机器学习项目实战:成人收入预测
项目目的
基于个人收入数据(包括教育程度、年龄、性别等)的数据集,通过机器学习算法,预测一个人的年收入是否超过5万美金。
数据集
-
地址:http://idatascience.cn/dataset-detail?table_id=100368
-
数据集字段
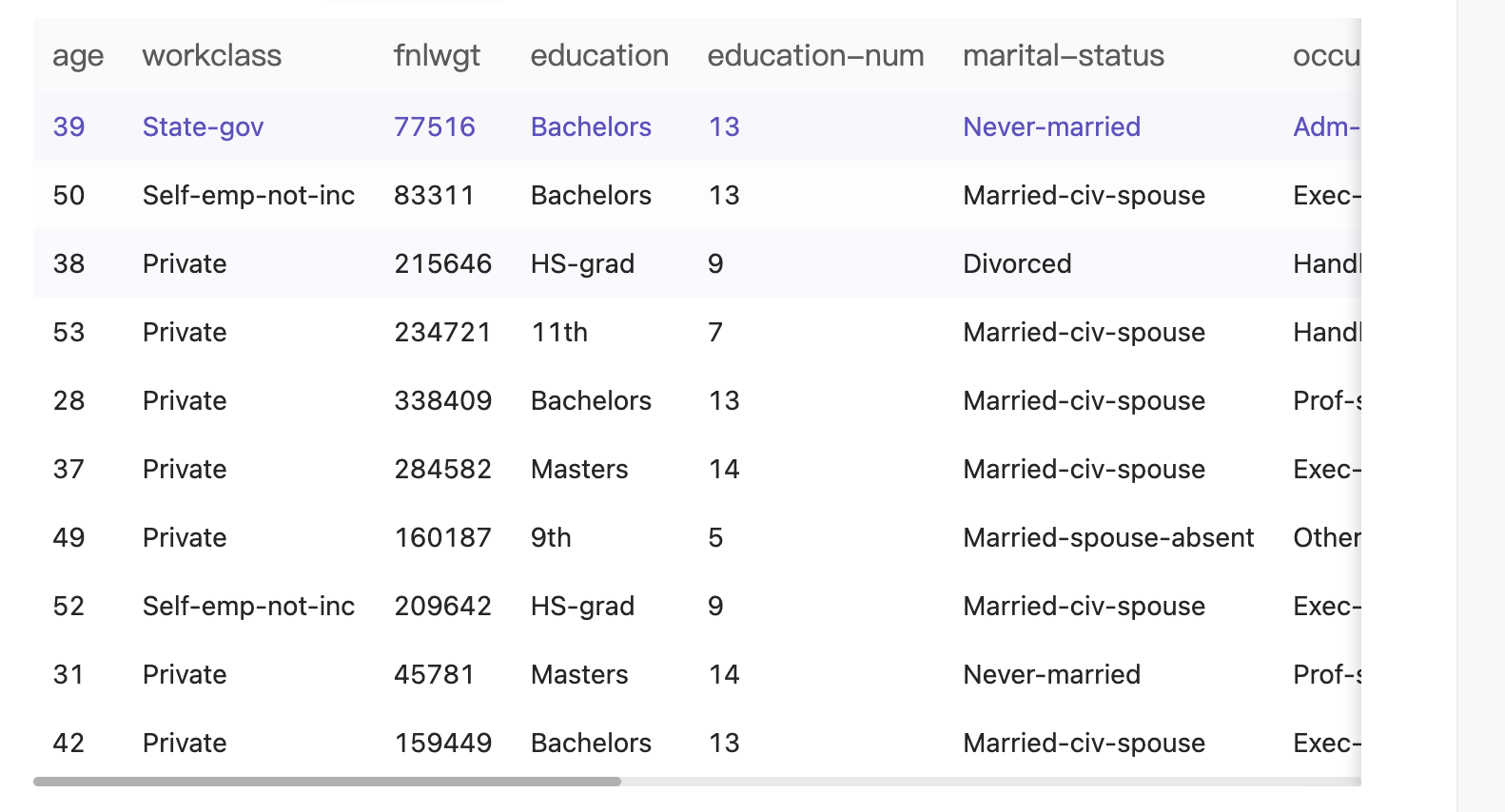
字段名称 字段类型 字段说明 age 数值型 年龄 workclass 字符型 工作类型 fnlwgt 字符型 序号 education 字符型 教育程度 education-num 数值型 受教育时长 marital-status 字符型 婚姻状况 occupation 字符型 职业 relationship 字符型 关系 race 字符型 种族 sex 字符型 性别 capital-gain 数值型 资本收益 capital-loss 数值型 资本损失 hours-per-week 数值型 每周工作小时数 native-country 字符型 原籍 salary 字符型 收入 -
数据集样例:
解决思路
分析输入/输出
通过分析,本次项目我们要解决的问题:给定一个人的相关信息(包括年龄、教育程度、受教育时长等),预测其收入是否超过5万。
该问题如果是预测其收入是多少,那么就属于线性回归问题;但数据集中在收入标签是>=5万或<5万,所以这应该是一个分类问题。
分析相关输入/输出如下:
- 输入:一个人的信息(包括年龄、教育程度、受教育时长等)
- 输出:0为<=50K,1为>50K
构建数据集
分析数据类型
首先,我们先分析一下如何将数据集向量化,通过以下代码来查看数据集每列的内容:
import csv
import numpy as np
def read_file(file_path, skip_header=True):"""读取CSV文件的内容。参数:file_path (str): CSV文件的路径。skip_header (bool): 是否跳过表头数据,默认为True。返回:list: 包含CSV文件内容的列表。"""print(f'读取原始数据集文件: {file_path}')with open(file_path, 'r', encoding='utf-8') as f:if skip_header:# 跳过表头数据f.readline()reader = csv.reader(f)return [row for row in reader] # 读取csv文件的内容def print_unique_columns(data):"""打印表格数据中每一列去重后的数据。参数:data (list): 包含表格数据的列表。"""if not data:print("没有读取到任何数据。")