Elasticsearch:日志和搜索场景首选解决方案。
技术特点:分布式、全文搜索和数据分析引擎,可以对海量数据进行准实时地存储、搜索和统计分析。

ES的技术栈一共包含四个组件:
其中最核心的是Elasticsearch,可用于数据的存储与检索。
在数据采集层面,我们可以使用Beats组件,采集之后通过Logstash进行加工,然后存储到Elasticsearch中,最后我们可以在Kibana中进行数据的可视化与分析。除了开源属性外,ES也支持商业特性X-Pack,包含安全、机器学习等能力。
传统ES集群模式的挑战

首先是集群运维,对于ES,我们需要自行完成配置调优、重启跟升级,在流量突增时需要进行集群扩缩容以应对业务压力。而节点或者磁盘不均或者过载时,都会对集群的稳定性造成极大影响,故障的排查等繁琐、复杂。其次是数据接入。我们通过集群模式进行数据接入,需要自行搭建数据链路。配置Beats、Kafka、Logstash等组件。组件的部署、运维管理以及全链路的故障排查等,面临着极大的挑战,运维与管理成本高。最后是索引管理,索引的Setting、Mapping以及别名等配置需要有较多的经验支撑。同时随着业务的不断增长,分片数量的动态调优以及滚动、降冷、删除等,都需要我们自行介入。例如当流量突增时,我们需要调大分片数量以应对高并发的写入,避免出现写入拒绝。当流量下来时我们则可以适当的降低分片数量,避免元数据管理压力过大。
而以上的调整,均需要我们自行处理。整体而言,传统ES集群模式下,学习成本、人力投入以及时间投入都比较高。
ES Serverless服务的设计理念与设计思路
让算力像自来水一样按需使用,一直是各大云厂商最求的目标。
在云计算的发展初期,侧重的是能够快速地平滑迁移上云,例如把IDC的资源换成云服务以及云硬盘。而现在客户的需求已经从上好云转变为用好云,即在释放运维与管理成本的同时,能够更加聚焦于业务,实现降本增效。ES Serverless服务在设计开发过程中,始终坚持以下几个目标:
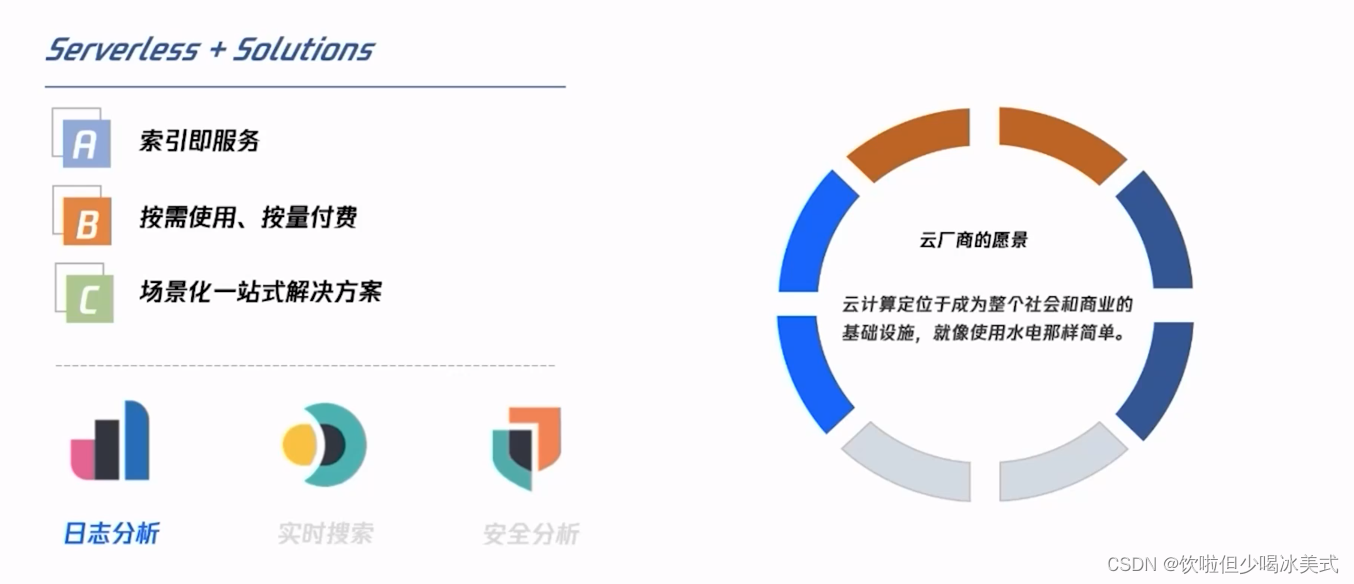
一是索引即服务、无集群的概念,可按需创建与使用索引。
二是按需使用、按量付费,即按照实际使用的计算与存储资源去按量计费。
三是不止索引,还是场景化的一站式服务,能针对每个场景提供相应的开箱即用的能力,提升整体的使用效率。
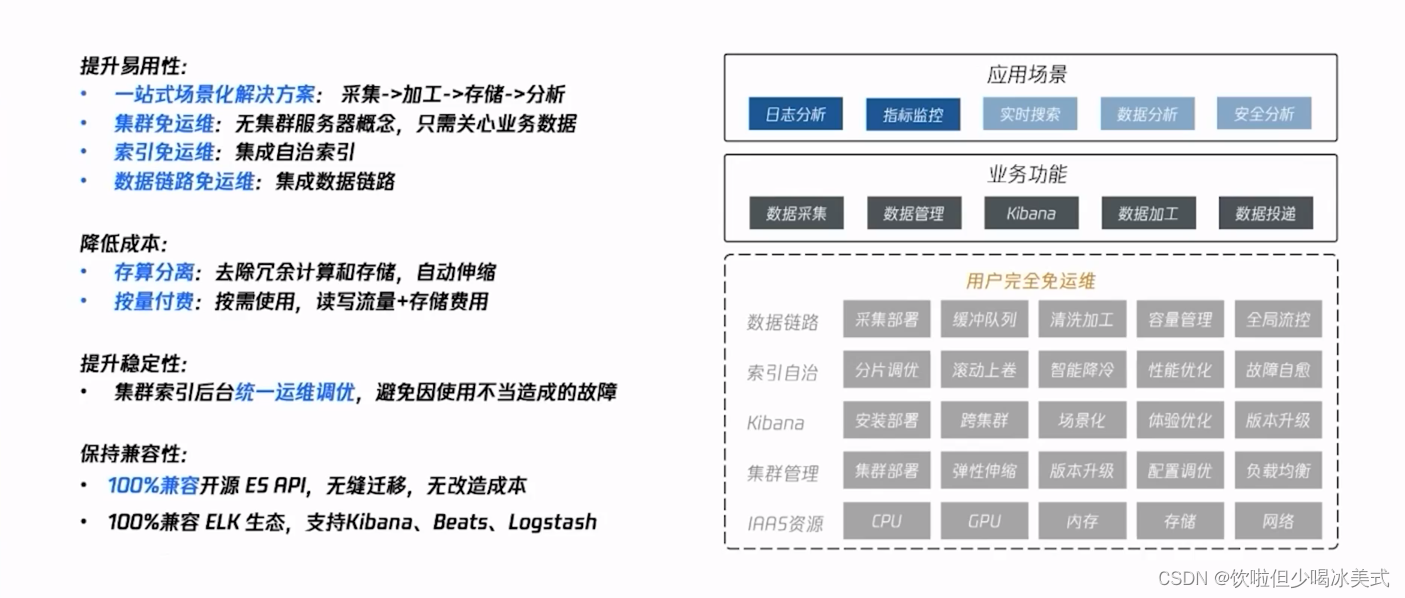
一站式日志分析体验
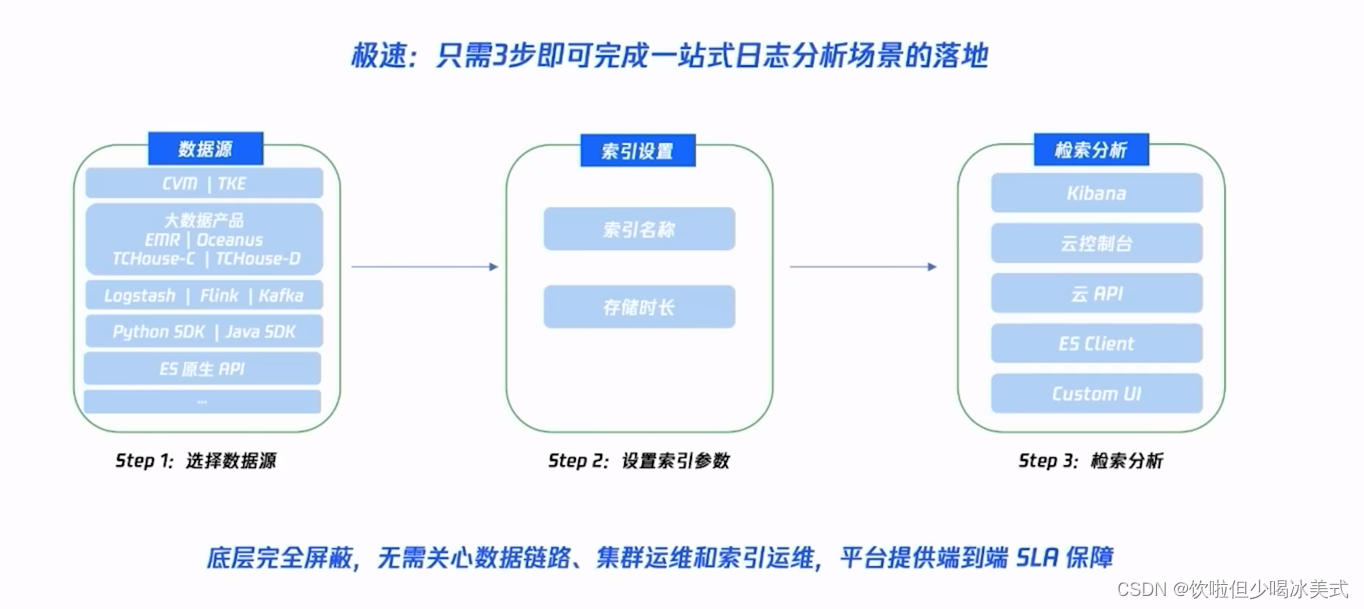
在使用时,用户仅需关注数据源以及检索分析等业务逻辑即可。中间的流量调度、链路调度以及资源调度全部由ES Serverless服务完成。不需要关注底层的数据链路、消息队列、集群运维以及索引配置等。平台端会提供端到端的一个SLA保障。
那除了支持原生的ES API写入方式之外,我们在控制台已经支持了云服务器CVM,容器服务TKE、EMR、云数据仓库TCHouse-C等云产品的一站式日志分析与采集,同时也支持通过Logstash、Flink以及Kafka等将数据投递到ES Serverless服务的索引中。
那从产品能力上来看,已经打通了云服务器CVM、容器服务TKE以及大数据产品。在索引管理方面,我们提供了配置管理、指标监控、用户管理及告警能力,可方便我们快速完成数据应用。而在检索分析能力方面,除了支持原生的Kibana能力之外,无需外链访问即可快速进行检索分析。