1.堆的概念及结构
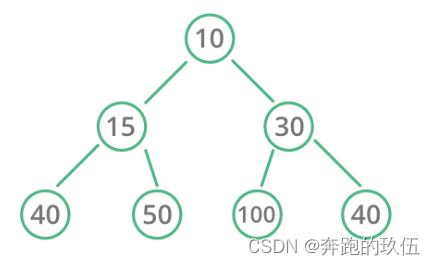
堆是一种特殊的树形数据结构,称为“二叉堆”(binary heap)
看它的名字也可以看出堆与二叉树有关系:其实堆就是一种特殊的二叉树
堆的性质:
- 堆中某个结点的值总是不大于或不小于其父结点的值;
- 堆总是一棵完全二叉树
1.1大堆
大堆:
- 大堆的根节点是整个堆中最大的数
- 每个父节点的值都大于或等于其孩子节点的值
- 每个父节点的孩子之间并无直接的大小关系

1.2小堆
小堆:
- 小堆的根节点是整个堆中最小的数
- 每个父节点的值都小于或等于其孩子节点的值
- 每个父节点的孩子之间并无直接的大小关系
2.堆的实现
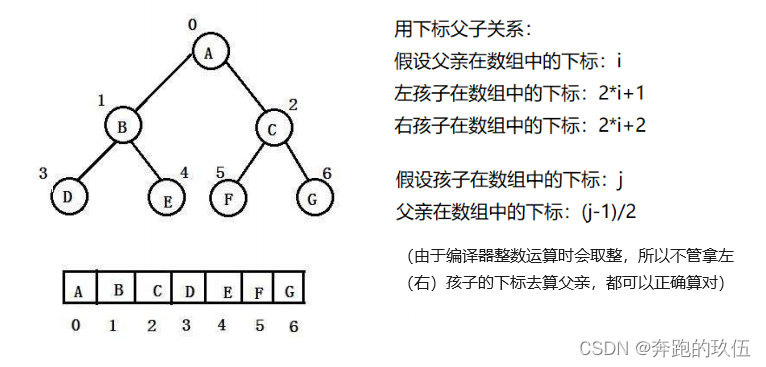
2.1使用数组结构实现的堆
由于堆是一个完全二叉树,所以堆通常使用数组来进行存储
使用数组的优点:
- 相较于双链表更加的节省内存空间
- 相较于单链表可以更好的算父子关系,并找到想要找的父子
2.2堆向上调整算法
堆的向上调整(也称为堆化、堆的修复或堆的重新堆化)是堆数据结构维护其性质的关键操作之一
int arr = [ 15, 18, 19, 25, 28, 34, 65, 49, 37, 10]
小堆演示向上调整算法演示过程
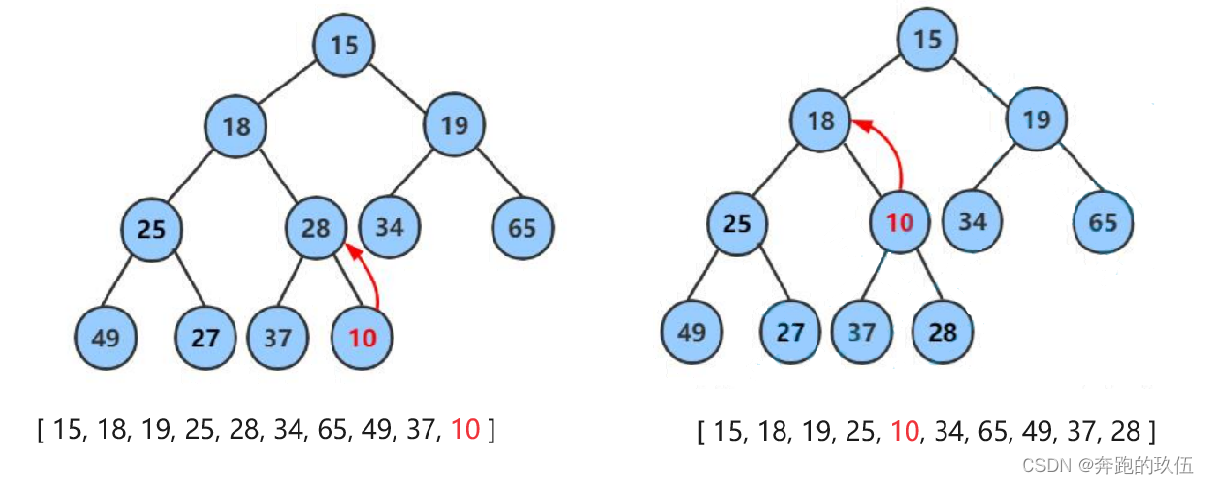
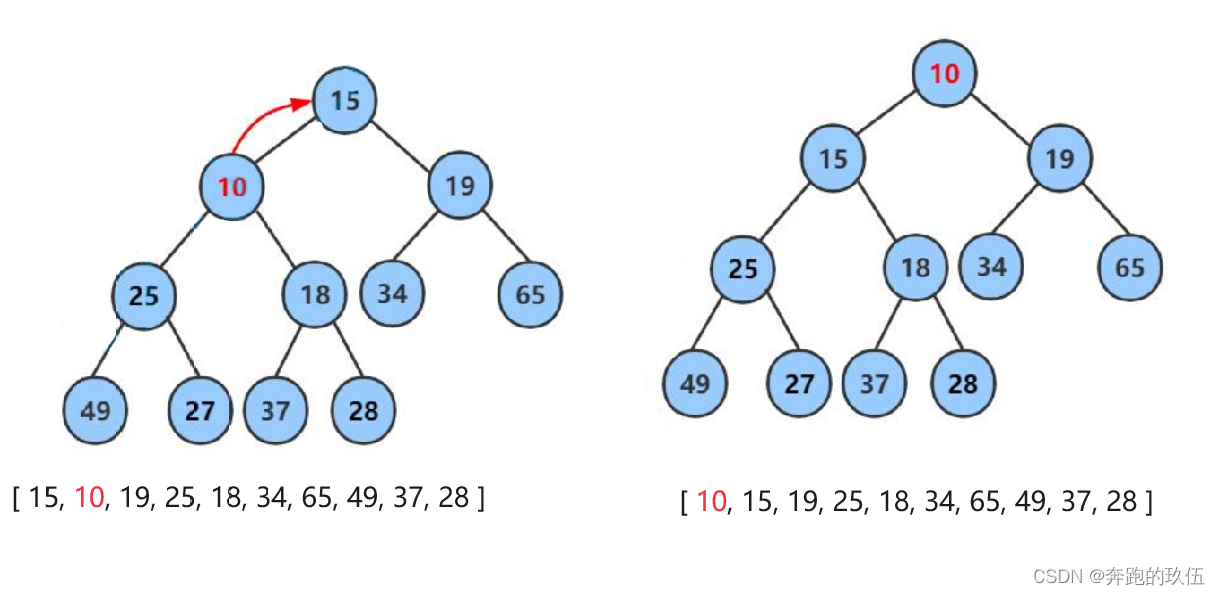
向上调整的过程 :将新插入的值与它的父亲相比,如果小则向上调整,调整完成后与新的父亲去比较,直到其值 >= 父亲的时候停止调整
void Swaps(HPDataType* a, HPDataType* b) {HPDataType temp;temp = *a;*a = *b;*b = temp;
}//向上调整(小堆)
//child是下标void AdjustUp(HPDataType* a, int child) {assert(a);int parent = (child - 1) / 2;//算父亲节点的下标//向下调整主要逻辑while (child > 0) //当调整至根节点时,已经调整至极限,不用在调整{//当父亲节点 > 孩子时,开始调整if (a[parent] > a[child]) {Swaps(&a[child],&a[parent]); //交换child = parent; //走到新的位置为新一轮的向下调整做准备parent = (child - 1) / 2; //算出新位置的父亲节点下标}//当父亲节点 < 孩子时,说明调整已经完毕,退出循环else{break;}}