return# 获取每一列的数据columns = zip(*data)# 打印每一列去重后的数据for i, column in enumerate(columns):unique_values = set(column)unique_count = len(unique_values)print(f"第{i}列去重后的数据(最多前20个):")# 如果数据大于20个,则只打印前20个if unique_count > 20:for value in list(unique_values)[:20]:print(value)print(f"共 {unique_count} 个不同的值")else:for value in unique_values:print(value)print(f"共 {unique_count} 个不同的值")print()data = read_file('./成人收入预测数据集.csv')
print_unique_columns(data)
运行结果:


对上述每一列内容进行梳理,梳理结果如下:
| 列的序号(第几列) | 原始数据表头名称 | 表头名称中文解释 | 对应列取值举例 | 取值个数 | 数据类型 | 数据处理办法 |
|---|---|---|---|---|---|---|
| 0 | age | 年龄 | 69, 62, 37, 80, 34 | 73 | 连续量 | 保留 |
| 1 | workclass | 工作类型 | Without-pay, State-gov, Federal-gov | 9 | 离散量 | 保留 |
| 2 | fnlwgt | 疑似邮编编号 | 226092, 209770, 31840 | 21648 | 连续量 | 舍弃 |
| 3 | education | 教育程度 | Masters, Bachelors, Some-college | 16 | 离散量 | 保留 |
| 4 | education-num | 教育年限 | 3, 4, 16, 2, 11 | 16 | 连续量 | 保留 |
| 5 | marital-status | 婚姻状况 | Divorced, Separated, Never-married | 7 | 离散量 | 保留 |
| 6 | occupation | 职业类型 | Exec-managerial, Adm-clerical, Handlers-cleaners | 15 | 离散量 | 保留 |
| 7 | relationship | 家庭关系 | Wife, Not-in-family, Other-relative | 6 | 离散量 | 保留 |
| 8 | race | 种族 | Amer-Indian-Eskimo, White, Black | 5 | 离散量 | 保留 |
| 9 | sex | 性别 | Female, Male | 2 | 离散量 | 保留 |
| 10 | capital-gain | 投资利得 | 3781, 2062, 401 | 119 | 连续量 | 保留 |
| 11 | capital-loss | 投资损失 | 1816, 1876, 1762 | 92 | 连续量 | 保留 |
| 12 | hours-per-week | 每周工作时长 | 37, 80, 34 | 94 | 连续量 | 保留 |
| 13 | native-country | 出生国家 | Japan, England, Guatemala | 42 | 离散量 | 保留 |
通过分析上述每列内容可知:
- 数据集中,age、education-num、capital-gain、capital-loss、hours-per-week等字段的内容一般都是数字,可以视为连续量。这类数据直接使用即可,不需要做向量化处理(因为是数字,机器能够处理)。
- 数据集中,workclass、education、marital-status、occupation、relationship、race、sex、native-country等字段内容一般都是表示状态,属于离散量;由于其内容不是数字,为了让机器能够处理,我们后续需要进行向量化处理。
- 数据集中,fnlwgt疑似是连续量,但是查看取值个数(21648)与总样本个数(32561个)不一致,所以确定该列不是类似身份证号的唯一编号数据(如果身份证可以舍弃,因为身份证跟收入没啥关系);该列可能是类似邮编的数据,虽然邮编可能与收入有一定关系,但是因为其取值数量比较大(21648个),这会导致特征数据过去庞大,所以选择舍弃。
离散量的编码
通过与chatGPT交流,我们了解到,离散量的编码常见方式有One-Hot编码、标签编码、序数编码、Target编码、哈希编码、实体嵌入。
- One-Hot编码:
- 编码方式:将每个离散特征转换为多个二进制特征。
- 优点:能够很好地表示分类特征,不会引入大小关系。
- 缺点:会增加特征维度。
- 适用场景:适用于没有大小关系的分类特征,如性别、产品类别等。
- 标签编码(Label Encoding):
- 编码方式:将每个离散特征的取值映射为一个整数值。
- 优点:简单直观。
- 缺点:可能会让算法认为特征之间存在大小关系。
- 适用场景:适用于没有明确大小关系的分类特征,但要注意可能带来的影响。
- 序数编码(Ordinal Encoding):
- 编码方式:将每个离散特征的取值映射为一个有序的整数值。
- 优点:能够保留特征之间的大小关系。
- 缺点:对于没有明确大小关系的离散特征可能不太合适。
- 适用场景:适用于有明确大小关系的有序离散特征,如学历、星级等。
- Target编码:
- 编码方式:将每个离散特征的取值映射为目标变量的平均值或中位数。
- 优点:能够捕捉特征取值与目标变量之间的关系,通常能提高模型性能。
- 缺点:需要提前知道目标变量,不适用于无监督学习。
- 适用场景:适用于有监督学习问题中,当目标变量与离散特征存在相关性时。
- 哈希编码:
- 编码方式:将每个离散特征的取值通过哈希函数映射为一个整数值。
- 优点:在处理高基数特征时较为有效,能减少内存占用。
- 缺点:可能会产生冲突,导致信息丢失。
- 适用场景:适用于高基数离散特征,且内存受限的情况下。
- 实体嵌入(Entity Embedding):
- 编码方式:将每个离散特征的取值映射为一个低维的稠密向量。
- 优点:能够学习特征之间的潜在关系,通常能提高模型性能。
- 缺点:需要额外的训练过程来学习嵌入向量。
- 适用场景:适用于复杂的机器学习问题,如自然语言处理、推荐系统等,能够更好地捕捉特征之间的潜在关系。
分析上述编码内容,其中
-
Target编码、哈希编码、实体嵌入暂未学习到,本次暂不做考虑。 -
标签编码、序数编码由于其存在潜在的数字大小对比,让算法认为特征之间存在大小关系,所以并不适用于上述的婚姻状况、职业类型、国家等。
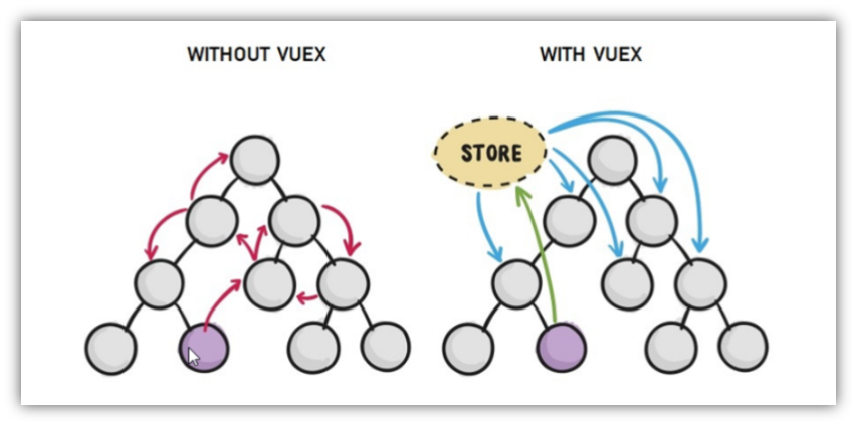
所以,综上所述本次练习使用One-Hot编码,其编码示意图如下:
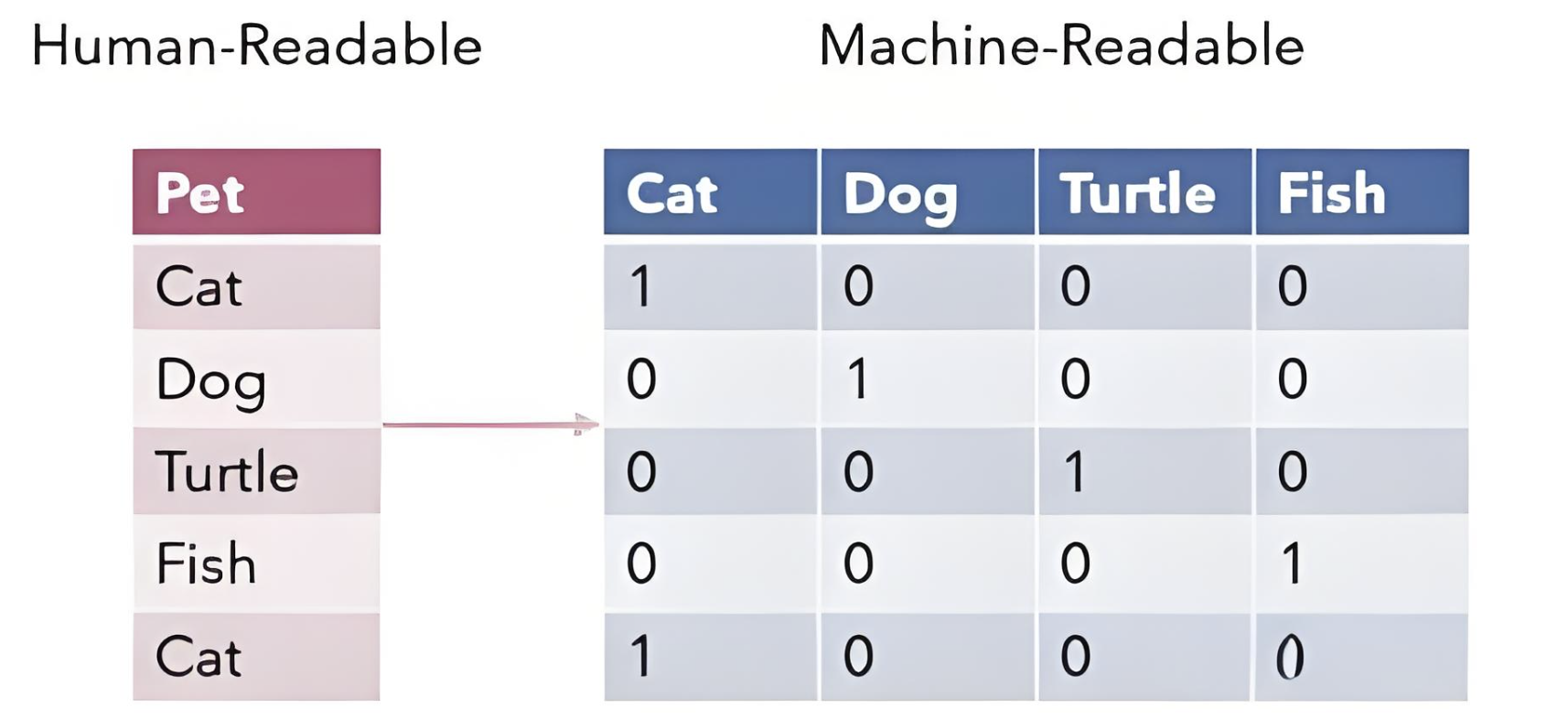
基于上面的思想,我们通过与GPT沟通了解到,sklearn的库函数中有OneHotEncoder,使用方法如下:
import numpy as np
from sklearn.preprocessing import OneHotEncoder# 示例数据
data = np.array([['A', 'X', 'P'],['B', 'Y', 'Q'],['A', 'X', 'R'],['B', 'Z', 'Q']
])# 创建 OneHotEncoder 实例
encoder = OneHotEncoder(sparse_output=False)# 对数据进行one-hot编码
encoded_data = encoder.fit_transform(data)print("原始数据:")
print(data)
print("\n编码后的数据:")
print(encoded_data)
执行结果如下:

分离特征和标签
def split_data(data):"""将数据分割为标签和数据。参数:data (list): 数据行的列表,第一个元素是标签。返回:numpy.ndarray: 标签数组。numpy.ndarray: 连接元素后的数据数组。"""# 去除每个元素的前后空格data = [[col.strip() for col in row] for row in data]# 分离数据和标签n_label = np.array([row[-1] for row in data])n_data = np.array([row[:-1] for row in data])return n_label, n_datacsv_data = read_file('./成人收入预测数据集.csv')
label, data = split_data(csv_data)
label, data
运行结果:

处理特征列
这部分的处理较为麻烦,整体思路是这样:
1、实现一个函数,传入三个参数:分别是离散量列的序号、连续量列序号和丢弃列序号
2、函数根据传入的列序号,分别进行如下处理:
-
如果是连续量列,取出对应的列,不用做处理;
-
如果是离散量列,取出对应的列,使用OneHotEncoder进行编码
-
如果是丢弃列,则在矩阵中删除对应的列
最后,在去除丢弃列之后,将连续量列和离散量列按照列方向堆叠为一个新的矩阵
import numpy as np
from sklearn.preprocessing import OneHotEncoder, StandardScalerdef vectorize_data_with_sklearn(data, onehot_cols, continuous_cols, exclude_cols=None):"""使用scikit-learn将给定的NumPy数组中的数据进行one-hot编码和标准化处理。参数:data (np.ndarray): 输入的NumPy数组onehot_cols (list): 需要进行one-hot编码的列索引continuous_cols (list): 不需要one-hot编码的连续量列索引exclude_cols (list, optional): 需要排除的列索引返回:np.ndarray: 经过one-hot编码和标准化的向量化数据"""# 排除不需要处理的列if exclude_cols:data = np.delete(data, exclude_cols, axis=1)onehot_cols = [col - sum(col > exc for exc in exclude_cols) for col in onehot_cols if col not in exclude_cols]# 解释过程:# 1. 遍历 onehot_cols 中的每个索引 col# 2. 检查 col 是否在 exclude_cols 中# - 如果在,计算 col 在 exclude_cols 中的位置 sum(col > exc for exc in exclude_cols)# - 并从 col 中减去这个值,更新 col 的索引# - 例如: col = 1, 在 exclude_cols 中的位置为 0, 则更新后 col = 1 - 0 = 1# - ⭐ 这样可以确保 onehot_cols 中的索引能正确对应到数据的列# 3. 如果 col 不在 exclude_cols 中,则保留原始索引continuous_cols = [col - sum(col > exc for exc in exclude_cols) for col in continuous_cols if col not in exclude_cols]# 解释过程:# 1. 遍历 continuous_cols 中的每个索引 col# 2. 检查 col 是否在 exclude_cols 中# - 如果在,计算 col 在 exclude_cols 中的位置 sum(col > exc for exc in exclude_cols)# - 并从 col 中减去这个值,更新 col 的索引# - 例如: col = 2, 在 exclude_cols 中的位置为 0, 则更新后 col = 2 - 0 = 2# - ⭐ 这样可以确保 continuous_cols 中的索引能正确对应到数据的列# 3. 如果 col 不在 exclude_cols 中,则保留原始索引else:onehot_cols = onehot_cols[:]continuous_cols = continuous_cols[:]# 对离散量列进行one-hot编码onehot_encoder = OneHotEncoder(sparse_output=False)one_hot_data = onehot_encoder.fit_transform(data[:, onehot_cols])# 对连续量列进行标准化scaler = StandardScaler()continuous_data = scaler.fit_transform(data[:, continuous_cols])# 将one-hot编码结果和标准化后的连续量列拼接起来final_data = np.hstack((one_hot_data, continuous_data))return final_datacsv_data = read_file('./成人收入预测数据集.csv')
label, data = split_data(csv_data)# 对数据进行切分
onehot_cols = [1, 3, 5, 6, 7, 8, 9, 13]
continuous_cols = [0, 2, 4, 10, 11, 12]# 排除列增加最后一列
exclude_cols = [2, 13]
vectorized_data = vectorize_data_with_sklearn(data, onehot_cols, continuous_cols, exclude_cols)
vectorized_data
运行结果:

处理标签列
因为标签列的内容只有两种情况:‘<=50K’ 和’>50K’,所以只需要将这一列中’<=50K’替换为0,'>50K’替换为1即可。
import numpy as np
from sklearn.preprocessing import LabelBinarizerdef binarize_labels(labels):"""将标签二值化。参数:labels (numpy.ndarray): 原始标签数组。返回:numpy.ndarray: 二值化后的标签数组。"""lb = LabelBinarizer()binarized_labels = lb.fit_transform(labels)return binarized_labelsvectorized_label = binarize_labels(label)
vectorized_label
试验算法
为了能够将整个流程跑通,我们仍然选择决策树算法跑通流程。
from sklearn.model_selection import train_test_split
from sklearn.tree import DecisionTreeClassifierdef decision_tree(label, data, test_size=0.2):"""决策树模型的训练和评估。参数:train_data_file_path (str): 向量化数据的文件路径。test_size (float): 测试集的比例,默认为0.2。"""print('开始加载训练数据...')# 训练集和测试集切分X_train, X_test, y_train, y_test = train_test_split(data, label, test_size=test_size)print('开始训练决策树模型...')# 数据预测clf = DecisionTreeClassifier()clf.fit(X_train, y_train)y_pred = clf.predict(X_test)# 评估print('开始决策树预测...')accuracy = np.mean(y_pred == y_test)print(f'预测准确率:{accuracy}')# 读取文件
listdata = read_file('./成人收入预测数据集.csv')
# 对数据进行切分
label, data = split_data(listdata)# 对数据进行切分
onehot_cols = [1, 3, 5, 6, 7, 8, 9, 13]
continuous_cols = [0, 2, 4, 10, 11, 12]# 排除列增加最后一列
exclude_cols = [2, 13]
vectorized_data = vectorize_data_with_sklearn(data, onehot_cols, continuous_cols, exclude_cols)
vectorized_label = binarize_labels(label)decision_tree(vectorized_label, vectorized_data)
运行结果:

工程优化
通过以上的工作,整体构建数据集→训练模型→预测模型流程已经跑通,接下来进行代码重构优化。
1、将整体代码使用面向对象封装为类实现
2、在模型预测部分加入KNN、贝叶斯、线性回归、随机森林、SVC向量机的方式
3、将预测结果使用matplotlib绘制出来
4、给关键代码处增加带有时间戳的日志
以上工作就交给GPT来完成了,最后重构的代码请见Github仓库
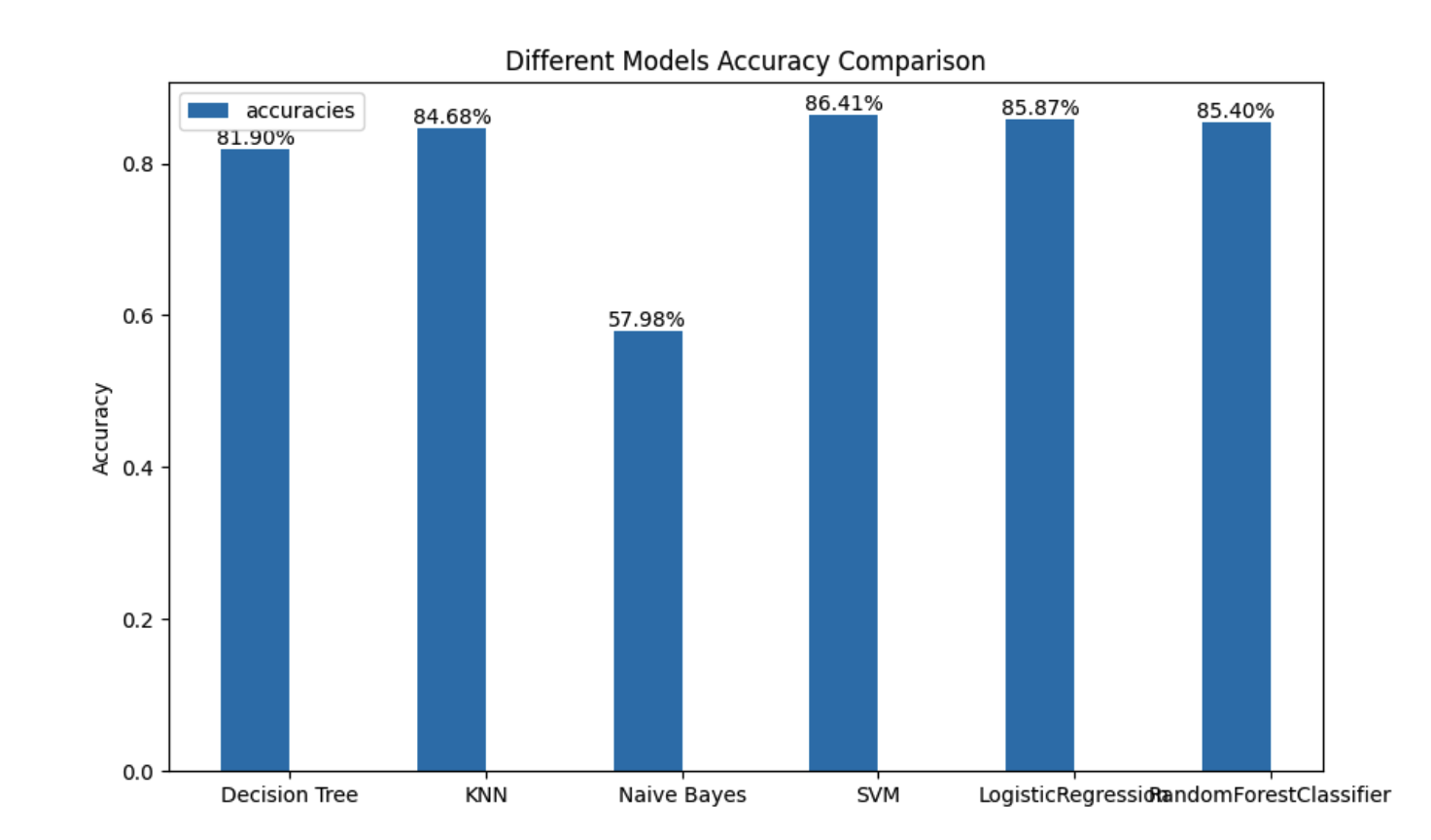
遴选算法
通过运行上述工程优化后的代码,执行结果如下: