平时写代码的时候,作为云村用户的一员,我当然也是最爱开着网易云音乐(以下简称网易云)。大家都知道在网易云里你可以查看好友或是任意用户的听歌排行(假使Ta设置全部可见),但是如果想知道Ta喜欢哪些歌手,其中又有哪几个是Ta的最爱呢?很可惜,网易云并没有直接提供信息。如果不会编程,你将怎么做?
一、网易云和词云
想知道Ta在网易云所有时间喜爱和最爱的歌手,逻辑上讲:你可以基于Ta的所有时间听歌排行,手动记录他排行中前100首听得最多的歌曲的歌手/音乐人(以下统称为歌手),然后根据记录的信息统计重复出现的歌手次数,以此可以推断出Ta更喜欢的歌手,而余下这些不重复人名也都是Ta喜欢的歌手。不过显然这样用眼睛看、记录、比对非常的麻烦,几乎不具有可行性。但是我们用python去实现上述逻辑,就没有很大的难度,这里会用到爬虫技术来代替我们去看、去记录,再使用词云图展示和对比出Ta喜爱的歌手。
词云是什么?简单介绍一下:“词云”,英文’wordle’,这个概念由美国西北大学新闻学副教授、新媒体专业主任里奇·戈登(Rich Gordon)提出。他一直很关注网络内容发布的最新形式——即那些只有互联网可以采用而报纸、广播、电视等其它媒体都望尘莫及的传播方式。“词云”就是通过形成“关键词云层”或“关键词渲染”,对网络文本中出现频率较高的“关键词”的视觉上的突出。词云图过滤掉大量的文本信息,使浏览网页者只要一眼扫过文本就可以领略文本的主旨。
来看一种最简单的词云图:
是不是还蛮有趣的?网上能做词云图的工具不少,虽然它们看起来也很好用,可功能都有些单一,适用范围有限。选择用Python来制作词云,不仅上手简单便利,而将各种模块组合起来合理调用,更是功能强大且自定义广。看完了这篇文章,你马上就能做出一张比上面示例图更好看的词云图。说完了思路,现在来跟着我动手吧~
二、用户听歌排行
在正式开始之前,先说明一下,博主使用的IDE是pycharm,如果你用vscode或者jupyter notebook之类的都是没影响的,如有软件操作问题,请自行百度解决哦。
回到正题,我们先来看网易云:进入网易云音乐随便找一个用户:
点击进入Ta的主页:
在用户主页如果能看到听歌排行,那就说明Ta设置为可见。那我们接着就可以点右下角查看更多,前往完整听歌排行的页面。注意右上角,这些操作都是不需要我们登录自己账号的,这样在爬取时很方便。随意进入一个用户的完整听歌排行页面:
可以看到url发生了变化,同时展示的歌曲比主页多了很多,最多为Ta听歌排行的前100首。我们要爬取的就是这个页面,来观察此时的url:https://music.163.com/#/user/songs/rank?id=412091xxxx(隐私问题我隐藏了用户最后四位数字)可以看出url结构最后**?id=xxxx**,当用户设置听歌排行可见时,每次爬取不同用户的url的区别只是最后的id变更,至于id你可以通过访问该用户的任何页面从url最后获取(每人都是唯一且不同的)。
还记得吗?我们今天的目标是爬取所有时间听歌排行,所以请找到右上角最近一周的边上,点击切换到所有时间,再观察页面url:https://music.163.com/#/user/songs/rank?id=412091xxxx哎呀,什么变化都没是吗?没关系。对于这样的动态页面,我决定使用selenium来进行爬取比较偷懒 方便~
Selenium模块简介:Selenium是一个用于测试网站的自动化测试工具,支持各种浏览器包括Chrome、Firefox、Safari等主流界面浏览器,同时也支持phantomJS无界面浏览器。简单来说它可以模拟人对浏览器的操作包括点击,输入删除文字,或是滚动屏幕等等。要使用它,你需要先pip install selenium安装该模块,并且拥有上述浏览器中的一种,然后下载安装对应的驱动webdriver文件。具体安装细节,不会的朋友请自行搜索教程,非常简单,本篇不再赘述。Tip:使用selenium可以异步加载动态网页,将它变成静态网页后再交由bs4解析,是我常用的好搭档。
回到正题,我们有了url,也决定了使用什么方法爬取,接着我们来找每一首音乐的歌手在网页的位置:开局一个F12,所有标签全靠ctrl+f~打开开发者工具(F12)后,到Elements里找歌手信息位置:
使用工具里箭头选中歌手名字看到:
标出来的标签和属性都是可以方便我们等下定位到歌手信息的,而且找到一个就可以找到全部了,所有的歌手信息最后都藏在< li >里:
现在url、爬取方法、信息标签定位都已经齐全,可以开始写代码了!
三、爬取歌手代码
以我用的chrome浏览器为例写代码。先来导入模块,我们先要用到selenium、bs4和time模块:
import time from selenium import webdriver from bs4 import BeautifulSoup
构建url以及设置等下要用到的变量名:
uid = '41209xxxx'#随时可替换用户id url_recd = 'https://music.163.com/#/user/songs/rank?id='+uid#构建爬取url unknown = '未知'#特殊情况下错误提示用 asingerlist = []#储存所有时间排行中所有歌手的列表 start = time.time()#设置计时器 samaritan =webdriver.Chrome()#webdriver实例化
接着创建一个负责爬取目标用户所有时间听歌排行的方法好像就可以成功了?因为我们刚刚已经定位到了歌手文本信息。可是这里有个坑~如果你直接用selenium定位或bs4解析定位尝试刚才的标签的话会什么都找不到。因为仔细看elements里:
这里是iframe页面嵌套,如果不能进入iframe里面,是不能定位到任何在它里面的标签的。幸运的是这对selenium来说仍然不是问题:
def get_record():#创建获取歌手信息的方法samaritan.get(url_recd)#实例化对象访问urlsamaritan.switch_to.frame('g_iframe')#找到指定iframe标签(这里是g_iframe)然后跳入samaritan.implicitly_wait(10)#隐式等待checkall = samaritan.find_element_by_id('songsall')#定位到切换到所有时间的按钮标签checkall.click()#模拟鼠标点击查看所有时间下的听歌排行samaritan.implicitly_wait(10)#隐式等待time.sleep(0.5)#这里还需要强制等待加载时间,一般一秒内就可以了htmlrec = samaritan.page_source#此时网页成为静态页面,获取所有页面信息pagerec = BeautifulSoup(htmlrec, 'html.parser')#使用bs4解析静态网页allrec = pagerec.find(class_="g-wrap p-prf").find(class_="m-record").find(class_="j-flag").find_all('li')#定位该位置下所有<li>的标签try:#使用try except结构防止意外报错中断运行for i in allrec:#遍历刚才位置下每一个<li>标签内信息asinger = i.find(class_="s-fc8").text.replace('-', '')#定位并获取歌手文本信息,再用replace方法清洗文本去掉歌名和各种之间连结的'-'asingerlist.append(asinger)#将干净的歌手文本加入列表except:print(unknown)#如遇到意外,提示'未知'。
最后调用方法以及查看结果:
get_record()#调用爬取方法
samaritan.close()#关闭浏览器
end = time.time()#结束计时
print(asingerlist)#打印所有歌手列表
print(f'总共用时:{end-start}秒')#打印程序用时输出结果:
[' Matteo', ' Russ', ' 永彬Ryan.B/AY楊佬叁', ' DP龙猪/宝楽CNBALLER/CLOUDWANG\xa0王云',' 音阙诗听', ' Deep\xa0Chills/IVIE', ' 白小白', ' Fly\xa0Project', ' 金志文'...... #以下省略]总共用时:4.079788398742676秒
