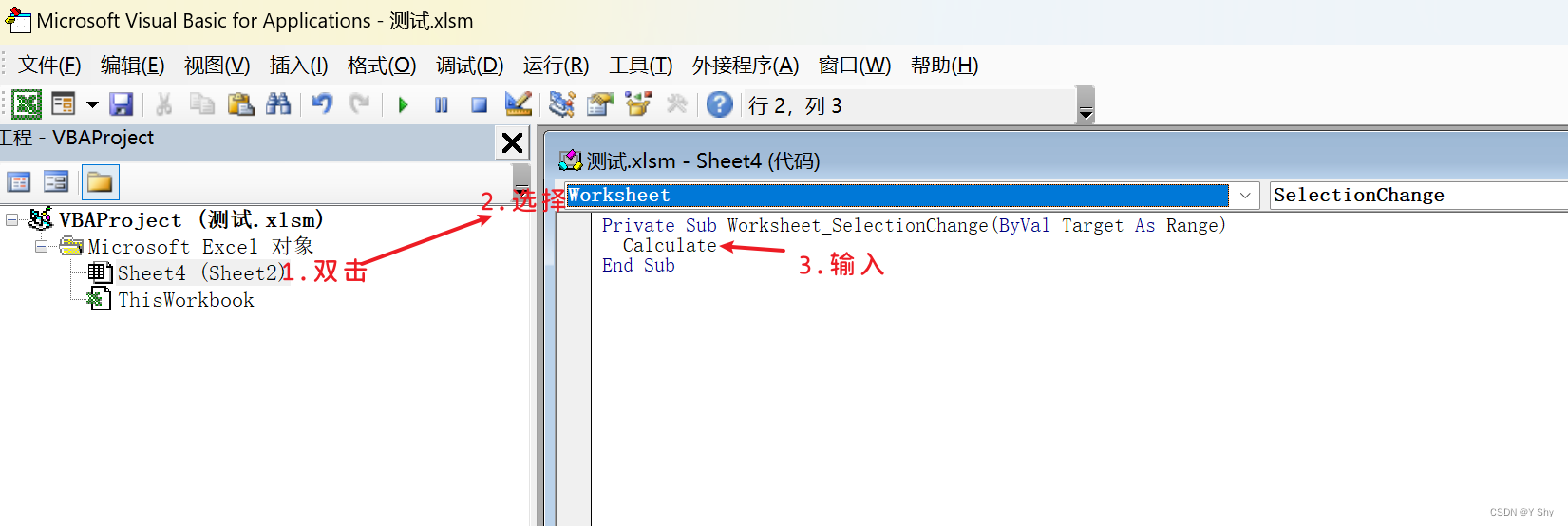
【框架地址】
https://github.com/THU-MIG/yolov10
【算法介绍】
今天为大家介绍的是 YOLOv10,这是由清华大学研究团队最新提出的,同样遵循 YOLO 系列设计原则,致力于打造实时端到端的高性能目标检测器。

方法
创新
- 双标签分配策略
众所周知,标签分配策略对于目标检测器来说是至关重要的。经过这几年的发展,前前后后也提出了许多的不同的方案,但归根结底还是围绕着正负样本去定义。通常,我们会认为与 GT 框的 IoU 大于给定阈值的便是正样本。
首先,回顾下经典的 YOLO 架构,其通过网格化的方式预定义数千个锚框(anchor),然后基于这些锚框进一步执行回归和分类任务。然而,实际场景中,我们所面临的目标其大小、长宽比、数量、位姿均各有所异,因此很难通过这种方式来提供一个完美的先验信息,尽管可以借助一些方法如 kmeans 聚类来获得一个次优的结果。
于是乎,基于 anchor-free 的目标检测器被提出来了。其标签分配策略被简化成了从网格点到目标框中心或者角点的距离。遗憾的是,无论是 anchor-based 的“框分配”策略还是 anchor-free 的“点分配”策略,其始终会面临一个 many-to-one 的窘境,即对于一个 GT 框来说,会存在多个正样本与之对应。
这便意味着 NMS 成为了一种必不可少的手段,以避免产生冗余检测框。然而,引入 NMS 一方面会增加耗时,同时也会引入一些问题,譬如当 IoU 设置不恰当时会导致一些高置信度的正确目标框被过滤掉(密集场景下)。
当然,针对这个问题,后面也提出了不少解决方案。如最容易想到的就是 two-stage 模型的 one-to-one 即一对一分配策略,我们强制只将一个 GT 框分配给一个正样本,这样就可以避免引入 NMS,可惜效率方面是个极大的劣势。
又比如 One-Net 提出的最小代价分配(Minimum Cost Assignment),即于每个 GT,仅将一个最小代价样本分配为正样本,其它均为负样本,该方法不涉及手动制定的启发式规则或者复杂的二分图匹配。这里代价是指样本与真值之间的分类代价和位置代价的总和。

另一方面,诸如 DETR 系列的检测器,其直接利用 Transformer 的全局建模能力,将目标检测看成是一个集合预测的问题。为了实现端到端的检测,其使用的标签分配策略是二分匹配,使得一个 GT 只能分配到一个正样本。

由于篇(知)幅(识)有(盲)限(区),今天我们就讲到这。回到今天的主角,YOLOv10 的一大创新点便是引入了一种双重标签分配策略,其核心思想便是在训练阶段使用一对多的检测头提供更多的正样本来丰富模型的训练;而在推理阶段则通过梯度截断的方式,切换为一对一的检测头,如此一来便不在需要 NMS 后处理,在保持性能的同时减少了推理开销。
原理其实不难,大家可以看下代码理解下:
#https://github.com/THU-MIG/yolov10/blob/main/ultralytics/nn/modules/head.py
class v10Detect(Detect):max_det = -1def __init__(self, nc=80, ch=()):super().__init__(nc, ch)c3 = max(ch[0], min(self.nc, 100)) # channelsself.cv3 = nn.ModuleList(nn.Sequential(nn.Sequential(Conv(x, x, 3, g=x), Conv(x, c3, 1)), \nn.Sequential(Conv(c3, c3, 3, g=c3), Conv(c3, c3, 1)), \nn.Conv2d(c3, self.nc, 1)) for i, x in enumerate(ch))self.one2one_cv2 = copy.deepcopy(self.cv2)self.one2one_cv3 = copy.deepcopy(self.cv3)def forward(self, x):one2one = self.forward_feat([xi.detach() for xi in x], self.one2one_cv2, self.one2one_cv3)if not self.export:one2many = super().forward(x)if not self.training:one2one = self.inference(one2one)if not self.export:return {"one2many": one2many, "one2one": one2one}else:assert(self.max_det != -1)boxes, scores, labels = ops.v10postprocess(one2one.permute(0, 2, 1), self.max_det, self.nc)return torch.cat([boxes, scores.unsqueeze(-1), labels.unsqueeze(-1)], dim=-1)else:return {"one2many": one2many, "one2one": one2one}def bias_init(self):super().bias_init()"""Initialize Detect() biases, WARNING: requires stride availability."""m = self # self.model[-1] # Detect() module# cf = torch.bincount(torch.tensor(np.concatenate(dataset.labels, 0)[:, 0]).long(), minlength=nc) + 1# ncf = math.log(0.6 / (m.nc - 0.999999)) if cf is None else torch.log(cf / cf.sum()) # nominal class frequencyfor a, b, s in zip(m.one2one_cv2, m.one2one_cv3, m.stride): # froma[-1].bias.data[:] = 1.0 # boxb[-1].bias.data[: m.nc] = math.log(5 / m.nc / (640 / s) ** 2) # cls (.01 objects, 80 classes, 640 img)
- 架构改进

- Backbone & Neck:使用了先进的结构如 CSPNet 作为骨干网络,和 PAN 作为颈部网络,优化了特征提取和多尺度特征融合。
- 大卷积核与分区自注意力:这些技术用于增强模型从大范围上下文中学习的能力,提高检测准确性而不显著增加计算成本。
- 整体效率:引入空间-通道解耦下采样和基于秩引导的模块设计,减少计算冗余,提高整体模型效率。
这块没啥好讲的,大家看一眼框架图便清楚了,懂的都懂。:)
性能
YOLOv10 在各种模型规模上显示了显著的性能和效率改进。关键比较包括:
- YOLOv10-S vs. RT-DETR-R18:YOLOv10-S 的速度提高了 1.8 倍,同时在 COCO 数据集上保持类似的平均精度(AP),参数和 FLOPs 分别减少了 2.8 倍。
- YOLOv10-B vs. YOLOv9-C:YOLOv10-B 的延迟减少了 46%,参数减少了 25%,而性能相当。
扩展性
| Model | Test Size | #Params | FLOPs | APval | Latency |
|---|---|---|---|---|---|
| YOLOv10-N | 640 | 2.3M | 6.7G | 38.5% | 1.84ms |
| YOLOv10-S | 640 | 7.2M | 21.6G | 46.3% | 2.49ms |
| YOLOv10-M | 640 | 15.4M | 59.1G | 51.1% | 4.74ms |
| YOLOv10-B | 640 | 19.1M | 92.0G | 52.5% | 5.74ms |
| YOLOv10-L | 640 | 24.4M | 120.3G | 53.2% | 7.28ms |
| YOLOv10-X | 640 | 29.5M | 160.4G | 54.4% | 10.70ms |
YOLOv10 提供了多个模型规模(N、S、M、B、L、X),允许用户根据性能和资源约束选择最适合的模型。这种可扩展性确保了 YOLOv10 能够有效应用于各种实时检测任务,从移动设备上的轻量级应用到需要高精度的复杂任务。
实验

这里重点看下表3,可以看出,采用一对多的检测头性能最好(提供了更丰富的正样本监督信号),但延迟也高了许多(需要 NMS 做后处理);另外方面,一对一的检测头则性能会稍微下降,但延迟却低了不少;最终综合利用两者的优势能达到一个最优的精度-速度折衷。
【效果展示】

【部分实现代码】
using System;
using System.Collections.Generic;
using System.ComponentModel;
using System.Data;
using System.Diagnostics;
using System.Drawing;
using System.Linq;
using System.Text;
using System.Threading.Tasks;
using System.Windows.Forms;
using OpenCvSharp;namespace FIRC
{public partial class Form1 : Form{Mat src = new Mat();Yolov10Manager ym = new Yolov10Manager();public Form1(){InitializeComponent();}private void button1_Click(object sender, EventArgs e){OpenFileDialog openFileDialog = new OpenFileDialog();openFileDialog.Filter = "图文件(*.*)|*.jpg;*.png;*.jpeg;*.bmp";openFileDialog.RestoreDirectory = true;openFileDialog.Multiselect = false;if (openFileDialog.ShowDialog() == DialogResult.OK){src = Cv2.ImRead(openFileDialog.FileName);pictureBox1.Image = OpenCvSharp.Extensions.BitmapConverter.ToBitmap(src);}}private void button2_Click(object sender, EventArgs e){if(pictureBox1.Image==null){return;}Stopwatch sw = new Stopwatch();sw.Start();var result = ym.Inference(src);sw.Stop();this.Text = "耗时" + sw.Elapsed.TotalSeconds + "秒";var resultMat = ym.DrawImage(result,src);pictureBox2.Image= OpenCvSharp.Extensions.BitmapConverter.ToBitmap(resultMat); //Mat转Bitmap}private void Form1_Load(object sender, EventArgs e){ym.LoadWeights(Application.StartupPath+ "\\weights\\yolov10n.onnx", Application.StartupPath + "\\weights\\labels.txt");}private void btn_video_Click(object sender, EventArgs e){var detector = new Yolov10Manager();detector.LoadWeights(Application.StartupPath + "\\weights\\yolov10n.onnx", Application.StartupPath + "\\weights\\labels.txt");VideoCapture capture = new VideoCapture(0);if (!capture.IsOpened()){Console.WriteLine("video not open!");return;}Mat frame = new Mat();var sw = new Stopwatch();int fps = 0;while (true){capture.Read(frame);if (frame.Empty()){Console.WriteLine("data is empty!");break;}sw.Start();var result = detector.Inference(frame);var resultImg = detector.DrawImage(result,frame);sw.Stop();fps = Convert.ToInt32(1 / sw.Elapsed.TotalSeconds);sw.Reset();Cv2.PutText(resultImg, "FPS=" + fps, new OpenCvSharp.Point(30, 30), HersheyFonts.HersheyComplex, 1.0, new Scalar(255, 0, 0), 3);//显示结果Cv2.ImShow("Result", resultImg);int key = Cv2.WaitKey(10);if (key == 27)break;}capture.Release();}}
}
【视频演示】
C# winform部署yolov10的onnx模型_哔哩哔哩_bilibiliC#部署yolov10官方onnx模型,首先转成Onnx模型然后即可调用。测试环境:vs2019netframework4.7.2onnxruntime1.16.3opencvsharp==4.8.0, 视频播放量 1、弹幕量 0、点赞数 0、投硬币枚数 0、收藏人数 0、转发人数 0, 视频作者 未来自主研究中心, 作者简介 未来自主研究中心,相关视频:我的开源代码居然被盗去卖钱?AI文字搜图搜视频,语义搜索新版整合包发布!,yolov10 tensorrt C++ 推理!全网首发!,C++使用纯opencv部署yolov9的onnx模型,重生紫薇之:容嬷嬷带我了解yolo v10! ----人工智能/计算机视觉/yolo,起猛了,一觉起来看到YOLOv10都发布了!我看看是谁还在研究yolov123456789的,C#YOLO工业滑轨螺丝缺失检测~示例,将yolov5-6.2封装成一个类几行代码完成语义分割任务,毕设项目—基于最新YOLOv10+ByteTrack+PaddleOCR实现交通状态分析 (功能:目标检测、轨迹跟踪、车牌检测、车牌号识别、单目测速及目标计数),labelme json转yolo工具用于目标检测训练数据集使用教程,将yolov8封装成一个类几行代码完成语义分割任务![]() https://www.bilibili.com/video/BV111421173R/?vd_source=989ae2b903ea1b5acebbe2c4c4a635ee
https://www.bilibili.com/video/BV111421173R/?vd_source=989ae2b903ea1b5acebbe2c4c4a635ee
【测试环境】
vs2019,netframework4.7.2,onnxruntime1.16.3,opencvsharp4.8.0
【源码下载】
https://download.csdn.net/download/FL1623863129/89366968
【参考文献】
1 https://zhuanlan.zhihu.com/p/699842844