目录
写在开头
一、DNN的搭建
问题描述与数据集
神经网络搭建
模型训练
模型评估
模型复用
二、手写数字识别
任务描述
数据集
神经网络搭建
模型训练
模型评估
写在最后
写在开头
本文将介绍如何使用PyTorch框架搭建深度神经网络模型。实现模型的搭建、模型训练、测试、网络的保存等。实现机器学习领域的Hello world——手写数字识别。本文是基于B站爆肝杰哥的讲解基础下进行的总结,特别感谢杰哥的讲解,其视频如下:
Python深度学习:安装Anaconda、PyTorch(GPU版)库与PyCharm_哔哩哔哩_bilibili
使用的PyTorch为1.12.0版本,Numpy为1.21版本,相近的版本语法差异很小。有关数组的数据结构教程、神经网络的基本原理(前向传播/反向传播)和神经网络作为“函数模拟器”直观感受,详见本专栏的前两篇文章,链接如下:
【深度学习基础】NumPy数组库的使用-CSDN博客
【深度学习基础】用PyTorch从零开始搭建DNN深度神经网络-CSDN博客
在本专栏的上一篇文章中,我们手动搭建了神经网络,并通过反向传播对参数final_bias进行了优化,上一篇博客中提到的在神经网络的类中,前向传播方法如下:
def forward(self, input):input_to_top_relu = input * self.w00 + self.b00top_relu_output = F.relu(input_to_top_relu)scaled_top_relu_output = top_relu_output * self.w01input_to_bottom_relu = input * self.w10 + self.b10bottom_relu_output = F.relu(input_to_bottom_relu)scaled_bottom_relu_output = bottom_relu_output * self.w11input_to_final_relu = scaled_top_relu_output + scaled_bottom_relu_output + self.final_biasoutput = F.relu(input_to_final_relu)return output然而这种方法在实现前向传播计算输出值的过程过于繁琐,需要人工的写很多公式以搭建神经网络,可扩展性很差。如果是有很多层数的大型神经网络,难道也要这样逐个公式的手工摆出吗?实际上,PyTorch封装了一些可以直接搭建网络的方法,后文中我们会具体实现,非常便捷。下面我们就用PyTorch搭建DNN,实现一个简单的分类预测问题。
一、DNN的搭建
使用PyTorch搭建的神经网络需要引入一些库,如下所示:
import torch
import torch.nn as nn
import matplotlib.pyplot as plt
# 下面这几行用于展示高清图,在jupter notebook中最好加上,本地运行代码也可以不加
%matplotlib inline
from matplotlib_inline import backend_inline
backend_inline.set_matplotlib_formats('svg')问题描述与数据集
本节我们以一个简易的分类预测问题为例,通过使用PyTorch搭建神经网络,实现模型的训练、测试、模型的保存等。一共有三个输入特征X1,X2,X3,预测输出特征Y1,Y2,Y3,其中Y1,Y2,Y3为对应的类别。设X_sum = X1 + X2 + X3,数据集中输入特征满足以下分布:
1.X1,X2,X3相互独立,且服从在范围(0-1)的均匀分布;
2.当X_sum < 1 时,Y1=1,否则Y1=0;
3.当1<X_sum < 2 时,Y2=1,否则Y2=0;
2.当X_sum > 2时,Y3=1,否则Y3=0。
显然,输出特征组合后是一个One-Hot编码,这是一个分类问题。
特别注意,如上的X1,X2,X3的分布是我们创建数据集自定义的规则,对于神经网络而言,神经网络起初并不知道这些分布,需要通过对数据集的学习(模型训练),去尽可能拟合出这些分布,以实现分类预测。