只要四秒钟,我们就完成了对目标用户所有时间听歌排行的歌手爬取。但是这样一点看不清啊,而且怎么知道哪些歌手更被偏爱呢?接下去我们就要把这个歌手列表里的内容制作成一目了然的词云图了~
四、制作歌手词云
制作词云我们还需要用到以下模块:os
PIL
numpy
matplotlib
wordcloud这些模块的安装使用也不在本篇讲解了,只是展示给大家这种实战情况下如何调用,有兴趣的一样可以自行搜索深入学习。
开始制作词云,依旧先导入模块:
from os import path from PIL import Image import numpy as np import matplotlib.pyplot as plt from matplotlib import colors from wordcloud import WordCloud
我们用wordcloud的方法处理文本,以生成词云。无论是你从表格文件还是txt文本还是直接爬取到的数据,只要是字符串就可以给他处理,所以这一步先要将刚才的歌手列表变成wordcloud可以处理的字符串:
astext = ','.join(asingerlist) #将列表所有元素依序合并成字符串,并用'逗号'连接
是的你没看错,一行代码就ok了!因为我们在加入列表前已经做了数据清洗。我之前说了,这个词云图要做出比上面举例的那张好看才行,所以我们给它戴一个’面具’mask:模板图片love.png
d = path.dirname(__file__) #获取当前文件路径 alice_mask = np.array(Image.open(path.join(d,"love.png"))) #读取模板的图片
非常简单,就两行代码。这里我用了PIL模块读取的图片,也可以使用别的模块比如imageio、opencv等等都一样的。读取以后等下我们会在wordcloud参数设置里套用上它。现在我们再来美化一下这个词云,我可以使它的颜色在丰富一些:
color_list=['r','g','b','y','pink','purple','orange','black'] #建立颜色数组,列表中的颜色可以随便改动,除了常用颜色英文名外,也可以直接使用RGB色值,例如'#FDF5E6' colormap=colors.ListedColormap(color_list) #调用颜色数组
万事俱备啦,现在设置wordcloud对象参数:
wc = WordCloud( #创建wordcloud实例font_path='wqy-microhei.ttc',#设置字体路径,如果要制作的词云中有中文我们需要下载字体文件调用background_color="white",#设置图片背景色,默认为黑色,这里我觉得用白色比较好看max_words=1000,#设置显示最大单词数colormap=colormap,#设置字体颜色mask=alice_mask,#设置模板图片,戴上'面具' ) wc.generate(astext)
词云到这里就做好啦,不过别急,现在运行是什么都看不见的哦!我们需要通过matplotlib模块来展示图片:
plt.imshow(wc, interpolation='bilinear')
#生成词云图片
plt.axis("off")
# 关闭图像坐标系
plt.figure('singer')
#指定所绘图名称
plt.show()
#显示图片
准备好运行看看了吗,下面就是见证奇迹的时刻:
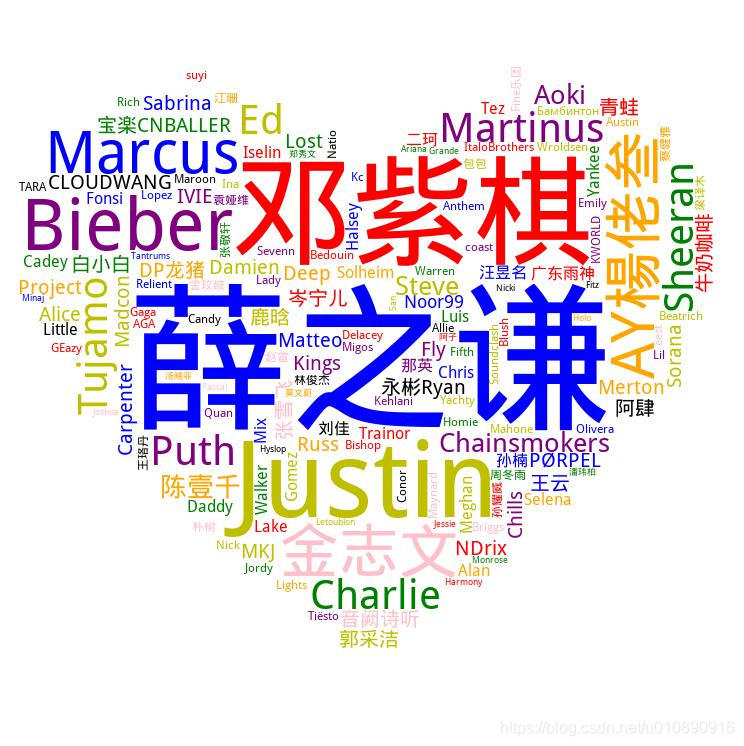
是不是一目了然?Ta在网易云数据中最喜欢的歌手依次排序就是薛之谦、邓紫棋、Justin Bieber、ED Sheeran等~字号从大到小可以说非常直观了。
结尾
到此为止整个实战项目全部完成,你已经掌握对任意网易云用户迅速了解其喜爱歌手的方法以及制作帅气的词云图。接下去,无论想要爬取更多网易云上的信息也好,还是制作更加酷炫的词云图也罢,你需要不断的深入学习。但看到好的一面是,你能够以我这篇博文为基础拓展出去,兴趣会促使你自主学习更多的东西。
需要完整项目代码的小伙伴加群:1136192749