作者主页:作者主页
数据结构专栏:数据结构
创作时间 :2024年5月18日
前言:
今天我们就给大家带来几种排序的讲解,包括冒泡排序,插入排序,希尔排序,选择排序,堆排序,快速排序等等,在讲解之前我先给大家一个网站,用于查看各种排序的动图,这样有助于我们更加清晰的去了解各种排序:排序动图
冒泡排序:
首先我们来讲解一下冒泡排序,这是我们学习编程第一个接触到的排序,也是较为容易理解的一个排序,下面我们来看一下她是如何实现的。
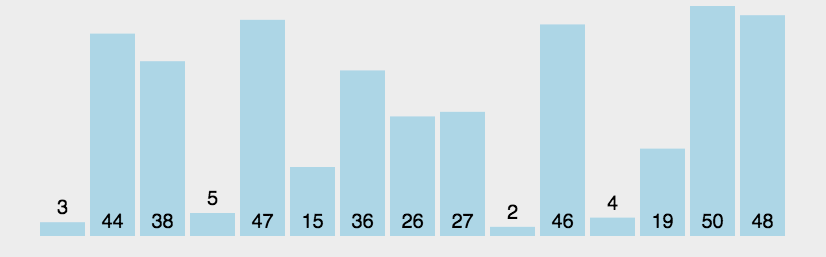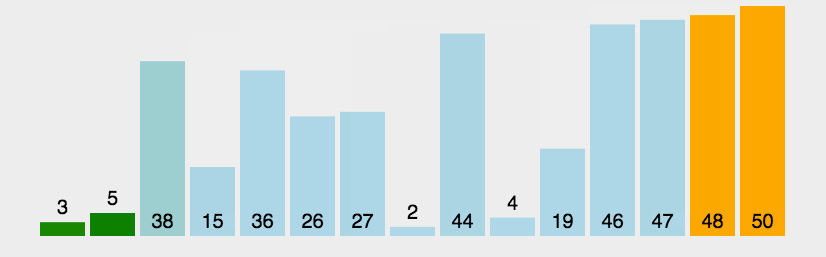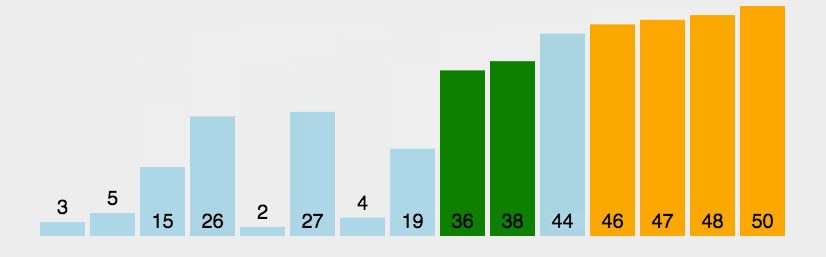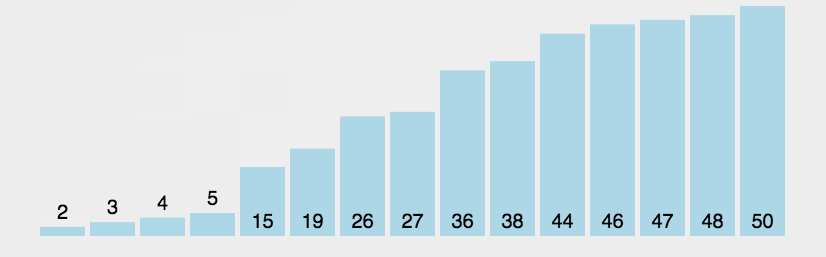
这就是一个大概的冒泡排序的实现过程,其实就是每次都把最大的一个放到最后面,然后下一轮就不需要去管后面最大的那几个。
下面我们来看一下代码应如何实现:
#include<stdio.h>
#include<iostream>
#include<algorithm>
using namespace std;void print(int* arr, int n)
{for (int i = 0; i < n; i++) {printf("%d ", arr[i]);}
}int main()
{int arr[] = { 23,235,13,123523,2342,2342,1,41523,3456,6547,546 };int n = sizeof(arr) / sizeof(arr[0]);for (int i = 0; i < n - 1; i++){for (int j = 0; j < n - 1 - i; j++) {if (arr[j] > arr[j + 1]) { swap(arr[j], arr[j + 1]);}}}print(arr, n);return 0;
}这就是冒泡排序实现的过程,这里我们就不过多的去说了,还是比较简单的。
时间复杂度:最坏情况:O(N^2)
最好情况:O(N)
空间复杂度:O(1)
插入排序:
下面我们来看一下插入排序,插入排序的步骤大概是这样的。
1.从第一个元素开始,该元素可以认为已经被排序
2.取下一个元素tem,从已排序的元素序列从后往前扫描
3.如果该元素大于tem,则将该元素移到下一位
4.重复步骤3,直到找到已排序元素中小于等于tem的元素
5.tem插入到该元素的后面,如果已排序所有元素都大于tem,则将tem插入到下标为0的位置
6.重复步骤2~5
图像演示:
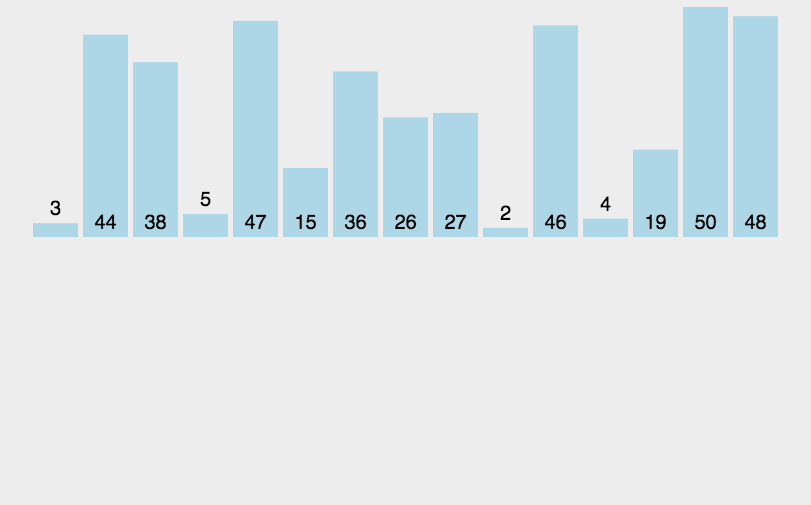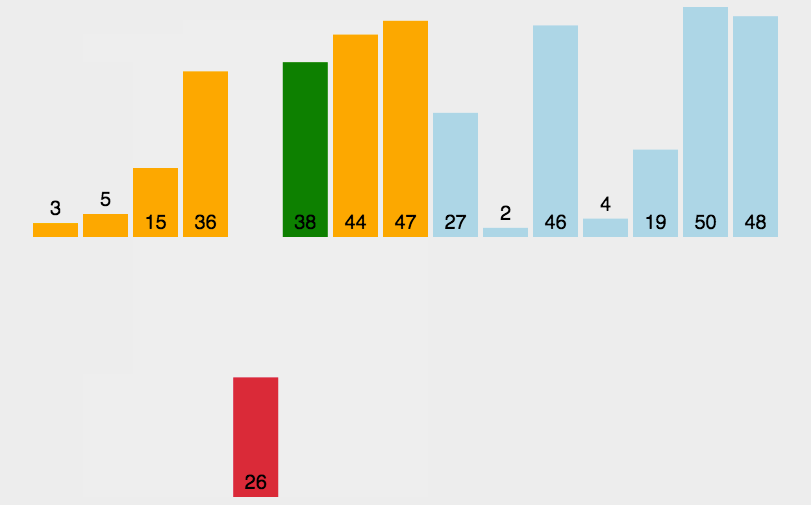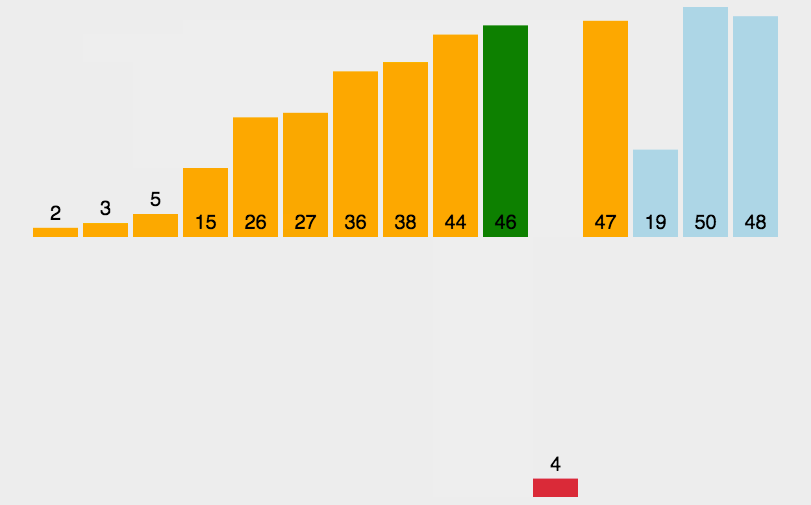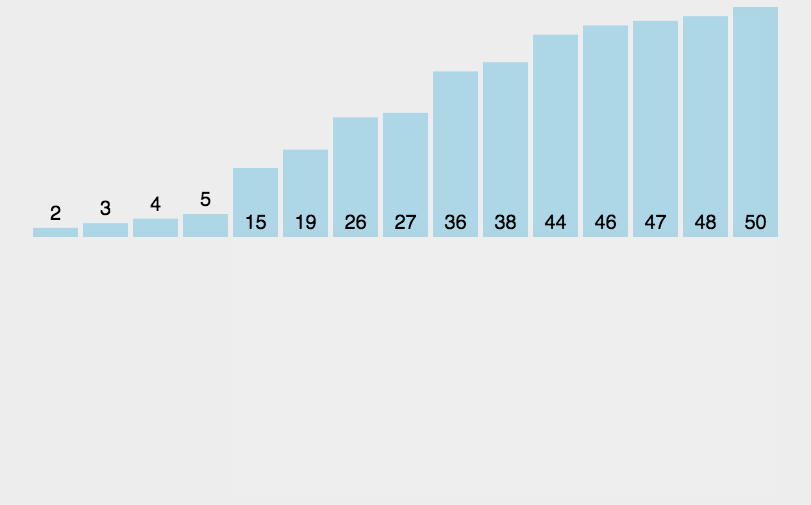
这个图像还是比较清晰易懂的,下面我们来看一下代码吧。
void InsertSort(int* arr, int n)
{for (int i = 0; i < n - 1; i++){int end = i;int temp = arr[end + 1];while (end >= 0){if (temp < arr[end]){arr[end + 1] = arr[end];end--;}else{break;}}arr[end + 1] = temp;}
}插入排序其实就是我们从第一个开始,然后我们用tmp记录要被插入的元素,然后一直和前面的作比较,如果大于前面的,那么就结束,如果小于前面的,我们就令end+1的位置等于end,然后end--就可以了,最后再将temp放到不符合这个条件的位置,就完成了一轮插入排序,后面也是这样循环进行的。
时间复杂度:最坏情况下为O(N*N),此时待排序列为逆序,或者说接近逆序
最好情况下为O(N),此时待排序列为升序,或者说接近升序。
空间复杂度:O(1)
希尔排序:
下面我们来讲一下希尔排序,这个排序其实是比较难懂的,但他的时间复杂度也是较为小的,下面我们看一下如何实现这个排序:
大致步骤:
1.先选定一个小于N的整数gap作为第一增量,然后将所有距离为gap的元素分在同一组,并对每一组的元素进行直接插入排序。然后再取一个比第一增量小的整数作为第二增量,重复上述操作…
2.当增量的大小减到1时,就相当于整个序列被分到一组,进行一次直接插入排序,排序完成。
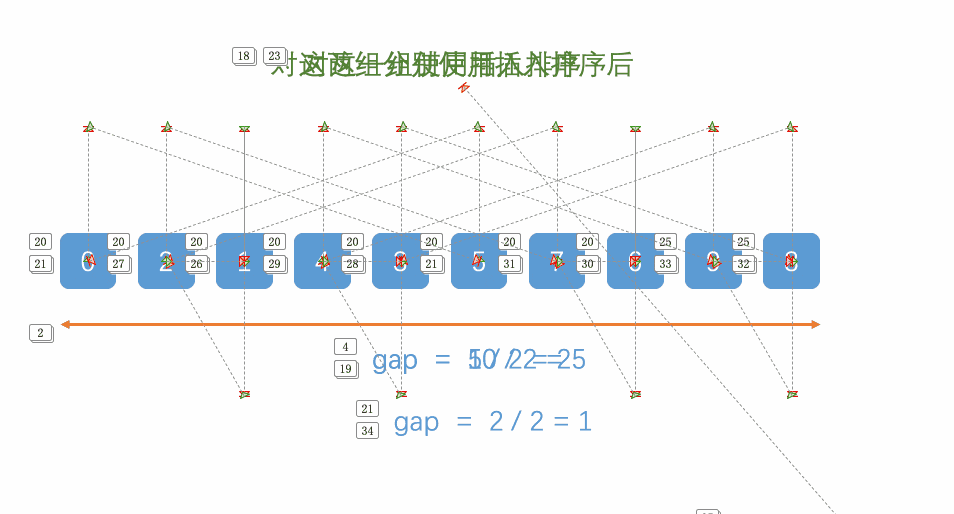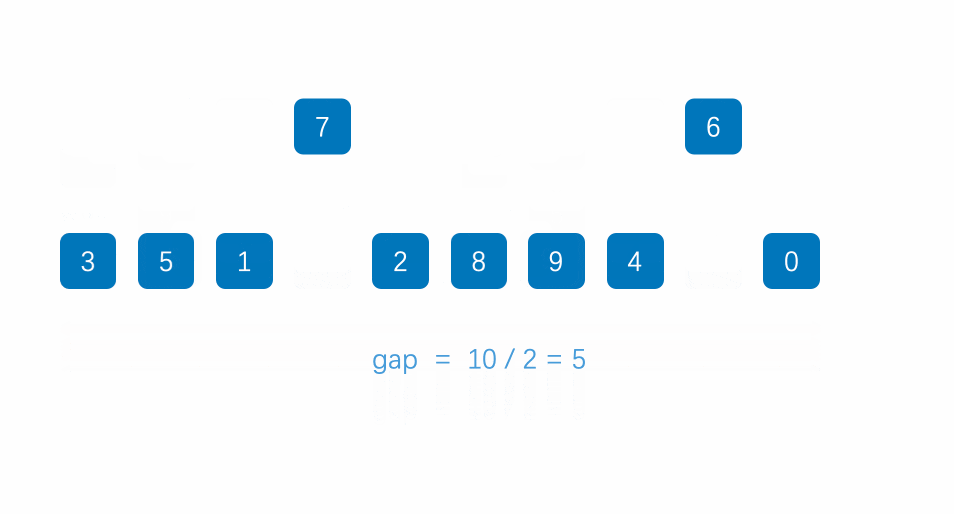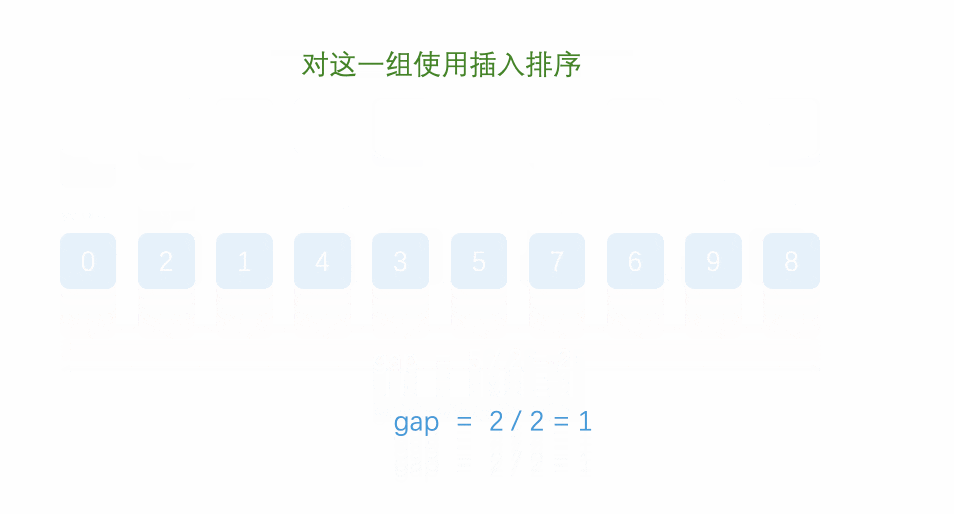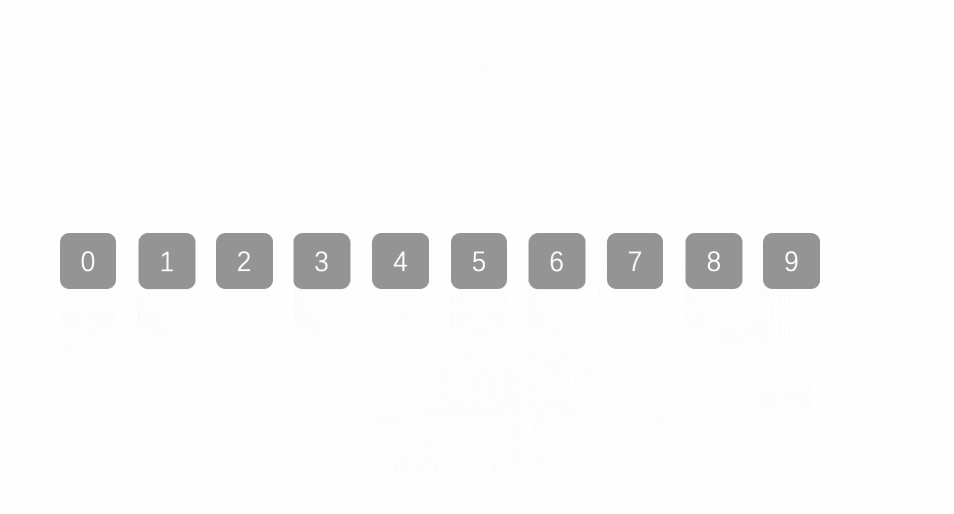
代码:
void ShellSort(int* arr, int n)
{int gap = n;while (gap > 1){gap /= 2;for (int i = 0; i < n - gap; i++){int end = i;int temp = arr[end + gap];while (end >= 0){if (temp < arr[end]){arr[end + gap] = arr[end];end -= gap;}else{break;}}arr[end + gap] = temp;}}
}
时间复杂度平均:O(N^1.3)
空间复杂度:O(1)
选择排序:
思路:
每次从待排序列中选出一个最小值,然后放在序列的起始位置,直到全部待排数据排完即可。
实际上,我们可以一趟选出两个值,一个最大值一个最小值,然后将其放在序列开头和末尾,这样可以使选择排序的效率快一倍。
下面我们来看一下动图:
这里我们图片仅供参考,因为我们要用两个下标,一个最大值,一个最小值,以此来提高效率。
void SelectSort(int* arr, int n)
{int begin = 0, end = n - 1;while (begin < end){int max = begin, min = begin;for (int i = begin; i <=end; i++){if (arr[i] < arr[min]){min = i;}if (arr[i] > arr[max]){max = i;}}swap(arr[begin], arr[min]);//为防止最大值在begin位置被换走,我们还要加个判断if (begin == max){max = min;}swap(arr[max], arr[end]);++begin;--end;}
}
时间复杂度:最坏情况:O(N^2)
最好情况:O(N^2)
空间复杂度:O(1)
堆排序:
想要更好的了解堆排可以查看这篇博文:堆
在学习堆排之前,首先我们要知道社么是堆,堆其实就是一个二叉树,然后有大根堆和小根堆,然后他们分别长这样:

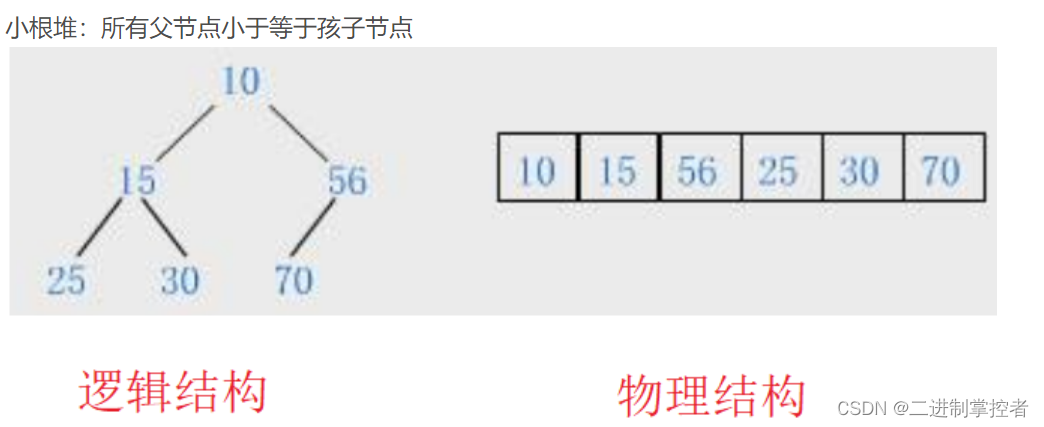
然后我们这里排序的思路就是,比如说大根堆,他的最大值一定在堆顶,然后我们就让他和最后一个数交换,然后不再去管他,再得到一个新的大根堆,继续进行这个操作,这样是不是就实现了呢。
然后这里我们首先还要建堆,然后我们升序的话就建大堆,直接把最大的放在最后一个,然后就不把他看作堆里的数据了。反之,降序就建小堆。下面我们先来看一下如何建堆。
//向上调整(小根堆)
void AdjustUp(HPDataType* a, int child)
{int parent = (child - 1) / 2;while (child>0){//if (a[child] < a[parent])//小于就换就相当于建小堆if (a[child] > a[parent])//大于就换就会变成大堆{std::swap(a[child], a[parent]);child = parent;parent = (child - 1) / 2;}else{break;}}
}//建堆
void HPPush(HP* php, HPDataType x)
{assert(php);if (php->size == php->capacity){int newcapacity = php->capacity == 0 ? 4 : php->capacity * 2;HPDataType* tmp = (HPDataType*)realloc(php->a,sizeof(HPDataType) * newcapacity);if (tmp == NULL){perror("realloc failed!!!");return;}php->a = tmp;php->capacity = newcapacity;}php->a[php->size++] = x;//向上调整AdjustUp(php->a, php->size - 1);
}这就是c语言种建堆的一个过程,还是比较麻烦的。
然后有了堆之后,排序就比较简单了。
void HeapSort(int* a, int n)
{//首先建堆//升序:建大堆//降序:建小堆/*for (int i=0;i<n;i++){AdjustUp(a, i);}*/// 求最后一个节点的父亲for (int i = (n - 1 - 1) / 2; i >= 0; i--){AdjustDown(a, n, i);}int end = n - 1;///这里>0即可,因为=0时只剩下最后一个,就不再需要继续进行了while (end>0)//思路就是:比如我们升序排序,那么我们就利用大根堆,每次都将最大的那个数放在最顶上,然后将它和最后一个交换,然后让整体的大小--,那么最后一个就不再会受影响{std::swap(a[0], a[end]);AdjustDown(a, end, 0);--end;}}堆排最好的最坏的时间复杂度均为O(n*logn)
空间复杂度为O(1)
快速排序:
快排还是这几个排序种比较麻烦的有一个,但其实也是比较好用的一个
我们这里将会用三种方法来实现这个快速排序:
hoare版本(左右指针法):
思路:
1、选出一个key,一般是最左边或是最右边的。
2、定义一个begin和一个end,begin从左向右走,end从右向左走。(需要注意的是:若选择最左边的数据作为key,则需要end先走;若选择最右边的数据作为key,则需要bengin先走)。
3、在走的过程中,若end遇到小于key的数,则停下,begin开始走,直到begin遇到一个大于key的数时,将begin和right的内容交换,end再次开始走,如此进行下去,直到begin和end最终相遇,此时将相遇点的内容与key交换即可。(选取最左边的值作为key)
4.此时key的左边都是小于key的数,key的右边都是大于key的数
5.将key的左序列和右序列再次进行这种单趟排序,如此反复操作下去,直到左右序列只有一个数据,或是左右序列不存在时,便停止操作,此时此部分已有序

//快速排序 hoare版本(左右指针法)
void QuickSort(int* arr, int begin, int end)
{//只有一个数或区间不存在if (begin >= end)return;int left = begin;int right = end;//选左边为keyint keyi = begin;while (begin < end){//右边选小 等号防止和key值相等 防止顺序begin和end越界while (arr[end] >= arr[keyi] && begin < end){--end;}//左边选大while (arr[begin] <= arr[keyi] && begin < end){++begin;}//小的换到右边,大的换到左边swap(&arr[begin], &arr[end]);}swap(&arr[keyi], &arr[end]);keyi = end;//[left,keyi-1]keyi[keyi+1,right]QuickSort(arr, left, keyi - 1);QuickSort(arr,keyi + 1,right);
}
挖坑法:
递归:
挖坑法思路与hoare版本(左右指针法)思路类似
1.选出一个数据(一般是最左边或是最右边的)存放在key变量中,在该数据位置形成一个坑
2、还是定义一个L和一个R,L从左向右走,R从右向左走。(若在最左边挖坑,则需要R先走;若在最右边挖坑,则需要L先走)

//快速排序法 挖坑法
void QuickSort1(int* arr, int begin, int end)
{if (begin >= end)return;int left = begin,right = end;int key = arr[begin];while (begin < end){//找小while (arr[end] >= key && begin < end){--end;}//小的放到左边的坑里arr[begin] = arr[end];//找大while (arr[begin] <= key && begin < end){++begin;}//大的放到右边的坑里arr[end] = arr[begin];}arr[begin] = key;int keyi = begin;//[left,keyi-1]keyi[keyi+1,right]QuickSort1(arr, left, keyi - 1);QuickSort1(arr, keyi + 1, right);
}
非递归:
//单趟排
int PartSort(int* arr, int begin, int end)
{int key = arr[begin];while (begin < end){while (key <= arr[end] && begin < end){--end;}arr[begin] = arr[end];while (key >= arr[begin] && begin < end){++begin;}arr[end] = arr[begin];}arr[begin] = key;int meeti = begin;return meeti;
}void QuickSortNoR(int* arr, int begin, int end)
{stack<int> st;//先入右边st.push(end);//再入左边st.push(begin);while (!st.empty()){//左区间int left = st.top();st.pop();//右区间int right = st.top();st.pop();//中间数int mid = PartSort(arr, left, right);//当左区间>=mid-1则证明左区间已经排好序了if (left < mid - 1){st.push(mid - 1);st.push(left);}//当mid+1>=右区间则证明右区间已经排好序if (right > mid + 1){st.push(right);st.push(mid + 1);}}
}
前后指针法:
思路:
1、选出一个key,一般是最左边或是最右边的。
2、起始时,prev指针指向序列开头,cur指针指向prev+1。
3、若cur指向的内容小于key,则prev先向后移动一位,然后交换prev和cur指针指向的内容,然后cur指针++;若cur指向的内容大于key,则cur指针直接++。如此进行下去,直到cur到达end位置,此时将key和++prev指针指向的内容交换即可。
经过一次单趟排序,最终也能使得key左边的数据全部都小于key,key右边的数据全部都大于key。
然后也还是将key的左序列和右序列再次进行这种单趟排序,如此反复操作下去,直到左右序列只有一个数据,或是左右序列不存在时,便停止操作
//快速排序法 前后指针版本
void QuickSort2(int* arr, int begin, int end)
{if (begin >= end)return;int cur = begin, prev = begin - 1;int keyi = end;while (cur != keyi){if (arr[cur] < arr[keyi] && ++prev != cur){swap(&arr[cur], &arr[prev]);}++cur;}swap(&arr[++prev],&arr[keyi]);keyi = prev;//[begin,keyi -1]keyi[keyi+1,end]QuickSort2(arr, begin, keyi - 1);QuickSort2(arr, keyi + 1, end);}
![【Qt秘籍】[002]-开始你的Qt之旅-下载](https://img-blog.csdnimg.cn/direct/295859a42bf746b49b5a8feb3dcd4ed8.png)