目前大多数单细胞分析管道仅限于细胞嵌入,并且严重依赖于聚类,而缺乏显式建模不同特征类型之间相互作用的能力。此外,这些方法适合于特定的任务,因为不同的单细胞问题的表述方式不同。为了解决这些缺点,SIMBA作为一种图嵌入方法,它将单个细胞及其定义特征(如基因、染色质可及区域和DNA序列)共同嵌入到一个共同的潜在空间中。通过利用细胞和特征的联合嵌入,SIMBA允许研究细胞异质性、marker发现、基因调控推断、批次效应去除和组学集成。SIMBA提供了一个单一的框架,允许以统一的方式制定各种单细胞问题,从而简化了新分析的开发和扩展到新的单细胞模态。
来自:SIMBA: single-cell embedding along with features
目录
- 方法概述
- 结果
- scRNA-seq分析
- scATAC-seq分析
- 多模态分析
- scRNA-seq批次整合
- 多组学整合
- 指标计算
方法概述
SIMBA是一种支持单或多模态分析的单细胞嵌入方法。它利用最新的图嵌入技术将细胞和基因组特征嵌入到共享的潜在空间中。与现有的主要集中于学习细胞状态的方法不同,SIMBA将细胞和特征都视为同一图中的节点,从而通过统一的过程解决各种单细胞任务。重要的是,SIMBA引入了几个关键程序,包括Softmax变换、控制过拟合的权重衰减和实体类型约束,以生成细胞和特征的可比较嵌入(联合嵌入),并解决单细胞数据中的独特挑战。
SIMBA首先将不同类型的实体,如细胞、基因、开放染色质区域(峰或箱)、转录因子(TF)基序和k-mers(特定长度k的短序列)编码成单个图(图1),其中每个节点代表一个单独的实体,边表示实体之间的关系。
在SIMBA中,可以通过(1)实验测量或(2)计算推断两种方式添加边。对于实验测量的边,每个cell-feature edge对应于单细胞测量数据。例如,如果一个基因在一个细胞中表达,那么在基因和细胞之间就会产生一条边。这条边的权重由基因表达水平决定。类似地,如果染色质区域在细胞中是开放的,则在细胞和染色质区域之间添加一条边。还允许在不同特征之间使用边来捕获和建模潜在的调控机制。例如,染色质区域和TF基序(或k-mer)之间的边捕获了TF可能结合到包含特定DNA序列的调控区域。不能直接测量的边通过汇总相同或不同类型的特征来计算推断。不同批次或模态的细胞之间的每条边都表示细胞功能或结构的相似性。图1总结了由边表示的潜在关系和SIMBA中提出的分析的语义,即:(cell-gene),细胞表达给定的基因;(cell-peak),细胞有一个可接近的染色质区域;(peak- TFmotif),峰序列包含给定TF的可能结合位点;(peak-kmer),一个峰序列包含一个给定的k-mer序列;(cell-cell) 不同批次或模态的细胞在功能或结构上是相似的。
一旦构建了输入图,SIMBA使用无监督图嵌入方法计算图节点的低维表示,利用PyTorch-BigGraph框架,可以扩展到数百万个细胞。由此产生的细胞和特征的联合嵌入不仅重建了细胞的异质性,而且还允许发现每个细胞的定义特征,而不依赖于聚类,将细胞类型特异性(信息)特征与非细胞类型特异性(非信息)特征分开。SIMBA嵌入中的proximity反映了边的概率,即图中存在边的可能性,并提供了特征重要性或特征之间相互作用的信息。
细胞类型特异性特征,如marker基因和顺式调控元件(cREs),可以通过两种方式在没有聚类的情况下被发现。有了已知的细胞标签,marker特征可以通过生物学查询识别为细胞的邻近特征。在没有已知标签的情况下,可以通过使用诸如基尼指数之类的度量来计算特征和所有细胞之间边概率的不平衡来识别marker特征。重要的是,图构造具有固有的灵活性,使SIMBA能够应用于各种单细胞任务。