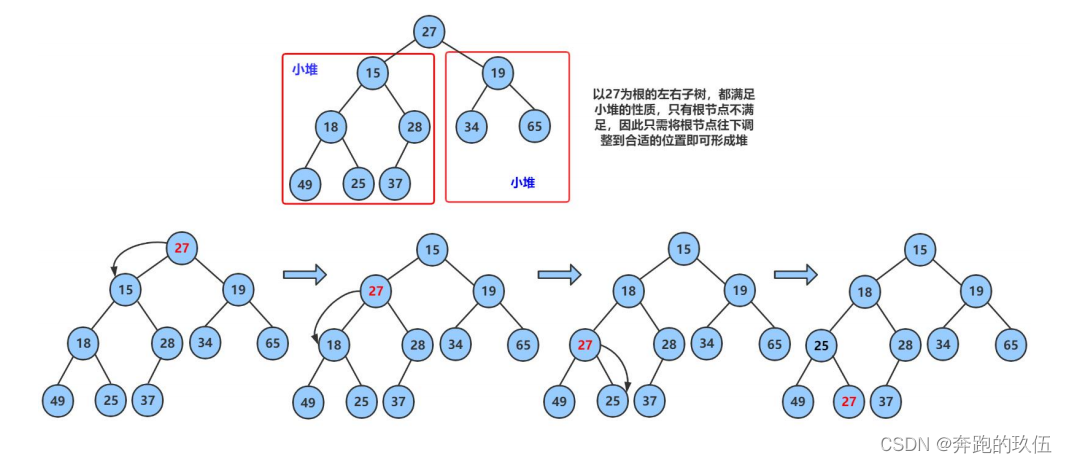
}2.3堆向下调整算法
在堆排序或其他需要维护堆性质的场景中,当堆的某个节点不满足堆的性质(对于最大堆,父节点小于其子节点;对于最小堆,父节点大于其子节点)时,就需要通过向下调整来修复这个子树,使其重新成为堆
int array[] = {27,15,19,18,28,34,65,49,25,37};
2.4堆的插入
堆的插入(HeapPush):通常通过将新元素添加到堆的末尾,并通过向上调整算法来维持堆的性质 (由于插入前的堆肯定是一个标准的堆,所以我们在将数据插入后执行一次向上调整算法,即可完成堆的插入)
2.5堆的删除
删除元素(HeapPop):在最大堆或最小堆中,通常删除的是根节点(即最大或最小元素),并通过向下调整算法来维持堆的性质 (由于删除前的堆肯定是一个标准的堆即左右子树肯定也是标准的堆,所以我们在将数据删除后执行一次向下调整算法,即可完成堆的删除)
为什么要删除根节点?
- 相较于删除别的位置的节点,每次删除的根节点都是堆中最大或最小的数(大堆为最大,小堆为最小)、
- 从根节点开始删除并调整堆结构,在实现上相对简便。只需删除后算法向下调整即可
2.6堆的代码实现
Heap.h
#pragma once
#include<stdio.h>
#include<stdlib.h>
#include<assert.h>typedef int HPDataType;
typedef struct Heap
{HPDataType* _a;int _size;int _capacity;
}Heap;//堆的初始化
void HeapInit(Heap* php);
// 堆的销毁
void HeapDestory(Heap* hp);
// 堆的插入
void HeapPush(Heap* hp, HPDataType x);
// 堆的删除
void HeapPop(Heap* hp);
// 取堆顶的数据
HPDataType HeapTop(Heap* hp);
// 堆的数据个数
int HeapSize(Heap* hp);
// 堆的判空
int HeapEmpty(Heap* hp);//向上调整
void AdjustUp(HPDataType* a, int child);
//向下调整
void AdjustDown(HPDataType* a, int n, int parent);Heap.c
//堆的初始化
