节前,我们星球组织了一场算法岗技术&面试讨论会,邀请了一些互联网大厂朋友、参加社招和校招面试的同学。
针对算法岗技术趋势、大模型落地项目经验分享、新手如何入门算法岗、该如何准备、面试常考点分享等热门话题进行了深入的讨论。
合集:
《大模型面试宝典》(2024版) 正式发布!
持续火爆!!!《AIGC 面试宝典》已圈粉无数!
检索增强生成 (RAG) 是将检索模型与生成模型结合起来,以提高生成内容的质量和相关性的一种有效的方法。RAG 的核心思想是利用大量文档或知识库来获取相关信息。各种工具支持 RAG,包括 Langchain 和 LlamaIndex。
AI Retriever 是 RAG 框架的基础,确保 AI 应用中的准确和无缝体验。Retriever 大致分为两类:关键词搜索和向量搜索。关键词搜索依赖于关键词匹配,而向量搜索则关注语义相似性。流行的工具包括用于关键词搜索的 Elasticsearch 和用于向量搜索的 Milvus、Chroma 和 Pinecone。
在大语言模型时代,从工程师和科学家到市场营销等各个领域的专业人士,都热衷于开发 RAG AI 应用原型。像 Langchain 这样的工具对此过程至关重要。例如,用户可以使用 Langhian 和 Chroma 快速构建一个用于法律文档分析的 RAG 应用。
本文中,分享一款工具:Denser Retriever。用户可以通过一个简单的 Docker Compose 命令快速安装 Denser Retriever 及其所需工具。Denser Retriever 不仅仅止步于此,它还提供了自托管解决方案,支持企业级生产环境的部署。
此外,Denser Retriever 在 MTEB 检索数据集上提供了全面的检索基准测试,以确保部署中的最高准确性。用户不仅可以享受 Denser Retriever 的易用性,还可以享受其最先进的准确性。

-
GitHub地址:https://github.com/denser-org/denser-retriever/tree/main
-
博客地址:https://denser.ai/blog/denser-retriever/
Denser Retriever 能做什么?
Denser Retriever 的初始版本提供了以下功能:
-
支持异构检索器,如关键词搜索、向量搜索和机器学习模型重排序。
-
利用 xgboost 机器学习技术有效结合异构检索器。
-
在 MTEB 检索基准测试中实现 State of the art accuracy。
-
演示如何使用 Denser Retriever 来驱动端到端应用,如聊天机器人和语义搜索。
为什么选择 Denser Retriever?
-
Open Source Commitment:Denser Retriever 是开源的,提供透明性和持续的社区驱动改进机会。
-
Production-Ready:设计用于生产环境的部署,确保在实际应用中的可靠性和稳定性。
-
State-of-the-art accuracy:提供最先进的准确性,提高 AI 应用质量。
-
可扩展性:无论是处理不断增长的数据需求还是扩展用户需求,Denser Retriever 都能无缝扩展以满足要求。
-
灵活性:该工具适应广泛的应用,并可根据具体需求进行定制,是多种行业的多功能选择。
在这篇博客中,我们将展示如何安装 Denser Retriever,从文本文件或网页页面构建检索索引,并在此索引上进行查询。
由于篇幅限制,本文不会涵盖更多高级主题,如使用自定义数据集训练 Denser Retriever、在 MTEB 基准数据集上进行评估以及创建端到端 AI 应用(如聊天机器人)。有兴趣的用户可参考以下资源获取这些高级主题的信息。
设置
安装 Denser Retriever
我们使用 Poetry 安装和管理 Denser Retriever 包。在仓库根目录下使用以下命令安装 Denser Retriever。
git clone https://github.com/denser-org/denser-retriever
cd denser-retriever
make install
更多细节可以在 DEVELOPMENT 文档中找到:https://github.com/denser-org/denser-retriever/blob/main/DEVELOPMENT.md
安装 Elasticsearch 和 Milvus
运行 Denser Retriever 需要 Elasticsearch 和 Milvus,它们分别支持关键词搜索和向量搜索。我们按照以下指示在本地计算机(例如,您的笔记本电脑)上安装 Elasticsearch 和 Milvus。
要求:docker 和 docker compose,它们都包含在 Docker Desktop 中,适用于 Mac 或 Windows 用户。
- 手动下载 docker-compose.dev.yml 并保存为 docker-compose.yml,或者使用以下命令。
wget https://raw.githubusercontent.com/denser-org/denser-retriever/main/docker-compose.dev.yml \
-O docker-compose.yml
- 使用以下命令启动服务。
docker compose up -d
- Optionally,我们可以运行以下命令验证 Milvus 是否正确安装。
poetry run python -m pytest tests/test_retriever_milvus.py
索引和查询用例
在索引和查询用例中,用户提供一组文档,如文本文件或网页,以构建检索器。然后用户可以查询该检索器以从提供的文档中获取相关结果。此用例的代码可在 index_and_query_from_docs.py 中找到。
代码地址:https://github.com/denser-org/denser-retriever/blob/main/experiments/index_and_query_from_docs.py
要运行此示例,请导航到 denser-retriever 仓库并执行以下命令:
poetry run python experiments/index_and_query_from_docs.py=
如果运行成功,我们预期会看到类似以下的输出。
2024-05-27 12:00:55 INFO: ES ingesting passages.jsonl record 96
2024-05-27 12:00:55 INFO: Done building ES index
2024-05-27 12:00:55 INFO: Remove existing Milvus index state_of_the_union
2024-05-27 12:00:59 INFO: Milvus vector DB ingesting passages.jsonl record 96
2024-05-27 12:01:03 INFO: Done building Vector DB index
[{'source': 'tests/test_data/state_of_the_union.txt',
'text': 'One of the most serious constitutional responsibilities...',
'title': '', 'pid': 73,
'score': -1.6985594034194946}]
在接下来的部分中,我们将解释其中的基础过程和机制。
概述
下图说明了 Denser Retriever 的结构,它由三个组件组成:
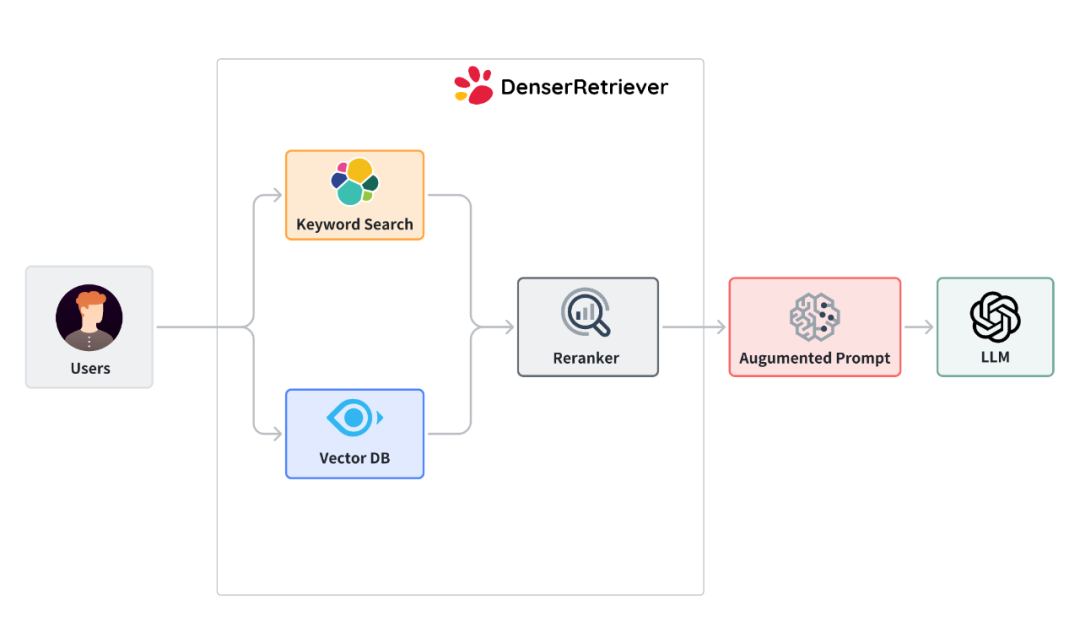
-
关键词搜索依赖于使用精确关键词匹配的传统搜索技术。我们在 Denser Retriever 中使用 Elasticsearch。
-
向量搜索使用神经网络模型将查询和文档编码为高维空间中的密集向量表示。我们使用 Milvus 和 snowflake-arctic-embed-m 模型,该模型在 MTEB/BEIR 排行榜的各个尺寸变体中均实现了最先进的性能。
-
ML 交叉编码器重排序器可用于进一步提升上述两种检索方法的准确性。我们使用 cross-encoder/ms-marco-MiniLM-L-6-v2,该模型在准确性和推理延迟之间具有良好的平衡。
配置文件
我们在以下 yam 文件中配置上述三个组件。大多数参数是不言自明的。关键字、向量、重排序的部分分别配置 Elasticsearch、Milvus 和重排序器。
我们使用 combine: model 通过一个 xgboost 模型(experiments/models/msmarco_xgb_es+vs+rr_n.json)来结合 Elasticsearch、Milvus 和重排序器,该模型是使用 mteb msmarco 数据集训练的(参见训练配方了解如何训练这样的模型)。
除了模型组合,我们还可以使用线性或排名来结合 Elasticsearch、Milvus 和重排序器。在 MTEB 数据集上的实验表明,模型组合可以显著提高准确性,优于线性或排名方法。
一些参数,例如 es_ingest_passage_bs,仅在训练 xgboost 模型时使用(即查询阶段不需要)。
version: "0.1"# linear, rank or model
combine: model
keyword_weight: 0.5
vector_weight: 0.5
rerank_weight: 0.5
model: ./experiments/models/msmarco_xgb_es+vs+rr_n.json
model_features: es+vs+rr_nkeyword:es_user: elastices_passwd: YOUR_ES_PASSWORDes_host: http://localhost:9200es_ingest_passage_bs: 5000topk: 100vector:milvus_host: localhostmilvus_port: 19530milvus_user: rootmilvus_passwd: Milvusemb_model: Snowflake/snowflake-arctic-embed-memb_dims: 768one_model: falsevector_ingest_passage_bs: 2000topk: 100rerank:rerank_model: cross-encoder/ms-marco-MiniLM-L-6-v2rerank_bs: 100topk: 100output_prefix: ./denser_output_retriever/max_doc_size: 0
max_query_size: 10000
生成 passages (段落)
我们现在描述如何从给定的文本文件(state_of_the_union.txt)构建一个检索器。以下代码显示如何读取文本文件,将文件分割成文本块并将其保存为 jsonl 文件(passages.jsonl)。
from langchain_community.document_loaders import TextLoader
from langchain_text_splitters import RecursiveCharacterTextSplitter
from denser_retriever.utils import save_HF_docs_as_denser_passages
from denser_retriever.retriever_general import RetrieverGeneral# Generate text chunks
documents = TextLoader("tests/test_data/state_of_the_union.txt").load()
text_splitter = RecursiveCharacterTextSplitter(chunk_size=500, chunk_overlap=100)
texts = text_splitter.split_documents(documents)
passage_file = "passages.jsonl"
save_HF_docs_as_denser_passages(texts, passage_file, 0)
passages.jsonl 中的每一行都是一个段落,包含 source、title、text 和 pid(段落 ID)字段。
{"source": "tests/test_data/state_of_the_union.txt",
"title": "",
"text": "Madam Speaker, Madam Vice President, our First Lady and Second Gentleman...",
"pid": 0}
构建 Denser 检索器
我们可以使用给定的 passages.jsonl 和 experiments/config_local.yaml 配置文件来构建 Denser 检索器。
# Build denser index
retriever_denser = RetrieverGeneral("state_of_the_union", "experiments/config_local.yaml")
retriever_denser.ingest(passage_file)
查询 Denser 检索器
我们可以简单地使用以下代码来查询检索器以获得相关段落。
# Query
query = "What did the president say about Ketanji Brown Jackson"
passages, docs = retriever_denser.retrieve(query, {})
print(passages)
每个返回的段落都会接收一个置信分数,以指示它与给定查询的相关性。我们得到类似以下的结果。
[{'source': 'tests/test_data/state_of_the_union.txt',
'text': 'One of the most serious constitutional...',
'title': '', 'pid': 73,
'score': -1.6985594034194946}]
将所有内容整合在一起
我们将所有代码整合如下。代码也可在 repo 中找到。
from langchain_community.document_loaders import TextLoader
from langchain_text_splitters import RecursiveCharacterTextSplitter
from denser_retriever.utils import save_HF_docs_as_denser_passages
from denser_retriever.retriever_general import RetrieverGeneral# Generate text chunks
documents = TextLoader("tests/test_data/state_of_the_union.txt").load()
text_splitter = RecursiveCharacterTextSplitter(chunk_size=500, chunk_overlap=100)
texts = text_splitter.split_documents(documents)
passage_file = "passages.jsonl"
save_HF_docs_as_denser_passages(texts, passage_file, 0)# Build denser index
retriever_denser = RetrieverGeneral("state_of_the_union", "experiments/config_local.yaml")
retriever_denser.ingest(passage_file)# Query
query = "What did the president say about Ketanji Brown Jackson"
passages, docs = retriever_denser.retrieve(query, {})
print(passages)
从网页构建检索器
与上述方法类似,除了段落语料库的生成。index_and_query_from_webpage.py 源代码可以在这里找到。
要运行这个用例,请进入 denser-retriever repo 并运行:
poetry run python experiments/index_and_query_from_webpage.py
poetry run python experiments/index_and_query_from_webpage.py
如果成功,我们预计会看到类似以下的内容。
2024-05-27 12:10:47 INFO: ES ingesting passages.jsonl record 66
2024-05-27 12:10:47 INFO: Done building ES index
2024-05-27 12:10:52 INFO: Milvus vector DB ingesting passages.jsonl record 66
2024-05-27 12:10:56 INFO: Done building Vector DB index
[{'source': 'https://lilianweng.github.io/posts/2023-06-23-agent/',
'text': 'Fig. 1. Overview of a LLM-powered autonomous agent system...',
'title': '',
'pid': 2,
'score': -1.6985594034194946}]
进一步阅读
由于篇幅限制,我们在这篇博客中未包括以下主题。
- 使用客户数据集训练 Denser Retriever。用户提供一个训练数据集来训练一个 xgboost 模型,该模型决定如何结合关键字搜索、向量搜索和重排序。训练和测试的工作流程如下图所示。
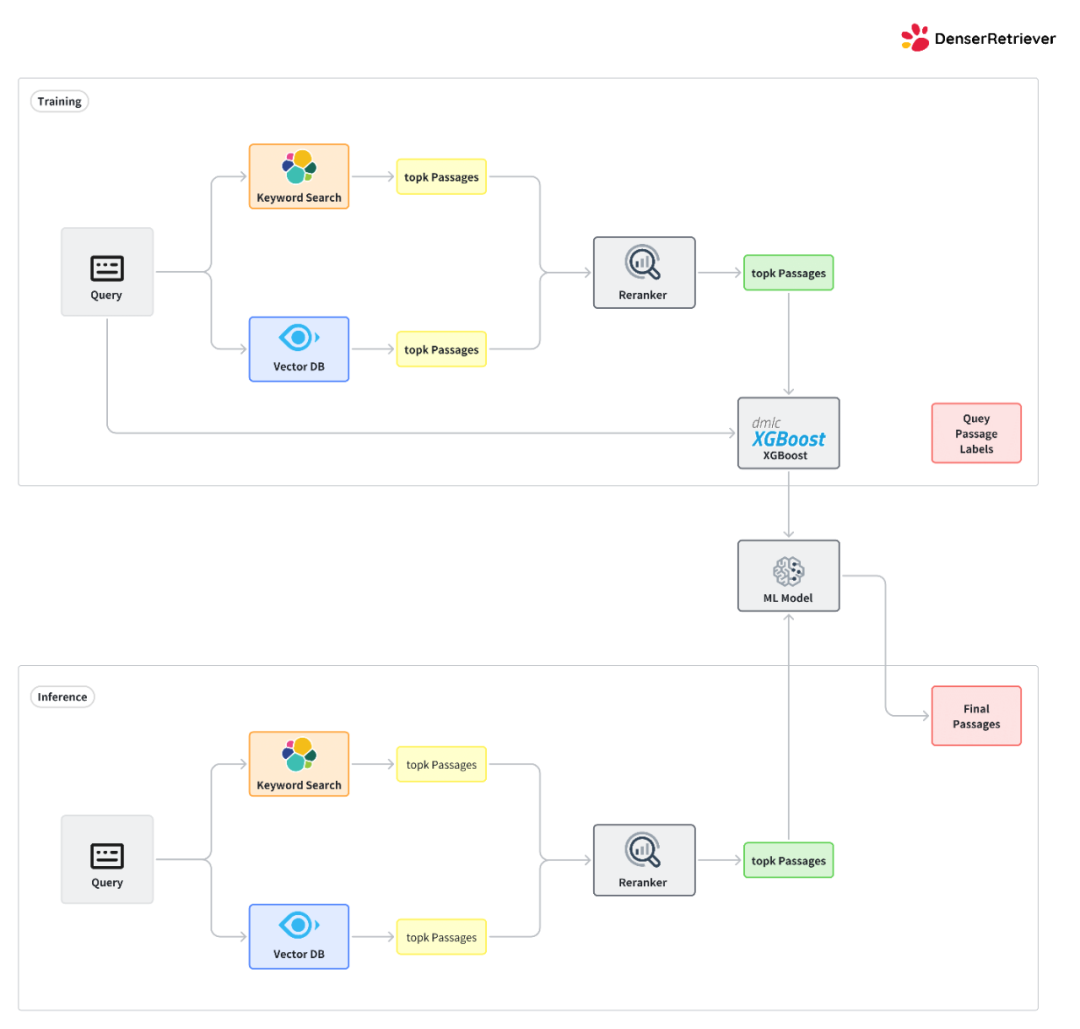
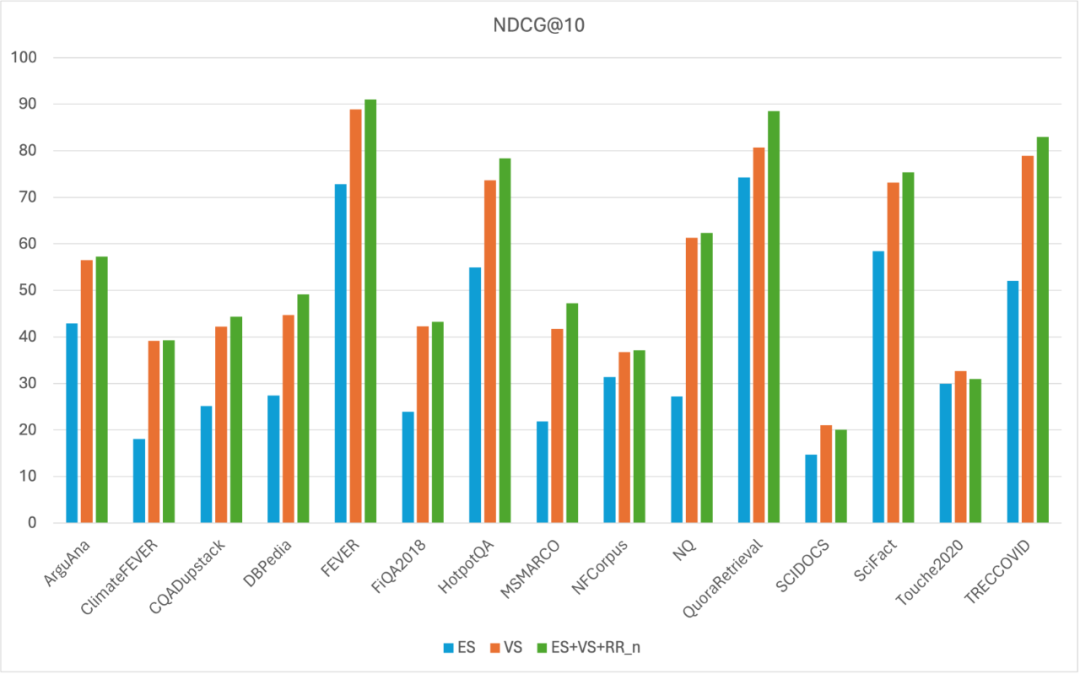
- 在 MTEB 数据集上评估 Denser Retriever。通过 xgboost 模型结合关键字搜索、向量搜索和重排序可以进一步提高向量搜索基线。例如,我们最好的 xgboost 模型在所有 MTEB 数据集上的 NDCG@10 得分为 56.47,相比向量搜索基线(NDCG@10 得分 54.24)绝对提高了 2.23,相对提高了 4.11%。
- 端到端搜索和聊天应用。我们可以轻松使用 Denser Retriever 构建端到端的聊天机器人。

- 过滤器 (Filters)。上述索引和查询用例假设搜索项仅包含非结构化文本。此假设可能不成立,因为数据集可能包含数值、分类和日期属性。过滤器可用于为这些属性设置约束。