近年来,深度学习一直在时间序列预测中追赶着提升树模型,其中新的架构已经逐渐为最先进的性能设定了新的标准。
这一切都始于2020年的N-BEATS,然后是2022年的NHITS。2023年,PatchTST和TSMixer被提出,最近的iTransformer进一步提高了深度学习预测模型的性能。
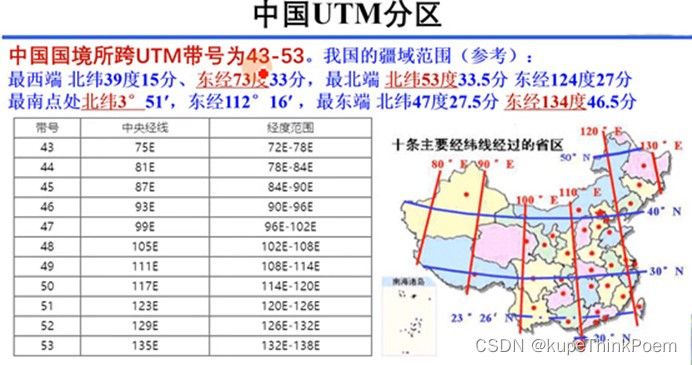
这是2024年4月《SOFTS: Efficient Multivariate Time Series Forecasting with Series-Core Fusion》中提出的新模型,采用集中策略来学习不同序列之间的交互,从而在多变量预测任务中获得最先进的性能。
在本文中,我们详细探讨了SOFTS的体系结构,并介绍新的STar聚合调度(STAD)模块,该模块负责学习时间序列之间的交互。然后,我们测试将该模型应用于单变量和多变量预测场景,并与其他模型作为对比。
SOFTS介绍
SOFTS是 Series-cOre Fused Time Series的缩写,背后的动机来自于长期多元预测对决策至关重要的认识:
首先我们一直研究Transformer的模型,它们试图通过使用补丁嵌入和通道独立等技术(如PatchTST)来降低Transformer的复杂性。但是由于通道独立性,消除了每个序列之间的相互作用,因此可能会忽略预测信息。
iTransformer 通过嵌入整个序列部分地解决了这个问题,并通过注意机制处理它们。但是基于transformer的模型在计算上是复杂的,并且需要更多的时间来训练非常大的数据集。
另一方面有一些基于mlp的模型。这些模型通常很快,并产生非常强的结果,但当存在许多序列时,它们的性能往往会下降。
所以出现了SOFTS:研究人员建议使用基于mlp的STAD模块。由于是基于MLP的,所以训练速度很快。并且STAD模块,它允许学习每个序列之间的关系,就像注意力机制一样,但计算效率更高。
SOFTS架构
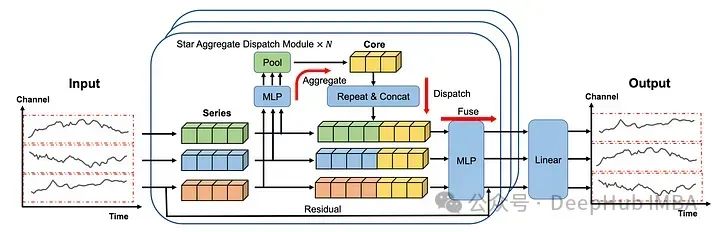
在上图中可以看到每个序列都是单独嵌入的,就像在iTransformer 中一样。
然后将嵌入发送到STAD模块。每个序列之间的交互都是集中学习的,然后再分配到各个系列并融合在一起。
最后再通过线性层产生预测。
这个体系结构中有很多东西需要分析,我们下面更详细地研究每个组件。
1、归一化与嵌入
首先使用归一化来校准输入序列的分布。使用了可逆实例的归一化(RevIn)。它将数据以单位方差的平均值为中心。然后每个系列分别进行嵌入,就像在iTransformer 模型。
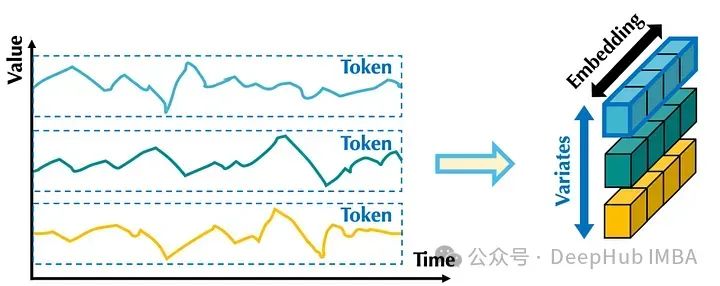
在上图中我们可以看到,嵌入整个序列就像应用补丁嵌入,其中补丁长度等于输入序列的长度。
这样,嵌入就包含了整个序列在所有时间步长的信息。
然后将嵌入式系列发送到STAD模块。
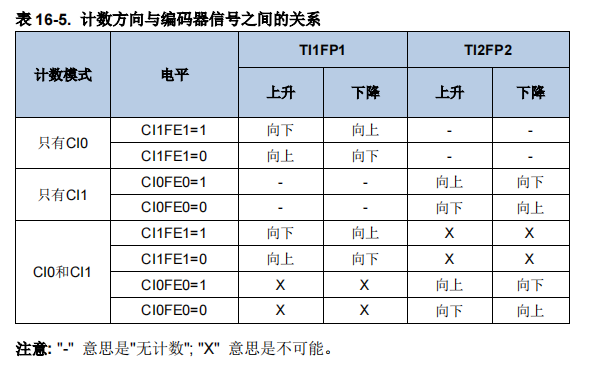
2、STar Aggregate-Dispatch (STAD)
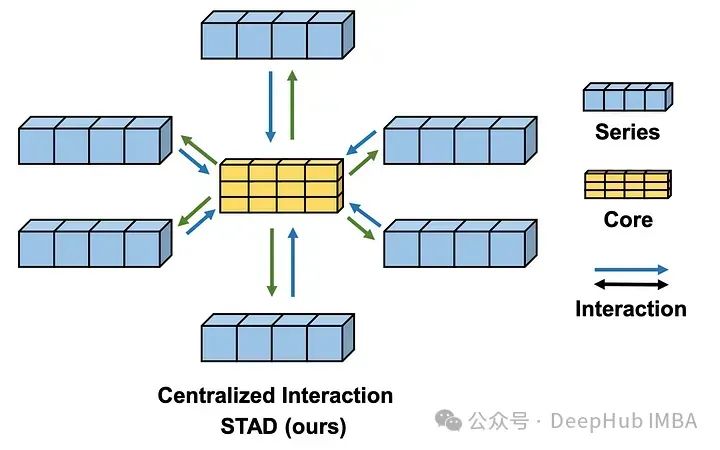
STAD模块是soft模型与其他预测方法的真正区别。使用集中式策略来查找所有时间序列之间的相互作用。
嵌入的序列首先通过MLP和池化层,然后将这个学习到的表示连接起来形成核(上图中的黄色块表示)。
核构建好了以后就进入了“重复”和“连接”的步骤,在这个步骤中,核表示被分派给每个系列。
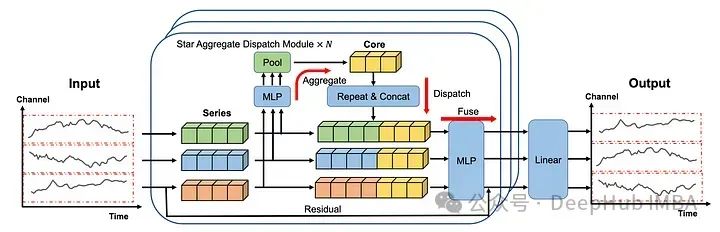
MLP和池化层未捕获的信息还可以通过残差连接添加到核表示中。然后在融合(fuse)操作的过程中,核表示及其对应系列的残差都通过MLP层发送。最后的线性层采用STAD模块的输出来生成每个序列的最终预测。
与其他捕获通道交互的方法(如注意力机制)相比,STAD模块的主要优点之一是它降低了复杂性。
因为STAD模块具有线性复杂度,而注意力机制具有二次复杂度,这意味着STAD在技术上可以更有效地处理具有多个序列的大型数据集。
下面我们来实际使用SOFTS进行单变量和多变量场景的测试。
使用SOFTS预测
这里,我们使用 Electricity Transformer dataset 数据集。
这个数据集跟踪了中国某省两个地区的变压器油温。每小时和每15分钟采样一个数据集,总共有四个数据集。
我门使用neuralforecast库中的SOFTS实现,这是官方认可的库,并且这样我们可以直接使用和测试不同预测模型的进行对比。
在撰写本文时,SOFTS还没有集成在的neuralforecast版本中,所以我们需要使用源代码进行安装。
pip install git+https://github.com/Nixtla/neuralforecast.git
然后就是从导入包开始。使用datasetsforecast以所需格式加载数据集,以便使用neuralforecast训练模型,并使用utilsforecast评估模型的性能。这就是我们使用neuralforecast的原因,因为他都是一套的
import pandas as pdimport numpy as npimport matplotlib.pyplot as pltfrom datasetsforecast.long_horizon import LongHorizonfrom neuralforecast.core import NeuralForecastfrom neuralforecast.losses.pytorch import MAE, MSEfrom neuralforecast.models import SOFTS, PatchTST, TSMixer, iTransformerfrom utilsforecast.losses import mae, msefrom utilsforecast.evaluation import evaluate
编写一个函数来帮助加载数据集,以及它们的标准测试大小、验证大小和频率。
def load_data(name):if name == "ettm1":Y_df, *_ = LongHorizon.load(directory='./', group='ETTm1')Y_df = Y_df[Y_df['unique_id'] == 'OT'] # univariate datasetY_df['ds'] = pd.to_datetime(Y_df['ds'])val_size = 11520test_size = 11520freq = '15T'elif name == "ettm2":Y_df, *_ = LongHorizon.load(directory='./', group='ETTm2')Y_df['ds'] = pd.to_datetime(Y_df['ds']) val_size = 11520test_size = 11520freq = '15T'return Y_df, val_size, test_size, freq
然后就可以对ETTm1数据集进行单变量预测。
1、单变量预测
加载ETTm1数据集,将预测范围设置为96个时间步长。
可以测试更多的预测长度,但我们这里只使用96。
Y_df, val_size, test_size, freq = load_data('ettm1')horizon = 96
然后初始化不同的模型,我们将soft与TSMixer, iTransformer和PatchTST进行比较。
所有模型都使用的默认配置将最大训练步数设置为1000,如果三次后验证损失没有改善,则停止训练。
models = [SOFTS(h=horizon, input_size=3*horizon, n_series=1, max_steps=1000, early_stop_patience_steps=3),TSMixer(h=horizon, input_size=3*horizon, n_series=1, max_steps=1000, early_stop_patience_steps=3),iTransformer(h=horizon, input_size=3*horizon, n_series=1, max_steps=1000, early_stop_patience_steps=3),PatchTST(h=horizon, input_size=3*horizon, max_steps=1000, early_stop_patience_steps=3)]
然后初始化NeuralForecast对象训练模型。并使用交叉验证来获得多个预测窗口,更好地评估每个模型的性能。
nf = NeuralForecast(models=models, freq=freq)nf_preds = nf.cross_validation(df=Y_df, val_size=val_size, test_size=test_size, n_windows=None)nf_preds = nf_preds.reset_index()
评估计算了每个模型的平均绝对误差(MAE)和均方误差(MSE)。因为之前的数据是缩放的,因此报告的指标也是缩放的。
ettm1_evaluation = evaluate(df=nf_preds, metrics=[mae, mse], models=['SOFTS', 'TSMixer', 'iTransformer', 'PatchTST'])
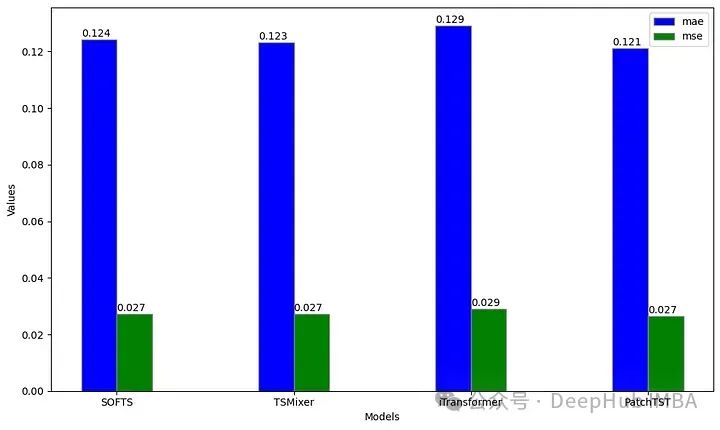
从上图可以看出,PatchTST的MAE最低,而softts、TSMixer和PatchTST的MSE是一样的。在这种特殊情况下,PatchTST仍然是总体上最好的模型。
这并不奇怪,因为PatchTST在这个数据集中是出了名的好,特别是对于单变量任务。下面我们开始测试多变量场景。
2、多变量预测
使用相同的load_data函数,我们现在为这个多变量场景使用ETTm2数据集。
Y_df, val_size, test_size, freq = load_data('ettm2')horizon = 96
然后简单地初始化每个模型。我们只使用多变量模型来学习序列之间的相互作用,所以不会使用PatchTST,因为它应用通道独立性(意味着每个序列被单独处理)。
然后保留了与单变量场景中相同的超参数。只将n_series更改为7,因为有7个时间序列相互作用。
models = [SOFTS(h=horizon, input_size=3*horizon, n_series=7, max_steps=1000, early_stop_patience_steps=3, scaler_type='identity', valid_loss=MAE()),TSMixer(h=horizon, input_size=3*horizon, n_series=7, max_steps=1000, early_stop_patience_steps=3, scaler_type='identity', valid_loss=MAE()),iTransformer(h=horizon, input_size=3*horizon, n_series=7, max_steps=1000, early_stop_patience_steps=3, scaler_type='identity', valid_loss=MAE())]
训练所有的模型并进行预测。
nf = NeuralForecast(models=models, freq='15min')nf_preds = nf.cross_validation(df=Y_df, val_size=val_size, test_size=test_size, n_windows=None)nf_preds = nf_preds.reset_index()
最后使用MAE和MSE来评估每个模型的性能。
ettm2_evaluation = evaluate(df=nf_preds, metrics=[mae, mse], models=['SOFTS', 'TSMixer', 'iTransformer'])

上图中可以看到到当在96的水平上预测时,TSMixer large在ETTm2数据集上的表现优于iTransformer和soft。
虽然这与soft论文的结果相矛盾,这是因为我们没有进行超参数优化,并且使用了96个时间步长的固定范围。
这个实验的结果可能不太令人印象深刻,我们只在固定预测范围的单个数据集上进行了测试,所以这不是SOFTS性能的稳健基准,同时也说明了SOFTS在使用时可能需要更多的时间来进行超参数的优化。
总结
SOFTS是一个很有前途的基于mlp的多元预测模型,STAD模块是一种集中式方法,用于学习时间序列之间的相互作用,其计算强度低于注意力机制。这使得模型能够有效地处理具有许多并发时间序列的大型数据集。
虽然在我们的实验中,SOFTS的性能可能看起来有点平淡无奇,但请记住,这并不代表其性能的稳健基准,因为我们只在固定视界的单个数据集上进行了测试。
但是SOFTS的思路还是非常好的,比如使用集中式学习时间序列之间的相互作用,并且使用低强度的计算来保证数据计算的效率,这都是值得我们学习的地方。
并且每个问题都需要其独特的解决方案,所以将SOFTS作为特定场景的一个测试选项是一个明智的选择。
SOFTS: Efficient Multivariate Time Series Forecasting with Series-Core Fusion
https://avoid.overfit.cn/post/6254097fd18d479ba7fd85efcc49abac