国内外主流GPU卡性能分析!2024!
大模型兴起助推算力需求激增
2024年,深度学习与人工智能技术飞速跃进,Transformer、GPT-3等大模型在自然语言处理、图像识别、语音合成等领域大放异彩,开启AI新纪元。其庞大的参数与数据量对计算能力提出新挑战,预示着AI技术正迈向更高峰。
大模型训练涉及的前向传播和反向传播算法对浮点运算需求极高,极大促进了高性能GPU、TPU等并行计算设备的需求。如GPT-3这类万亿级参数模型,需数千GPU长时间并行计算,凸显了计算能力的关键性。
大模型推理阶段对算力需求巨大,尤其在实时性要求高的场景下。如何在保障响应速度的同时处理复杂模型,成为当前算力基础设施建设的关键挑战。
大模型的广泛应用推动了云计算、边缘计算等领域的迅猛发展,满足大规模分布式训练与部署需求。其兴起不仅极大提升了全球对高效能、高并发计算能力的渴求,更催生了芯片制造、数据中心及新型计算架构等领域的创新步伐,引领技术变革潮流。

AIGC下的算力规模预测
2024年,AIGC技术飞跃,超大规模预训练模型升级,引领算力需求至全新高峰,预示AI生成内容将实现前所未有的广泛应用。
AIGC涵盖多媒体形式的大规模数据处理与创作,特别是在生成高精度的内容时,将极大提升对GPU/TPU等高性能计算资源的迫切需求。
随着模型压缩、分布式训练、异构计算技术的突破,虽能减轻单点算力压力,但整体算力规模仍可能指数增长。未来,全球算力基础设施的持续优化建设,将成为AIGC繁荣发展的核心驱动力。

AI芯片架构分析
AI芯片架构专注于高效执行机器学习算法,特别是深度神经网络(DNN)的并行处理需求,当前主流架构涵盖GPU、FPGA及ASIC,助力智能化升级。
GPU因其高度并行计算能力而被广泛应用于训练大型深度学习模型;
FPGA通过灵活编程适应多样化的AI算法,且能效比高,在特定场景下有优势;
ASIC如Google的TPU,专为深度学习定制,结构化设计实现极致性能与能效,适用于大规模推理。类脑芯片模拟人脑神经元,突破传统冯·诺依曼架构,追求低功耗下的智能计算,开启全新计算时代。

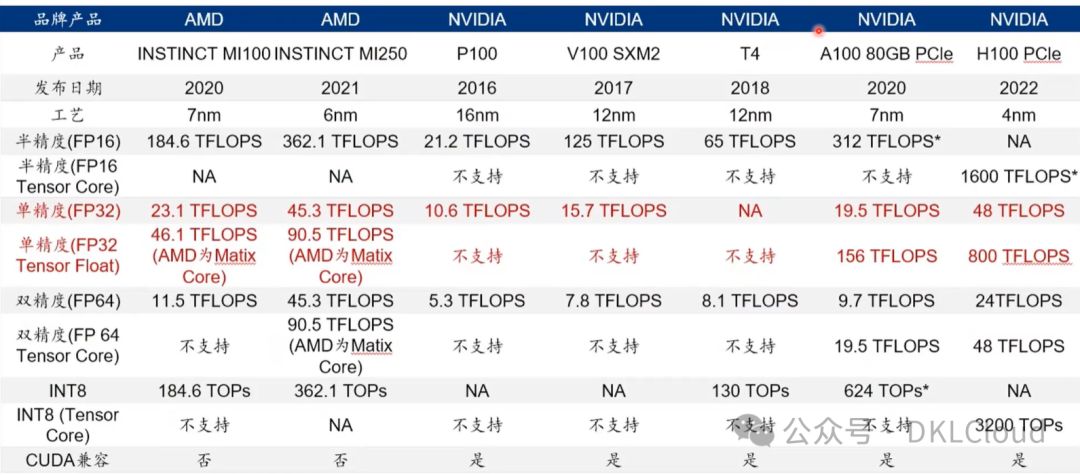
国内外主流GPU产品对比分析
英伟达、AMD、英特尔等国际大厂主导GPU市场,但中国国产GPU厂商正迅速崛起,挑战市场领导地位,展现技术突破之势,力争打破国际厂商的市场壁垒。
国际主流GPU厂商:
- 英伟达以CUDA编程环境和GPU计算平台称雄,产品线横跨个人游戏至高性能计算和数据中心,如A100、H100系列GPU,其卓越的FP32单双精度浮点性能及AI运算能力,使其在AI训练和高性能计算领域独占鳌头。
- AMD的Radeon系列GPU在游戏市场与英伟达分庭抗礼,同时,AMD在数据中心领域推出Instinct系列加速卡,以卓越的计算力和能效比,领跑AI训练和推理领域,展现强大实力。
- 英特尔深耕独立GPU市场,推出基于Xe架构的高性能GPU,不仅在集成GPU领域领先,更在数据中心和专业图形市场谋求更大份额。
国产GPU厂商:
- 海光信息CPU与DCU产品融合通用计算与特定领域加速,安全性能卓越,精准满足国内市场对高性能、安全可靠芯片的迫切需求。
- 芯动科技“风华”系列GPU,彰显国产GPU在图形处理与AI计算领域的卓越进步,像素填充率与AI性能直逼国际标杆,国产实力不容小觑。
- 登临科技GPU兼容主流CPU和服务器,专注打造生态,减少用户迁移成本,并领先支持大模型训练与推理等尖端AI应用,助力科技前沿。
国产GPU厂商技术取得显著进步,但性能指标、市场份额、生态建设仍需加强,以缩小与国际巨头差距。国家政策与市场需求双重助力下,国产GPU产业有望突破技术瓶颈,提升创新能力,在特定领域树立竞争优势,未来可期。
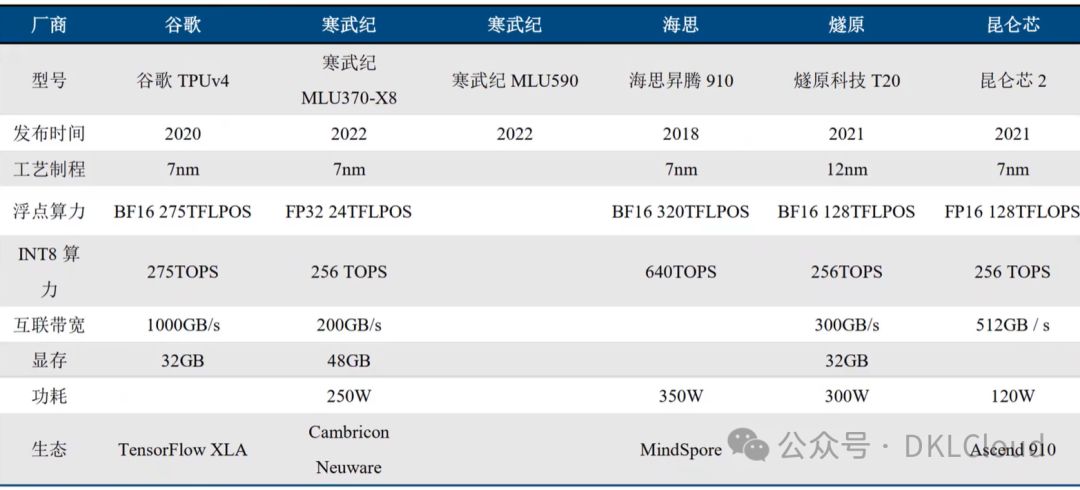
国内外ASIC产品对比分析
ASIC是专为特定应用定制的集成电路,较通用芯片(如GPU、CPU)在特定任务执行效率、功耗、尺寸及成本上优势显著。以下是国内外ASIC产品的对比分析,为您揭示其卓越性能与广泛应用。
国际主流ASIC厂商及产品特点:
- 英特尔(Intel)专为客户在ASIC领域打造定制芯片,聚焦数据中心与网络基础设施市场,提供高性能、低延迟ASIC产品,助力云服务、5G通信及区块链加密货币挖掘等前沿应用,实现卓越性能。
- 博通(Broadcom),ASIC领域的领军者,专注于无线通信、网络交换、数据中心等领域,凭借卓越的信号处理、电源效率及封装技术,树立行业标杆。
- 高通ASIC产品,深耕移动通信与物联网,专注手机基带、射频前端、Wi-Fi/蓝牙芯片等,定制化方案显著提升终端设备性能与能效,引领行业前沿。
- 谷歌研发的TPU(张量处理单元)是专为AI和机器学习优化的ASIC,在TensorFlow框架中显著提升了深度学习训练和推理效率,成为谷歌技术突破的关键力量。
国内ASIC厂商及产品特点:
- 华为海思:推出ASIC产品系列,包括昇腾AI芯片,专为人工智能计算设计;麒麟SoC处理器,为智能手机和平板电脑量身定制,性能卓越。
- 阿里巴巴平头哥推出玄铁系列CPU与含光系列AI芯片,均为ASIC产品,广泛应用于阿里集团云计算、大数据、IoT等多元化领域,实力非凡。
- 寒武纪,AI芯片设计翘楚,ASIC产品深度学习领域领先,神经网络计算优化架构,高效运行各类AI算法,引领智能时代。
- 比特大陆以ASIC矿机芯片设计引领行业,推出多款高性能、低功耗的专业芯片,为比特币挖矿行业树立新标杆。
ASIC厂商在国内外细分领域均显卓越。国际厂商凭借技术积淀与市场优势领先,而国内厂商在AI、5G、区块链等新兴领域崭露头角,成果斐然。然而,国产ASIC在产业链、生态建设与高端工艺等方面尚待提升。展望未来,持续的技术创新与市场拓展将是核心驱动力,推动国产ASIC实现跨越式发展。
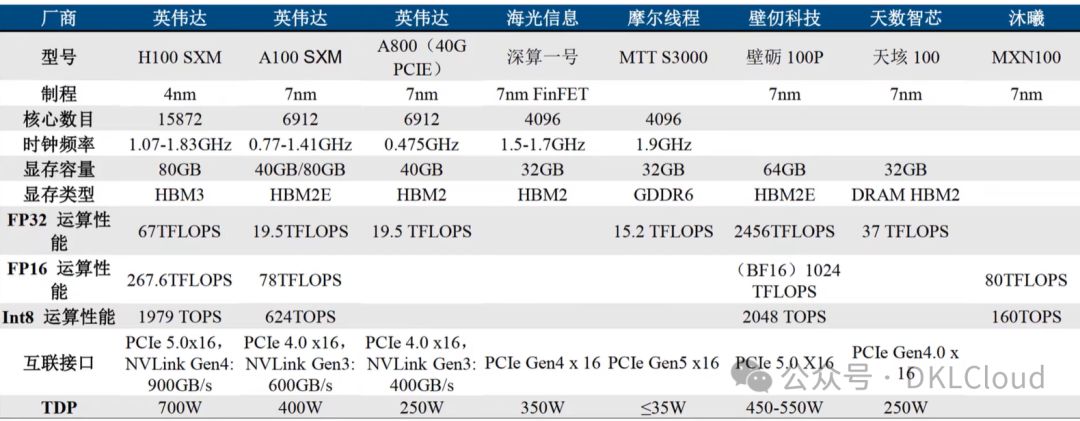
国内主流算力系统分析
国内主流算力系统汇聚CPU、GPU、ASIC等多元计算资源,构成计算密集型任务的核心支撑。以下是对其关键组成及代表企业的深入剖析,揭示行业发展趋势。
- CPU算力系统:
- 海光信息,国内CPU制造翘楚,其CPU性能比肩国际高端,7000、5000、3000系列全面覆盖市场需求,为数据中心、云计算及高性能计算提供卓越算力,展现国内制造的强大实力。
- GPU算力系统:
- 英伟达与AMD在中国市场占主导,深耕科研、数据中心、AI训练与推理。同时,景嘉微、壁仞科技等国内企业也在GPU领域积极研发国产产品,以满足高性能计算和AI计算的庞大需求,推动国内科技产业的蓬勃发展。
- AI加速芯片:
- 华为海思、阿里平头哥等企业推出AI推理与训练优化的ASIC芯片,如华为昇腾、阿里含光系列,专为特定场景设计,提供卓越算力支持,助力AI应用更高效。
- 数据中心与服务器集群:
- 华为、中科院系(如中科曙光)、浪潮、联想等国内IT巨头,在数据中心、服务器生产和算力整合上贡献卓越。其产品融合尖端计算单元,依托云计算、边缘计算等技术,提供全方位的算力服务,引领行业前沿。
- 算力网络与云服务:
- 阿里云、腾讯云、华为云等云服务巨头构建庞大数据中心网络,提供弹性可扩展云端算力,助力企业机构迅速构建部署大规模计算应用,轻松应对各类需求。
国内算力系统蓬勃发展,不仅提升单体设备性能,更在算力分布、资源调度、节能降耗、生态建设等方面加大投入,满足数字经济、AI及科研的强劲需求。同时,政府主导的“东数西算”工程优化跨区域算力资源配置,推动国内算力基础设施均衡发展,助力行业创新升级。

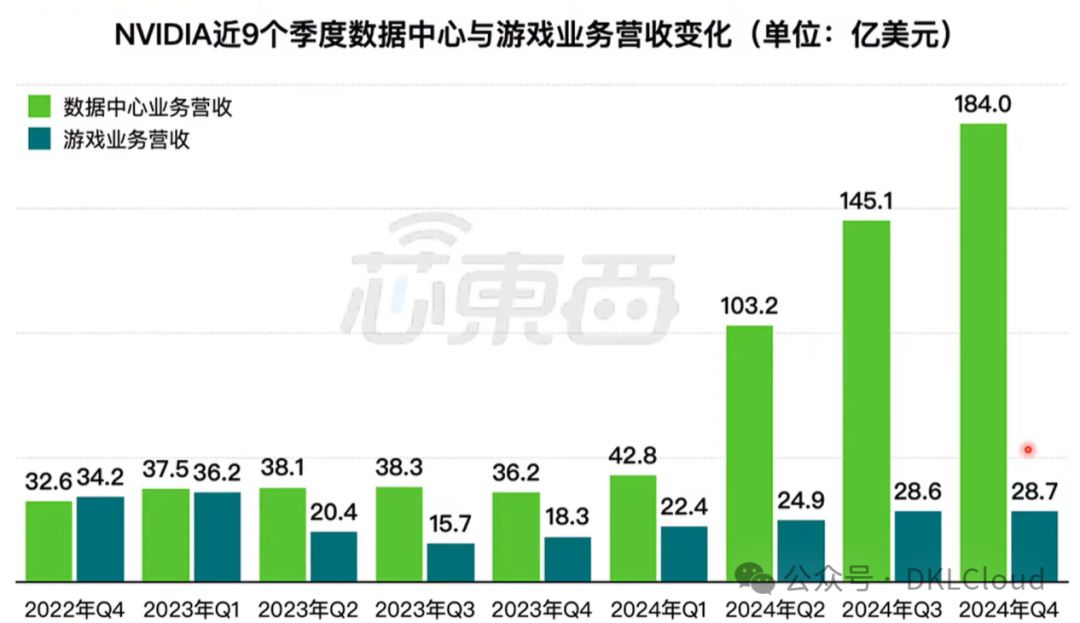
英伟达数据中心营收分析
2023年英伟达的数据中心业务表现出极为强劲的增长势头,尤其是在第四季度,数据中心业务营收取得了显著成就,具体表现为:在2023财年第四季度,英伟达的数据中心业务营收达到了184.04亿美元,相比分析师预期的172.08亿美元高出不少,同比增长更是超过400%,显示出该业务板块的爆炸性增长。
这种增长趋势表明,随着全球范围内对人工智能、机器学习、大数据分析等计算密集型应用需求的急剧增加,特别是生成式AI等先进技术的兴起,市场对英伟达所提供的高性能计算解决方案产生了巨大的需求。此外,从全年角度来看,数据中心业务在英伟达的整体营收中所占比例不断提升,凸显出数据中心和云计算市场对其GPU产品和技术解决方案的高度依赖。
英伟达在数据中心业务上的不断创新和领导地位,使其在面对内外部挑战时,依旧保持了业务的高速增长,有效推动了公司的整体盈利能力和市场价值。 总结来说,2023年英伟达的数据中心业务营收实现了里程碑式的跃升,反映了该公司在高性能计算和AI基础设施市场上无可争议的领先地位以及对未来趋势的准确把握。
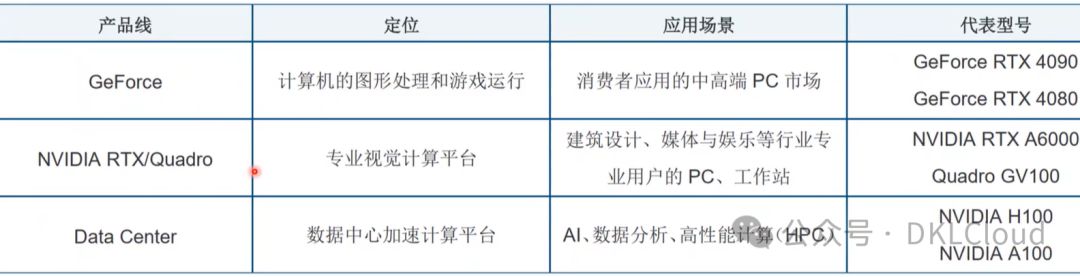
英伟达GPU主要产品线
英伟达(NVIDIA)的GPU产品线主要包括以下几个系列:
1. GeForce系列:
GeForce GTX系列显卡,涵盖GTX 1060、GTX 1070、GTX 1080等经典型号,现已迭代至更先进的RTX系列。
GeForce RTX系列显卡,持续革新至2023年,包括RTX 2060、2070、2080及RTX 3060、3070、3080、3090等型号,均搭载先进的光线追踪技术,不断推出新品与迭代,为玩家带来极致的视觉体验。
2. Quadro系列:
专业图形工作站市场首选,为CAD、3D建模、渲染、动画制作提供高稳定性、高精度的优化解决方案,助您高效创作。
3. Tesla 系列:
专为数据中心与高性能计算(HPC)打造的解决方案,支持海量并行计算,涵盖科学计算、深度学习训练与推理、大数据分析等。如Tesla P4、P40、T4等型号,结合Pascal、Kepler、Maxwell等先进架构,为您的计算需求提供强大支撑。
4. Data Processing Unit (DPU):
DPU是英伟达的创新产品线,专注于数据中心网络、存储和安全数据处理,显著提升数据中心运行效率和安全性能。
5. Grace CPU 和 Grace-Hopper 超级芯片:
英伟达 NVIDIA GPU架构演进分析

英伟达 NVIDIA 数据中心产品路线图
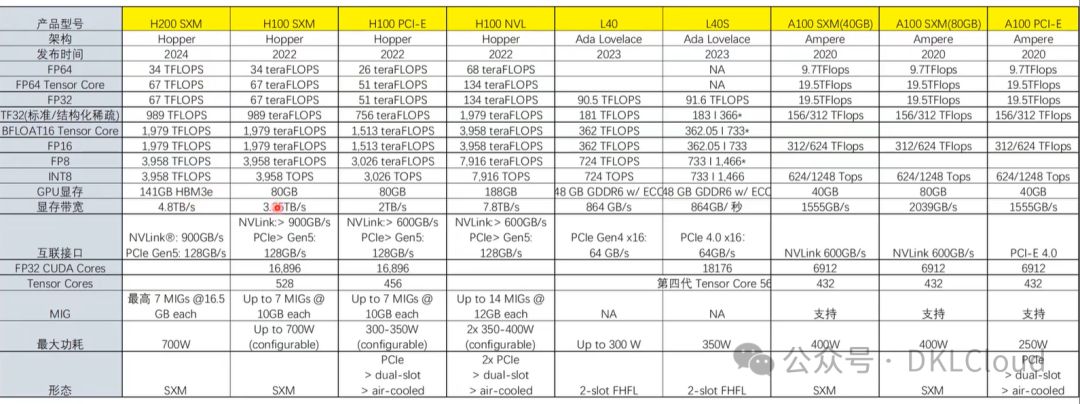
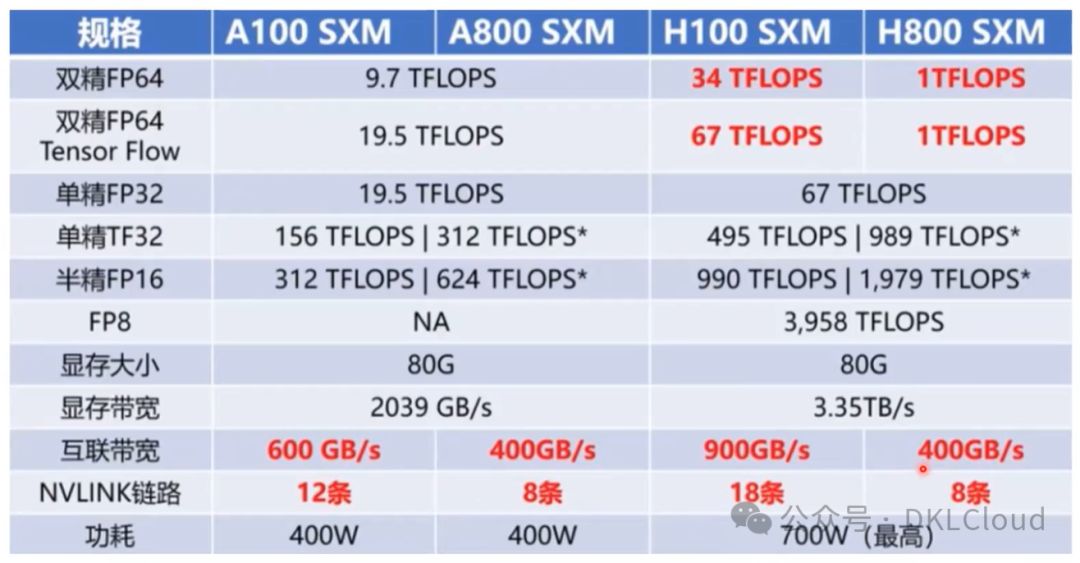
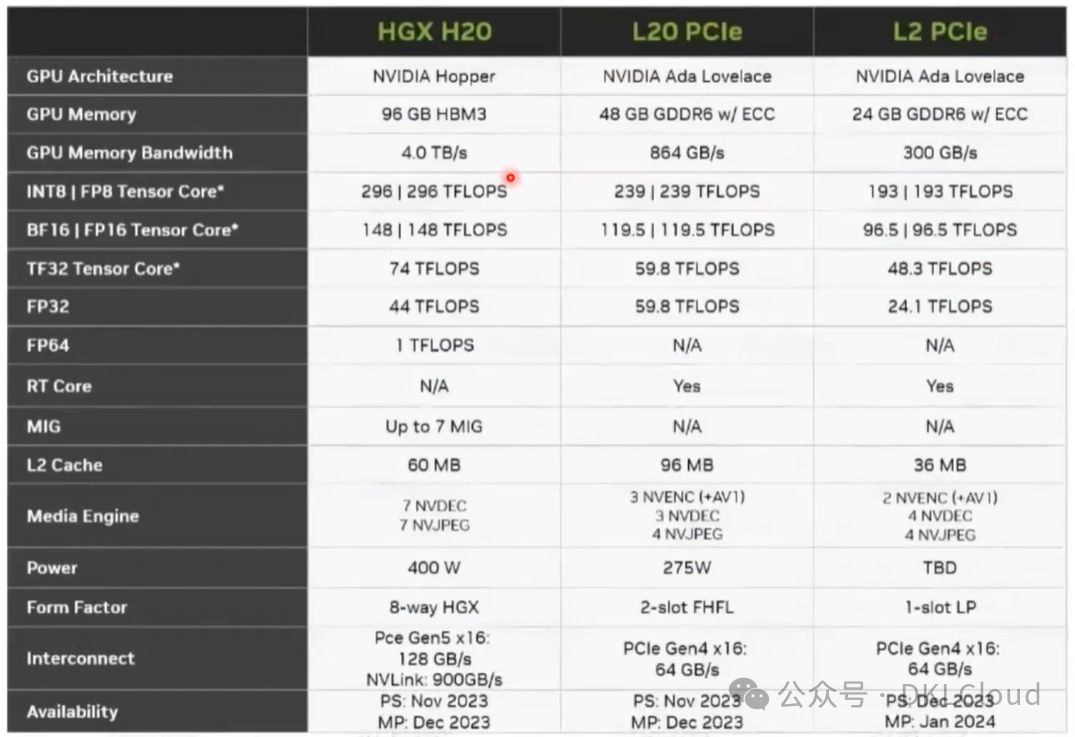
NVIDIA GPU卡规格参数性能分析
老美对于高端GPU卡出口限制令分析
1. 2022年10月美国限制出口英伟达和AMD的高性能人工智能芯片

设定了传输带宽和总体处理性能两个指标 ,总体处理性能=位宽*算力
2. 2023年10月美国高性能芯片禁令升级,旨在限速中国人工智能发展

取消了传输带宽限制,新增了性能密度指标
性能密度=总体处理性能/裸片面积
20221007禁令之后中国特供版

20231017禁令之后中国特供版
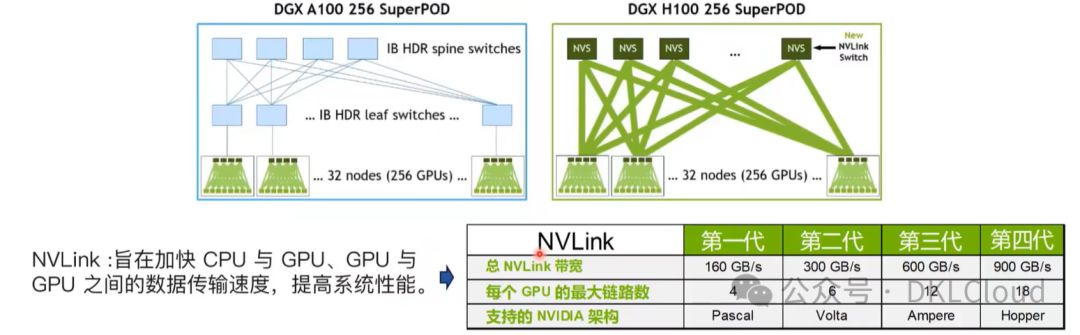
卡间通信:NVLink 与 InfiniBand
NVLink与InfiniBand,两大顶尖技术,专为不同层级高速数据传输量身打造,是构建高性能计算集群的关键。尤其在GPU间高速互连上,二者展现出无可比拟的优势,引领数据传输新纪元。
NVLink:
NVLink 是由 NVIDIA 开发的一种高速互连技术,用于连接同一系统内的多个GPU或其他加速器。它的主要目标是在单个服务器节点内部实现极高的带宽和低延迟的点对点通信,从而显著提高多GPU协作时的效率,尤其是在深度学习、科学计算等应用场景中。NVLink 提供的带宽远超过传统的 PCI Express (PCIe) 接口,能够使GPU之间直接共享内存,实现近乎无缝的数据交换。随着技术的发展,NVLink 不断升级,提供更高的带宽版本,例如 NVLink 3.0 可能提供的带宽高达 900 GB/s。
InfiniBand:
InfiniBand,一种卓越的高性能计算网络技术,专为多服务器节点间高效互联而设计。其基于RDMA技术,实现内存层面的直接数据传输,绕过CPU处理,显著减少通信延迟,提升CPU效率。InfiniBand网络带宽高达数十至数百GB/s,延迟低至微秒级,广泛应用于超级计算机、数据中心及GPU集群间通信,确保大规模并行计算环境的卓越性能。
总结起来:
结合NVLink与InfiniBand,大型GPU集群构建强大计算资源池,NVLink实现机箱内高速互联,InfiniBand确保跨节点数据高速传输,为大规模并行计算和机器学习提供高效动力。

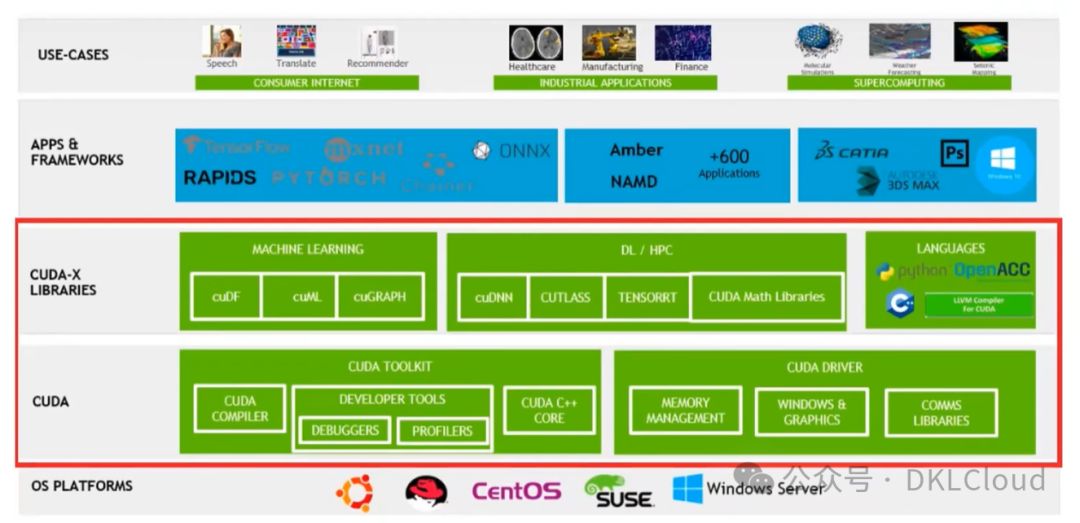
软件栈:CUDA
3、华为昇腾
Atlas 数据中心产品线--智能算力卡
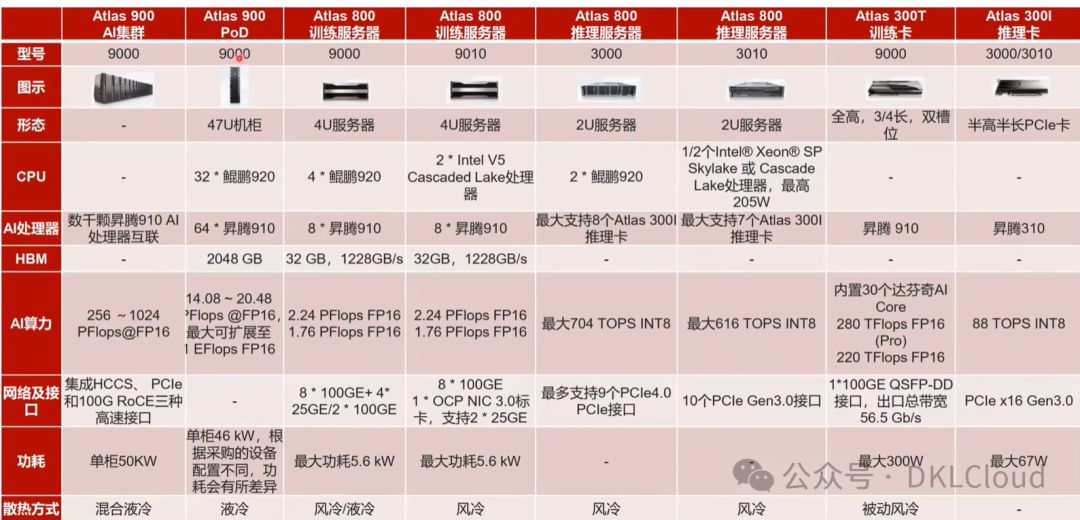
Atlas 视频卡与推理卡

从芯片封装成整卡
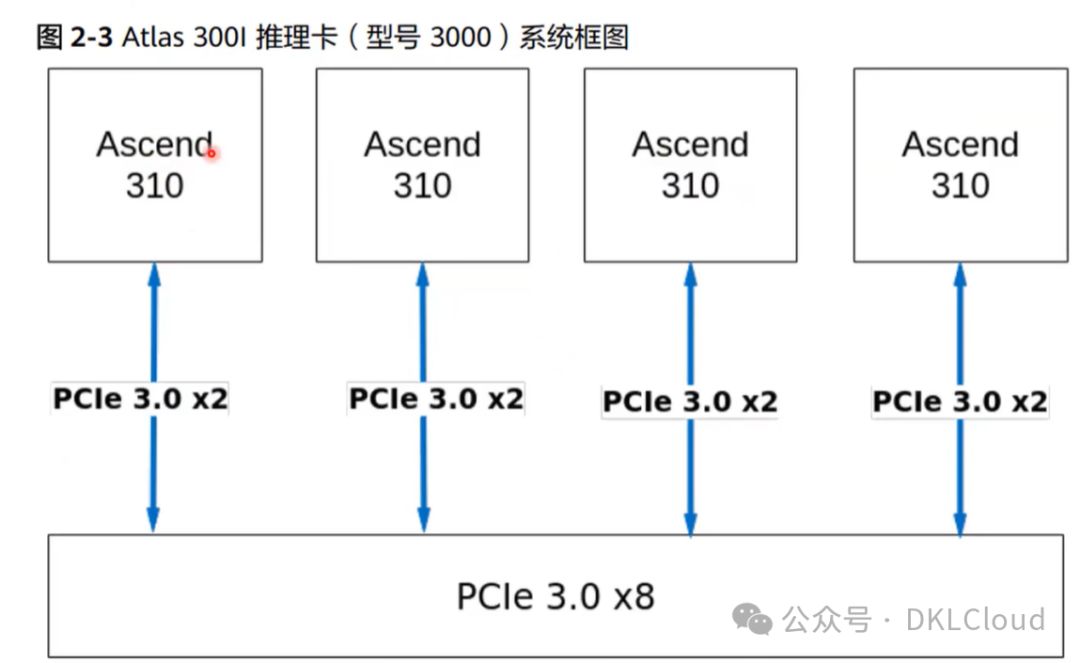
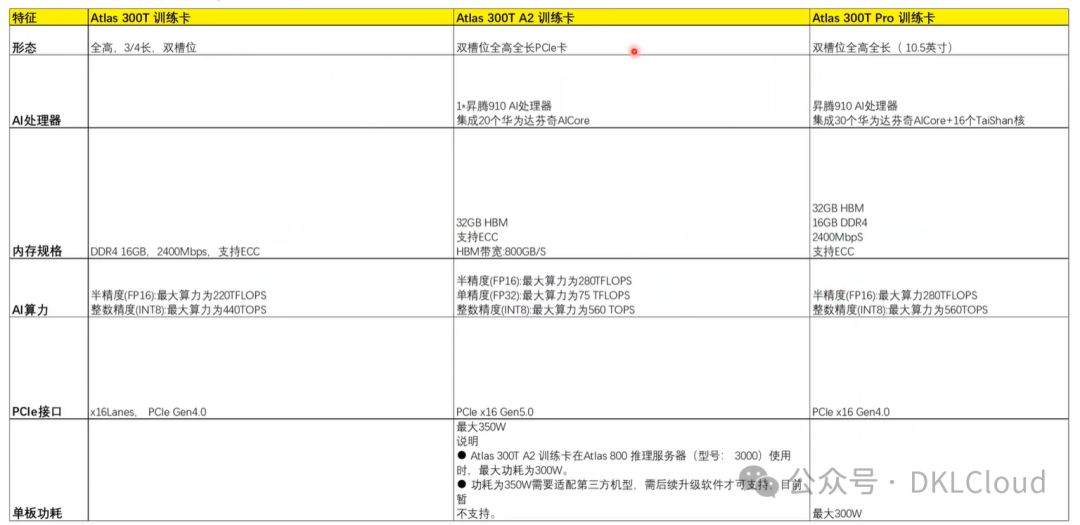
Atlas训练卡
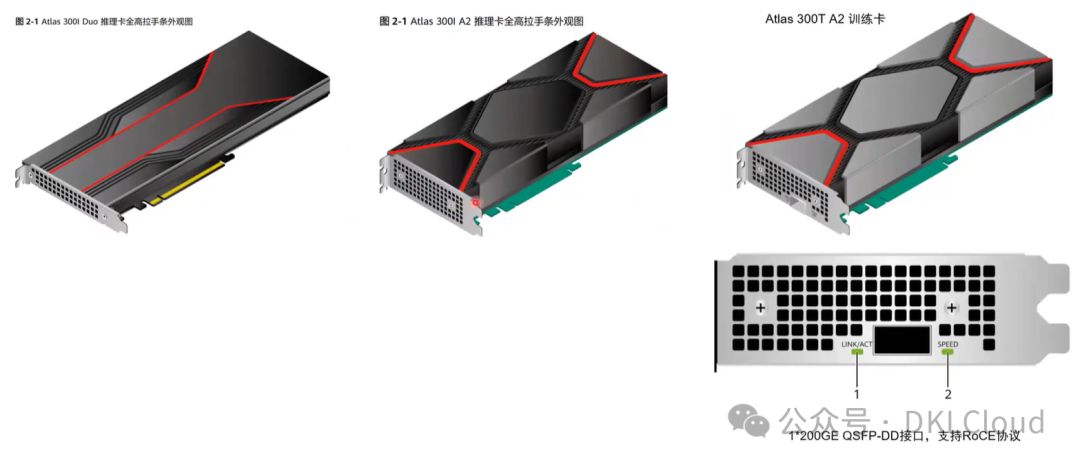
卡的形态
Ascend310 卡
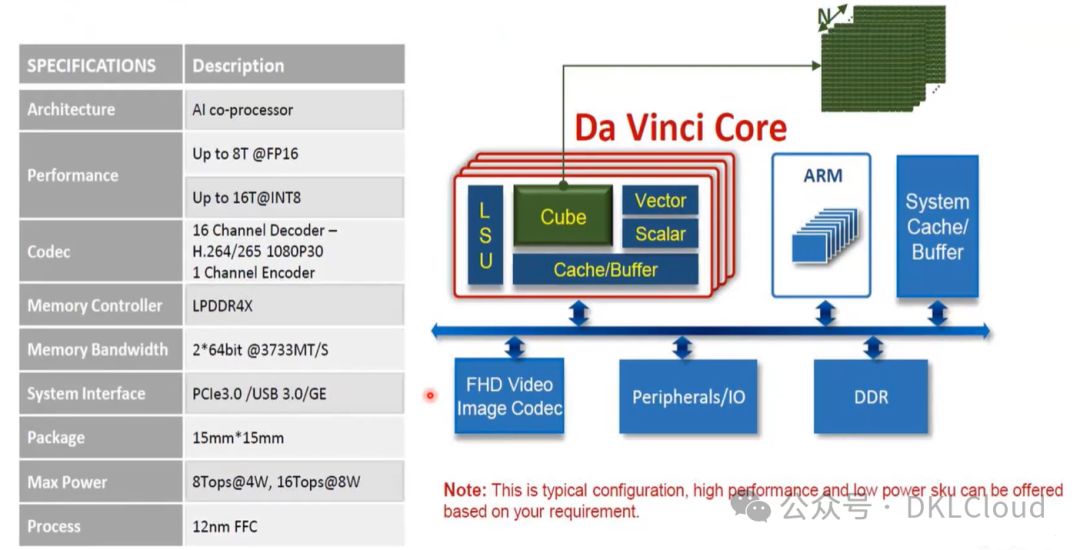
Ascend 310 AI处理器逻辑架构
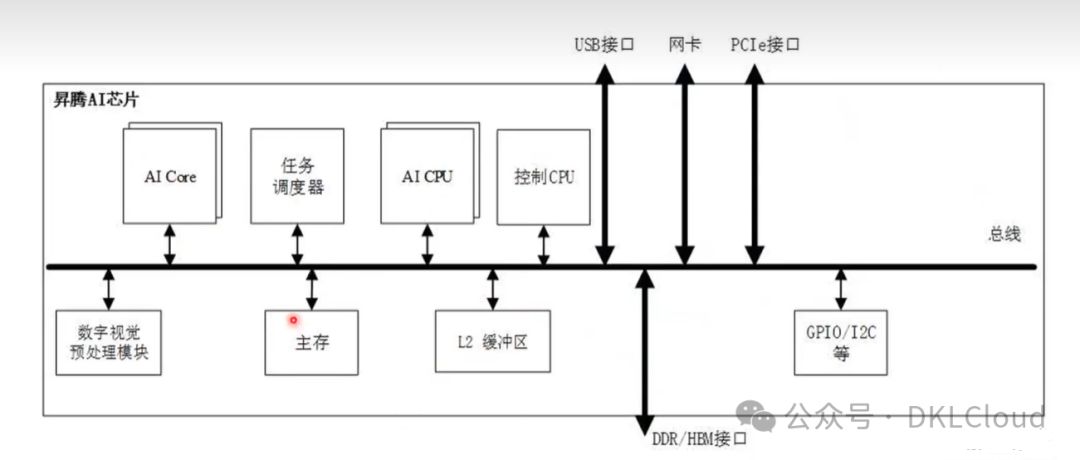
Ascend 910

Ascend 910B 对比 NVIDIA H800和H100
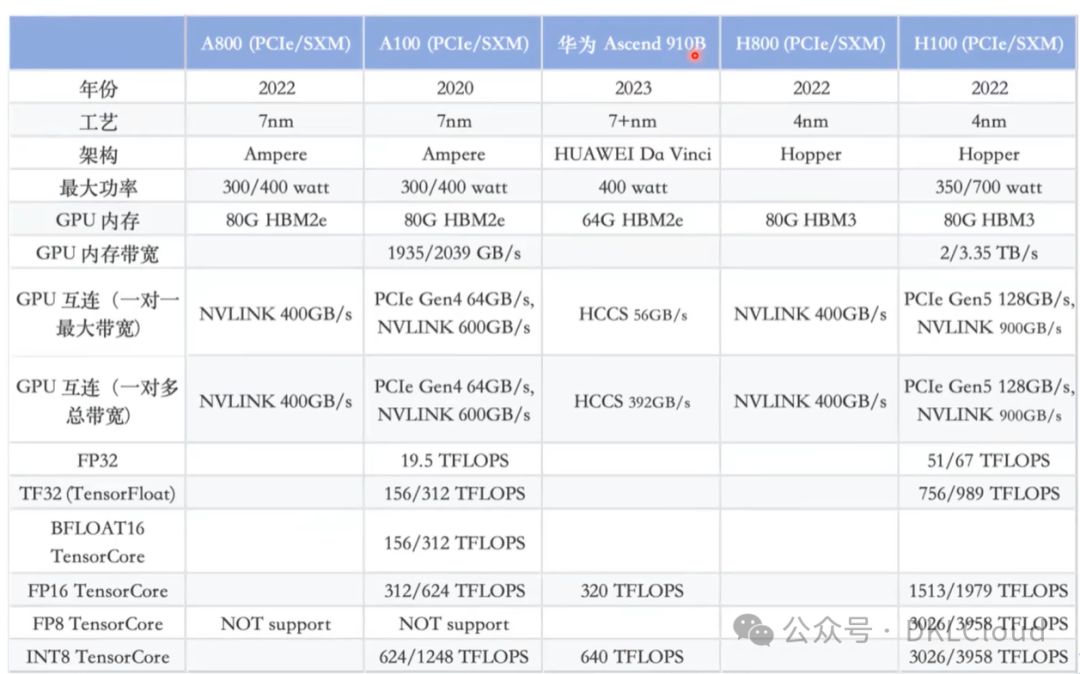
据业内报道 Ascend 910B的性能接近A100
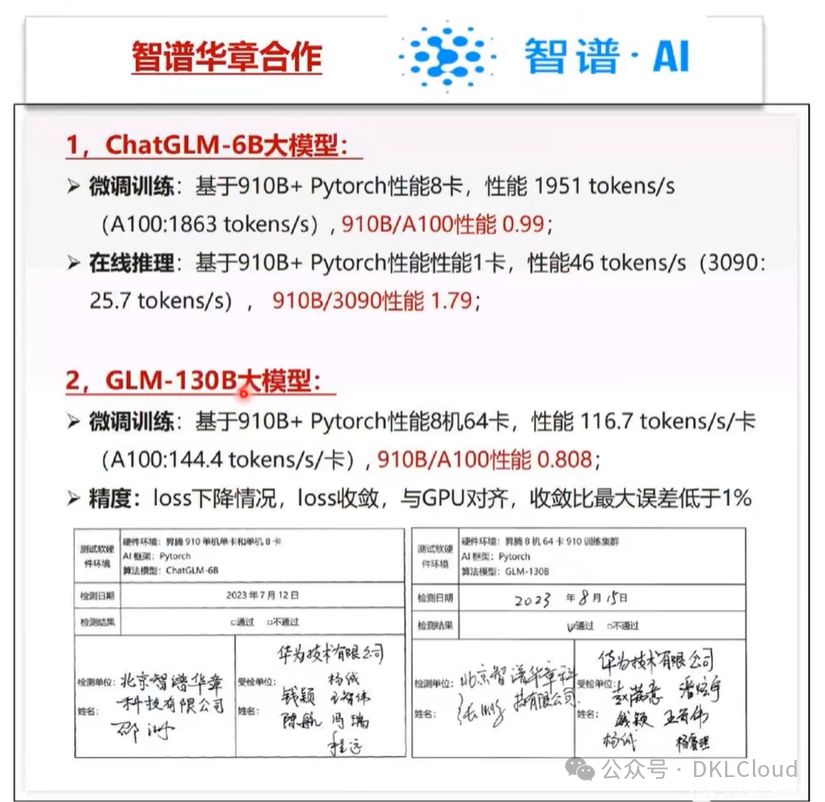
华为异腾与英伟达对标

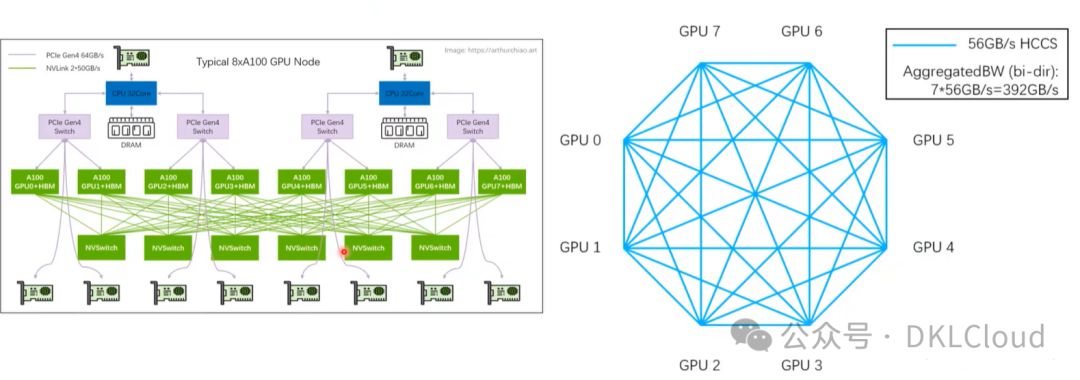
Nvlink与HCCS对比分析
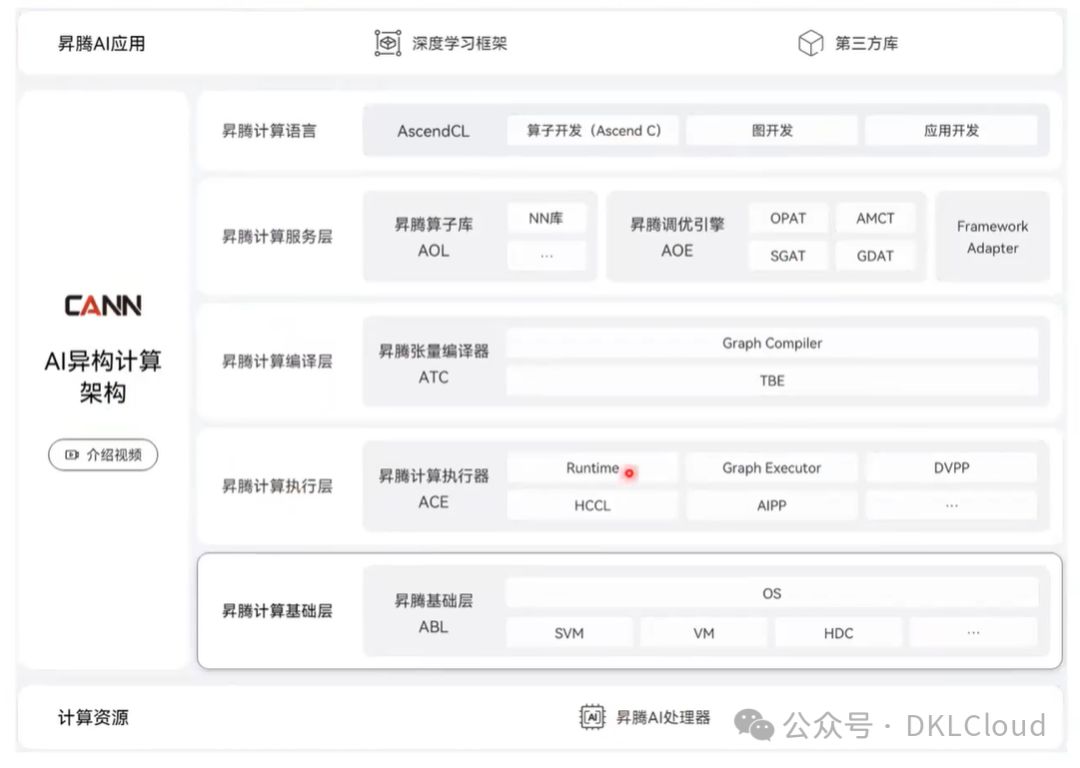
昇腾全栈 AI 软硬件平台