通过以下代码可以实现数据集的构建,数据集一共有10000个样本,每个样本有3个输入特征和3个输出特征(标签),我们针对每个输入特征,生成0-1均匀分布的随机数,构成10000行1列的矩阵X1,X2,X3,然后根据数据集特征的分布构建其标签Y1,Y2,Y3,特别注意,.float()方法用于将布尔型张量转换为浮点型,代码如下:
# 生成数据集
X1 = torch.rand(10000,1)
X2 = torch.rand(10000,1)
X3 = torch.rand(10000,1)
Y1 = ((X1+X2+X3)<1).float()
Y2 = (((X1+X2+X3)>1) & ((X1+X2+X3)<2)).float()
Y3 = (X1+X2+X3>2).float()
Data = torch.cat([X1,X2,X3,Y1,Y2,Y3], axis=1) #整合数据集
Data = Data.to('cuda:0') # 将数据集迁移到GPU上最后我们可以看一下这个数据集的形状和内容:
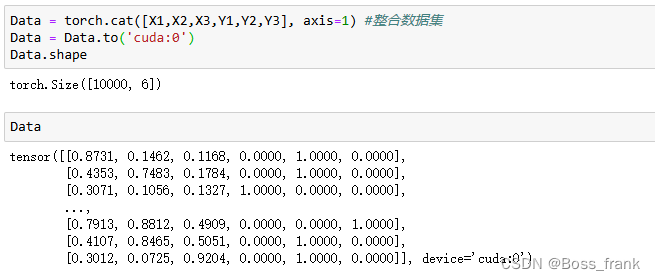
确实是10000*6的张量形式,前三列为输入特征,后三列为真实情况的分类(One-Hot编码)。下面我们划分数据集为训练集和测试集。7000:3000即可,代码如下:
# 划分训练集和测试集
train_size = int(len(Data)*0.7) # 训练集大小
test_size = len(Data) - train_size # 测试集大小
Data = Data[torch.randperm(Data.size(0)), :] #打乱数据集
train_Data = Data[:train_size, :]
test_Data = Data[train_size:, :]这段基本上是固定的代码,打乱数据集也有助于模型训练。
神经网络搭建
接下来我们进入正题,用PyTorch搭建神经网络。我们搭建的神经网络以nn.Module作为父类,直接继承父类的方法和属性,nn.Module中已经包含了网络各个层的定义。用__init__方法作为构造函数,构造自己的神经网络结构, forward方法用于将输入数据进行前向传播。反向传播无需我们再写代码实现,因为张量可以自动计算梯度。搭建DNN的代码如下:
class DNN(nn.Module):def __init__(self):'''搭建神经网络的各层'''super(DNN, self).__init__() # 初始化父类self.net = nn.Sequential(nn.Linear(3, 5), nn.ReLU(),nn.Linear(5, 5), nn.ReLU(),nn.Linear(5, 5), nn.ReLU(),nn.Linear(5, 3))def forward(self, inputx):'''前向传播'''outputy = self.net(inputx) #从输入到输出return outputy # 返回输出结果这段代码非常简洁,我们用nn.Sequential()方法按顺序搭建了神经网络的4个全连接层,除了输出层外,剩下的每层(即隐藏层)后都使用了ReLU作为激活函数,用于引入非线性。特别注意每一层的神经元个数分别为(3,5,5,5,3),其中最开始的3表示输入层的三个神经元,这是因为有3个输入特征,同理,最后的3表示输出层的三个神经元,由输出特征的数量(3个)决定。至于隐藏层的个数和隐藏层中的神经元个数,这些称之为超参数,可由读者自行决定。
接下来我们创建网络的实例:
model = DNN().to('cuda:0') #创建子类实例,并搬到GPU上可以直接在jupter notebook上查看以下我们实例的模型model:

如上图所示,显示了每一层的形式,输入特征和输出特征分别有多少个(通常我们不把单个激活函数称之为“一层”,不过这里显示单独把ReLU列为一层,大家懂其含义就行,关键还是看Liner层的层数)。 如果想看一下每一层的参数具体是多少,也可以通过如下代码实现:
# 查看内部参数(非必要)
for name, param in model.named_parameters():print(f"参数:{name}\n形状:{param.shape}\n数值:{param}\n")比如这里我们可以看到在训练前,输入层的参数如下:

最后一层,即输出层的参数如下:

此时这些参数都还没经过训练(注意到requites_grad=True,变送这些需要进行反向传播的内部参数都打开了张量的自动梯度计算功能),参数都是随机的(实际上我们还可以对初始值进行一些操作,这里不展开讲了),读者可以等模型训练完毕之后,再度查看一下参数的情况,会发现参数大多发生了改变。
模型训练
网络已经搭建完毕,接下来我们就要开始训练网络了。首先设置损失函数和优化算法:
# 选择损失函数
loss_fn = nn.MSELoss()
# 选择优化算法
learning_rate = 0.01 # 设置学习率
optimizer = torch.optim.SGD(model.parameters(), lr=learning_rate) # 梯度下降法进行优化这里有关损失函数的选择和优化算法的具体选择我们不展开说,读者可以自行查阅资料,PyTorch 1.12版本的文档在torch.nn — PyTorch 1.12 documentation 。
接下来对网络进行训练,并作图画出损失函数的变化曲线:
# 训练网络
epochs = 1000
losses = [] #记录损失函数变化的列表# 对训练集划分输入输出
X = train_Data[:, :3] #前三列为输入特征
Y = train_Data[:, -3:] #后散列为输出特征for epoch in range(epochs):Pred = model(X) #进行一次前向传播loss = loss_fn(Pred, Y) #计算损失函数losses.append(loss.item()) # 记录损失函数的变化,loss是张量,用.item()降级为普通元素optimizer.zero_grad() # 清理上一轮滞留的梯度loss.backward() # 一次反向传播optimizer.step() # 优化内部参数# 作图表示损失函数的变化
Fig = plt.figure()
plt.plot(range(epochs), losses)
plt.ylabel('loss')
plt.xlabel('epochs')
plt.show()所有代码的注释已经标注出来,绘图结果如下,设置训练轮次是1000。显然,随着轮次epoch的增加,损失函数逐渐减小:
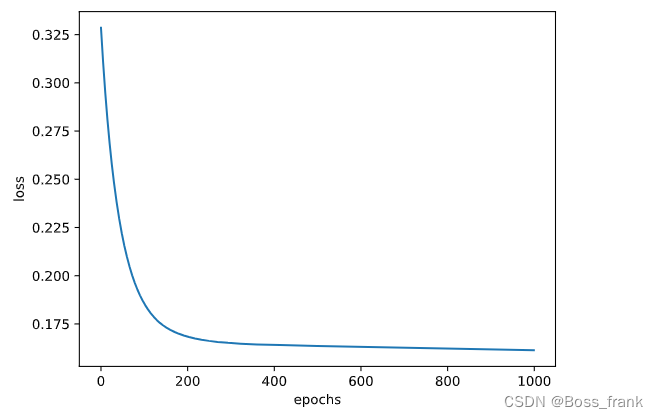
训练完成后,读者如果对于网络此时的内部参数感兴趣,也可以用上文的方法查看,相比训练前有所不同了。
模型评估
网络已经训练完成了。那么这个网络的性能如何呢?能不能实现由输入特征预测输出分类呢?这就需要用测试集进行模型评估了。测试的代码如下:
# 测试网络# 给测试集划分输入和输出
X_test = test_Data[:, :3] # 前三列为输入特征
Y_test = test_Data[:, -3:] # 后三列为输出特征with torch.no_grad(): # 只需要前向传播,该局部关闭梯度计算功能,降低内存开销,提高运算速度Pred = model(X_test) # 一次前向传播Pred[:, torch.argmax(Pred, axis=1)] = 1Pred[Pred!=1] = 0 # 这两行,用argmax函数,将预测值中的最大者置为1,然后再将不为1的地方置为0,相当于转换为one-hot编码的输出形式correct = torch.sum((Pred == Y_test).all(1)) #预测正确的样本数total = Y_test.size(0) # 所有样本数print(f"预测的正确的样本数{correct}\n测试集的精准度是:{100*correct/total}%")测试集共有3000条数据,也就是最终的预测输出会有一个3000行、3列的输出。当然,经过前向传播Pred = model(X_test)得到的结果应该是浮点型的张量,我们如何将其转换为One-hot编码的形式,并与真实情况进行对比呢?
这个问题也不难解决,我们使用argmax函数,将输出的三个特征中的最大值的位置设置为1,其他位置设置为0,就相当于将输出转换为了One-hot编码的形式,具体如下:
Pred = model(X_test) # 一次前向传播,此时Pred是3000*3的浮点型张量
接下来我们要将Pred转换为One-hot编码的形式。
torch.argmax(Pred, axis=1)可以求得此时Pred张量中,最大值所在列的位置。
然后通过代码 Pred[:, torch.argmax(Pred, axis=1)] = 1 将最大值所在列的位置的值置为1
再通过 Pred[Pred!=1] = 0 将其他位置的值置为0,就相当于实现了One-hot编码。
最终我们输出预测结果,如下:
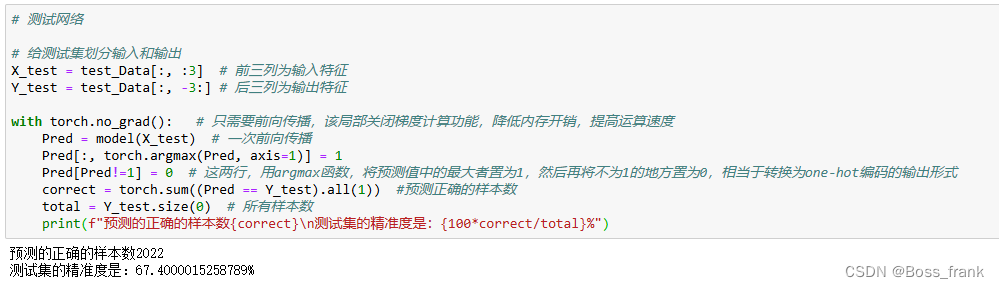
准确率大概是67%,说明我们这个模型还有不小的提升空间,可以调节网络的结构或使用更好的优化算法、使用小批量梯度下降的方式进行优化。
模型复用
最后还有个实际的问题,那就是我们训练好的网络如何保存?当在其他环境需要用到模型的时候,该如何迁移?这个只要用如下的代码就可以实现模型保存:
# 保存网络
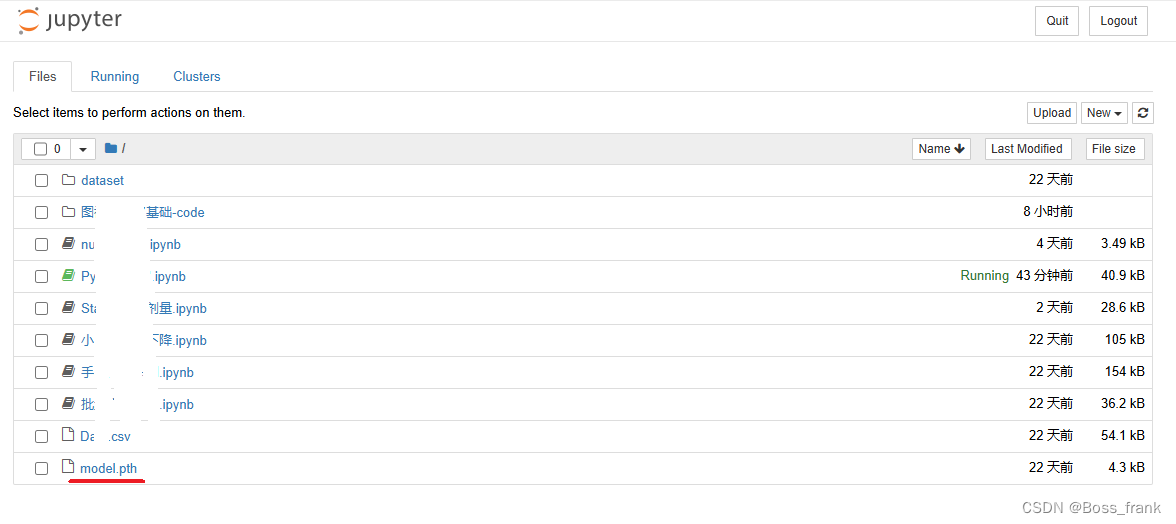
torch.save(model, 'model.pth')torch.save()函数的参数是,model表示要保存的模型(此处就是我们的model),’model.pth‘是保存模型的路径,此处我们就保存在当前文件夹下,运行次代码后,我们可以看到当前文件夹中出现了model.pth,即我们的模型:
接下来可以通过torch.load(模型路径)的方法将模型赋值给新网络:
# 把模型赋给新网络
new_model = torch.load('model.pth')# 用新网络测试
# 给测试集划分输入和输出
X_test = test_Data[:, :3] # 前三列为输入特征
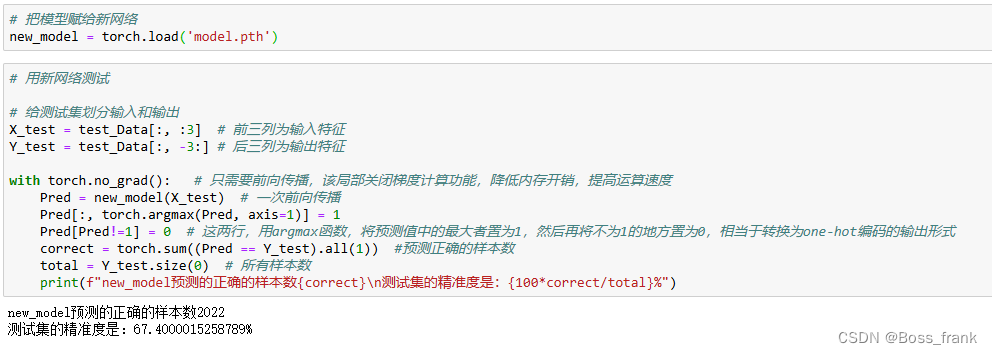
Y_test = test_Data[:, -3:] # 后三列为输出特征with torch.no_grad(): # 只需要前向传播,该局部关闭梯度计算功能,降低内存开销,提高运算速度Pred = new_model(X_test) # 一次前向传播Pred[:, torch.argmax(Pred, axis=1)] = 1Pred[Pred!=1] = 0 # 这两行,用argmax函数,将预测值中的最大者置为1,然后再将不为1的地方置为0,相当于转换为one-hot编码的输出形式correct = torch.sum((Pred == Y_test).all(1)) #预测正确的样本数total = Y_test.size(0) # 所有样本数print(f"new_model预测的正确的样本数{correct}\n测试集的精准度是:{100*correct/total}%")如下图所示,网络是一样的,测试集也一样,当然预测结果也一样啦:
最后给出完整的模型训练-测试代码:
import torch
import torch.nn as nn
import matplotlib.pyplot as plt