void HeapInit(Heap* hp) {assert(hp);hp->_a = NULL;hp->_capacity = hp->_size = 0;
}
// 堆的销毁
void HeapDestory(Heap* hp) {assert(hp);free(hp->_a);hp->_capacity = hp->_size = 0;}
// 堆的插入
void HeapPush(Heap* hp, HPDataType x) {assert(hp);//扩容if (hp->_size == hp->_capacity){int newcapacity = hp->_capacity == 0 ? 2 : hp->_capacity * 2;HPDataType* newa = (HPDataType*)realloc(hp->_a, newcapacity * sizeof(HPDataType));if (newa == NULL){perror("realloc");return;}hp->_capacity = newcapacity;hp->_a = newa;}//插入数据hp->_a[hp->_size] = x;hp->_size++;//向上调整AdjustUp(hp->_a,hp->_size-1);}
void Swaps(HPDataType* a, HPDataType* b) {HPDataType temp;temp = *a;*a = *b;*b = temp;
}
//向上调整(小堆)
//child是数组的下标
void AdjustUp(HPDataType* a, int child) {assert(a);int parent = (child - 1) / 2;while (child > 0){if (a[parent] > a[child]){Swaps(&a[child],&a[parent]);child = parent;parent = (child - 1) / 2;}else{break;}}
}
// 堆的删除
void HeapPop(Heap* hp) {assert(hp);assert(hp->_size);//删除顶部数据 ,先与末尾的交换,在向下调整Swaps(&hp->_a[0],&hp->_a[hp->_size-1]);//让数组首元素,与尾元素交换位置hp->_size--;AdjustDown(hp->_a, hp->_size, 0);}
//向下调整(小堆)
//n是数据数个数
void AdjustDown(HPDataType* a, int n, int parent) {assert(a);//假设法,默认两个孩子最小的是左孩子int child = parent * 2 + 1;//当没有左孩子的时候停止向下调整,拿新算的孩子位置去判断while (child < n){if (child + 1 < n && a[child + 1] < a[child])//挑最小的孩子换,且要注意有没有右孩子{child += 1;}if (a[child] < a[parent])//孩子比父亲小就往上换{Swaps(&a[child], &a[parent]);parent = child;//孩子变成父亲,与他的孩子比child = parent * 2 + 1;}else{break;}}}
// 取堆顶的数据
HPDataType HeapTop(Heap* hp) {assert(hp);assert(hp->_size);return hp->_a[0];
}
// 堆的数据个数
int HeapSize(Heap* hp) {assert(hp);return hp->_size;
}
// 堆的判空
int HeapEmpty(Heap* hp) {return hp->_size == 0;
}3堆的应用 — 堆排序
堆排序,我们肯定是运用堆这个数据结构来完成我们的堆排序
接下来我们将充分的了解堆排序的运作原理
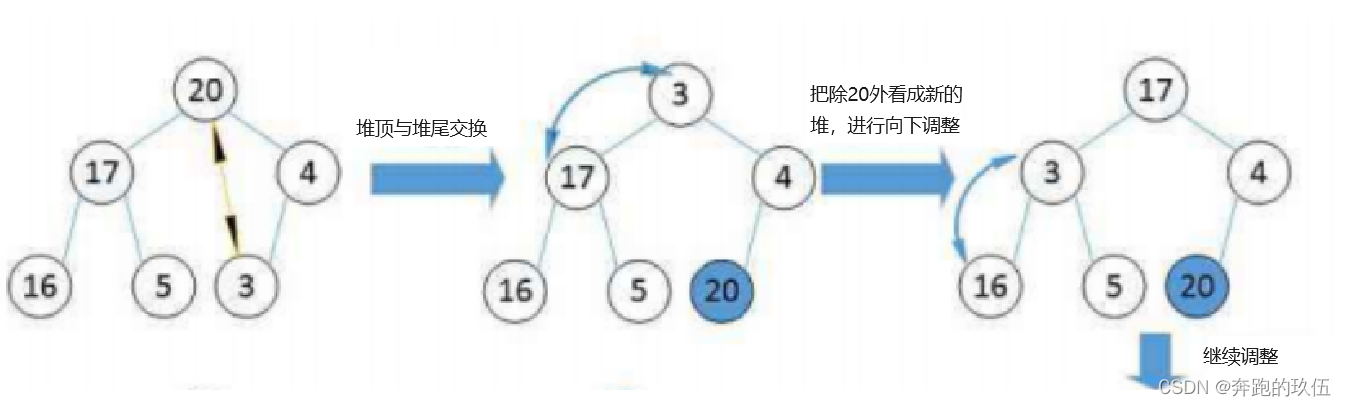
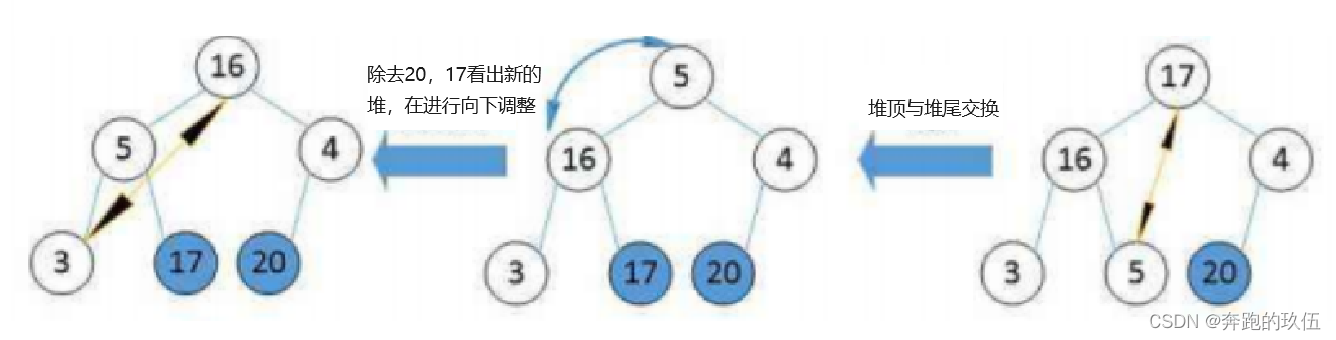
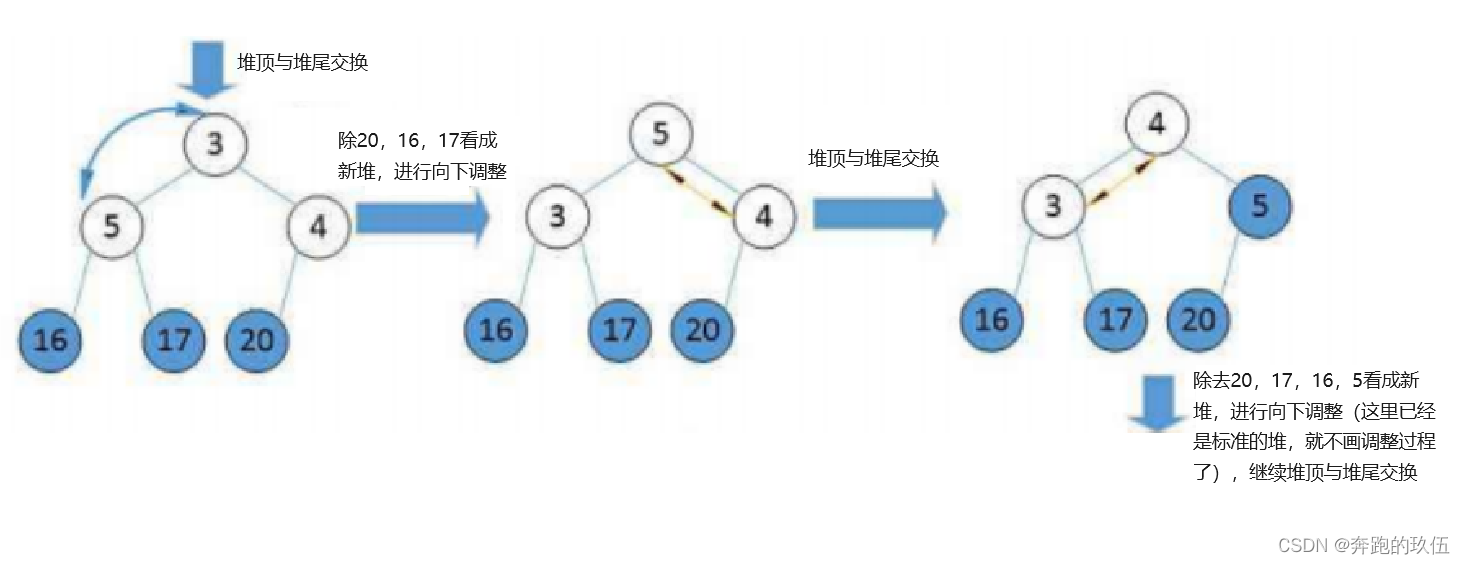
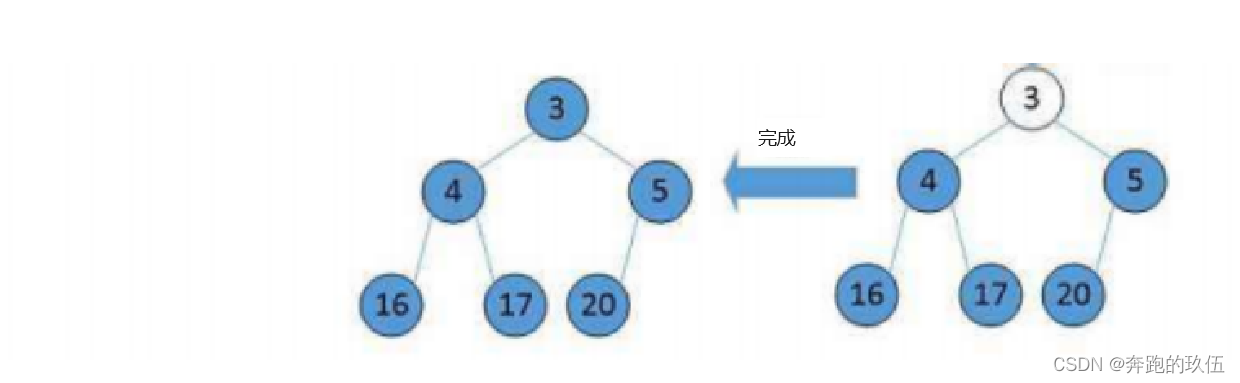
不难看出
- 在每次交换时,堆顶最小的数都会沉到当前堆底
- 小堆在经历过N(数据个数)轮后就会得到一个升序的数组
- 大堆在经历过N(数据个数)轮后就会得到一个降序的数组
知道了堆排序的运转过程之后还有一个问题:使用者不可能说给你一个堆结构让你排序,肯定给的是一串无序且不是堆的数组给你排,这时侯我们就要考虑如何建堆了
3.1建堆
难道说建堆要用到上面写的堆结构,一个一个的去push吗?
其实不然,我们只需要使用向上调整算法或向下调整算法就可以完成建堆
向上调整建堆法
1.构建过程:
- 初始时,将数组的第一个元素视为堆的根节点(对于下标从0开始的数组,根节点的下标为0)
- 对于数组中剩余的元素(从下标1开始),将它们逐个视为“新插入”的元素,并执行向上调整操作