寒武纪MLU

MLU 370 系列
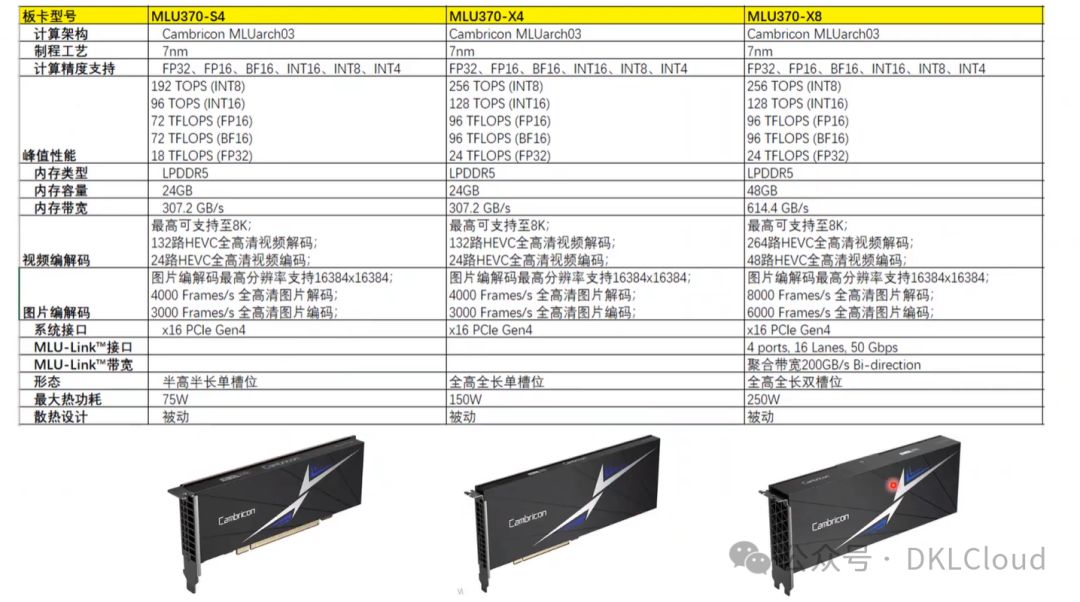
从芯片封装成整卡
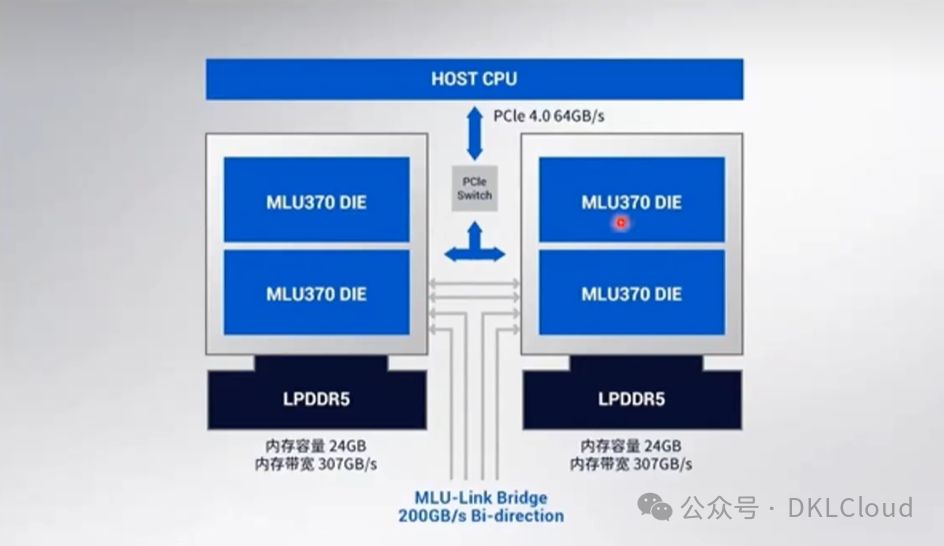
MLU-Link多芯互联

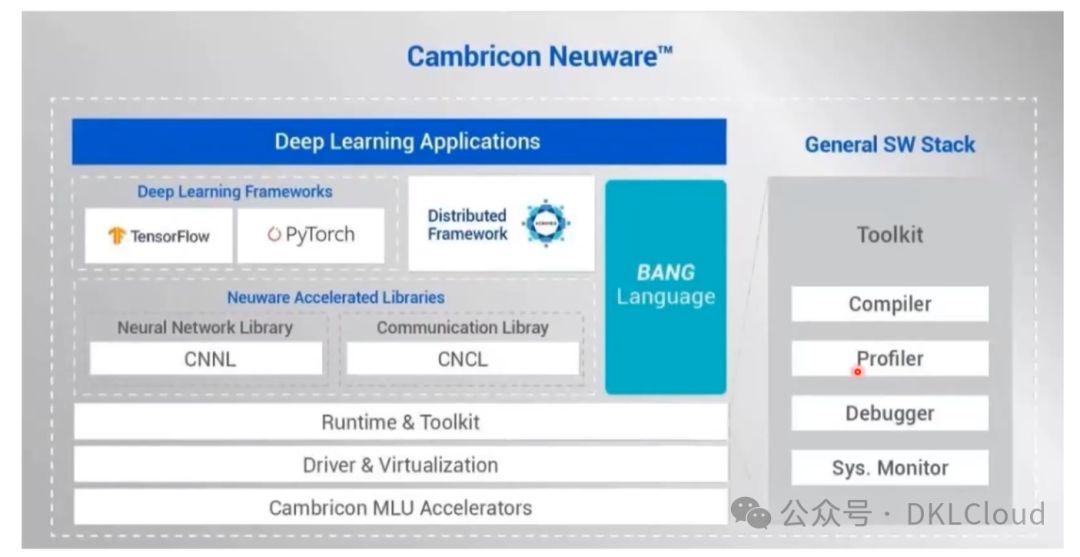
寒武纪基础软件平台

寒武纪Neuware
5、海光DCU
海光目前主流型号 Z100系列
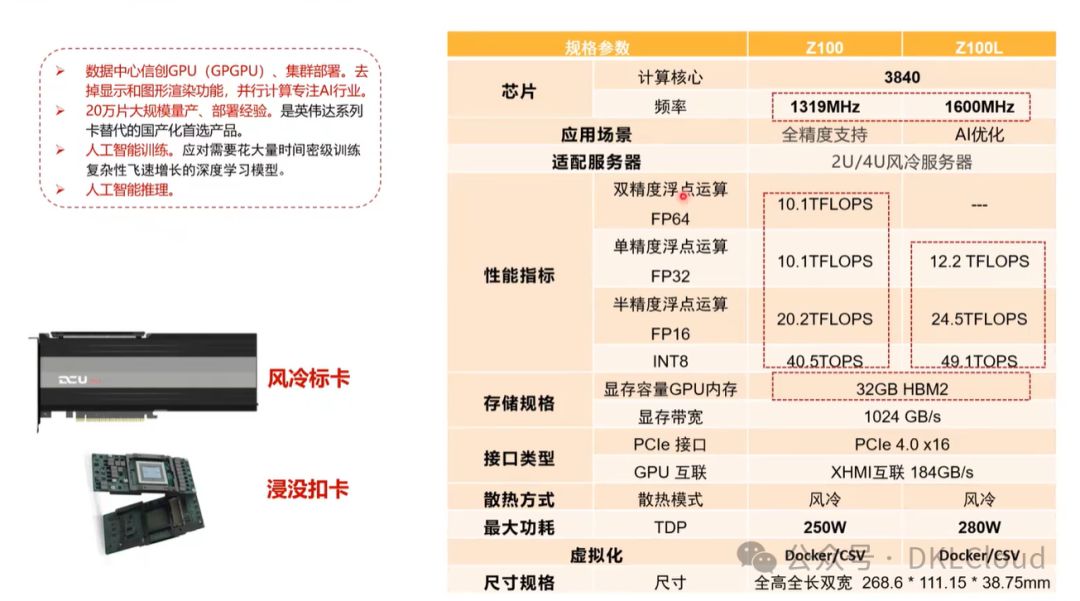
海光DTK (DCU Toolkit)

-对此,您有什么看法见解?-
-欢迎在评论区留言探讨和分享。-