背景
近期在公司使用了SparkSql重构一个由Java开发的ETL程序,因为Java模块不易于修改和部署,而由于SparkSql脚本是由Python开发,便于根据业务需求来开发维护,特别是不需要编译、打包部署。
技术理念
SparkSql是以Sql的形式去开发程序,提交到Spark集群去执行。Spark是大数据领域现在很常见的一种计算框架,它主要基于内存和弹性数据集合的迭代运算,用于替换MapReduce的相对频繁写磁盘的早期框架。SparkSql提供了一种友好的方式对数据进行计算,也就是我们常用的数据库语言Sql。提交SparkSql程序到Spark集群后,Spark首先会对Sql进行语法分析和词法分析,然后转换成具体的操作算子如Map、Join、Reduce等,再经过优化器,最后分配到Executors去执行。
如何使用
在这次的开发场景中,首先整理了原先Java ETL程序的数据抽取和计算逻辑明细,涉及到对Cassandra和Mysql多个表拉取数据、数据清洗、数据聚合、衍生列。然后使用SparkSql重新实现。我们先将源数据拉取到数据仓库中作为ODS层数据,再开发sparksql ETL程序去做下一步计算和聚合。使用的sparksql语法主要如下:
insert overwrite table1
select column1,column2
from table2
where condition = 1
left join table3
on join_condition
在这个过程中,通过编写自定义UDF函数实现一些计算逻辑的封装,使用窗口函数进行分组和排序,使用case when进行条件判断和衍生列。
性能调优
在sparksql程序开发和调试过程中,有一些性能优化的点可以关注下。第一,spark参数可以做一定的调优,例如spark-executor数量spark-executor-memory也就是执行器的内存大小,调整参数可以避免运行时出现OOM的错误以及提高效率;第二,减少使用窗口函数,就算使用也最好不要对大数据量的列进行排序;第三,优化sql语法,比如减少子查询和sql复杂度,因为sql的复杂度和子查询的数量影响了spark解析sql后的stage数量,将影响执行速度;第四,减少在sparksql使用RDD算子,因为sparksql执行器中有进过优化,效率高于RDD计算。
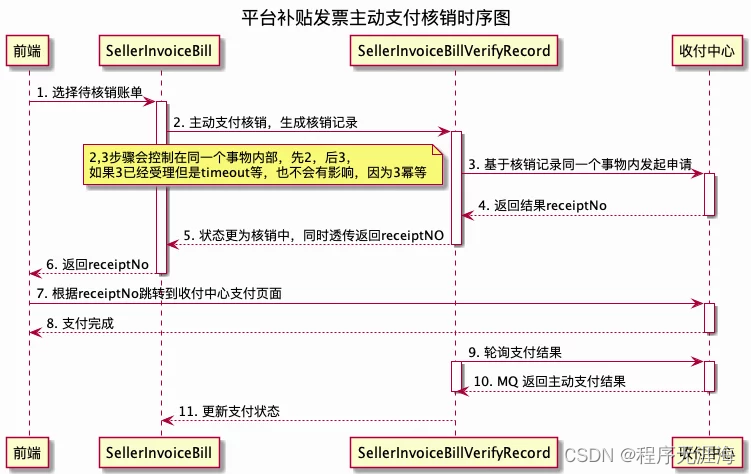
以下是此次数据开发的数据流程图: