票据识别 - 自动化业务的守门员
发票、票据识别,是OCR技术和RPA、CMS系统结合的一个典型场景,从覆盖率、覆盖面的角度来说,应该也是结合得最成功的场景之一。
产品简介
国内通用票据识别V2.0(简称“多票识别2.0”)是一款凝聚了合合信息17年OCR技术积累的产品。目前,其1.0版本SaaS服务年调用次数已突破千万大关。
更新亮点
多票识别2.0支持17大类、26小类票面识别,能够实现智能分类与精准结构化提取。无论是主流图片格式、多页PDF还是多页OFD格式,多票识别2.0都能轻松应对。
一一化解传统票据识别产品的痛点
- 难以试用
- 传统OCR服务中,支持私有化服务的产品往往无法在线试用,而能在线试用的产品又难以原样部署到本地。这导致在项目或业务中的不同阶段,验证OCR服务的性能和能力边界变得困难。
- 采用多端同步引擎架构,确保在线SaaS服务版本与私有化版本的引擎一致性,保障两者提供几乎一致的识别率和性能表现,让在线验证、线下部署成为可能。同时,SaaS版本和私有化版本还可以简单构成混合云架构,提供灵活的补位选择,满足复杂应用需求。
- 分类困难
- 票据识别OCR多用于报销或审核场景,但具体票据类别难以预测。传统逐票据分类方法通常针对某一票面提供单一的API接口,在高吞吐量、多票面场景下难以应对。
- 多票识别2.0经过深度优化,提供单接口调用服务,自动分类票种并返回识别结果,大幅简化用户的集成难度。用户不必过度考量业务场景,只需交给多票识别2.0,即可便捷享受高效服务。
- 显存膨胀
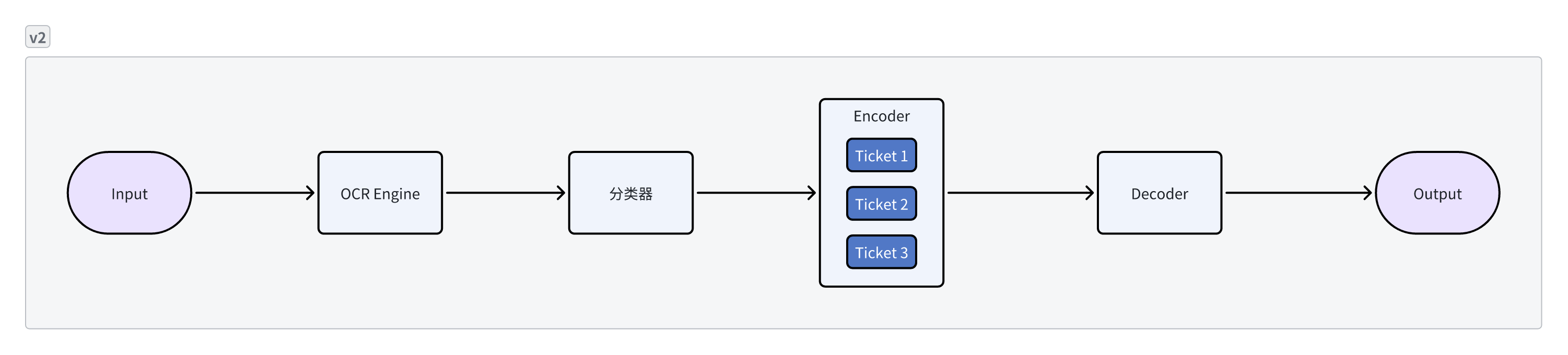
- 传统票据识别引擎通常采用单一票据结合单一模型的结构,基于此框架的票据识别产品开发、维护相对简单,但当用户需要一次性识别多个票据类型时,同时启动多个模型所需的显存资源将会线性叠加
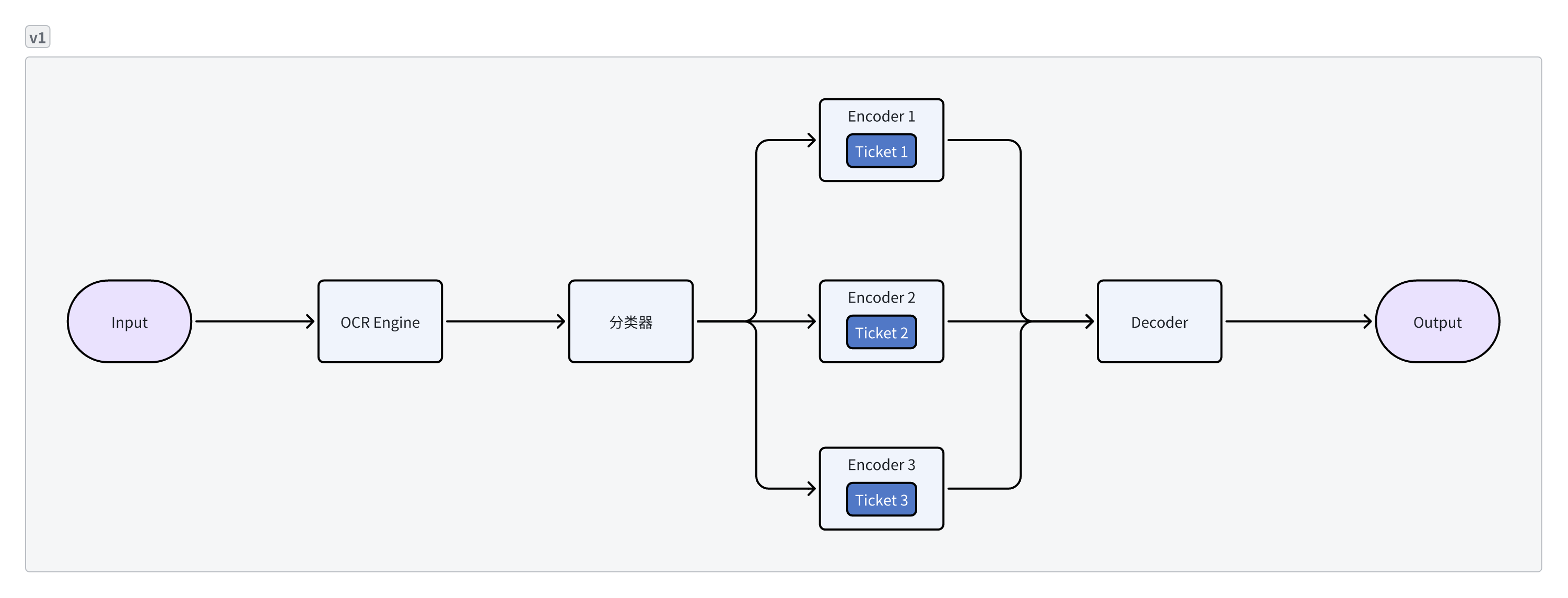