- 在向上调整过程中,对于当前元素,首先计算其父节点的下标(parent = (child - 1) / 2)。然后,比较当前元素与其父节点的值
- 如果当前元素的值大于其父节点的值(对于大根堆),则交换它们的位置。然后,将当前元素设置为新交换位置的父节点,并重复上述步骤,直到当前元素的值不大于其父节点的值或已经到达根节点
- 通过重复上述步骤,直到所有元素都被处理过,最终得到的数组将满足堆的性质
2.时间复杂度:
- 向上调整建堆法的时间复杂度为O(N * logN),其中N是数组中的元素数量
void Swaps(int* a, int* b) {int temp;temp = *a;*a = *b;*b = temp; }//向上调整(小堆) void AdjustUp(int* a, int child) {assert(a);int parent = (child - 1) / 2;while (child > 0){if (a[parent] > a[child]){Swaps(&a[child], &a[parent]);child = parent;parent = (child - 1) / 2;}else{break;}} }//堆排序 void HeapSort(int* a, int n) {//创建堆,向上调整建堆for (int i = 1; i < n; i++) {AdjustUp(a,i);}}
向下调整建堆法
向下调整(Adjust Down)是指从给定的非叶子节点开始,通过与其子节点比较并交换位(如果需要)来确保堆的性质
1.构建过程
- 确定开始位置:
- 对于长度为n的数组,由于堆是完全二叉树,所以最后一个非叶子节点的下标为
(n-1-1)/2(整数除法)- 从这个下标开始,向前遍历所有非叶子节点
- 执行向下调整
- 遍历结束:
- 当所有非叶子节点都经过向下调整后,整个数组就形成了一个堆
2.时间复杂度
向下调整建堆法的时间复杂度为O(N),其中N是数组中的元素数量
void Swaps(int* a, int* b) {int temp;temp = *a;*a = *b;*b = temp; } //向上调整(小堆) void AdjustUp(int* a, int child) {assert(a);int parent = (child - 1) / 2;while (child > 0){if (a[parent] > a[child]){Swaps(&a[child], &a[parent]);child = parent;parent = (child - 1) / 2;}else{break;}} }//堆排序 void HeapSort(int* a, int n) {//创建堆,向下调整建堆int parent = (n - 1 - 1) / 2; //找到最后一个非叶子节点for (parent; parent >= 0; parent--){AdjustDown(a, n, parent);}}