- 图1:SIMBA 将单细胞实验期间测量的细胞和各种特征共同嵌入到共享潜在空间中,以完成单细胞数据分析中涉及的常见任务以及单细胞基因组学中仍为未解决的问题。左侧是 SIMBA 可能编码的生物实体示例,包括细胞、基因表达测量、染色质可访问区域、已经发现的 TF 基序和 k-mer 序列。中间是 SIMBA 将多种类型的实体嵌入到低维空间的嵌入图。所有以形状表示的实体按相关细胞类型着色(此示例中为绿色、橙色和蓝色)。非信息性特征为深灰色。在图中,每个实体都是一个节点,边表示实体之间的关系。一旦在图中连接起来,这些实体就可以嵌入到共享的低维空间中。右图,可以使用 SIMBA 完成常见的单细胞分析任务。不同的不透明度级别表示不同实验批次或模态的细胞。实线表示实验测量的边。虚线表示计算推断的边。
结果
scRNA-seq分析
scRNA-seq是最广泛使用的单细胞模态。图2a提供了SIMBA图构建和结果低维嵌入矩阵的示意概述,在scRNA-seq分析中同时包含细胞和基因。SIMBA将标准化的基因表达矩阵离散化为多个水平(默认为五个水平)。然后,根据基因表达水平通过加权边连接细胞和基因构建输入图。随后,SIMBA通过图嵌入程序生成这些节点的嵌入(见图2a)。根据任务,我们可以完全灵活地使用UMAP可视化整个SIMBA嵌入(见补充图1c中的细胞和所有基因的嵌入)或部分SIMBA嵌入(见图2b中的细胞的嵌入,或图2c中的细胞和高变基因的嵌入,或感兴趣的任何实体的嵌入)。

- 图2a:生物实体,包括细胞和基因,被表示为不同形状,并按相关细胞类型(绿色和橙色)进行着色。无信息的基因被着为深灰色。每个细胞的基因表达测量值被组织成cell-gene矩阵。这些标准化的非负观察值经过离散化,分为五个基因表达水平。然后将细胞和基因组装成一个图,其中节点表示细胞和基因,它们之间的边表示不同的基因表达水平。然后可以将该图嵌入到较低维度的空间中,得到一个实体数量 × 维度数量(默认为50)的SIMBA嵌入矩阵。

- 补充图1c:所有细胞+基因的embedding可视化。
将SIMBA应用于来自10x Genomics的流行外周血单核细胞(PBMCs)数据集。细胞的SIMBA embedding显示出8种细胞类型的清晰分离,包括B细胞、巨核细胞、CD14单核细胞、FCGR3A单核细胞、树突状细胞、NK细胞、CD4 T细胞和CD8 T细胞(图2b)。

- 图2b:细胞的embedding
细胞和基因的SIMBA embedding都正确地恢复了细胞异质性,并保留了接近相关细胞类型的信息基因(图2c)。先前用于注释细胞的标记基因在UMAP图上被突出显示,表明SIMBA不仅准确地将主要细胞群特异性基因嵌入到正确的位置(例如,IL7R15嵌入到CD4 T细胞中,MS4A1嵌入到B细胞中),而且对罕见细胞群特异性基因(例如,PPBP嵌入到巨核细胞中)也具有鲁棒性,而非信息性基因,如GAPDH和B2M,嵌入所有细胞组的中间(图2c)。

- 图2c:细胞和指定gene的embedding
这些突出显示的基因可以通过“barcode plots”进一步确认,barcode plot显示了SIMBA根据预测的边置信度将特征分配给细胞的估计概率(图2d)。概率的不平衡表明基因与细胞亚群(通常对应于已知的细胞类型)的关联,而均匀的概率分布表明非细胞类型特异性基因。对于标记基因(CST3用于单核细胞和树突状细胞,MS4A1用于B细胞,NGK7用于NK细胞和CD8 T细胞),观察到将每个基因分配到各自细胞类型的概率明显过高。相反,对于housekeeping基因GAPDH,我们观察到更均匀的分布,将该基因与排名靠前的细胞联系起来的可能性要低得多。

- 图2d:barcode plot
SIMBA还提供了几个定量指标(称为“SIMBA指标”),包括最大值、基尼指数、标准差(s.d)和熵,以评估各种特征的细胞类型特异性,而不需要预先了解诸如预定义的细胞类型。通过检查最大值与基尼指数的基因度量图(值越高表明细胞类型特异性越高),可以观察到marker基因(如CST3, NKG7, MS4A1)位于右上角,而housekeeping基因(如GAPDH)位于左下角(图2e)。通过在UMAP图(图2f)上可视化marker基因的表达模式,进一步证实了所选marker基因的细胞类型特异性。

- 图2e和f
实际上,SIMBA不需要可变基因选择,而可变基因选择是标准scRNA-seq管道(如Seurat或Scanpy)的重要步骤。在进行或不进行可变基因选择测试时,SIMBA产生的嵌入质量相似。然而,在应用中,高变基因选择是为了提高训练过程的效率。
scATAC-seq分析
scATAC-seq已被广泛用于分析开放染色质区域和鉴定功能性顺式调控元件,如增强子(enhancers)和活性启动子(active promoters)。
细胞具有不同类型的特征,如可访问的染色质区域(“peaks”或“bins”)和顺式调控元件(DNA序列),包括TF基序或k-mers。现有方法只能使用peaks或bins(区间)或DNA序列,SIMBA可以利用单个或多个类型的特征来学习细胞状态,因为它在图构建方面具有灵活性。此外,由于SIMBA将细胞特征或特征之间的关系编码到图中,基于特征的简单二进制存在,因此它不需要额外的归一化步骤,例如大多数scATAC-seq分析所需的TF-IDF预处理(图3a)。
通过嵌入过程,SIMBA生成细胞以及peaks和DNA序列的嵌入。最后,可以将部分SIMBA嵌入(图3b中细胞的嵌入)或整个SIMBA嵌入(图3c中细胞和所有特征的嵌入)可视化。

- 图3a:SIMBA图构建和在scATAC-seq分析中的嵌入。包括细胞、峰值peaks或区间bins、TF基序和k-mers在内的生物实体,并根据相关细胞类型(绿色和橙色)着色。非信息特征着以深灰色。细胞和染色质可访问特征(峰值/区间)被组织成cell×peaks/bins矩阵。当这些区域内的序列信息(TF基序或k-mer序列)可用时,它们可以被组织成两个子矩阵,以将TF基序或k-mer序列与每个peaks或bins关联起来。然后,这些构建的特征矩阵被二值化并组装成图。当使用单个特征(染色质可访问性)时,图将细胞和峰值/区间编码为节点。当使用多个特征(染色质可访问性和DNA序列)时,这个图可以通过添加TF基序和k-mer序列作为节点来扩展。最后,通过图嵌入过程生成这些实体的SIMBA嵌入。
作者将SIMBA应用于2034个具有荧光激活细胞分选(FACS)特征细胞类型的scATAC-seq数据集。如图3b所示,对于单独的细胞embedding,SIMBA准确地分离了细胞,从而在视觉上区分了属于不同细胞类型的细胞(根据FACS标签定义)。对于不同类型特征的细胞嵌入,如图3c所示,SIMBA根据其生物学关系成功地将来自位置(peaks/bins)和序列内容(TF motif和k-mers)信息的不同特征嵌入在一起。值得注意的是,在SIMBA指标的基础上,嵌入在每种细胞类型中的这些突出显示的特征都具有很高的细胞类型特异性评分(图3d的右上方)。

- 图3d

- 图3b,c,e,f,g:c.细胞和特征的SIMBA嵌入的UMAP可视化,包括TF motif,k-mers和peaks。细胞按细胞类型着色,基序、k-mers和peaks分别为绿色、蓝色和粉红色。嵌入在相应细胞类型附近的特定于细胞类型的特征以带有箭头的文本标签(根据特征类型的颜色)表示。e.排列的scATAC-seq片段的基因组轨迹,按细胞类型分离和着色。两个marker峰P1和P2(红色)显示在对齐的下方。在P1峰内,k-mer GATAAG及其类似GATA1的motif标志被突出显示。f.通过GATA1 motif的TF活性评分和k-mer GATAAG富集着色的细胞SIMBA嵌入的UMAP可视化。
- g.GATA1 motif、k-mer GATAAG和P1、P2两个峰的SIMBA barcode plots。根据上面描述的细胞类型标签给细胞着色。红色虚线表示在所有四个图中相同的截止点。
使用SIMBA进行的分析导致了PBMC分化的几个关键发现。首先,SIMBA确定了造血的关键主调控因子(regulators)。如图3c所示,可以观察到先前报道的TF motif嵌入在UMAP图中各自的细胞类型附近。例如,GATA1和GATA3基序靠近megakaryocyte-erythroid progenitor(MEP) cells,PAX5和EBF1基序靠近common lymphoid progenitor(CLP) cells,CEBPB和CEBPD基序靠近monocyte(mono)群体。
其次,SIMBA揭示了一组无偏的DNA序列,即k-mers,它们代表了造血过程中重要的TF结合基序。可以观察到,这些k-mers嵌入在与其匹配的TF结合基序和相关细胞亚群附近(图3c和e),表明SIMBA能够从头发现基序。例如,DNA序列GATAAG嵌入到MEPs中,这个序列与GATA1的结合基序相匹配,GATA1是erythropoiesis的主要调节因子。作者还计算了TF/k-mer活性评分(高方差TF motif/k-mer),并在细胞的SIMBA嵌入上进行可视化(图3f)。例如,通过SIMBA嵌入MEP细胞的GATA1 TF motif和k-mer GATAAG在MEP细胞中也显示出高水平的活性。
第三,SIMBA鉴定了可能介导细胞类型特异性基因调控的差异可达染色质区域。例如,KLF1基因基因组位点附近的两个峰,坐标chr19:12997999-12998154 (P1)和chr19:12998329-12998592 (P2),嵌入在MEP细胞中,几乎只在MEP细胞中观察到(图3e)。有趣的是,KLF1上游的P1含有与GATA1结合基序匹配的k-mer GATAAG,而已知TF GATA1调控KLF1基因,在红细胞(erythroid cell)和巨核细胞(megakaryocyte)发育中起关键作用。因此,通过将这些MEP细胞相关调控元件嵌入到MEP细胞附近,SIMBA为研究细胞分化的表观遗传景观提供了一种新的手段。
尽管SIMBA与目前的scATAC-seq分析方法不同,可以实现细胞和特征的联合嵌入,但作者仍然在定性和定量上比较了SIMBA嵌入细胞与最先进的scATAC-seq分析方法区分细胞类型的能力。分析表明,SIMBA总体上优于当前的scATAC-seq分析方法。作者还表明,在将序列作为附加特征包含时,SIMBA对细胞嵌入的影响可以忽略不计。
多模态分析
最近发展的单细胞多组学技术可以联合分析同一细胞内的转录组和染色质可及性,为探索基因调控原理提供了一种手段。SIMBA能够从单细胞多组学数据中学习细胞异质性和基因调控网络。图4a描述了图的构造和SIMBA嵌入过程。基因表达矩阵和染色质可达性(peaks)、TF基序和k-mer匹配矩阵分别被离散化和二值化,通过在细胞、基因、峰、TF基序和k-mer等五种实体(节点)类型之间创建边来构建图。图嵌入过程生成细胞和特征的SIMBA嵌入。为了避免非信息性峰值占据空间,作者利用SIMBA嵌入的灵活性,仅可视化部分SIMBA嵌入,以提高细胞和细胞类型特异性特征的可见性。

- 图4a:SIMBA的多模态(scRNA-seq + scATAC-seq)数据分析方法概述。
为了证明SIMBA嵌入的多功能性,作者分析了SHARE-seq测量的小鼠皮肤毛囊分化细胞群。首先,作者计算SIMBA指标(最大值和基尼指数得分)来评估不同类型特征的细胞类型特异性,包括基因、TF motif和峰(图4b)。如图4b所示,作者成功恢复了与毛囊相关的基因,如Lef1和Hoxc13。同样,这些基因的基因组位点附近的TF基序和峰也在度量图的右上象限得分。

- 图4b
接下来,我们可视化(1)细胞的SIMBA嵌入,(2)基于SIMBA指标的细胞排名靠前的基因,(3)基于SIMBA指标的细胞、排名靠前的基因和TF基序及其相邻峰(图4c)。细胞的SIMBA embedding揭示了transit-amplifying cells (TACs)的三个命运,包括inner root sheath(IRS)、medulla、cuticle和cortex。细胞的SIMBA嵌入和信息特征揭示了沿hair-follicle分化轨迹的重要基因和调节因子。例如,将标记基因Krt71、Krt31和Foxq1分别嵌入相应的细胞类型:IRS、cuticle / cortex 和 medulla。调控因子Lef1和Hoxc13分别嵌入cuticle / cortex分化的初期和后期。Lef1和Hoxc13位点附近的峰也嵌入到这些基因和基序的附近区域。TF-motif的距离可能表明TF的表达与其结合活性之间存在滞后。例如,pioneer factors可以绑定到无法进入的区域,帮助其他factors打开这些区域。
在图4c中,Hoxc13基因出现的时间早于其基序,这与之前的一项研究一致,该研究表明Hoxc13具有结合不可接近的基序的能力。报告的marker基因和TF motif也得到了UMAP和SIMBA barcode plots的支持,有很高的概率指向正确的细胞类型标签。作者还在SHARE-seq数据集中进行了scRNA-seq和scATAC-seq单模态分析,并获得了与多模态分析一致的嵌入结果,表明SIMBA嵌入过程对输入图中编码的特征类型和数量具有鲁棒性。
此外,作者证明了细胞和特征的SIMBA共嵌入空间提供了识别主调控因子并推断其靶调控基因的潜力。SIMBA成功地识别了先前描述的主调控因子,如Lef1、Gata6、Nfatc1和Hoxc13,作为与小鼠皮肤谱系相关的顶级主调控因子(图4d)。

- 图4c,d,e
为了推断给定主调控因子的靶基因,作者假设,在共享的SIMBA嵌入空间中,(1)靶基因与TF基序和TF基因都很接近;(2)目标基因位点附近的可达区域(峰)必须既靠近TF基序又靠近TF基因。基于这两个顺势调控的动力学假设(图4e),SIMBA推断出主调控因子的靶基因,如Lef1和Hoxc13(图4f,补充图12e和补充表4)。值得注意的是,SIMBA恢复了原始研究中报道的靶基因,包括TF Lef1调控的Lef1、Jag1、Hoxc13和Gtf2ird1基因,以及TF Hoxc13调控的Cybrd1、Hoxc13和St14基因。

- 图4f
数据集其实来自:Ma-2020
scRNA-seq批次整合
SIMBA通过将多个scRNA-seq数据集编码成单个图来完成批次校正(图5a)。不同批次的细胞节点通过实验测量的边连接到共享基因节点,就像在scRNA-seq图构建中一样。通过使用基于截断的随机奇异值分解(SVD)的过程,在数据集上的相似细胞节点之间绘制计算推断的边,进一步增强了批校正。从生成的图中,SIMBA生成细胞和基因的批校正嵌入,允许通过对共享潜在空间中的细胞的生物查询进行单个细胞水平的marker检测。

- 图5a:批校正分析中SIMBA图的构造与嵌入。透明度表示批次。
多组学整合
SIMBA分别为scRNA-seq和scATAC-seq数据构建独立的图,在共享基因表达模块的基础上通过计算推断的边将它们连接起来,并将细胞、基因和峰的图嵌入到一个低维空间中,表示多模态的集成空间(图6a)。这使得通过在SIMBA空间中对细胞进行生物学查询,可以在单个细胞水平上检测多种类型的特征。
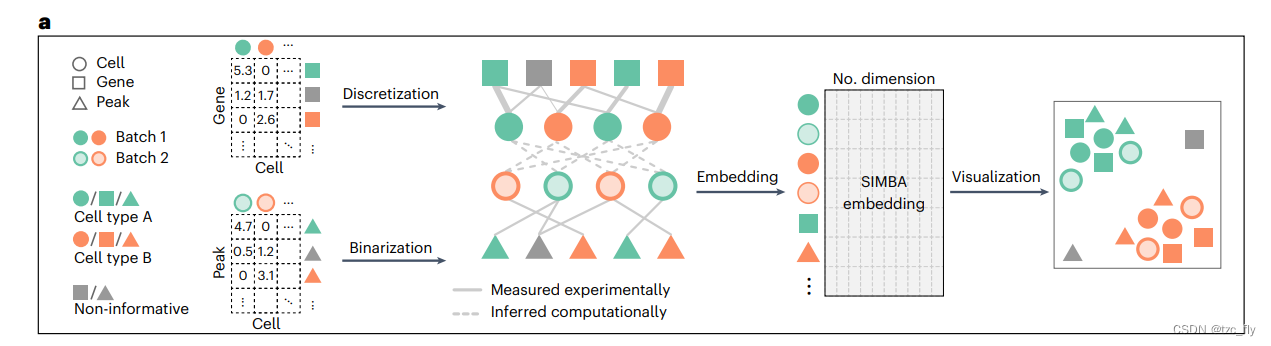
- 图6a:多组学整合的构造过程。
指标计算
SIMBA计算将特征分配给细胞的概率分数(表示为点积),因此为每个特征生成所有细胞的概率分布。在此基础上或其衍生的概率分布(如SIMBA barcode plot所示),四个指标可以从不同方面评估每个特征的细胞类型特异性。
平均前50个细胞的归一化概率的最大score作为对细胞类型分配的信心度量,并有助于过滤噪声特征(更高的值表明更高的细胞类型特异性)。基尼指数是由softmax变换后的概率分布计算得出的,用于评估与完全均匀分布的偏差,因此,显示不平衡分布(即细胞类型特异性)的特征被赋予更高的基尼指数值。S.d.测量概率分布的变异量,值越大表示细胞内偏差越大(即细胞类型特异性越强)。熵测量信息的内容,并捕获细胞在softmax变换后的概率分布上分布的程度,较低的熵表示分布几乎集中在细胞的一个子集上(较低的熵表示较高的细胞类型特异性)。
观察到这四个指标通常会给出一致的结果。对于每个SIMBA指标图,默认情况下,基尼指数是根据最大值绘制的。
对于特征 f j f_{j} fj,max被定义为前 k k k个细胞的平均标准化相似性(默认情况下, k = 50 k = 50 k=50)。相似度归一化函数定义为: n o r m ( x i ) = x i − l o g ∑ j = 1 n e x p ( x j ) n norm(x_{i})=x_{i}-log\frac{\sum_{j=1}^{n}exp(x_{j})}{n} norm(xi)=xi−logn∑j=1nexp(xj)其中, n n n为细胞数量, x j x_{j} xj表示特征 f j f_{j} fj的嵌入 v ^ f j \widehat{v}_{f_{j}} v fj与细胞 i i i嵌入的点积。
最大值为: m a x ( f j ) = ∑ i = 1 k n o r m ( x i ) k max(f_{j})=\frac{\sum_{i=1}^{k}norm(x_{i})}{k} max(fj)=k∑i=1knorm(xi)基尼系数为: g i n i ( f j ) = ∑ i = 1 n ( 2 i − n − 1 ) × p c i , f j n ∑ i = 1 n p c i , f j gini(f_{j})=\frac{\sum_{i=1}^{n}(2i-n-1)\times p_{c_{i},f_{j}}}{n\sum_{i=1}^{n}p_{c_{i},f_{j}}} gini(fj)=n∑i=1npci,fj∑i=1n(2i−n−1)×pci,fj其中, p c i , f j p_{c_{i},f_{j}} pci,fj表示特征 f j f_{j} fj与细胞 c i c_{i} ci存在边连接的概率。