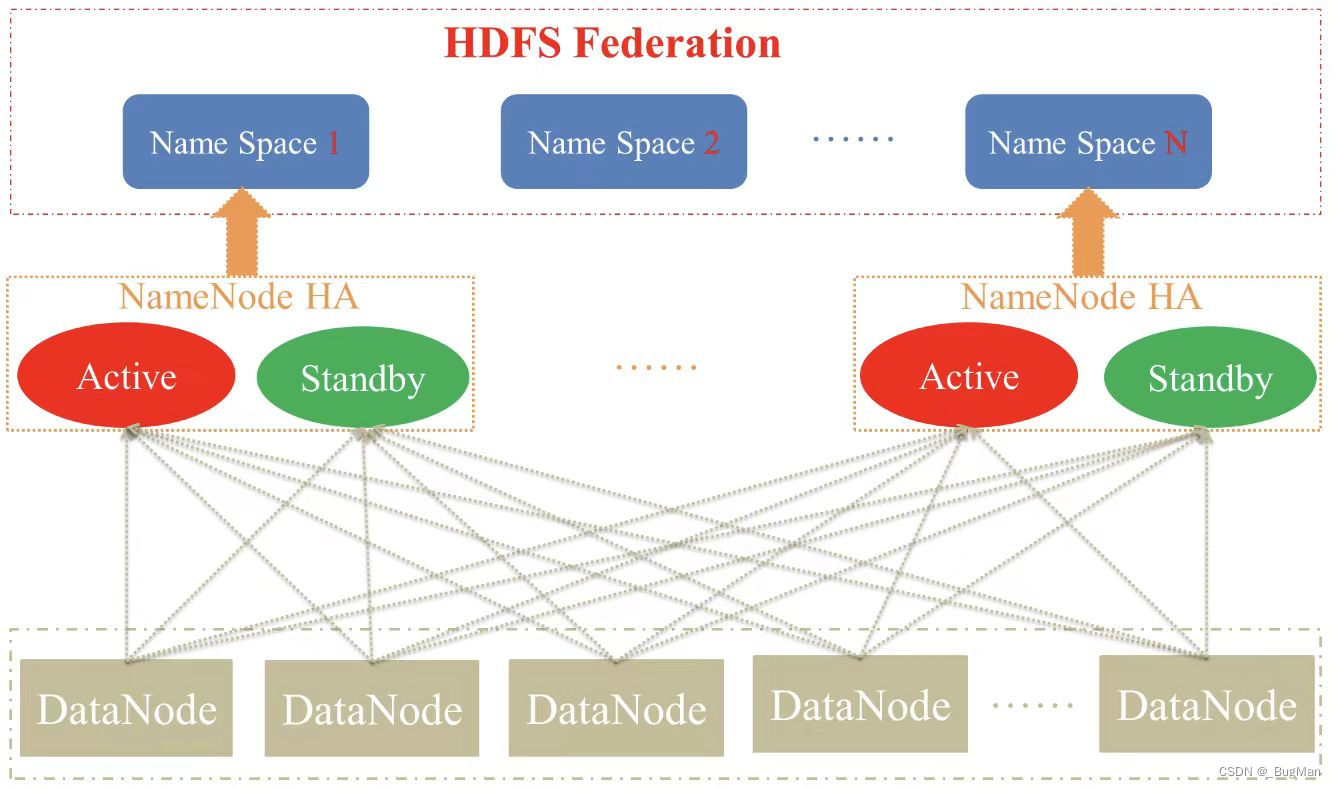
Haddop federation属于一种架构,是对Hadoop的垂直扩展,用来解决单节点存储上限的问题,如果名称节点是单节点那么内存会很有局限性,毕竟要装入内存的元数据很多。
Hadoop federation将名称节点切分为不同的命名空间(其实就是文件系统路径下的不同的文件夹),一个名称上面有一个或者多个命名空间,不同的名称节点上管理不同的命名空间。
至于客户端怎么访问到自己要的命名空间喃?会在客户端本地提前配置好映射,指定客户端去访问哪些名称节点。
4.yarn
yarn是hadoop 2.X开始引入的资源调度、监控框架。
在hadoop 1.X中,Map Reduce干的活儿很杂,既是个资源调度框架,要负责资源调度、任务监控、还是个计算框架,要负责具体的计算。作为资源调度框架来说,hadoop 1.X的设计上不太合理,所以hadoop在2.x的时候借着重构资源调度框架的时候,将资源调度单独拆了出来做成了新的组件——yarn。这样拆之后在hadoop 2.X开始mapreduce就不再负责资源调度,而是一个纯计算框架。
hadoop 1.X的设计上哪里不合理:
全部资源管理、全部job的任务调度、全部job的任务监控都要由jobtracker来负责,压力太大了。就像公司管理一样,所有员工直接对接老板,老板肯定扛不住,分级对接才是正解,老板就能减轻很多压力。每一级对接自己的管理层,管理层再统一对接老板yarn的设计思想就是这种分级管理的思想。
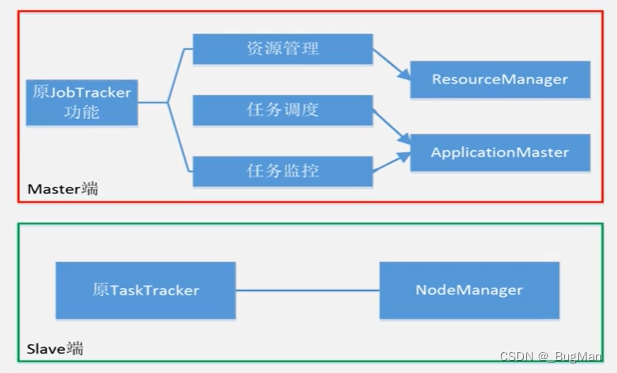
yarn有三大核心组件:
- Resource Manager,负责资源管理
- Application Master,负责任务调度、任务监控
- NodeManager,在具体节点上负责与前两者通信
Map Reduce 1.X与yarn的组件类比:
三大核心组件如何配合工作:
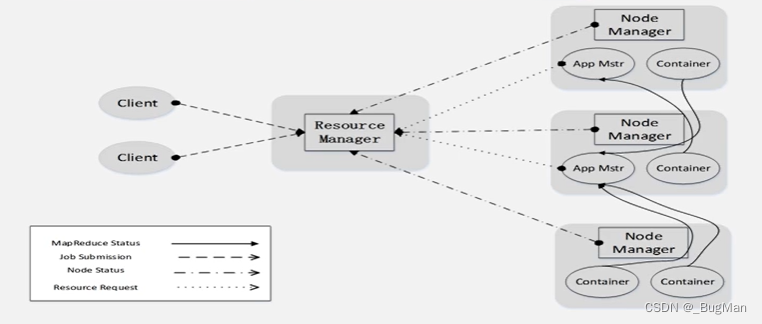
- ResourceManager (RM):
- RM 是全局的资源调度器,负责整个集群的资源管理和分配。
- 它维护着集群的全局视图,了解所有节点的状态和可用资源。
- 当应用程序提交时,RM 启动一个 ApplicationMaster 进程。
- RM 与各个 NodeManager 通信以获取和更新节点状态。
- ApplicationMaster (AM):
- AM 是每个应用程序的代理,负责应用程序的执行逻辑和资源请求。
- 应用程序启动后,AM 会向 RM 申请资源(如内存、CPU 核心等)来运行任务。
- AM 和 RM 通过一个协商过程来获取资源,这个过程可能是基于优先级或公平共享的策略。
- 一旦获得资源,AM 会将这些资源进一步划分为更小的单位,即 Containers。
- NodeManager (NM):
- NM 是每个节点上的代理,它负责管理该节点上的资源和容器实例。
- NM 向 RM 报告节点的资源使用情况和健康状况。
- 当 AM 请求资源时,RM 将资源分配给 NM,然后 NM 根据指示启动容器。
- NM 监控容器的生命周期,包括启动应用程序的任务,监控资源使用,以及在任务完成或失败时清理资源。
- Container:
- Container 是 YARN 中资源分配的基本单位,它包含了一定量的 CPU、内存和其他资源。
- AM 会将任务分解为多个小任务,并在多个 Container 中运行这些任务。
- AM 直接与 NM 通信来启动和停止 Container,以及监控任务的进度和状态。
5.周边组件
关于2.X中新引入的组件这里不做扩展,只是大概说一下引入了些什么东西、解决了些什么问题,后续聊到相关组建的时候会细聊。
2.X引入的周边组件主要是围绕封装操作和扩展计算引擎来的,追求用更方便的方式来访问存储和编写计算任务,以及支持更多类型的计算引擎来应对不同的场景。
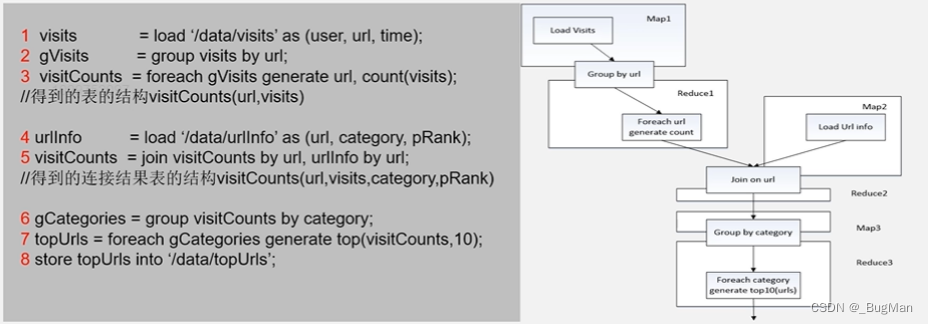
pig用pig latin语言来封装了Map Reduce,以便我们减少代码的编写:
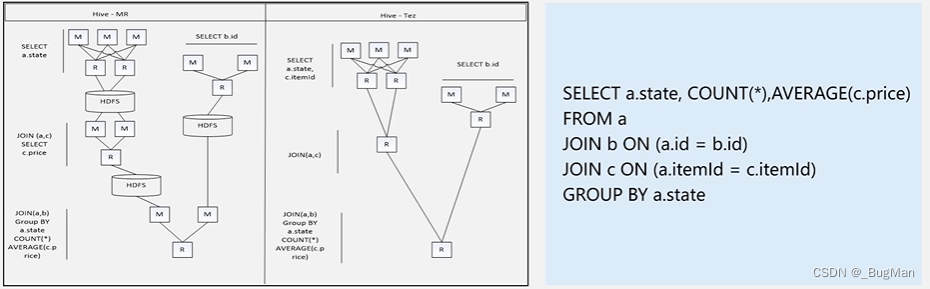
tez用DAG作业的方式来优化了Map Reduce过程,提高了Map Reduce的执行效率:
至于spark计算引擎,接下来的文章会详聊,敬请期待。