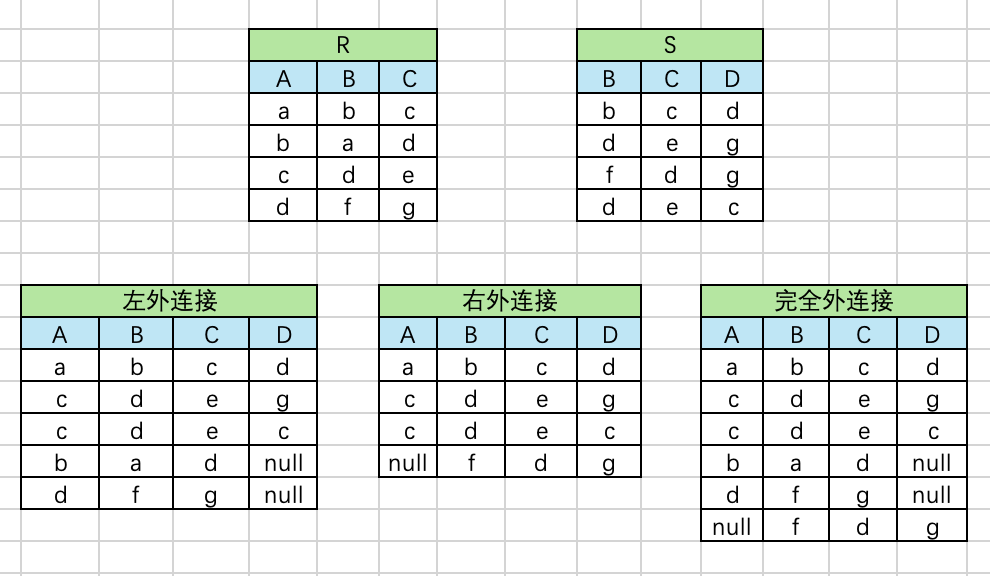
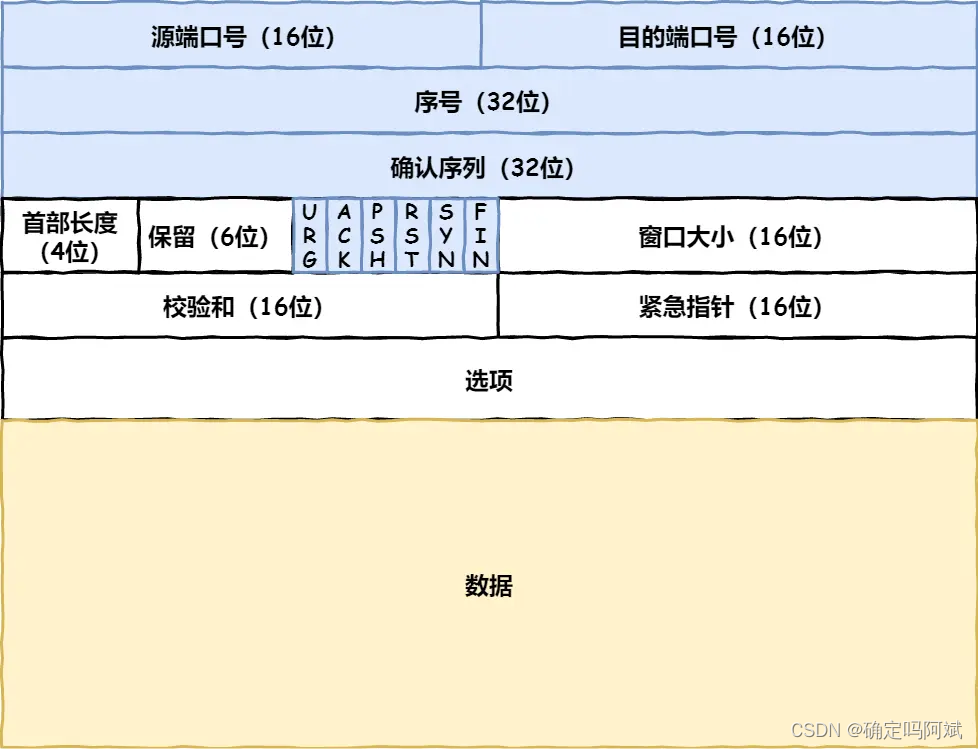
TCP 是传输层上的协议,它是可靠的,面向连接的。
概括
1. 设置传输格式,包括分为 TCP 段、使用校验和、使用序列号
2. 数据丢失之后的重传,超时重传、快速重传、SACK 选择确认、D-SACK 重复选择确认
3. 流量控制,控制数据包的传输速度,避免接受方处理不及时导致数据丢失,使用的是滑动窗口的方法
4. 拥塞控制,控制传输速度,避免传输数据包过多导致网路拥塞,主要算法:慢启动、拥塞避免、拥塞发生、快速恢复
传输内容形式
图片来源:小林coding
1. 基于数据块传输
TCP 传输数据时,不是直接一整个数据直接发送给接收端,而是分成很多数据段,叫做TCP 段或者报文段去发送,比如一个文件很大时,如果直接发送整个文件,传输的过程就不好控制。
2. 对每个数据段分配一个序列号
TCP 将数据分段之后,为了避免其中一个数据段在传输过程中丢失,就给每个数据段分配系列号,通过验证数据段的序列号来判断是否发生了丢失,或者这个数据段是否重复发送了
3. 校验和
TCP 保证首部和数据的校验和,目的是检验数据在传输工程中的变化,如果收到的数据段的校验和有差错,就表示数据发生了变化,就会丢弃这段。
在传输过程中,难免会因为各种原因,导致数据包发生丢失,丢失后的数据包就会通过重传机制来重新发送确保数据的完整性。
重传机制
TCP 实现可靠传输的方式之一,是通过序列号和确认应答机制。
TCP 中,发送端的数据到达接收端之后,接收端和发送一个 ACK 应答信息,表示已经收到了数据包。但是如果发生了数据丢失,比如发送端的数据丢失了,接收端根本没接收到,或者接收端接收到了,应答信息在中间丢了,都会触发重传机制来确保数据发送接收成功。
常见的重传机制:超时重传、快速重传、SACK(选择重传)、D-SACK (重复选择重传)
超时重传
顾名思义,超时重传就是通过设定一个超时时间,当发送数据之后,这个时间内没有接收到应答信息,发送端就认为数据丢失了,就会重新发送丢失的数据包。