- 2.0版本使用统一主干网络结构,将多种不同票据场景统一编码并提取信息,送入票据专属的轻量级解码模块。此外,面向票据中常见的表格抽取需求,2.0版本使用统一的关系模块处理不同票据场景。相比于1.0版本,票据场景的扩增对于显存资源的需求下降两个数量级。
- 识别率受限
- 传统OCR票据识别一般采用规则抽取方案,先对所有字符进行识别,然后基于特定规则,匹配字符串内容,映射Key和Value。规则抽取方案在研发初期需要投入的算法工作量较低,但高度依赖预设的规则来识别和解析票据上的信息。这意味着系统必须事先知道所有可能的票据格式和内容布局,这在实际应用中往往难以实现,因为票据的格式可能会有细微的变化或定制化设计。每当票据格式发生变化时,都需要人工重新设计和调整识别规则,这不仅耗时而且成本高昂。对于一些频繁更新格式的票据,这种依赖性会导致系统维护困难。并且,由于规则是针对特定情况设计的,当遇到新的或未预见的票据格式时,系统可能无法正确识别,导致识别率下降。
- 更新后的票据识别2.0采用模型抽取方案,规避了人工设计规则对于一些排版变化的样例适配性差的问题。由于模型是通过大量数据训练得到的,它能够更好地泛化到未见过的票据样本上,提高识别的准确性和鲁棒性。模型抽取方案可以集成自动化的分类、回流和再训练流程。这意味着系统可以自动从错误中学习并优化自身,不断提高识别性能。并且,相比于传统OCR,模型抽取方案减少了对人工设计规则的依赖,从而降低了系统更新和维护的工作量。
新增票面
新增医疗发票识别,助力医保报销流程自动化
在各类报销场景中,医疗费用报销占据了相当高的比例。根据国家卫生健康委数据,中国医疗卫生机构每年总诊疗人次超过84.2亿次,医院次均门诊费用约342.7元,每年产生8.48万亿卫生医疗费用。
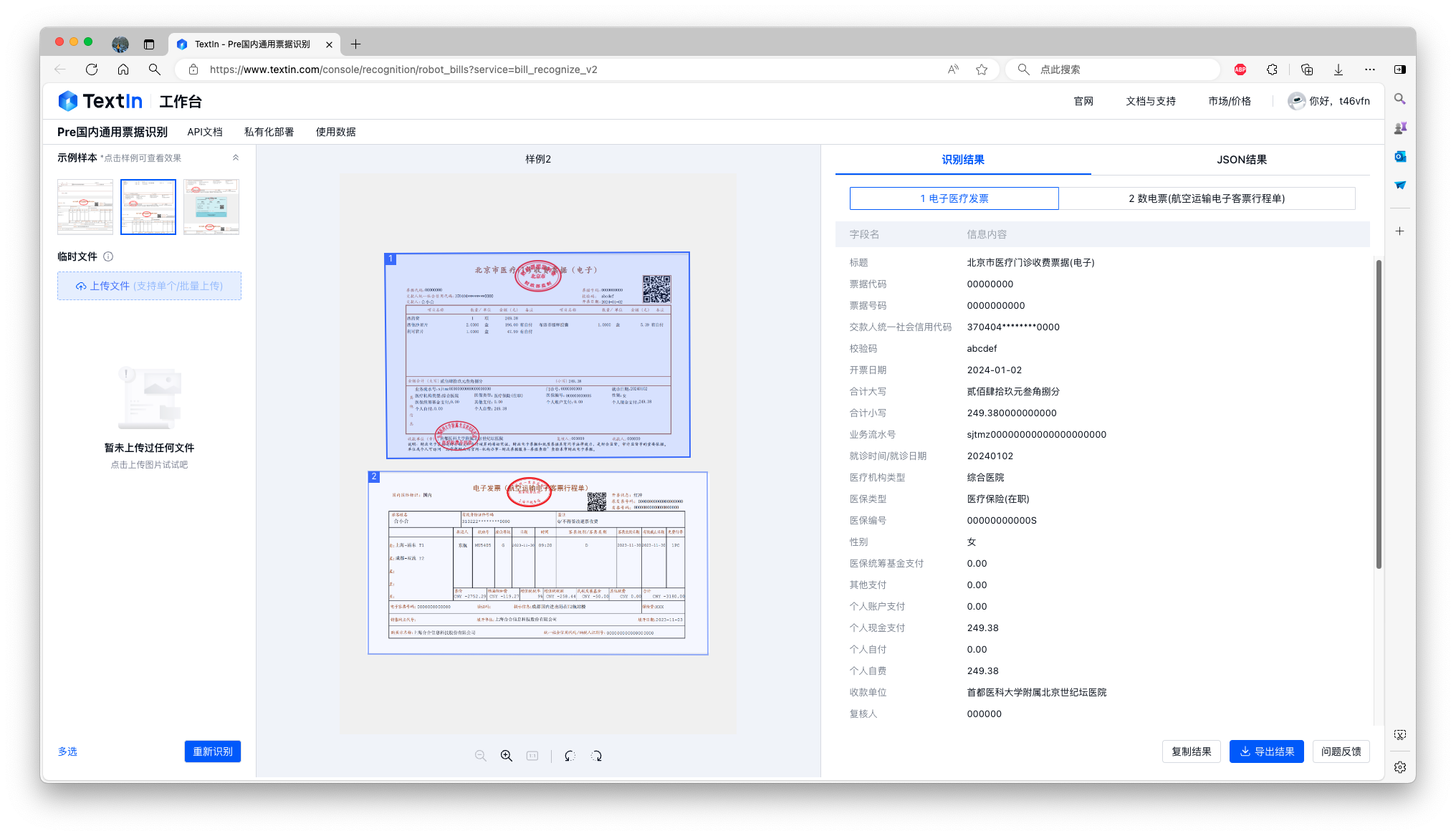