3.2 利用堆删除思想来进行排序
void Swaps(int* a, int* b) {int temp;temp = *a;*a = *b;*b = temp;
}//向上调整(小堆)
void AdjustUp(int* a, int child) {assert(a);int parent = (child - 1) / 2;while (child > 0){if (a[parent] > a[child]){Swaps(&a[child], &a[parent]);child = parent;parent = (child - 1) / 2;}else{break;}}
}//向下调整(小堆)
void AdjustDown(int* a, int n, int parent) {assert(a);int child = parent * 2 + 1;while (child < n){if (child + 1 < n && a[child + 1] < a[child]){child += 1;}if (a[child] < a[parent]){Swaps(&a[child], &a[parent]);parent = child;child = parent * 2 + 1;}else{break;}}}//堆排序
void HeapSort(int* a, int n) {创建堆,向上调整建堆//for (int i = 1; i < n; i++)//{// AdjustUp(a, i);//}//创建堆,向下调整建堆int parent = (n - 1 - 1) / 2;for (parent; parent >= 0; parent--){AdjustDown(a, n, parent);}//小堆,可以排降序while (n){Swaps(&a[0], &a[n - 1]);//交换完成把除了最后一个数据之外的数组看成一个新的堆,开始向下交换,形成新的小堆n--;AdjustDown(a, n, 0);}}4堆的应用 — Top-K问题
- 前k个最大的元素,则建小堆
- 前k个最小的元素,则建大堆
void Swaps(int* a, int* b) {int temp;temp = *a;*a = *b;*b = temp;
}//向下调整(小堆)大的下去
//n是数据数个数
void AdjustDown(HPDataType* a, int n, int parent) {assert(a);int child = parent * 2 + 1;while (child < n){if (child + 1 < n && a[child + 1] < a[child]){child += 1;}if (a[child] < a[parent]){Swaps(&a[child], &a[parent]);parent = child;child = parent * 2 + 1;}else{break;}}}
void CreateNDate()
{// 造数据int n = 10000;srand((unsigned int)time(NULL));const char* file = "data.txt";FILE* fin = fopen(file, "w");if (fin == NULL){perror("fopen error");return;}for (size_t i = 0; i < n; ++i){int x = rand() % 1000000;fprintf(fin, "%d\n", x);}fclose(fin);
}void PrintTopK(int k) {//找出前K个最大的数//打开文件FILE* p = fopen("data.txt", "r");if (p == NULL){perror("fopen error");return;}//构建一个小堆int x = 0;int arr[10] = { 0 };for (int i = k; i < 10; i++){fscanf(p,"%d", &x);arr[i] = x;}//创建堆,向下调整建堆,F(N)int parent = (k - 1 - 1) / 2;for (parent; parent >= 0; parent--){AdjustDown(arr, k, parent);//这里的n数组的位置,里面的child会算出超过数组的位置,这样会停下来}//在将后面的数字依次对比小堆顶部,比它大就向下调整while (fscanf(p, "%d", &x) > 0){if (arr[0] < x){arr[0] = x;AdjustDown(arr, k, 0);}}for (int i = 0; i < k; i++){printf("%d\n", arr[i]);}
}