源自:软件学报
作者:梁震, 刘万伟, 吴陶然, 薛白, 王戟, 杨文婧
注:若出现无法显示完全的情况,可 V 搜索“人工智能技术与咨询”查看完整文章
摘 要
随着智能信息时代的发展, 深度神经网络在人类社会众多领域中的应用, 尤其是在自动驾驶、军事国防等安全攸关系统中的部署, 引起了学术界和工业界对神经网络模型可能表现出的错误行为的担忧. 虽然神经网络验证和神经网络测试可以提供关于错误行为的定性或者定量结论, 但这种事后分析并不能防止错误行为的发生, 如何修复表现出错误行为的预训练神经网络模型依然是极具挑战性的问题. 为此, 深度神经网络修复这一领域应运而生, 旨在消除有缺陷的神经网络产生的错误预测, 使得神经网络满足特定的规约性质. 目前为止, 典型的神经网络修复范式有3种: 重训练、无错误定位的微调和包含错误定位的微调. 介绍深度神经网络的发展和神经网络修复的必要性; 厘清相近概念; 明确神经网络修复的挑战; 详尽地调研目前已有的神经网络修复策略, 并对内在联系与区别进行分析和比较; 调研整理神经网络修复策略常用的评价指标和基准测试; 展望未来神经网络修复领域研究中需要重点关注的可行方向.
关键词
深度神经网络修复 错误行为 重训练 微调 错误定位
引 言
近年来, 随着计算硬件算力的提升和数据规模的不断增长, 深度神经网络(deep neural network, DNN)迅猛发展, 成为深度学习(deep learning, DL)的主要计算模型, 在图像识别[1−3]、自然语言处理[4−6]、自动驾驶[7,8]、医药医学[9,10]、恶意软件检测[11,12]等各个领域取得了巨大成功. 特别是以ChatGPT[13]为代表的大模型的面世, 人类社会与深度神经网络模型的交织和联系将会更加紧密和深厚.
尽管深度神经网络在众多领域取得了极大的成功, 但是神经网络并不总是正确的, 也就是说在一些情况下, 它们可能产生不满足预期性质的输出结果. 例如对一张大熊猫的图片进行肉眼难以察觉的噪声扰动, 原来可以正确处理这张图片的神经网络以99.3%的概率误认为它是长臂猿[14]. 这样的错误行为可能导致系统故障[15,16]、错误的刑事拘捕[17,18]、甚至生命财产的损失[19]. 比如, 一个不公平的神经网络, 相较于白色人种, 它可能更倾向于预测黑色人种是犯罪嫌疑人, 从而引起警力资源的浪费和错误的拘捕; 对一张“STOP”道路指示牌进行局部的遮挡, 神经网络将会错误地将其识别为“限速”的路标, 这会使得自动驾驶汽车存在严重的安全隐患[20]. 因此, 鉴于深度神经网络表现出的错误行为, 其在安全攸关领域的应用受到极大限制, 这成为一个重要而亟待解决的研究问题.
为了获得用户对深度神经网络的信任, 减轻他们对于错误行为的担忧, 确保深度神经网络在部署到实际应用之前满足特定要求并产生预期输出就显得至关重要. 近几年, 深度神经网络验证(DNN verification)[21−39]、深度神经网络测试(DNN testing)[40−45]和基于性质满足的深度神经网络训练(DNN property-satisfaction-guided training)[23,46−51]等方面的进展为解决这个问题提供了思路. 神经网络验证指的是判断训练好的神经网络模型是否满足某些特定的规约性质, 比如安全性(safety)[52], 鲁棒性(robustness)[14], 公平性(fairness)[53]和可达性(reachability)[54,55]等, 学术界提出了多种验证技术, 包括基于抽象解释(abstract interpretation)的[22−26], 基于可满足性模理论(satisfaction module theory, SMT)的[27−30]和基于凸优化理论(convex optimization theory)的[31−34]验证技术等, 对多种神经网络模型进行了验证. 与软件测试类似, 神经网络测试是通过大量的测试用例来评估神经网络的行为, 判断是否存在错误行为, 近几年在测试的覆盖标准[43]和用例生成[44,45]方面取得了重大进展. 然而, 神经网络验证和神经网络测试都是事后分析, 也就是说, 它们只能提供错误行为是否存在的定性或者定量结论, 当神经网络不满足某个性质时, 神经网络验证或者测试的结果并不能缓解这些违背情况. 相反, 基于性质满足的深度神经网络训练方法抛开了预训练模型, 专注于从头开始构建并训练一个满足特定性质的神经网络(满足程度可以通过神经网络验证或者测试进行评估), 尤其是基于鲁棒性质的深度神经网络的训练方法获得了众多关注并取得了重大突破, 感兴趣的读者可以阅读文献[50]以更全面地了解该领域的进展.
无论是神经网络验证、神经网络测试还是基于性质满足的神经网络训练, 当面对一个具有错误行为的神经网络模型时, 它们都将失效, 也就是说这几种方法对于神经网络模型已经表现出的错误行为无能为力. 为了解决这个问题, 深度神经网络修复(DNN repair)[56−77]应运而生, 即当发现神经网络表现出错误行为时(通过神经网络验证或测试技术实现), 神经网络修复旨在消除这些错误行为, 使修复后的神经网络满足特定的规约性质, 同时最大限度地减少对网络模型性能的影响.
本文将主要介绍重训练(retraining)、无错误定位的微调修复(fine tuning without fault localization)和包含错误定位的微调修复(fine tuning with fault localization)这3类常见的神经网络修复策略, 并对不同修复方法之间的异同进行分析和梳理. 本文第2节介绍了必要的基础知识并给出了神经网络修复问题的形式化定义和常见的修复要求. 第3节介绍了近几年提出的3类常见深度神经网络修复策略的核心思想, 包括基于反例制导的、基于神经网络验证的、基于优化问题的、基于约束求解的、基于搜索的、基于函数空间优化的修复策略, 并对不同的修复策略进行了比较和分析. 第4节介绍了目前常见的神经网络修复策略的评价指标和测试基准. 第5节展望了神经网络修复策略领域未来可能的研究方向. 第6节对全文内容进行了总结. 图1从年份和核心思想两个维度列举了本文介绍的神经网络修复策略, 其中重训练、无错误定位的微调修复和包含错误定位的微调修复分别用红色、绿色和蓝色矩形框展示. 需要注意图1的分类结果只考虑各个修复策略的主要创新, 不是严格唯一的.

图 1 主要神经网络修复策略展示
2 神经网络修复
本节在补充介绍神经网络及其规约性质的基础上, 介绍了神经网络修复问题的定义和常见的神经网络修复要求. 此外, 为了更好地理解和辨清神经网络修复问题, 本节比较讨论了神经网络修复与其他相近概念的异同.
2.1 神经网络及规约性质
通常来说, 一个L层深度神经网络N包含一个输入层(input layer), 一个输出层(output layer)和若干个连续的隐藏层(hidden layer)[78], 分别为
![]()
, 其计算过程近似了一个高度复杂的函数
![]()
, 其中m 和n 分别是输入层和输出层神经元的个数, 也称作输入/输出维度(input/output dimension)[79,80]. 神经网络中相邻的两个网络层之间一般包含一个仿射变换(affine transformation)和一个非线性激活函数(nonlinear activation function), 最后两层之间一般只有仿射变换. 相邻两层神经元之间边上的权重(weight)和偏置(bias)实现了仿射变换, 而神经网络对于高度复杂函数的近似能力则来源于非线性激活函数的使用, 常见的激活函数有ReLU, tanh和Sigmoid等, 其中
![]()
是分段线性的, tanh和Sigmoid则是严格非线性的. 一般用θ 统一指代神经网络参数, 并把具有这一组参数的神经网络记作Nθ . 神经网络的训练过程是基于训练数据集(training dataset)D 按照深度学习算法对神经网络的参数θ 进行调整更新, 以期在训练数据集上获得较好的拟合能力, 并且在测试数据集(testing dataset)DT 上具有较好的泛化能力[78].
在部署到实际应用之前, 特别是在安全攸关领域, 深度神经网络需要满足一定的性质, 如分类正确性、鲁棒性、安全性、可达性等. 因此, 神经网络性质的形式化描述应运而生, 并被广泛应用于基于性质满足的神经网络训练和神经网络验证等相关领域. 神经网络Nθ 的一个规约性质P 通常由3个部分组成, 一个输入集合X , 一个输出集合Y 和这两个集合之间的映射关系ϕ , 即P:=(X;Y;ϕ) . 输入集合X 是输入域
![]()
上的约束, 它描述了Nθ 的一个输入的可行域, 输出集合Y 则给出了
![]()
空间中的一个输出范围. 映射要求ϕ 对Nθ 在输入集合X 和输出集合Y 之间施加了一个行为要求, 当映射关系ϕ 成立时, 神经网络Nθ 满足性质P ; 否则神经网络Nθ 违背性质P . 特别地, 把样本xp∈{x|x∈X,N(x)∈Y} 和xn∈{x|x∈X,N(x)∉Y} 分别称作性质P 的正样本(positive sample, 或者正例)和负样本(negative sample, 或者反例), 其中N(x) 是神经网络Nθ 关于样本x 的输出结果. 包含反例的性质P 在神经网络Nθ 上不成立, 网络Nθ 关于性质P 是一个待修复的错误神经网络(buggy/defective DNN). 为了描述的简洁性, Nθ⊨(X;Y;ϕ) 表示神经网络Nθ 满足性质约束P , 而Nθ⊭(X;Y;ϕ) 表示规约性质P 不适用神经网络Nθ . 表1给出了常见的几种神经网络规约性质的形式化描述, 此处区域以多面体(polytope)的半空间法(H-representation)[81]进行举例表示.

表 1 常见神经网络规约性质举例
对于神经网络Nθ 的一个规约性质集合
![]()
分别表示
![]()
在Nθ上的可满足性和不满足性, 分别定义为
![]()
和
![]()
. 也就是说, 规约性质集
![]()
在神经网络Nθ 上成立当且仅当集合中的每个性质都在Nθ 上成立, 而不成立意味着该规约集合中至少有一个性质被Nθ 违反.
2.2 神经网络修复问题
基于上述的背景知识, 神经网络的修复问题定义如下.
定义1. 神经网络修复问题(DNN repair problem). 给定一个待修复的初始神经网络Nθ 以及它所违背的规约性质集
![]()
, 即
![]()
. 神经网络修复问题是指通过某种修复手段将参数集θ 修改为θ′ , 得到的修复后的神经网络Nθ′ 满足约束性质集合, 即
![]()
值得注意的是, 上面的定义没有显式地要求初始待修复网络Nθ 和修复后的网络Nθ′ 必须保持同样的网络结构, 这意味着修复策略可以保持原有网络结构, 只调整网络参数; 也可以在调整参数的同时, 基于原有的网络结构进行额外的结构设计或扩展, 从而完成神经网络修复. 目前已有的修复方法中, 这两种修复类型都存在并且也都取得了一定的成效.
因为神经网络规约性质及其描述类型的不同, 近几年出现了各种更具体的神经网络修复问题. 从其所修复的网络性质来看, 神经网络修复问题可以分为神经网络安全性修复(DNN safety repair), 神经网络公平性修复(DNN fairness repair), 神经网络鲁棒性修复(DNN robustness repair)等. 本文重点介绍另一种更为一般和简洁的分类方式, 即按照规约性质所描述的输入/输出集合的类型进行划分, 分为基于样本的神经网络修复问题(sample-wise DNN repair problem, SRP)和基于区域的神经网络修复问题(domain-wise DNN repair problem, DRP), 它们的定义如下.
定义2. 基于样本的神经网络修复问题(sample-wise repair problem, SRP). 给定一个待修复的神经网络Nθ 以及它所违背的规约性质集
![]()
, 即
![]()
其中每个性质Pi 的输入集合X 和输出集合Y 描述了相应空间内的样本点的集合. 神经网络样本修复问题是指通过某种修复手段将参数集θ 修改为θ′ , 得到的修复后的神经网络Nθ′ 满足这些以样本点形式描述的约束性质集合, 即
![]()
.
定义3. 基于区域的神经网络修复问题(domain-wise repair problem, DRP). 给定一个待修复的神经网络Nθ 以及它所违背的规约性质集

, 其中每个性质Pi 的输入集合X 和输出集合Y 描述了相应空间内的一个区域(如区间, 多面体等). 神经网络区域修复问题是指通过某种修复手段将参数集θ 修改为θ′, 得到的修复后的神经网络Nθ′ 满足这些以区域形式描述的约束性质集合, 即
![]()
此外, 将同时包含了样本点和区域的修复问题也分类为基于区域的神经网络修复问题, 这是因为修复区域内样本的无穷性和不可遍历性使得区域修复相较于样本修复更具挑战性. 为了表达简洁, 后文将初始待修复神经网络Nθ 和修复后的神经网络Nθ′ 分别简记为N 和N′ , 基于样本(区域)的神经网络修复问题也会表述为神经网络样本(区域)修复问题.
2.3 神经网络修复要求
对于一个深度神经网络修复策略, 除了达到基本的修复目的之外, 在修复过程中还需要考虑其他的要求, 比如局部性、泛化性、效率等, 表2展示了主要的深度神经网络修复要求及其概念内涵.

表 2 常见神经网络修复要求
需要说明的是, 这些评价指标各有侧重, 它们之间并不是完全分割和独立的. 比如修复策略的可扩展性在一定程度上也反映了它们的效率和性能, 可证明性在一定程度上限制了修复策略的可扩展性, 而修复策略的最小性和局部性也有部分意义上的重叠. 第3节列举的神经网络修复策略或框架不同程度地考虑了以上修复要求的一个子集.
2.4 相近概念的讨论和区别
这一部分比较和区分了神经网络修复与神经网络程序修复、神经网络数据集修复、传统软件程序修复和神经网络辅助的程序修复等相近的概念.
2.4.1 神经网络修复与神经网络程序修复
神经网络程序修复(DNN program repair)指的是修复一个使用深度学习框架编写的报错的神经网络程序中存在的漏洞(bug)[82−84], 其本质还是程序修复, 而神经网络修复是对神经网络程序正确运行后的神经网络产品进行修复. Islam等人[84]使用由来自Stack Overflow的415个神经网络程序漏洞和来自GitHub的555个漏洞组成的深度神经网络程序漏洞数据集对5个深度学习库Caffe、Keras、TensorFlow、Theano和PyTorch的漏洞修复模式进行了全面研究, 分析了神经网络程序修复模式的以下几个方面: (1)常见的漏洞修复模式; (2)修复多种漏洞类型的模式; (3)跨深度学习库的漏洞的修复模式; (4)修复风险; (5)修复神经网络程序漏洞的挑战.
2.4.2 神经网络修复与神经网络数据集修复
神经网络数据集修复(DNN dataset repair)是指通过使用一些技术来修复损坏或不完整的神经网络数据集. 在复杂的神经网络任务中, 数据集通常需要进行归一化、标准化、去噪或者与其他数据集进行集成来提高数据质量[85,86]. 因此, 数据集修复是神经网络技术的重要组成部分, 可以帮助提高神经网络的准确性和可靠性. 常见的数据集修复技术包括数据清洗、数据采样、数据增强、数据集合等. 与神经网络的数据集修复不同, 在神经网络修复的问题设定下, 数据集是假设正确的, 问题的核心在于神经网络不能正确处理某些输入样本得到预期的输出结果.
2.4.3 神经网络修复与传统软件修复
传统软件修复(software repair)是修复程序中存在的漏洞, 使软件输出正确的预期的输出结果[87−89]. 与传统软件修复相比, 神经网络修复有着更大的区别. 当修复软件中的漏洞时, 常规做法是对已知的错误代码进行细致检查, 找出具体问题, 并对其进行适当的修改. 这些问题通常是由于代码逻辑错误、浮点计算误差以及其他各种常见错误引起的. 一旦问题被发现, 程序员可以快速修复缺陷. 此外, 软件开发人员有众多工具可以帮助他们识别和修复漏洞, 例如调试器和自动化测试工具等. 然而, 神经网络修复是一个更加复杂的过程. 神经网络模型的行为是由其参数确定的, 但参数并不是手动编写, 而是根据学习算法自动从训练数据中习得. 因此, 在修复神经网络模型的缺陷时, 需要更多技巧来找到正确的解决方案. 可能还需要通过调整网络模型结构、更改训练算法和优化训练过程等方法来纠正错误行为, 使模型能够更好地拟合数据. 但是, 成熟的传统软件修复技巧为神经网络的修复提供了很好的参考和指导.
2.4.4 神经网络修复与神经网络辅助的程序修复
神经网络在神经网络辅助的程序修复(DNN aided program repair)和神经网络修复两个领域中承担不同角色. 神经网络辅助的程序修复是近年来软件工程从业者利用神经网络来修复程序中漏洞的研究领域[90−92], 神经网络作为一种新型的修复工具被引入到传统软件修复中. 而神经网络修复则是指修复表现出错误行为的神经网络, 神经网络是待修复对象, 一般借助于软件工程领域的方法和工具进行神经网络修复.
3 神经网络修复策略的研究现状
目前已有的神经网络的修复策略或者框架主要分为以下3类: 重训练、无错误定位的微调修复和包含错误定位的微调修复. 本节将近几年来的神经网络修复策略相关的工作按照这3种大的类别进行组织和概述, 此外每小节对每一类方法进行了更为细致的对比, 使得修复策略的综述更加系统和容易理解. 接下来将详细介绍具体的神经网络修复策略.
本节所介绍的修复策略的总体对比展示在表3中, 分别从修复类型(支持求解样本修复问题或区域修复问题)、支持修复的网络性质、支持修复的神经网络所采用的激活函数、修复策略的可证明性、对于原有网络结构的保持性、支持求解修复问题的规模以及局限性等几个方面进行了总体比较.

表 3 神经网络修复策略对比
3.1 基于重训练的修复策略
为了更好地理解重训练的神经网络修复方法, 首先需要和基于性质满足的深度神经网络训练方法进行区分. 基于性质满足的神经网络训练方法专注于从头构建和训练满足特定规约性质的神经网络, 而重训练的修复方式则是在原有的网络模型基础上继续进行神经网络训练. 从参数更新空间上来看, 基于性质满足的神经网络训练有更大的参数搜索空间, 而基于重训练的神经网络修复则受限于修复的要求(比如局部性, 最小性等), 其参数搜索空间相对更小.
3.1.1 Apricot[57]
Zhang等人[57]提出的Apricot修复框架旨在通过权重自适应方法迭代地修复神经网络模型, 其核心思想在于如果在原始训练数据集的许多不同子集上训练深度学习的神经网络模型, 则所得简化深度学习模型(reduced deep learning model, rDLM)中的权重可以提供关于原始模型Nθ 权重调整方向和大小的见解, 以处理原始网络模型错误分类的测试用例. 这种方法基于两个观察结果, 首先随着数据集D0 规模的增加, 神经网络模型将越来越难以保留大部分权重来捕获所有基本特征. 第2个观察是, 考虑一对神经网络, 分别记为N0 和Nsub , 它们的训练过程相同, 只是模型N0 是在整个数据集D0 上训练, 而模型Nsub 是在D0 的一个子集Dsub 上训练, 模型Nsub 就是简化深度学习模型. 一般来说每个单独的简化深度学习模型可能不能完全捕获正确分类一个特定测试用例所需的基本特征, 但这组简化深度学习模型的集中趋势可能会正确地对测试用例进行分类.
后文图2展示了Apricot修复策略的工作流程: 给定神经网络模型N0 和训练数据集D0 , Apricot首先生成一组简化深度学习模型. 然后以N0 作为第1次迭代的输入深度学习模型(input DLM, iDLM). 在第k 次迭代时, 对于Nk的每个失败测试用例x , Apricot将简化深度学习模型集划分为两个类别, 分别表示为IncorrectSubModel(x)和CorrectSubModel(x) , 这两个类别中的每个简化深度学习模型分别对样本x 进行了错误和正确的分类. 然后, 对于Nk的权重w , Apricot取两个类别中简化网络模型的相应权重的集中趋势来调整w . 接下来, 它用D0 训练调整后的Nk, 以产生k+1 次迭代步骤的下一个输入模型Nk+1. 在所有迭代完成后, Apricot输出一个具有权重自适应的神经网络模型, 即修复神经网络Nθ′ .

图 2 Apricot神经网络修复策略工作流程
3.1.2 可编辑神经网络(editable neural networks, ENNs)[58]
目前大部分的神经网络, 对单个输入样本的预测要依赖所有的模型参数, 因此针对特定的输入对神经网络进行行为纠正很难不影响模型在其他输入上的性能表现. 基于此, Sinitsin等人[58]提出可编辑神经网络以及与之相对应的可编辑训练(editable training)的神经网络训练方法. 可编辑训练采用了新的目标函数
![]()
训练过程是多目标优化的过程, 其中, 基底目标函数Lbase(θ) 保证初始模型为Nθ 的训练; 编辑训练目标函数
![]()
, 其中Edit(θ,le) 被称为编辑函数, 目标在于在训练过程中调整参数集θ 使得le(θ)⩽0 , le(θ) 则是根据具体任务设计的修复目标函数, 比如对于分类任务,
![]()
保证了yref 是网络的预期最大输出, 即分类结果. 局部性目标函数
![]()
则保证了修复的局部性, 即尽量保证修复后的神经网络Nθ′ 在其他输入样本上的性能表现不受影响. 超参数cedit , cloc 设置充分小, 使得训练过程中保证Lbase(θ) 受到较小的影响, 同时也保证网络修复的局部性. 因为网络参数的冗余性, 可以保证上述目标函数得到优化.
图3展示了可编辑神经网络的前向传播和反向传播过程. 编辑函数采用梯度下降实现, 作者也找到了一些使得权重更新更加鲁棒且改善局部性的方法, 比如采用RPROP[93]、signSGD[94]、RMSProp[95]等弹性反向传播(resilient backpropagation)的参数更新策略.

图 3 可编辑神经网络的训练过程
3.1.3 Veritex[69]
Veritex是Yang等人[69]提出的一种利用可达性分析来修复安全攸关系统中不安全的ReLU神经网络的方法. Veritex首先通过可达性分析来计算神经网络的精确的不安全的多面体可达域(这也是激活函数限定为ReLU函数的原因)[96], 然后在重训练过程中使用一个损失函数项来表示不安全可达域与安全区域的距离Ldist(θ) . 由于神经网络参数的细微变化可能导致意想不到的模型性能下降, 因此Veritex在最小化可达域与安全域距离的同时, 也考虑了另外一个损失函数项Ldiff(θ,θ′) 来追求最小的神经网络修复, 损失项Ldiff 主要是优化原有网络Nθ 和修复后的神经网络Nθ′ 在原有数据集上的输出差距. 最终重训练过程采用两项损失函数的线性组合来进行网络参数更新. 此外, Veritex修复策略还可以与深度强化学习(deep reinforcement learning, DRL)算法[97]集成来修复神经网络智能体(DNN agent)的错误行为.
3.1.4 SpecRepair[70]
Bauer-Marquart等人[70]提出的SpecRepair是重训练修复范式的又一个代表性工作, 其核心思想在于将安全规约性质转换为目标函数, 该目标函数对于所有违反性质的网络输入都是负值, 然后使用全局优化方法检测反例. 接着利用这些检测到的反例, 通过惩罚性的重训练使得神经网络变得安全. SpecRepair专注于神经网络安全性修复, 构造了一个原始网络损失函数Lbase(θ) 与安全性质满足性Lsat(θ) 相结合的目标函数来指导重训练过程. SpecRepair将违反安全性的反例生成问题转化为优化问题进行求解. 基于反例和神经网络原有的训练数据, 框架设计了一种自动修复机制, 该机制使用上述损失函数在原有神经网络的基础上进行额外的训练迭代, 追求在保持高精度的同时消除错误行为. 重训练完成后, 反例生成组件再次执行. 如果没有反例被检测到, 神经网络验证器会检查修复网络是否遵从所要求的安全性质. 由于反例搜索是快速但不完整的, 验证器可能仍然会找到反例, 在这种情况下, SpecRepair会重新返回到修复组件. 否则, 修复后的神经网络Nθ′ 被SpecRepair验证并返回.
3.1.5 重训练方法对比分析
在表4中, 从核心思想、性质改进、性能保持和特点等4个方面对基于重训练的神经网络修复策略进行了总结和比较, 其中BIRDNN框架的重训练修复策略的相关介绍参见本文第3.3.9节. 可以看到基于重训练的神经网络修复策略的核心在于构造一个可以更好兼顾改进被违背的规约性质和保持原有性能的损失函数. 损失函数的设计极大影响了修复策略的评估, 比如Veritex修复策略需要计算准确可达集, 这就导致其对激活函数的高要求和较差的可扩展性. 一般而言, 重训练修复方法的计算代价比较高昂, 尤其是大规模神经网络的训练可能需要耗费数日. 此外原始神经网络的训练数据集也并不总是公开可用的, 这也为重训练修复带来一定的困难和挑战.

表 4 重训练神经网络修复方法对比
3.2 无错误定位的微调修复策略
在重训练修复策略中, 全局性且没有区分的参数更新可能会导致神经网络的行为发生剧烈的变化, 因此, 神经网络微调修复致力于局部地、有倾向地、轻微地修复有缺陷的神经网络, 即修补神经网络参数的特定子集, 以消除神经网络的错误预测.
3.2.1 MVDNN (modification with verification for DNNs)[59]
MVDNN试图将神经网络的修复问题转化为神经网络验证问题, 借助目前更加成熟的验证器来进行可证明的神经网络修复. 在修改权重的过程中, MVDNN限制了对神经网络进行更改的参数的数量和修改值的大小. 具体来说, MVDNN的目标确保修复后的神经网络Nθ′ 满足给出的规约性质的同时最小化原始网络Nθ 和修复网络Nθ′ 之间的参数差异. 这很容易借助于神经网络验证表示为一个优化问题, 并通过现有的SMT验证工具来解决. 但是基于SMT的神经网络验证工具一般可扩展性较差, 因此需要进一步降低优化问题的复杂度, 使这种修复方法可以应用于大型网络, 为此MVDNN将修改的网络权重限制在单层的权重. 然而, 即使当神经网络修复问题仅限于单层权重修改时, 针对较大输入区域的网络性质也会使得到的神经网络验证问题的求解变得困难. 因此, Goldberger等人[59]进一步将单层修复限制在网络的输出层修复上, 此时神经网络验证问题将变成复杂度更低的线性规划(linear programming)问题(输出层不包含激活函数). 直观地说, 仅更改输出层的权重会使得验证问题完全线性化, 这意味着它可以使用线性规划求解器来解决, 这往往比其他神经网络验证工具更具有可扩展性.
3.2.2 3M-DNN (minimal multi-layer modifications of DNNs)[66]
3M-DNN的关键思想是依据某些分离层(separation layer)将原始神经网络N分成多个子网络, 然后尝试分别为每个子网络找到最小的修复补丁, 从而给初始网络N带来期望的整体变化. 事实上, 修改神经网络的多层可能会产生许多难以预测的复杂影响(尤其是可能引入新的错误行为), 而仅改变网络的一层可能又不足以完全修复网络. 因此, Refaeli等人[66]试图将多层神经网络修复问题分解为一系列更容易解决的单层修复问题. 3M-DNN由两个逻辑层次组成, 即顶层的搜索和底层的单层修复. 3M-DNN首先对分离层可能的修改值进行启发式搜索, 文章特别研究了3种不同的启发式: 随机搜索(random search)、贪婪搜索(greedy search)和蒙特卡罗树搜索(Monte Carlo tree search, MCTS)[98], 理论上其他搜索方式也是可行的. 在使用启发式搜索找到每个分离层的修改值的指派后, 3M-DNN将计算使用该修复方案的总体修复代价(通过合并更改每个单独子网络来计算). 3M-DNN无法保证每次都能获得期望结果的修改方案, 因此3M-DNN进行下一次迭代来进一步优化探索分离层值的不同变化, 并记录到目前为止遇到的最小修复代价的修复方案. 3M-DNN是随时可用的, 无论何时停止, 它都会返回到目前为止发现的最佳(最小)更改.
3.2.3 PRDNN (provable repair of DNNs)[60]
Sotoudeh等人[60]提出的PRDNN是一种可证明的神经网络样本修复和区域(特指多面体)修复技术, 同时, PRDNN可以保证原有网络N和修复网络N′ 的差距(参数距离)是单层修复中最小的. 针对于样本修复问题, 即使是单层神经网络的可证明修复也是一个NP-hard问题, 在实际求解过程中可行性相对较低[59]. 然而, 如果神经网络的最后一层是线性的, 那么网络修复则将转换成一个线性规划问题, 可以在多项式时间内解决. PRDNN样本修复对神经网络使用的激活函数没有限制, 其关键见解是引入了一种新的深度神经网络架构, 称为解耦深度神经网络(decoupled deep neural networks, DDNNs), 每个深度神经网络都存在一个等效的解耦深度神经网络, 并且修复解耦深度神经网络中的任何单层都可以简化为线性规划问题[59]. 针对于分段线性神经网络的多面体区域修复, 网络行为在每个线性区域内保持凸性, 凸性保证任何给定的多面体当且仅当其顶点被映射到另一个多面体的顶点, 因此多面体修复问题可以简化为样本修复问题, 从而克服了输入区域中样本点的无限性和不可遍历性. 值得注意的是, 激活函数分段线性的假设保证了线性区域的计算, 但是, 由于计算神经网络的线性多面体区域的计算复杂性[99], 修复多面体的维度通常只有一维或二维是可行的; 将得到的解耦深度神经网络转换得到标准和等效的深度神经网络依然是一个亟待解决的问题.
3.2.4 LRNN (local repair of neural networks using optimization)[64]
LRNN是Majd等人[64]提出的一种神经网络修复框架, 使用混合整数二次规划(mixed-integer quadratic program, MIQP)[100]来生成满足给定神经网络规约性质的网络修复方案. LRNN将规约性质表述为一组谓词, 这些谓词在修复区域上对神经网络的输出施加约束, 同时将神经网络修复问题定义为一个混合整数二次规划, 以根据给定的谓词调整单层神经网络的权重, 同时最小化原始训练区域上的原始损失函数. 此外, 由于输出层不包含非线性激活函数, 因此对神经网络的输出层应用修复不会产生混合整数约束, 也就是说, 输出层的最小修复问题是一个更易求解的二次规划(quadratic program, QP)问题.
3.2.5 SR (self-repairing Transformer)[61]
自修复转换器是一个以给定一组分类性质和待修复神经网络N 作为输入, 产生一个新的神经网络N′ 的函数. 新产生的网络N′ 需要满足以下两个性质: 首先, 对于每个规约性质, 如果x 在性质的定义域内并且存在满足该性质的y , 那么N′(x) 也将满足该性质; 其次, 当且仅当x 不在性质域内或不存在满足性质的值时, N′(x) 将返回无效. 由于神经网络是由一系列网络层组成的, Leino等人[61]在原有网络添加了一个额外的网络层, 称为自我修复层(self-repair layer, SR-Layer). 自我修复层接收原始输入x 和原始神经网络的输出N(x) , 它或者返回无效(invalid, 输入不在性质区域内), 或者产生满足给定性质的输出(输入在性质区域内). 为了产生满足给定性质的输出, 如果输入x 在原始网络中满足规约性质, 那么自我修复层直接输出原始网络的输出N(x) , 否则自我修复层尝试找到一个在输出层上可满足的约束, 该约束是许多单一约束的不同组合, 使得x 对应的输出满足所有性质要求. 之后, 自我修复层检查创建的约束是否可满足, 如果单一约束都不能满足, 那么算法将判别原始网络无法被修复, 返回无效. 否则, 自我修复层根据前面得到的约束对输出进行排序, 选择最大程度保持原始网络输出的约束来完成网络修复. 图4展示了SR修复策略的简要流程.

图 4 SR神经网络修复策略流程
3.2.6 REASSURANCE[73]
与一般的神经网络权重修改策略不同, REASSURANCE修复方法在函数空间进行神经网络修复以满足被违背的网络性质. 如图5所示, 该方法针对ReLU神经网络修复提出了两个技巧: 补丁函数(patch function)和支撑网络(support network). 补丁函数是指为一个待修复的线性区域A寻找一个函数pA=cx+d 使得对于多面体区域A=aix⩽bi,i∈I 中的任意样本x , f(x)+pA(x) 满足规约性质. 其中f(x) 是原始神经网络的输出, 即N(x) . 为了避免求解过程中枚举多面体的顶点, 因此Fu等人[73]考虑了规约性质表达为网络输出限制在某个范围内的情况, 得到了更易求解的线性规划问题. 补丁函数可以保证指定的线性区域在修复后满足预期的性质, 但是, 补丁函数不能保证其他线性区域不受影响, 因此作者又提出了支撑网络来保证补丁函数几乎只在修复区域A 发挥作用. 区域A的支撑网络定义为
![]()
其中
![]()
是一个超参数, 表示修复的线性区域的限制程度(即, 它对周围线性区域的影响程度). 可以看到支撑网络在区域A 内成立, 离开区域A 后很快就会变为0. 综合补丁函数和支撑网络, 最终对神经网络的修复为
![]()
, 该修复方案包含了正反两个方向的激活功能, 以确保能够在正确的方向上修改神经网络.

图 5 REASSURANCE修复策略图示
3.2.7 RIPPLE (repair with linear programming concerning positive samples)[67]
基于线性规划, Sun等人[67]提出了一种神经网络分类器的修复策略, 通过修改深度神经网络的参数来提高分类器的准确率. 首先, RIPPLE通过采用线性规划中的约束条件和目标函数将深度神经网络修复问题编码为线性规划模型. 其次, 为了减小线性规划问题的求解复杂度, RIPPLE考虑通过只修改神经网络输出层的参数来高效地修复神经网络. 第三, 为了在不牺牲之前正确预测样本的精度的前提下提高之前错误预测样本的精度, RIPPLE在优化目标中采用了正确分类的样本和错误分类的样本, 来分别保证原有神经网络的性能保持和违背性质的改善.
3.2.8 ARNN (automated repair of neural networks)[68]
ARNN的目标是修复神经网络以保证网络安全性, 它利用形式化方法直接搜索模型参数, 而不是在验证和重训练方法之间迭代直到模型是安全的. ARNN提出了一个框架来自动和可证明地修复预训练的不安全的神经网络模型, 同时保持修复的函数表示与原始神经网络函数表示尽可能相似. 首先, ARNN使用传统算法在指定的任务上训练模型, 然后利用可满足性模理论[101]来形式化神经网络安全性修复问题, 并搜索模型满足所需安全性的正确参数. 与提供测试错误率界限的对抗性训练相反, ARNN框架产生了一个精确的安全的网络表示, 并且在某种意义上是通用的, 它可以执行任何一阶逻辑规范的可确定片段[102]. 此外, 除了展示如何利用现成的SMT求解器来自动修复不安全的神经网络, Cohen等人还提出了一些启发式方法来保持与原始网络的相似性, 并对这些启发式方法进行了比较.
3.2.9 APRNN (architecture-preserving provable repair of DNNs)[74]
虽然PRDNN可以提供理论可证明的修复, 但是如何将得到的解耦深度神经网络转换得到标准和等效的深度神经网络依然是一个开放的问题, 为此Tao等人[74]在后续工作APRNN中提出了一种保持神经网络结构的多面体可证明修复策略. 保持结构的神经网络修复只修改深度神经网络的参数, 而不修改网络结构. APRNN首先扩展了原来的如果将修复限制为只修改单层参数可以避免优化过程中出现二次项的观察结果[59], 即如果将修复限制为仅修改某些单层Nlk 中的权重, 但允许修改所有Nlj,j⩾k 中的偏置项, 则可以避免二次项. 虽然这个想法简单, 但允许修复更多的参数可以提高实际修复的质量. APRNN的第1个关键见解是找到一个隐含违背性质Pi 的线性公式Plin , 即任何满足Plin 赋值的都满足规约性质Pi . 第2个关键见解是如果神经网络对于多面体的值是局部线性的, 那么修复神经网络在多面体P 的顶点上的行为, 就足以保证其满足多面体P 内的无穷点集, 相当于将区域修复问题规约到点修复问题, 极大降低了求解问题的复杂性. 这也引出了APRNN的另一个贡献, 即可以修改神经网络的参数使得原有神经网络N 对于给定的多面体来说是局部线性的, 然后可以进一步修改参数来修复多面体顶点上的行为以实现区域修复. APRNN修复策略具有修改神经网络多层参数的灵活性, 并且在多项式时间内运行. 它支持具有一些线性部分的激活函数的神经网络, 以及全连接、卷积、池化和残差层等网络层.
3.2.10 无错误定位的微调修复策略的对比分析
表5从修复粒度、核心思想、修复指标和特点等4个方面对无错误定位的微调修复策略进行了对比和分析, 相较于重训练修复策略对整个神经网络参数的改变, 可以看到绝大部分无错误定位的修复策略都只改变了单层网络权重; 相较于中间层的权重修改, 神经网络输出层的权重修改可以极大降低求解复杂度; 大部分修复策略都将违背的网络性质编码成约束或者优化问题, 从而使得优化问题的可解性耦合了修复的可证明性, 或者利用神经网络验证器得到网络关于性质的验证结论.
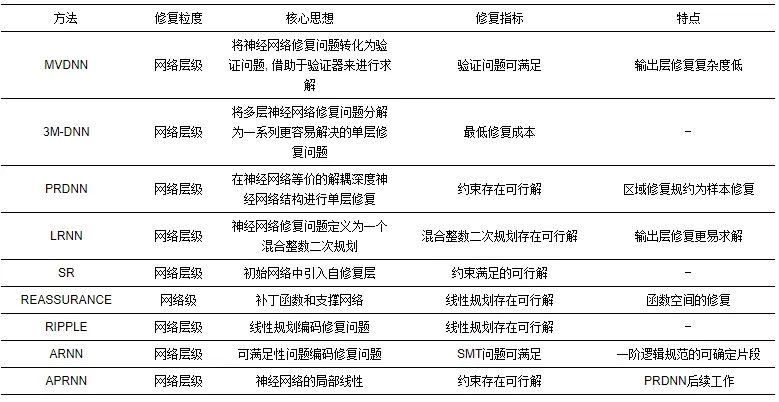
表 5 无错误定位的神经网络微调修复策略对比
3.3 包含错误定位的微调修复
错误定位策略的必要性在于神经网络中的参数数量通常是巨大的, 甚至相对较小的神经网络也可能由数千个权重和偏置参数组成, 试图优化所有的神经权重代价高昂, 并且难以扩展. 此外, 任意指定的修复层也缺乏目的性和针对性, 因此一些神经网络修复策略考虑了错误定位, 利用错误定位来确定对错误行为有更大影响的参数子集, 使微调修复过程更有倾向性和目的性.
3.3.1 DeepFault[103]
DeepFault是第1个错误定位的深度神经网络白盒测试方法. DeepFault的目标有两个: (1)识别可疑神经元, 即可能对不正确的神经网络行为负责的神经元; (2)合成新的输入来激活已识别的可疑神经元. 与传统软件工程的错误定位相比, DeepFault分析神经网络的神经元在训练后的行为, 以建立其命中谱(hit spectrum), 并通过使用可疑度量来识别可疑神经元(可能在深度神经网络性能(低精度/高损失)方面做出重大贡献的可疑神经元), 该度量使用频谱相关信息计算每个神经元的怀疑度分数. DeepFault实例化了3种可疑指标: Tarantula[104]、Ochiai[105]和D*[106]. 怀疑度分数越高的神经元更有可能被训练得不满意, 对错误的神经网络决策贡献更多, 因此这些神经元的权重需要进一步校准. DeepFault采用怀疑引导算法合成新的输入, 通过修改正确分类的输入来获得可疑神经元的高激活值, 涉及到对抗样本生成等领域, 不在本文讨论范围. 遗憾的是, DeepFault工作并没有进一步用来修复神经网络, 但Eniser等人[103]的初步探索却是神经网络错误定位的重要工作.
3.3.2 NREPAIR[62]
Dong等人[62]提出的NREPAIR修复策略的总体思路通过划分输入区域, 识别一个最小的违背规约性质的输入区域集合, 然后调整那些最应该为错误行为负责的神经元, 以便满足原始神经网络违背的规约性质. 一旦发现神经网络违反了某些约束性质, NREPAIR就会尝试为每个特定的违反性质的输入区域构建一个新的神经网络. 因此, NREPAIR的输出是一个原始网络和多个新构建的修复网络, 实际使用中, 它将根据输入落在哪个分区来决定采用哪个网络进行预测.
NREPAIR策略的修复框架如图6所示, 首先基于规约性质Pi 验证原始网络N , 如果N 满足规约性质Pi , 则直接返回原始神经网络. 否则, 它将检查输入区域是否可以进一步划分, 如果有进一步的划分可用, NREPAIR将把输入区域划分为两个互不重叠的区域, 并使用这两个新的输入区域重新开始验证过程, 直到输入区域不能被分割, 验证器生成一个反例(counterexample)提供给修复过程. 在修复过程中, 给定被违反的性质和反例样本, NREPAIR定义了一个损失函数, 然后通过修改神经元的输出来最小化反例的损失值. 接着, 根据所提供的反例和损失函数的值计算每个神经元的梯度并按梯度降序对每个神经元节点进行排序, 找到梯度最大且修改次数不超过允许次数的神经元. 确定了这些可疑神经元之后, NREPAIR将其输出修改为其原始输出减去该神经元的梯度和预定步长的乘积. 最后, 再次通过验证器运行新的神经网络来检验修复是否完成, 如果网络已经修复, 则返回新网络; 否则, 重复该过程直到找到一个解决方案或者超时.

图 6 NREPAIR神经网络修复框架图示
3.3.3 GenMuNN[76]
许多传统的程序修复方法是基于突变的, 如GenProg[107]在修复传统软件方面取得了很好的效果. 它通过模拟生物体的交叉突变产生新的程序突变体[108], 并选择适合度高的个体在下一轮突变, 直到所有测试用例都通过. 考虑到GenProg等基于突变的修复方法在传统程序修复中的成功应用, Wu等人[76]提出了一种基于突变的神经网络模型修复方法GenMuNN. 第1步是错误定位. 为了避免可能引入的错误行为, 他们采用了一种更加细粒度的错误定位方法, 即对神经元的缺陷权重进行定位, 得到一个影响神经网络模型精度的可疑权重递减序列. 为了得到可疑权重的降序, GenMuNN将测试数据输入到神经网络模型中, 并从输入层传播到输出层, 对于每个神经元, 将测试数据的输出按比例分配给每个权重作为覆盖信息. 然后根据覆盖信息计算权重的怀疑度, 并将权重排序, 可疑值越高的权重越有可能存在缺陷. 第2步是第1步产生的权重序列中的权重依次发生突变. 首先, 对于W 中的一个权重wi ,
![]()
为可疑权重所在神经元所有权重的平均权重(不包括wi��). 然后, 生成一组突变体
![]()
其中Mi,j 是将wi 更新为wi+ri,j 生成的,
![]()
中的随机值, a 是可调参数. 假设原模型的精度为p , 突变体的精度为pi,1,pi,2,… 如果pi,j−p>ε , 突变体Mi,j 将作为合格突变体保留, 否则, 突变体Mi,j 将作为不合格突变体被消除. 为了加速修复过程, 每轮突变只保留n 个合格的突变体. 对于合格的突变体, 准确率越高, 分配到下一轮突变的概率就越大. 最后, 如果连续s 轮没有产生符合条件的突变体, 则停止当前权重的突变, 选择W 中权重wi+1 进行下一轮突变. 当连续t 个权重没有产生合格的突变体时, 修复过程将停止, 整个修复过程如图7所示.

图 7 GenMuNN修复框架图示
3.3.4 NNrepair (neural network repair)[65]
直观地说, 神经网络输出层的修复更容易, 因为输出层的修复可以直接影响决策, 并且可以使用网络的预期输出作为约束来指导修复. 然而, 这种修复方法的泛化性较差, 而且网络可能在某些中间隐藏层出现故障. 中间层的修复可以对网络的行为产生更大的影响, 但由于不清楚使用何种约束或者启发式策略来指导修复, 因此更困难. NNrepair修复策略则提出了可以同时支持中间层和输出层修复的技术. 在这项工作中, Usman等人[65]提出使用神经元激活模式(activation pattern)[109]作为中间层修复的指导. 由于同时修复所有输出类非常困难, 因此NNrepair转而求解一组专家网络, 每个目标类一个, 将这些专家网络组合起来得到最终修复的分类器. 具体来说, NNrepair修复策略包含以下几个步骤: (1)错误定位: 这一步的目标是识别一组可疑神经元和输入边的可疑权重. (2)符号化执行(concolic execution)[110]: 在可疑边的权重上添加δ 值, 然后使用该网络沿正、负样本并行执行, 收集可疑神经元的符号表达式值. (3)约束求解: 由一组修复约束组合形成的符号表达式, 然后用已有的求解器进行求解. 本质上, 修复性质需要对正样本的网络决策进行编码, 并对负样本的网络决策进行修改. 对于最后一层修复, 这相当于添加决策层的约束. 对于中间层修复, 使用激活模式的约束将修复保持在网络层的局部. 从求解器中得到的符号δ 的解用于更新网络的权重, 从而获得特定类的专家网络. (4)专家组合: 将每个类得到的专家网络组合得到修复后的分类器. 这一步需要注意避免专家网络之间的冗余计算, 并且不损害分类网络的整体准确性.
3.3.5 Arachne[71]
Arachne是一个典型的基于搜索的包含错误定位的神经网络微调修复框架, 其修复策略主要包含两个环节: 错误定位和补丁生成. 在错误定位阶段, 针对一组给定的导致错误行为的输入样本, Arachne将识别一组可能与观察到的错误行为相关联的权重. 修改这些权重的值可能会影响模型的行为, 以期在正确的方向上修复神经网络. 定位策略根据损失函数和错误输入对权重梯度进行排序, 定位的目的在于识别对网络中错误行为负责的权重. 除了梯度损失之外, Arachne的错误定位过程还考虑每个权重对最终输出的影响程度, 定义为给定权重和前一层相应神经元输出的乘积. 而后, 综合权重梯度和影响程度, Arachne选择前k 个权重作为候选修复权重, 错误定位过程如图8所示. 在补丁生成阶段, Arachne则采用了差分演化算法(differential evolution, DE)[111]来生成候选权重更新值. 在差分演化优化算法中, Arachne使用适应度函数(fitness function)来评估每个候选解并指导搜索过程. 与其他G&V技术[112,113]一样, Arachne的适应度函数主要由两个部分组成: 修复错误分类和保留正确分类, 并且采用超参数在修复过程中平衡这两个部分.

图 8 Arachne修复框架错误定位策略图示
3.3.6 CARE (causality-based repair)[75]
近年来, 因果关系推断在可解释人工智能(explainable artificial intelligence, XAI)中得到了越来越多的关注, 研究者设计了多种基于因果关系的方法来解释机器学习模型中神经网络组件的决策过程[114,115]. 与传统方法相比, 因果方法确定了网络模型组成部分的原因和结果, 从而促进了对网络模型决策的推理和分析. CARE框架的目标是通过最小限度地调整给定神经网络的参数来构建满足性质的神经网络. 具体来说, Sun等人[75]提出了一种基于因果关系的神经网络修复技术, 主要包括两个步骤: (1)执行基于因果关系的错误定位和(2)优化识别神经元的参数以减少性质违背情况. 基于因果的定位策略识别了一组较少的需要对错误行为承担责任的神经元进行修复. 基于因果分析的错误定位策略不同于基于梯度的方法, 基于梯度的方法根据统计相关性得出结论, 可解释性较差. 识别到错误神经元之后, CARE采用粒子群优化算法(particle swarm optimization, PSO)[116]进行神经元参数更新. 粒子群算法模拟动物的智能集体行为, 如鱼群和鸟群, 是一种广泛使用的连续空间优化算法. PSO算法为在定位环节中识别的神经元的权重参数搜索小范围的调整, 以满足指定的性质且尽可能保持原有网络的性能, 完成网络修复.
3.3.7 NeuRecover[77]
采用重训练来修复神经网络的错误行为通常会对其他行为产生影响, 导致回归问题的产生, 即修复后的神经网络不能正确处理在原始神经网络上正确处理的输入. 为了解决这个问题, NeuRecover通过在错误定位步骤中使用训练历史来抑制回归问题的产生. NeuRecover的基本思想是, 通过对比历史模型和当前模型, 找到某一数据样本在训练历史中可以被模型正确分类而现在却被错误分类的检查点(checkpoint), 然后确定可以安全地纠正错误分类的权重. 具体来说, NeuRecover识别具有以下属性的权重: 它们的值在训练过程中发生了显著变化, 并且它们不影响改进数据的输出(即, 最初被错误分类但随后在训练过程中被正确分类的数据), 但影响回归数据的输出(即, 曾经被正确分类但随后在训练过程中被错误分类的数据). 然后, 通过对识别出的权重进行粒子群优化, NeuRecover可以修复神经网络模型, 得到更多的改进数据和更少的回归数据.
3.3.8 I-repair (repair using influence)[63]
因为原始训练数据的隐私性, 一些神经网络模型的原始训练数据并不公开, 基于这种情况, Henriksen等人[63]设计提出的I-repair修复策略考虑在不能访问原始训练集的情况下, 针对有限的分类样本集合修复神经网络的问题. 给定一个输入x 和一个待修复的神经网络N, I-repair首先估计每个参数在多大程度上影响输出N(x) , 主要思想是, 如果改变某个参数的值导致N(x) 发生剧烈变化, 则这个参数是一个“有影响”的参数. 如果一个参数对于待修复数据集DR 有很强的影响, 但是对于正确输入样本集合D 却影响较弱, 那么这个参数是一个很好的候选修复参数, 修改它的值可能使得网络决策发生预期的变化. 每个参数的影响力是基于给定的损失函数对参数的梯度来进行计算的. 一旦选择了一组参数进行修复, I-repair进行反向传播, 目的是修复DR 中的错误分类, 同时保持D 中输入的输出不变; 这个过程会重复进行, 直到所有输入都被修复或超时. 在此之后, I-repair算法报告在终止之前可以修复的输入和不能修复的输入.
3.3.9 BIRDNN (behavior-imitation based repair of DNNs)[72]
BIRDNN修复策略与其他较高层次的研究神经网络状态空间或者推理的神经网络修复方法不同, 该修复框架更加注重研究底层的神经元的行为, 并且基于神经元行为模仿(behavior imitation)修复神经网络. BIRDNN同时支持重训练和微调的神经网络修复范式. 对于基于重训练的修复方法, BIRDNN通过模仿附近正确样本的输出, 为错误样本分配新的正确标签, 然后重新训练原始神经网络以改善错误行为. 同时, 为了追求较小的网络修改, BIRDNN在训练过程中也考虑保持原有数据集的输入输出关系. 对于基于微调的方法, 错误定位通过分析正确样本和错误样本在具体神经元上的行为差异(behavior difference)来识别对错误预测最应该承担责任的神经元, 即行为差异最大的那些神经元. 然后, 和CARE策略类似, BIRDNN利用粒子群优化算法来修复这些错误神经元, 适应度函数的构造保证搜索过程在保持原始神经网络性能的同时最小化性质违背. 为了解决更有挑战性的神经网络区域修复问题, Liang等人[72]还在BIRDNN集成了蒙特卡罗采样技术从正确样本和错误样本两个方面来刻画神经网络的区域行为. 区域行为刻画技巧将区域修复问题转换为基于样本的修复问题, 以概率近似正确(probably approximate correct, PAC)的方法修复有缺陷的神经网络.
3.3.10 包含错误定位的神经网络修复策略的对比分析
表6从定位部分和修复部分两个方面对包含错误定位的神经网络修复策略进行了对比和分析, 定位部分主要比较核心思想、定位粒度和定位指标, 修复部分则是比较核心思想和修复指标. 可以看到, 与无错误定位的修复策略相比(表5), 包含错误定位的修复策略定位粒度更为细致, 主要是神经元级和权重级定位; 各个修复框架的定位策略基本都是启发式, 具有一定的可解释性. 对于神经元或者权重的修复, 主要算法集中在空间搜索上, 比如差分演化算法、粒子群优化算法等, 因而这些修复的可证明性较差, 但是修复效率和可扩展性高.

表 6 包含错误定位的微调修复策略对比
4 评价指标和测试基准
在本节, 笔者基于对已有工作的比较和分析, 介绍了深度神经网络修复策略常见的评价指标, 并基于第2节中对修复问题的分类方式, 从神经网络样本修复和神经网络区域修复两个方面列举了常见的测试基准和实验设置. 但是, 神经网络修复作为一个近几年逐渐兴起的研究领域, 目前在评价指标和测试基准上还没有形成较为统一的共识和规范, 这也是未来该领域需要进一步关注和发展的研究方向.
4.1 评价指标
和本文第2.3节列出的神经网络修复的要求相对应, 表7列出了神经网络修复策略常见的评价指标及其内涵解释, 主要包括性质提升、性能退化、准确度、参数距离、预测距离和运行时间. 需要说明的是, 这里只给出了常见评价指标的概念原型, 更为形式化的定义需要根据实验设置进一步规范和约束, 在已有工作中, 因为修复策略和实验设置的不同, 这些指标的计算方式也不尽相同. 此外, 部分评价指标之间存在意义重叠, 需要研究者在实际使用中综合考虑.

表 7 常见修复策略的评价指标及意义
4.2 基于样本的神经网络修复基准
本节主要介绍基于MNIST数据集的、基于Natural Adversarial Example数据集的和基于Census Income数据集的神经网络样本修复测试基准以及相应的神经网络修复的实验设置. 作为实验案例, 其他神经网络和数据集可以考虑采用类似的实验设置.
4.2.1 基于MNIST数据集的神经网络样本修复测试基准
MNIST数据集[117]由70k张分类标签为0,1,2,…,9 的手写数字的灰度图像组成, 其中60k为训练数据, 10k是测试数据. 基于MNIST训练数据集训练得到的神经网络(目前实验中采用的神经网络大部分都是作者自己构建并训练的前馈全连接神经网络, 且一般是较小规模的神经网络)通常在测试数据集上并不能取得100%的分类准确度, 因此可以考虑根据那些神经网络不能正确分类的样本来修复预训练的神经网络模型, 进一步提升预训练模型的准确性.
类似的基于数据集样本的神经网络修复还包括Fashion-MNIST (涵盖来自10种类别的不同商品的图片, 其大小、格式与原始的 MNIST 完全一致)[118], CIFAR-10 (包含10种类别的不同物品的彩色图像数据集)[119], CIFAR-100 (包含100类物品的图片数据集, 其大小、格式与CIFAR-10完全一致)[119], Labelled Faces in the Wild (LFW)(人脸识别数据集, 共有5749人的3233张人脸图像) [120]等数据集上的神经网络模型准确性的修复, 其中基于Fashion-MNIST和CIFAR-10数据集的修复一般针对于较小规模、较为简单的神经网络, 而基于CIFAR-100和LFW数据集的修复则一般在较大规模、较复杂结构的神经网络上进行.
4.2.2 基于Natural Adversarial Example数据集的神经网络样本修复测试基准
自然对抗样本(Natural Adversarial Example)数据集提供了7500个自然界中存在的可能被SqueezeNet神经网络错误分类的输入样本[121], SqueezeNet[122]是基于ImageNet数据集设计训练的卷积神经网络, 该网络一共有18层, 包含727626个参数. 相较于基于MNIST数据集的小型神经网络修复, 较大规模的SqueezeNet网络模型的修复更加具有挑战性. 自然对抗样本数据集中存在的错误分类样本表明SqueezeNet神经网络的分类准确性依然存在进一步被修复的必要, 即实验中需要修复的分类样本. 实验设计上, 可以针对自然对抗样本数据集中的全部错误分类样本进行修复, 也可以从中选择某些子集进行样本修复, 实验评估指标则是修复后的SqueezeNet网络在分类准确性上的提升.
4.2.3 基于Census Income数据集的神经网络样本修复测试基准
Census Income数据集[123]由包含13个特征的32561个数据实例组成, 用于预测个人年收入是否超过5万美元. 在所有属性中, 性别、年龄和种族是隐私特征, 标签是个人年收入是否超过5万美元, 其中隐私特征是指预期与标签预测独立的特征. 当某个样本实例在神经网络的预测与隐私特征不独立时, 则神经网络的公平性被破坏. 基于Census Income数据集的神经网络公平性修复旨在提升神经网络的公平性. 类似的基于数据集样本的神经网络公平性修复还包括基于German Credit数据集(1000个实例, 20个特征, 用于评估个人信用. 年龄和性别是隐私特征, 标签是个人信用是否良好)[124]和Bank Marketing数据集(45211个实例, 17个特征. 年龄是隐私特性, 标签是客户是否会认购定期存款)[125]的神经网络修复.
4.3 基于区域的神经网络修复基准
本节主要介绍基于MNIST数据集的神经网络区域修复、ACAS Xu神经网络区域修复和HorizontalCAS神经网络区域修复测试基准及相应的神经网络修复的实验设置. 作为实验案例, 其他神经网络和数据集可以考虑采用类似的实验设置.
4.3.1 基于MNIST数据集的神经网络区域修复测试基准
文献[126]考虑了在神经网络验证工作中广泛使用的一个神经网络, 该神经网络是基于MNIST手写数字数据集的以 ReLU作为激活函数, 由3个网络层和88010个参数组成的神经网络, 在MNIST测试集上的准确率为96.5%. 考虑构建如下一条线段, 该线段的一个端点是未损坏的MNIST手写数字图像, 另一个端点是来自MNIST-C数据集, 即被雾化损坏的MNIST图像[127]. 考虑该神经网络的一个鲁棒性性质规约, 即如果I 是未损坏的MNIST图像, I′ 是一个相应的雾化损坏图像, 那么从I 到I′ 这条线上的所有(无限)的输入样本必须具有与I 相同的分类. 对于此修复问题, 从I 到I′ 的线段是该神经网络的修复区域, 修复目标则在于使得修复后的神经网络满足鲁棒性规约.
4.3.2 ACAS Xu神经网络区域修复测试基准
ACAS Xu神经网络[128]的安全性修复是一个被广泛使用和评估的神经网络区域修复测试基准. ACAS Xu神经网络包含45个神经网络阵列(组织为5×9阵列, 即N1,1,N1,2,…,N1,9,…,N5,9), 用来生成机载避撞系统X的无人版本的机动建议, 机载避撞系统X是由美国联邦航空管理局设计开发的高度安全攸关的系统. 更具体地说, 这些深度神经网络采用5维输入, 代表航天器周围的场景(航天器的速度, 与入侵器的距离等), 并输出5维的预测结果, 指示5种可能的操作建议(clear-of-conflict, weak left, weak right, strong left或者strong right). ACAS Xu神经网络以每个离散化的状态作为输入, 网络使用全连接神经网络, 采用ReLU作为激活函数, 有6个隐藏层. 为了更好地描述ACAS Xu 神经网络的实际运行需求, 研究者提出了10个与之相关联的安全性质(P1,P2,…,P10 ). 这些安全性规约要求与特定输入区域内的输入相对应的输出必须落在给定的安全的多面体区域中. 现有的一些神经网络验证工具[27]已经证实这45个神经网络模型中, 有35个神经网络违反了至少一个安全性质, 例如神经网络N2,9 违反了安全性质P8 . ACAS Xu神经网络修复是目前广泛使用的神经网络修复的比较基准. 但是, 需要注意的是, ACAS Xu神经网络的原始训练数据集并不公开, 这也为网络修复带来了一定的困难, 目前主要是通过采样神经网络的输入输出序偶来近似模拟原始训练数据.
4.3.3 HorizontalCAS神经网络区域修复测试基准
HorizontalCAS (HCAS)神经网络[129]是ACAS Xu神经网络的简化版本, HCAS神经网络是Julian等人提出的神经网络阵列, 共包含40个神经网络模型, 每个模型包含3个节点的输入层, 5个隐藏层, 每个隐藏层有25个节点, 最后有5个节点的输出层. 与ACAS Xu同时进行垂直速度和水平转弯速度建议不同, HCAS只发布航天器的水平转弯速度建议. 可以采用ACAS Xu神经网络的安全性质进行验证和修复, 例如基于安全性质P5 修复神经网络N1,4 [71]. 此外, VerticalCAS (VCAS)神经网络阵列[129]发布航天器的垂直速度建议, 是ACAS Xu神经网络的另一简化版本, 也可以考虑类似的实验设计进行神经网络修复.
5 未来研究方向
本文主要从重训练、无错误定位的微调修复和包含错误定位的微调修复3个方面介绍了深度神经网络修复策略的最新研究进展, 并比较和分析了不同修复策略之间的异同与联系. 通过分析比较, 目前学术界对于神经网络修复问题的研究已经逐渐形成体系, 在不同种类的神经网络和不同类型的神经网络性质的修复上取得了优异的表现. 但是随着深度学习与人类社会的不断融合, 对神经网络修复带来挑战的同时也将提出更高的要求, 神经网络修复策略领域仍需进一步发展与完善. 展望神经网络修复策略领域的后续发展, 笔者总结得到以下几个未来可行的或者需要关注的研究方向.
5.1 从启发式经验修复到理论可证明修复
虽然目前已有的神经网络修复策略在多个测试基准上取得了出色的表现, 但是大部分的修复工作依然是经验性修复, 即是面向神经网络模型的启发式修复, 缺乏足够的理论支撑和修复保证. 目前只有少数的修复方法是理论可证明的修复, 而这些方法对修复的神经网络种类有较高的要求, 同时可扩展性也存在较大局限, 因而实际应用中受到较大的限制. 因此未来需要进一步发展理论可证明的神经网络修复策略, 扩展理论可证明的修复方法的应用范围; 也可以考虑采用神经网络验证或者测试工具作为后端为神经网络修复策略提供性能佐证.
5.2 权重级细粒度定位和修复
目前大部分的修复策略是网络级、网络层级或者神经元级的神经网络权重修复. 以神经元级的权重定位和修复为例, 定位到一个神经元通常意味着可能更改所有与之相关联的权重, 更不要说网络级和网络层级的权重修复可能更改整个原有网络或者某一层的所有权重. 从这一点来看, 这3种粒度的定位和修复依然是比较粗粒度的, 可以考虑进一步将错误定位和修复细化到权重级, 这是比较具有挑战性的工作, 因为即便是小规模的神经网络也包含大量的网络参数, 而且权重的定位又往往和神经元的状态密切相关. 权重级的定位和修复应当在之后的工作中予以重点关注和发展, 可以进一步满足神经网络修复的最小性和局部性, 也能够更大程度地避免引入新的不必要的错误行为.
5.3 可能引入的错误行为的评估
在神经网络模型的修复中, 极小的修改都可能会引入不必要的错误行为已是学界的共识, 但是目前的研究进展中对这些可能新引入的错误行为的识别和评估还没有形成规范. 大部分的修复策略都是通过追求修复的最小性和局部性来最小化可能引入的错误行为. 另外, 大部分修复策略的核心思想是待修复权重在样本集合上的拟合近似, 过拟合风险的存在会进一步加剧可能引入错误行为的情况. 这也是未来研究中需要进一步推动发展的方向, 在理论可证明的修复基础上明确神经网络修复策略所产生的副作用.
5.4 集成化的修复策略的测试基准平台
相较于神经网络验证成熟的、集成化的比较和测试平台ERAN[126]、Marabou[30]、GPUPoly[26]、PRODeep[130]等, 神经网络修复策略方面的工作依然是欠缺和有待发展的. 一个标准化的测试和比较平台将会更加有助于该领域的快速发展. 现在已有的神经网络修复策略的集成化测试平台AIREPAIR[131]和NeVer 2.0[132]只实现了少数的神经网络修复框架. 此外, 在实现更为集成化的修复策略测试基准平台的同时, 研究者需要对神经网络修复策略领域的相关问题进一步明确和规范.
5.5 神经网络智能系统的修复
相较于深度神经网络的修复, 神经网络智能系统的修复(以神经网络作为主要决策部件的系统)显得更为重要, 也更加具有实际应用前景, 比如自动驾驶系统等. 与基于输入样本或者区域的神经网络修复不同, 神经网络智能系统的实际运行环境对其修复设置了更多的困难和挑战, 比如气候、天气、温度、人为因素甚至一些突发因素等. Yu等人[133]提出的DeepRepair和Majd等人[134]的工作做了这个方面的一些探索, 但是目前修复的神经网络系统的规模依然较小, 修复算法的可扩展性需要进一步提升. 很多神经网络智能系统的修复需求是实时的, 这也意味着更加高效的修复算法. 此外, 理想情况下神经网络习得的信息对于实际神经网络智能系统的预测可能产生过拟合数据, 如何找到一个切合实际场景的子集来修复训练集, 使得神经网络可以忘记那些不相关或不重要的历史信息, 从而提高模型的泛化能力和预测准确率也是需要进一步研究的课题[135].
6 结 语
深度神经网络修复的相关研究正处于刚刚兴起并快速发展的阶段, 随着神经网络智能系统在社会生活中日益广泛的应用和部署, 神经网络模型的修复也将更加紧迫和重要. 虽然目前神经网络的修复已经逐渐形成体系, 但是已有的修复框架大多为面向模型的启发式修复, 少数的可证明修复策略停留在一般(中等)规模的神经网络和较为简单的网络性质, 求解规模上依然受限. 同时, 对于神经网络修复过程可能引入的新的错误行为的识别和评价目前没有形成规范和共识, 集成化的神经网络修复的基准测试平台也是匮乏的. 本文调研比较了近几年神经网络修复的相关文章, 梳理了神经网络修复的国内外研究现状, 比较了不同神经网络修复策略的内在联系和区别. 最后, 文章讨论了神经网络修复目前常见的评价指标和测试基准, 展望了神经网络修复领域未来可能的研究方向, 期望进一步推动神经网络修复领域的研究和发展.
声明:公众号转载的文章及图片出于非商业性的教育和科研目的供大家参考和探讨,并不意味着支持其观点或证实其内容的真实性。版权归原作者所有,如转载稿涉及版权等问题,请立即联系我们删除。
注:若出现无法显示完全的情况,可 V 搜索“人工智能技术与咨询”查看完整文章