医保的报销不仅关乎医院与国家相关机构,也和商业保险公司、各企业的财务部门密切相关。多票识别2.0新增了电子医疗发票、纸质门诊发票、纸质住院发票的识别,助力报销流程自动化,实现:
- 提高效率:快速准确地从医疗发票中提取信息,减少人工输入工作量,显著提高处理速度。
- 减少错误:减少因人工输入错误导致的审核错误,提高审核准确性。
- 自动化流程:可与现有财务和保险系统整合,实现从发票识别到报销流程的自动化,减少人工干预。
- 节约成本:通过自动化处理,减少对人力资源的依赖,降低运营成本。
- 改善客户体验:通过顺畅的报销流程提升客户满意度,增强客户对保险机构或公司的信任。
- 对于异地就医,多票识别2.0使发票实现线上流转,无需物理传输,加快报销速度。
- 环境友好:减少纸质发票使用,有助于实现绿色办公,符合可持续发展理念。
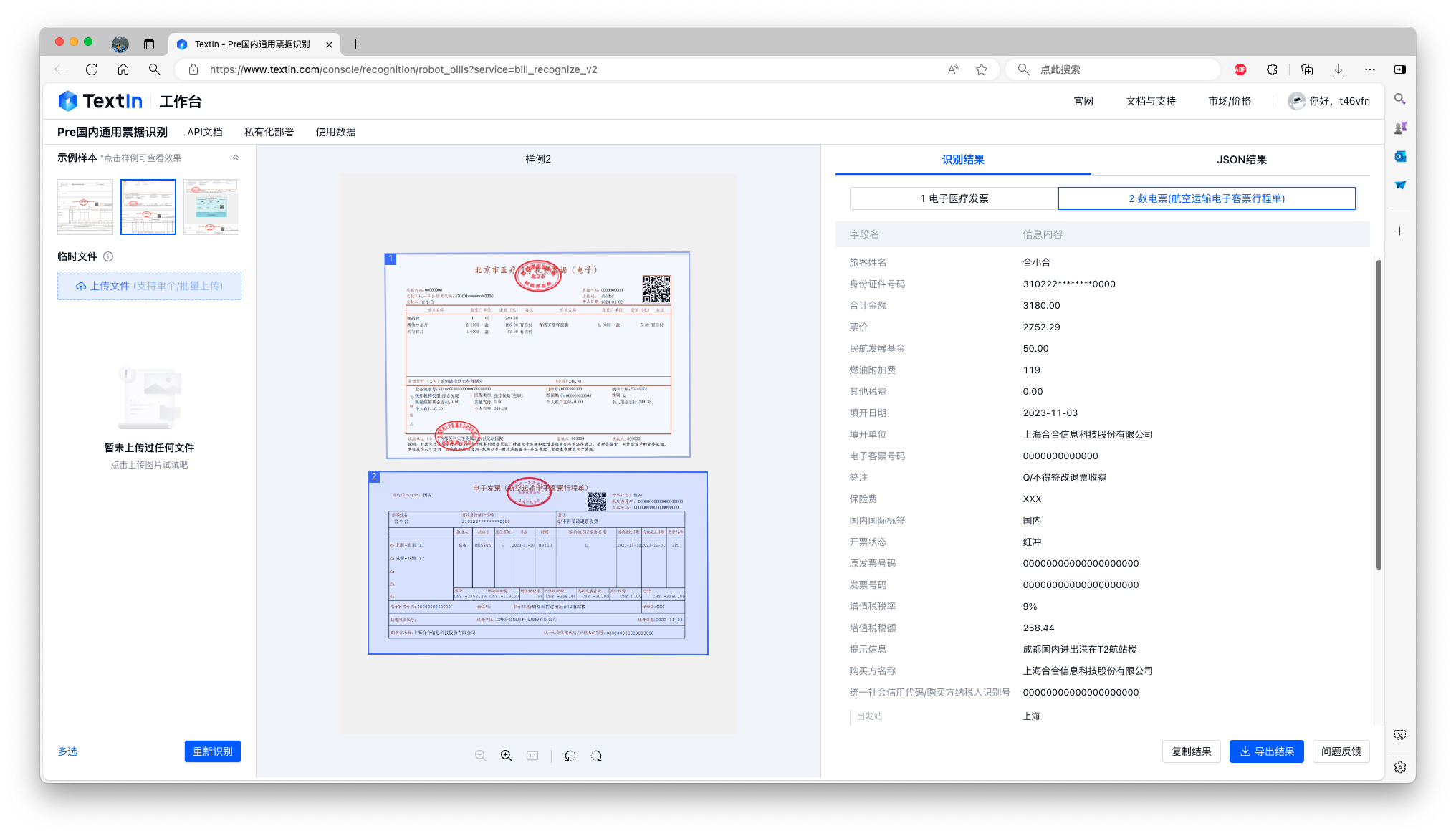
新增电子发票(数电票)识别,贴合票务系统发展
全面数字化的电子发票(数电票)是与纸质发票具有同等法律效力的新型发票。2022年,国票信息发票通企业数字化税务协同管理平台全新升级数电票功能。2023年12月,数电票试点覆盖到西藏,彻底覆盖全部省/直辖市。
乐企系统(数电票管理平台)接入需满足“上一年度营业收入合计5000万元以上”、“发起接入请求月度前12个月累计发票开票量及受票量合计不低于5万份”等要求,对于中国5200万中小微企业来说存在一定的门槛。因此,数电票的物理票据或截图票面识别能力在相当长时间内仍是刚需。
多票识别2.0此次更新覆盖了火车票、飞机行程单、增值税发票三个常见票种的数电票,后续将持续扩大支持范围,为中小微企业的数字化、自动化转型提供有力支持。
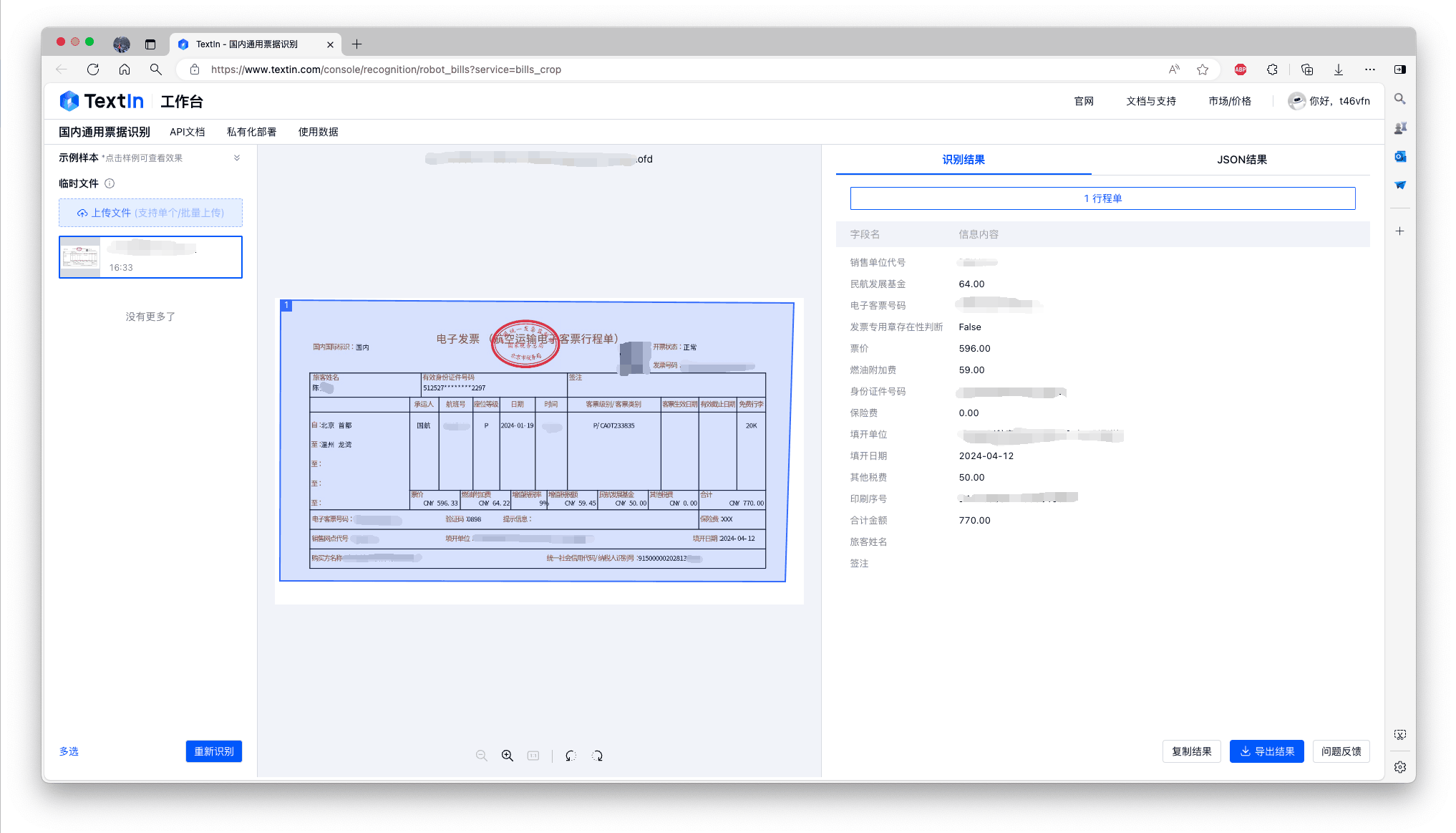
扩展OFD版式兼容范围,全票种支持多页OFD输入
