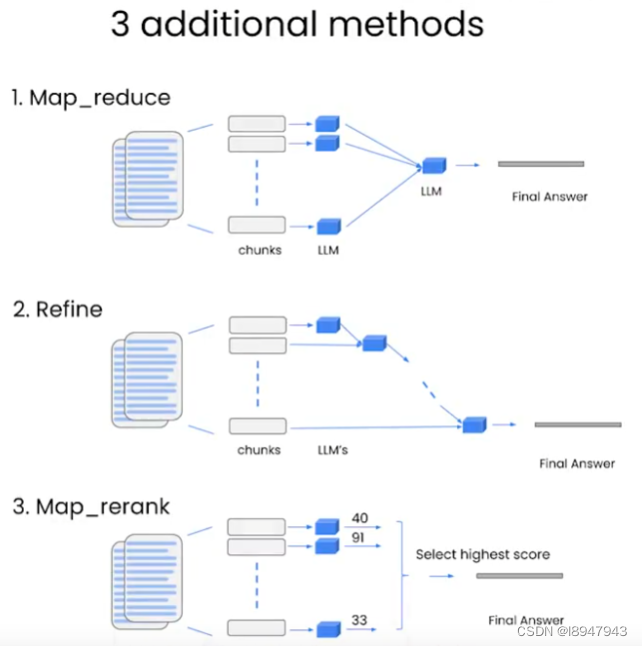
执行下面这段代码后,为什么返回的是 2 ?
vector = torch.tensor([7, 7])
vector.shape
为什么返回的是 torch.Size([2])?
当你创建一个PyTorch张量时,它会记住张量中元素的数量和每个维度的大小。在你的代码中,torch.tensor([7, 7])创建了一个一维张量,其中包含两个元素:7和7。因为这是一个一维张量,所以.shape属性返回一个只有一个元素的元组,该元素表示张量的长度。在这种情况下,张量的长度为2,因此返回的形状是torch.Size([2])。
tensor 的维度
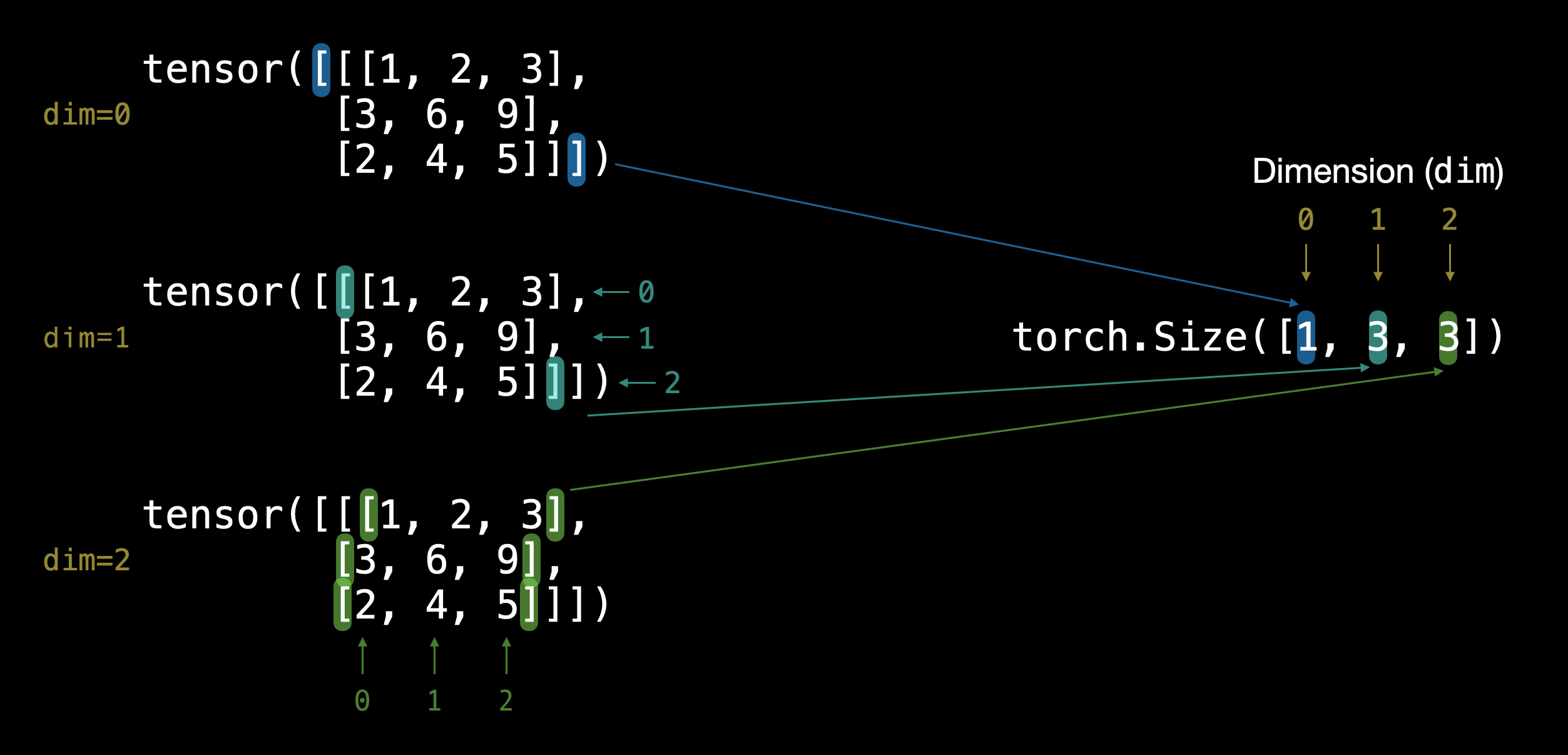
TENSOR = torch.tensor([[[1, 2, 3],[3, 6, 9],[2, 4, 5]]])
TENSOR.ndim
返回的是 [1,3,3] , 如何判断?有三层 [ ] 括号,将每个 [ ] 括号视为列表,从最里层起,当前列表有几个并列的元素,TENSOR.ndim 返回的列表最右边的元素就是几,然后去掉最外面一层的 [ ] 括号,继续判断当前列表有几个并列的元素,TENSOR.ndim 返回的列表次右边的元素就是几,依次类推。
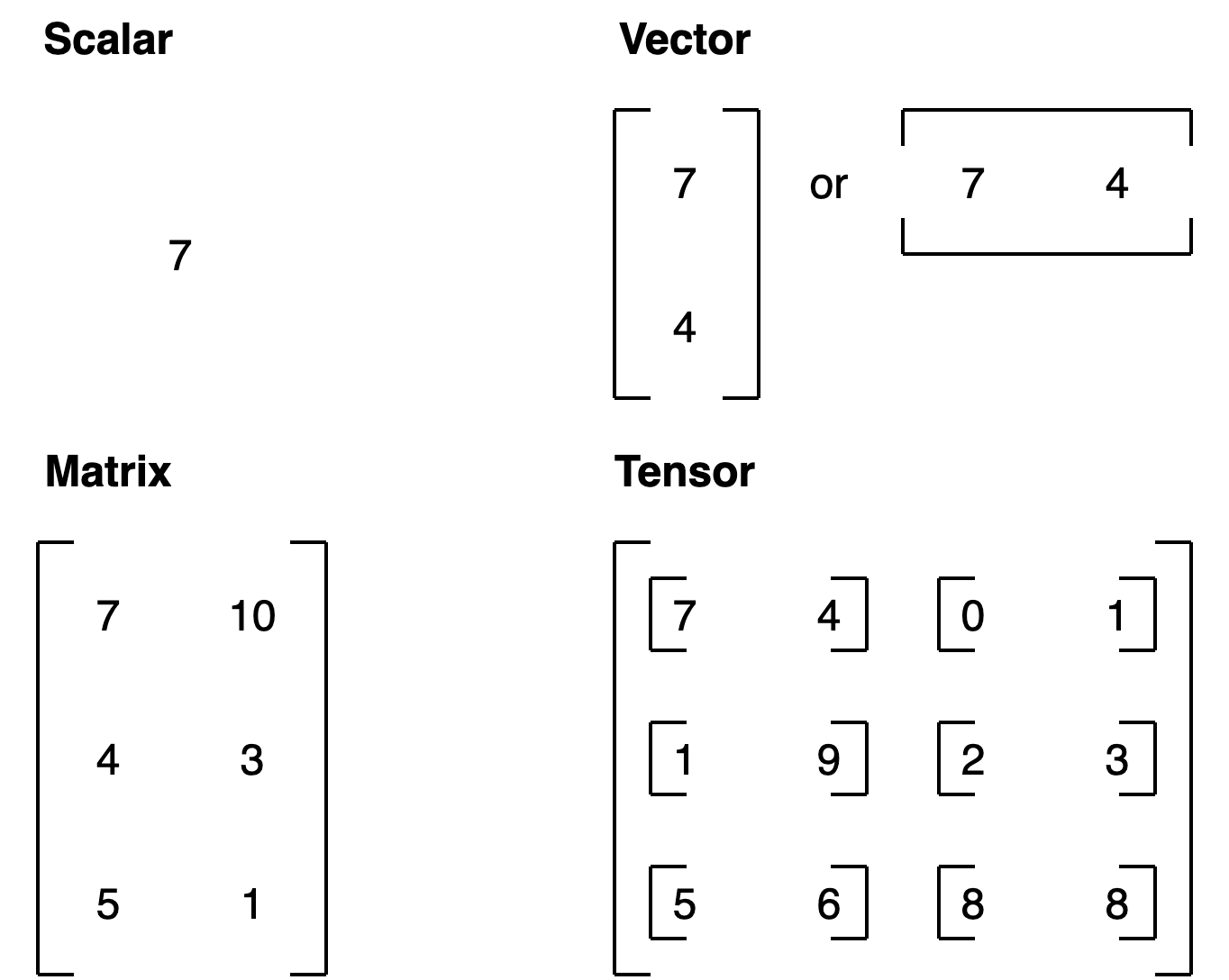
Scalar,Vector,Matrix,Tensor
torch.arange()
torch.arange() 返回的是 PyTorch 中的 tensor,而不是 NumPy 数组。
torch中对tensor的各种切片操作
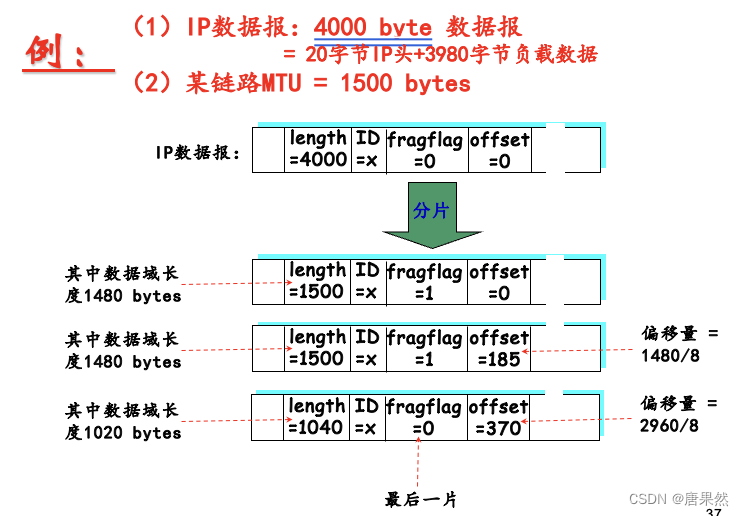
好的,让我们使用一个三维张量来详细解释各种复杂的切片操作。我们首先创建一个形状为 2 × 3 × 4 2 \times 3 \times 4 2×3×4 的三维张量:
import torch# 创建一个形状为 2x3x4 的三维张量
tensor = torch.arange(24).reshape(2, 3, 4)
print("Original Tensor:")
print(tensor)
假设我们有一个如下所示的三维张量:
tensor([[[ 0, 1, 2, 3],[ 4, 5, 6, 7],[ 8, 9, 10, 11]],[[12, 13, 14, 15],[16, 17, 18, 19],[20, 21, 22, 23]]])
1. 选择特定的切片
选择第一个维度的第一个子张量
slice_1 = tensor[0, :, :]
print("Slice along the first dimension (index 0):")
print(slice_1)
输出:
tensor([[ 0, 1, 2, 3],[ 4, 5, 6, 7],[ 8, 9, 10, 11]])
选择第二个维度的第二个子张量
slice_2 = tensor[:, 1, :]
print("Slice along the second dimension (index 1):")
print(slice_2)
输出:
tensor([[ 4, 5, 6, 7],[16, 17, 18, 19]])
选择第三个维度的第三个子张量
slice_3 = tensor[:, :, 2]
print("Slice along the third dimension (index 2):")
print(slice_3)
输出:
tensor([[ 2, 6, 10],[14, 18, 22]])
2. 高级切片操作
选择第一个维度的第一个子张量中的第1到第2行(不包括第2行)
slice_4 = tensor[0, 0:1, :]
print("Slice along the first dimension (index 0) and rows 0 to 1:")
print(slice_4)
输出:
tensor([[0, 1, 2, 3]])
选择第二个维度的第0和第2行,并选择所有列
slice_5 = tensor[:, [0, 2], :]
print("Select rows 0 and 2 from the second dimension:")
print(slice_5)
输出:
tensor([[[ 0, 1, 2, 3],[ 8, 9, 10, 11]],[[12, 13, 14, 15],[20, 21, 22, 23]]])
选择第三个维度的第1和第3列
slice_6 = tensor[:, :, [1, 3]]
print("Select columns 1 and 3 from the third dimension:")
print(slice_6)
输出:
tensor([[[ 1, 3],[ 5, 7],[ 9, 11]],[[13, 15],[17, 19],[21, 23]]])
3. 使用布尔张量进行索引
选择大于10的元素
mask = tensor > 10
slice_7 = tensor[mask]
print("Elements greater than 10:")
print(slice_7)
输出:
tensor([11, 12, 13, 14, 15, 16, 17, 18, 19, 20, 21, 22, 23])
4. 使用长整型张量进行索引
选择第1和第3列的数据
indices = torch.tensor([1, 3])
slice_8 = tensor[:, :, indices]
print("Select columns indexed by [1, 3]:")
print(slice_8)
输出:
tensor([[[ 1, 3],[ 5, 7],[ 9, 11]],[[13, 15],[17, 19],[21, 23]]])
5. 花式索引
使用多个索引数组
rows = torch.tensor([0, 1])
cols = torch.tensor([2, 3])
slice_9 = tensor[0, rows, cols]
print("Fancy indexing with rows and cols:")
print(slice_9)
输出:
tensor([2, 7])
通过这些示例,希望你对 PyTorch 中的张量索引和切片操作有了更深入的理解。这些操作在数据预处理、特征提取和神经网络模型的实现中非常重要。
torch 中 tensor 的各种乘法
在 PyTorch 中,有多种实现张量相乘的方式,每种方式在实现上有一些差异,有些是就地操作,有些不是。以下是几种主要的实现方式:
1. 元素级相乘 (Element-wise Multiplication)
要求两个 tensor 的 shape 一致
使用 * 操作符
import torcha = torch.tensor([[1, 2], [3, 4]])
b = torch.tensor([[5, 6], [7, 8]])result = a * b
print(result)
使用 torch.mul()
result = torch.mul(a, b)
print(result)
就地操作
使用 mul_() 方法:
a.mul_(b)
print(a)
2. 矩阵乘法 (Matrix Multiplication)
使用 @ 操作符 (Python 3.5+)
result = a @ b.T # 转置 b 以使其形状匹配矩阵乘法要求
print(result)
使用 torch.matmul()
result = torch.matmul(a, b.T)
print(result)
使用 torch.mm()(仅适用于二维张量)
result = torch.mm(a, b.T)
print(result)
3. 广义点积 (Dot Product for 1D tensors)
使用 torch.dot()
c = torch.tensor([1, 2, 3])
d = torch.tensor([4, 5, 6])result = torch.dot(c, d)
print(result)
4. 批量矩阵乘法 (Batch Matrix Multiplication)
使用 torch.bmm()
e = torch.randn(10, 3, 4) # 形状为 (batch_size, m, n)
f = torch.randn(10, 4, 5) # 形状为 (batch_size, n, p)result = torch.bmm(e, f)
print(result)
5. 广播相乘 (Broadcast Multiplication)
张量会自动广播到兼容的形状。
g = torch.tensor([1, 2, 3])
h = torch.tensor([[1], [2], [3]])result = g * h
print(result)
就地操作总结
就地操作会直接修改原始张量的值,通常以 _ 结尾:
a.mul_(b):就地进行元素级相乘
非就地操作会创建新的张量并返回结果,而不改变输入张量的值。
这些不同的乘法操作方式在不同的应用场景中有不同的用途,根据需要选择适合的乘法方式。
广播机制规则
广播机制遵循以下规则:
如果两个 tensor 的维度数不同,那么将维度较少的 tensor 的形状前面补1,直到维度数相同。
接着,对于每个维度,如果两个 tensor 在该维度上的长度相同,或者其中一个 tensor 在该维度上的长度为1,那么这两个 tensor 在该维度上是兼容的,可以进行广播。
广播后,在长度为1的维度上,该 tensor 会被扩展以匹配另一个 tensor 在该维度上的长度。
torch.stack()
torch.stack 是 PyTorch 中用于在新维度上连接一系列张量(tensor)的函数。它可以将一组形状相同的张量沿着指定维度堆叠成一个新的张量。详细解释如下:
函数签名
torch.stack(tensors, dim=0, *, out=None)
参数
tensors(sequence of Tensors): 要堆叠的一组张量。所有张量必须具有相同的形状。dim(int): 新维度的索引,定义堆叠的方向。默认值为0。out(Tensor, optional): 可选参数,用于存储输出的张量。
返回值
返回一个新的张量,该张量是在指定维度上堆叠输入张量生成的。
示例
假设有三个形状相同的张量,我们可以使用 torch.stack 将它们堆叠在一起。
import torch# 创建三个形状相同的张量
a = torch.tensor([1, 2, 3])
b = torch.tensor([4, 5, 6])
c = torch.tensor([7, 8, 9])# 在维度0上堆叠
stacked_tensor_0 = torch.stack([a, b, c], dim=0)
print(stacked_tensor_0)
# 输出:
# tensor([[1, 2, 3],
# [4, 5, 6],
# [7, 8, 9]])# 在维度1上堆叠
stacked_tensor_1 = torch.stack([a, b, c], dim=1)
print(stacked_tensor_1)
# 输出:
# tensor([[1, 4, 7],
# [2, 5, 8],
# [3, 6, 9]])
详细说明
- 当
dim=0时,新张量的第一个维度是堆叠的张量数量,后面的维度保持不变。在上面的示例中,stacked_tensor_0的形状为(3, 3)。 - 当
dim=1时,新张量的第二个维度是堆叠的张量数量,前面的维度保持不变。在上面的示例中,stacked_tensor_1的形状为(3, 3)。
注意事项
- 张量形状必须相同:要堆叠的所有张量必须具有相同的形状,否则会报错。
- 新维度的选择:指定的维度
dim会成为新张量的一个维度,原始张量的维度会相应地向后移动。
使用 torch.stack 可以方便地将多个张量组合成一个新张量,特别是在处理批量数据时非常有用。例如,在图像处理中,可以将多张图片沿着批次维度(通常是第0维)堆叠,形成一个批量张量以便进行批处理操作。
如何理解torch.stack中的dim?
如果进行stack的若干个tensor的维度个数都是n,那么torch.stack中的参数的dim的取值范围是0到n,对吗?

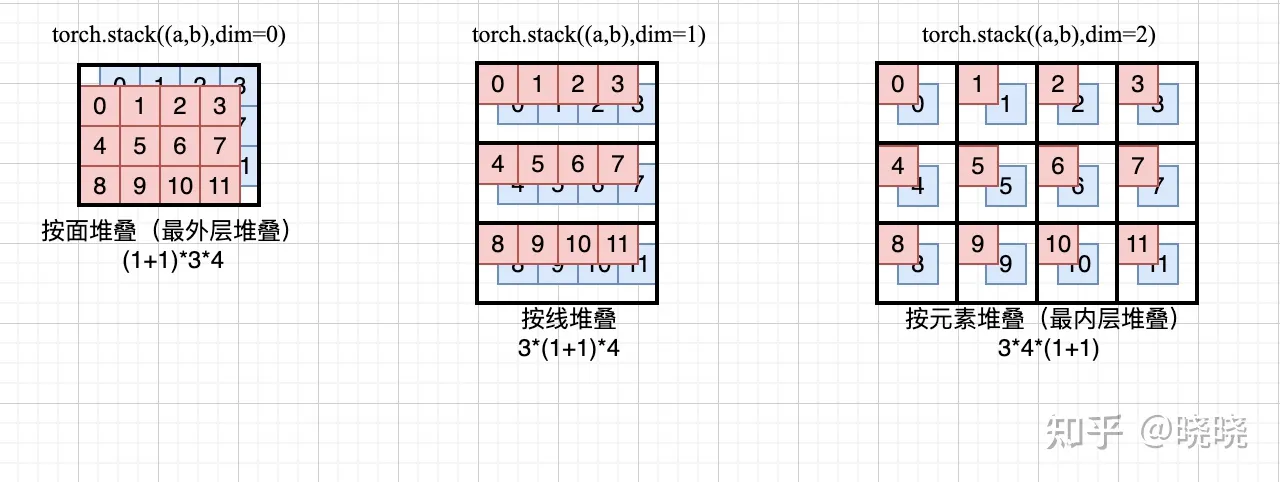
上图中 ,
- dim=0时,shape=(2,3,4) 2个3*4矩阵
- dim=1时, shape=(3,2,4) 3个2*4矩阵
- dim=2时,shape=(3,4,2) 3个4*2矩阵
这么理解,dim=0时,将所有要堆叠的tensor视为stack的元素,dim=1时,将所有要堆叠的tensor去掉最外层的一个[ ]括号对之后得到进行stack的元素,依此类推