但是问题在于,如何去设置超时时间,超时时间设置长了可能包都丢了有一会儿了才发现丢包了,就像你走马路上每隔一段时间摸下手机在不在口袋里,结果手机都丢了很久了你才摸包发现手机丢了。如果设置过短,就会出现数据还没丢,发送端就判断数据丢失了触发了重传,这样就浪费了资源。
首先确认两个概念:
RTT:往返时间,也就是数据包从发送出去一直到接收到 ACK 应答信息的时间。
RTO:重传超时,也就是超时时间。
在实际中只需要 RTO 超时时间略大于 RTT 往返时间即可,如果在往返时间之后还没有接收到应答,就到了 RTO 超时时间,就触发了超时重传。具体计算方法和公式这里就不贴了。
还有需要注意的就是,如果超时重发的数据,再次超时了,TCP 会将超时时间设为两倍。
快速重传
快速重传,不等待指定的时间,而是根据接收到发送的 ACK 应答信息来判断重传时机。
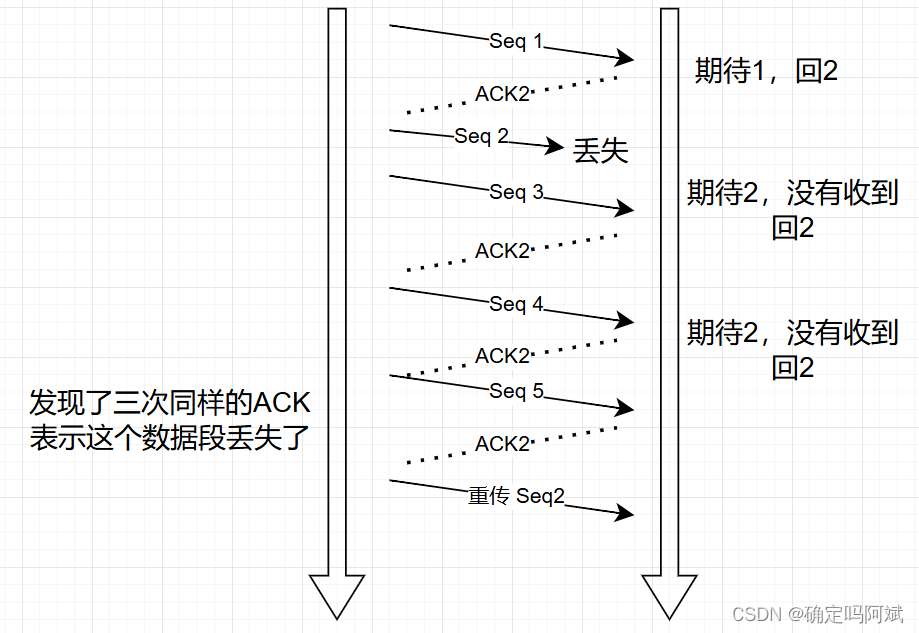
- 发送 Seq 1,接收到了回复 ACK2,理解为我收到了 Seq1,现在需要 Seq2;
- 发送 Seq2,发生了丢失,后续又发送了 Seq3,回复 ACK2;
- 后续继续发送 4 和 5,因为 2 一直没有收到,于是都回复 ACK2;
- 此时发送端接收到了三次相同的 ACK ,直到了 Seq 2丢失了,于是在过期时间之前就重传该数据包
解决了超时时间的问题,仍然有一个问题。当 Seq 2 和 3 都发生了丢失,因为一直没接收到 Seq2,所以回复的都是 ACK2。那么此时应该发送端怎么判断哪个包发生了丢失。
如果只重传 Seq2,接收端在这之前接收了 4,5,6,后来在接收到2 后,期待3,发现没有接收到,所以又要进行三次相同的回复,效率低。
如果将从 Seq2之后的三个数据包都重发,很明显出现了重复的数据报,浪费了资源。
SACK 选择确认
选择确认是在返回的 ACK 报文中加上 SACK ,作用是让接收端接收到数据包之后返回一个明确收到某一个数据包的应答报文。
举个例子,比如现在发送端发送一个 Seq 100 的数据包,接收端接收之后返回一个 ACK 100 的应答报文,当该数据包丢失之后,后续比如发送一个 Seq 200 的丢失了,再发送 Seq 300 的数据包,此时接收端返回的应答报文应该是 ACK 200,和 SACK 300,再发送一个 Seq 400 时,返回 ACK 200+SACK 400,三次过后,接收端没有收到 SACK 200 的选择应答,所以接收端重发 Seq 200。
D-SACK 重复选择确认
发送方重传的本质原因是没有接收到接收方的应答报文 ACK,而没有收到应答报文又有两种情况:
1. 数据包丢失或者网络阻塞
2. 数据包到达了接收方,而 ACK 应答报文丢失
出现重复数据包一半是网络阻塞和ACK 应答丢失造成的。当 ACK 应答报文丢失之后,实际数据包,比如 Seq 200 是发送到了接收端的,可是发送端认为没有发送到,所以会触发快速重传,重传之后的数据包到达接收端之后,再次返回 ACK 600 + SACK 200的,以为已经到了 ACK 600,表示600前面的数据包已经送达,而 SACK 200就表示这个 Seq 200 是重复的。
这就是重复选择确认。
流量控制
当发送方发送数据包存在一定速率,当速率过快,接收方不能及时处理这些数据,就可能导致数据包丢失。想要控制数据包的发送速率,使用了滑动窗口 的概念用来控制速率。
在之前说到的发送数据包都是收一个回复一个,很明显效率很低,引入滑动窗口,会在操作系统开辟一个缓冲区,当数据包到达接收方放入缓冲区,等待当前正在处理的数据包处理完成再从缓冲区取。这样就可以实现发送方连续发送多个数据包而不用等待每一个数据包的应答报文。
打个比方,有一家面馆,原来只有一个座位供顾客坐着吃面,其他人只能打包回去吃,这样就会少很多想要坐着吃的顾客,后来面馆赚钱了,把店面扩大了,座位增加到了10个,只要顾客吃面的速率和来顾客的速率差不多,就不会有顾客因为看见店里满了而选择另一家店了。顾客就相当于数据包,当接收方不能及时处理数据包时,就让数据包去缓冲区等着被处理。如果发送方速率过快,就会导致缓冲区满了而丢失数据包。
需要注意的是,滑动窗口大小会被操作系统控制,不是一直不变的。
拥塞控制
数据包是通过网络发送到接收方的,网络资源并不是无限的,所以如果发送方发送的太频繁,不仅是接收方处理不过来,首先网络可就先阻塞了。
所以需要一个拥塞窗口来控制发送方发送数据包的速率。拥塞窗口会根据网络情况进行变化,网络没有拥塞就会扩大,如果出现拥塞就会缩小。
控制拥塞的主要算法:
慢启动、拥塞避免、拥塞发生、快速恢复
慢启动
TCP 连接之后拥塞窗口不是一下就设置很大的,就像健身,你要从最轻的哑铃练起,要是你直接抱起100kg的东西,那还不闪了摇。。。
每当发送方接受到一个应答报文 ACK,拥塞窗口就会+1,表示现在网络没有拥塞,报文还能传过来。比如一开始是1,接收到一个 ACK 就是2,下一轮回来两个 ACK ,窗口就会被设置为4,同理,再下一轮就是 8,呈指数形式增长。
但是窗口也不能无限增长,否则和没有窗口限制没区别,用来控制最大窗口的叫做 慢启动门限。
当拥塞窗口小于慢启动门限时,就会增加,如果大于等于了,就会触发拥塞避免算法。
拥塞避免
拥塞避免,就是避免拥塞窗口开的太大,当拥塞窗口大于等于慢启动门限时,窗口扩大的速度就会变慢,每次增长 1/当前拥塞窗口大小。比如此时是 8 ,触发拥塞避免算法,于是接收到一个 ACK 扩大 1/8,一轮就是只增加 1 。增长速度就变成了线性增长。
网络不拥塞的情况下,窗口一直增长,直到网络出现了拥塞,数据包被堵在了网络上,一段时间之后,就触发的超时重传机制。于是发送方知道此时网络出现了拥塞,于是触发了拥塞发生算法。
拥塞发生
拥塞发生,发送端触发了超时重传,于是启动了拥塞发生算法,这个算法会重置慢启动门限和拥塞窗口。
慢启动门限会被设置为当前拥塞窗口的一半,拥塞窗口会被重置为初始状态。
看得出来这种方法会导致一切重来,传输速度变慢,5G网变回3G。
于是就有触发快速重传机制之后的 快速恢复 算法。
将拥塞窗口设置为当前的一半,然后将慢启动门限设为拥塞窗口的大小。
就相当于拥塞窗口再以线性增长的速度进行扩大。
快速恢复
快读恢复是在触发了快速重传之后使用的算法,快速重传是发送方接收到了3个相同的 ACK 应答报文才触发的,既然能接收到3个相同的 ACK 应答报文,就是说当前的网络也不是那么糟糕,只需要降低一点就可以。
于是就把拥塞窗口设置为当前的一半,慢启动门限设置为拥塞窗口的大小。具体过程:
1. 首先将拥塞窗口设置为当前的一半 + 3,因为是收到了3个重复的 ACK 应答报文
2. 造成拥塞的主要原因是数据包,而这些数据包都还没有送到接收方,所以要尽量把这些数据包发到接收方,所以如果后续收到的还是重复的 ACK,就把拥塞窗口+1,表示收到的是丢失的数据包。
3. 如果收到收到的新的 ACK ,则表示在此之前的数据包都已经收到了,然后就把拥塞窗口设置为当前的一半。
快速恢复不像拥塞发生,保证速率的同时能解决网络拥塞。