# 展示高清图
# from matplotlib_inline import backend_inline
# backend_inline.set_matplotlib_formats('svg')class DNN(nn.Module):def __init__(self):'''搭建神经网络的各层'''super(DNN, self).__init__()self.net = nn.Sequential(nn.Linear(3, 5), nn.ReLU(),nn.Linear(5, 5), nn.ReLU(),nn.Linear(5, 5), nn.ReLU(),nn.Linear(5, 3))def forward(self, inputx):'''前向传播'''outputy = self.net(inputx) # 从输入到输出return outputy# 生成数据集
X1 = torch.rand(10000,1)
X2 = torch.rand(10000,1)
X3 = torch.rand(10000,1)Y1 = ((X1+X2+X3)<1).float()
Y2 = (((X1+X2+X3)>1) & ((X1+X2+X3)<2)).float()
Y3 = (X1+X2+X3>2).float()
print(Y1.shape, Y2.shape, Y3.shape)Data = torch.cat([X1,X2,X3,Y1,Y2,Y3], axis=1) #整合数据集
Data = Data.to('cuda:0')# 划分训练集和测试集
train_size = int(len(Data)*0.7)
test_size = len(Data) - train_size
Data = Data[torch.randperm(Data.size(0)), :] #打乱数据集
train_Data = Data[:train_size, :]
test_Data = Data[train_size:, :]model = DNN().to('cuda:0') #创建子类实例,并搬到GPU上
# 查看内部参数(非必要)
for name, param in model.named_parameters():print(f"参数:{name}\n形状:{param.shape}\n数值:{param}\n")# 选择损失函数
loss_fn = nn.MSELoss()
# 选择优化算法
learning_rate = 0.01 # 设置学习率
optimizer = torch.optim.SGD(model.parameters(), lr=learning_rate)# 训练网络
epochs = 1000
losses = [] #记录损失函数变化的列表# 对训练集划分输入输出
X = train_Data[:, :3] #前三列为输入特征
Y = train_Data[:, -3:] #后散列为输出特征for epoch in range(epochs):Pred = model(X) #进行一次前向传播loss = loss_fn(Pred, Y) #计算损失函数losses.append(loss.item()) # 记录损失函数的变化,loss是张量,用.item()降级optimizer.zero_grad() # 清理上一轮滞留的梯度loss.backward() # 一次反向传播optimizer.step() # 优化内部参数# 作图表示损失函数的变化
Fig = plt.figure()
plt.plot(range(epochs), losses)
plt.ylabel('loss')
plt.xlabel('epochs')
plt.show()# 测试网络# 给测试集划分输入和输出
X_test = test_Data[:, :3] # 前三列为输入特征
Y_test = test_Data[:, -3:] # 后三列为输出特征with torch.no_grad(): # 只需要前向传播,该局部关闭梯度计算功能,降低内存开销,提高运算速度Pred = model(X_test) # 一次前向传播Pred[:, torch.argmax(Pred, axis=1)] = 1Pred[Pred!=1] = 0 # 这两行,用argmax函数,将预测值中的最大者置为1,然后再将不为1的地方置为0,相当于转换为one-hot编码的输出形式correct = torch.sum((Pred == Y_test).all(1)) #预测正确的样本数total = Y_test.size(0) # 所有样本数print(f"预测的正确的样本数{correct}\n测试集的精准度是:{100*correct/total}%")二、手写数字识别
接下来我们实现机器学习领域的Hello World——手写数字识别。使用的数据集MNIST是机器学习领域的标准数据集,其中的每一个样本都是一副二维的灰度图像:

任务描述
因此对于整个手写数字识别的任务,模型的输入是一副图像,输出则是一个对应的识别出的数字(0-9之间的整数)。这里注意,在进行模型训练时,PyTorch会在整个过程中自动将输出转换为One-Hot编码,因此我们在训练时不需要手动将输出转换为One-Hot编码,但进行模型评估测试时,由于需要比对预测输出(One-hot)和真实输出(0-9的数字),要进行一次转化。
对于单个样本,每个图像都是一个二维灰度图像,像素为28*28.二维灰度图像的通道数为1,因此可以将每个样本图像转换为28*28的张量,作为输入。相当于是下图这样的形式:

具体怎么转换,需要用到torchvision库中的trabsforms进行图像转换,将数据集转换为张量的形式,并调整数据集的统计分布(转换为标准正态分布更利于训练)。
数据集
我们需要从torchvision库中分别下载训练集和测试集,同时还需要用到torchvision库中的trabsforms进行图像转换。同时我们还要用到批次加载器,位于torch.utils.data中的DataLoader,因此需要导入的库如下所示:
import torch
import torch.nn as nn
from torch.utils.data import DataLoader
from torchvision import transforms
from torchvision import datasets
import matplotlib.pyplot as plt从torchvision库的datasets中下载数据集之前,需要先设定数据集的转换参数,将图像转换为二维张量,并转化为标准正态分布的形式,有助于提高模型性能。根据统计,MNIST中训练集所有像素的均值是0.1307、标准差是0.3081,数据集转换参数的设置代码如下:
# 设定下载参数 (数据集转换参数)
transform = transforms.Compose([transforms.ToTensor(), # 用于将图像转换为张量transforms.Normalize(0.1307, 0.3081) # 标准化,MNIST 训练集所有像素的均值是 0.1307、标准差是 0.3081
])
然后我们就可以进行下载了,分别下载训练集和测试集,代码如下:
# 下载训练集和测试集
train_Data = datasets.MNIST(root = 'D:/Jupyter/dataset/minst/', #下载路径train = True, # 是否下载训练集download = True, # 如果该路径没有数据集,则下载transform = transform # 数据集转换参数
)test_Data = datasets.MNIST(root = 'D:/jupyter/dataset/minst/',train = False,download = True,transform = transform
)然后使用批次加载器DataLoader加载数据,可以在接下来的训练中进行小批次的载入数据,有助于提高准确度,对训练集的样本进行打乱,设置shuffle=True。代码如下:
# 批次下载器
train_loader = DataLoader(train_Data, shuffle=True, batch_size=64)
test_loader = DataLoader(test_Data, shuffle=False, batch_size=64)神经网络搭建
此处和之前的区别不大,我们直接给出代码:
class DNN(nn.Module):def __init__(self):'''搭建神经网络各层'''super(DNN, self).__init__()self.net = nn.Sequential(nn.Flatten(), # 先把图像铺平成一维nn.Linear(784, 512), nn.ReLU(),nn.Linear(512, 256), nn.ReLU(),nn.Linear(256, 128), nn.ReLU(),nn.Linear(128, 64), nn.ReLU(),nn.Linear(64, 10))def forward(self, inputx):'''前向传播'''outputy = self.net(inputx)return outputy这里需要注意的是,由于图像转换后的张量是二维的,需要用nn.Flatten先将图像展平为一维的。28*28的图像铺平后,相当于有28*28=784个值,因此相当于有784个输入特征。所以输入层的神经元个数也为784,对应第第一个nn.Linear(784,xxx),最终是一个预测任务,输出可能有10个值(即0-9)的分类问题,输出特征个数为10(One-Hot编码),因此我们输出的神经元个数为10。
与之前类似,将模型实例化,并转移到GPU上:
model = DNN().to('cuda:0')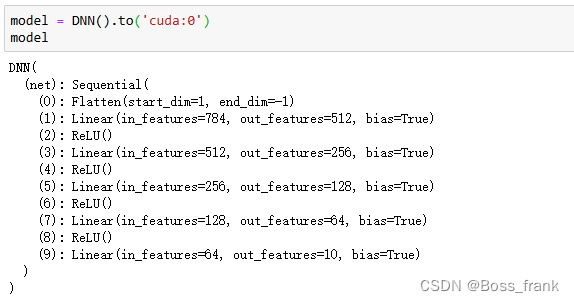
模型训练
这里还要注意,手写数字识别是分类预测问题,输出值相当于是One-Hot编码。对于这种多分类问题,如果想用概率表示分为每一类的可能性,输出层需要添加一个softmax激活函数,用于将输出层的数据归一化到0-1范围内,且总和为1,实现对概率的模拟。在我们选择损失函数的时候,可以选择自带softmax激活函数的交叉熵损失函数CrossEntropyLoss。 最终我们设定的损失函数和优化算法选择如下:
# 损失函数的选择
loss_fn = nn.CrossEntropyLoss() # 交叉熵损失函数自带softmax# 优化算法的选择
learning_rate = 0.01
optimizer = torch.optim.SGD(model.parameters(),lr = learning_rate,momentum = 0.5
)然后开始训练网络,采用小批次的方式加载数据:
# 训练网络
epochs = 5
losses = [] # 记录损失函数变化的列表for epoch in range(epochs):for (x, y) in train_loader:# 由于数据集内部进不去,只能在循环的过程中取出一部分样本,就立即将之搬到 GPU 上x, y = x.to('cuda:0'), y.to('cuda:0') Pred = model(x)loss = loss_fn(Pred, y)losses.append(loss.item())optimizer.zero_grad()loss.backward()optimizer.step()Fig = plt.figure()
plt.plot(range(len(losses)), losses)
plt.show()绘制出的损失函数变化如下:

模型评估
也是相似的方法进行模型评估,代码如下:
# 测试网络
correct = 0
total = 0
with torch.no_grad(): #局部关闭梯度计算,节省开销for (x, y) in test_loader:x, y = x.to('cuda:0'), y.to('cuda:0')Pred = model(x)_, predicted = torch.max(Pred.data, dim=1)correct += torch.sum((predicted==y))total += y.size(0)
print(f"测试集的精确度是{100*correct/total}%")
print(f"correct = {correct}, total = {total}")其中代码_,predicted = torch.max(Pred.data, dim=1)表示找出Pred每一行(dim=1)的最大值,将最大值的数值赋值给_(我们不关心这个数值的绝对大小,因此用_接受即可),将最大值所在的位置赋值给predicted,就相当于将One-hot编码转换回了阿拉伯数字(0-9),方便直接判断与标签y是否相等。注意到此处predicted和y都是一维的(一阶张量),因此求取正确预测个数时无需添加.all(1)
最终的评估结果如下:
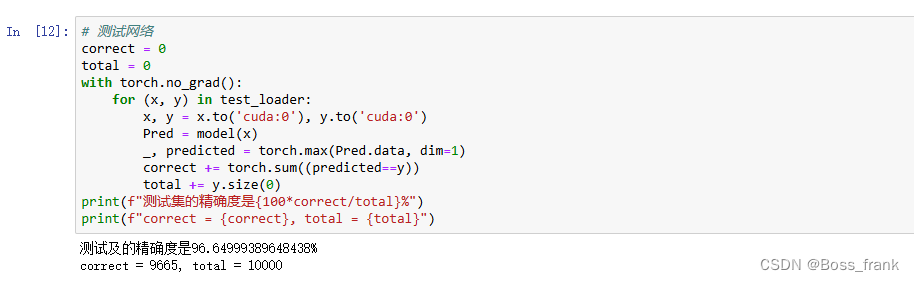
准确率高达96.65,很不错了!
写在最后
本文介绍了如何使用PyTorch框架搭建深度神经网络模型。实现模型的搭建、模型训练、测试、网络的复用等,并实现机器学习领域的Hello world——手写数字识别。重点关注PyTorch的实现方式,有关模型结构的设置、损失函数和优化算法的选择并没有进行详细的讲解,读者可以自行研究。可以看出PyTorch框架还是大幅度提高了我们搭建神经网络的效率,可以通过直接调用接口的方式搭建不同的网络模型。
本文实现的手写数字识别是基于DNN实现的,将灰度图像转换后的二维数组展平到一维,将一维的784个特征作为模型输入。在“展平”的过程中必然会失去一些图像的形状结构特征,因此基于DNN的实现方式并不能很好的利用图像的二维结构特征,而卷积神经网络CNN对于处理图像的位置信息具有一定的优势,相比于DNN,CNN在图像处理领域往往有更好的性能。后续我也可能会更新一些相关的内容。
后续还会继续更新神经网络的相关知识,另外近期我个人的研究方向涉及到图神经网络,回头也会更新一些相关博客。如果读者有相关建议或疑问也欢迎评论区与我共同探讨,我一定知无不言。总结不易,还请读者多多点赞关注支持!