OFD格式作为我国电子学会牵头制定的国家标准,于2009年首次发布,2020年被指定为“增值税电子普通发票”标准文件格式,适用于政府、金融、教育等领域。多票识别2.0在继续支持全票种OFD格式的基础上,额外增加了多页OFD识别能力,为有强自动化、批处理需求的用户提供更好的体验,进一步提升效率。
票据识别 - 自动化业务的守门员
产品特点
- 低成本:SaaS服务单次调用低至0.025元,新用户享受100次免费调用,支持Web前端使用,降低试用门槛。
- 高精度:基于合合信息自研OCR引擎,清晰有效样本识别准确率超95%。
- 高效率:单次识别速度<2秒,私有化版本采用全新模型架构,资源占用稳定。
- 强兼容:支持多种图像格式、多页PDF和OFD输入,集成智能切边技术,支持单页多票据识别。
- 简易集成:标准化API接口,支持智能分类,无需手动指定。
- 灵活部署:支持私有化、公有云部署,提供前端识别预览和标准化JSON结果。
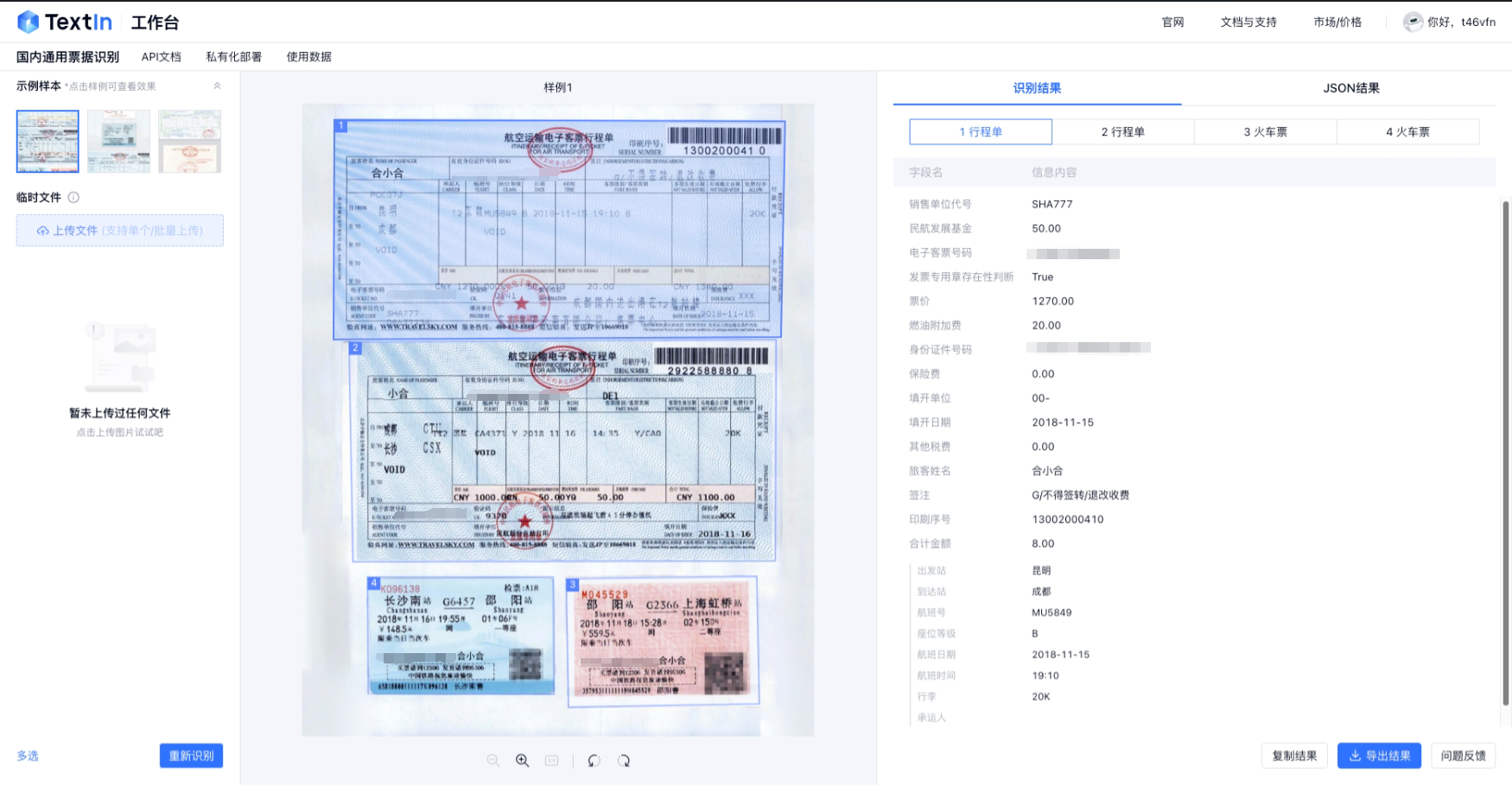
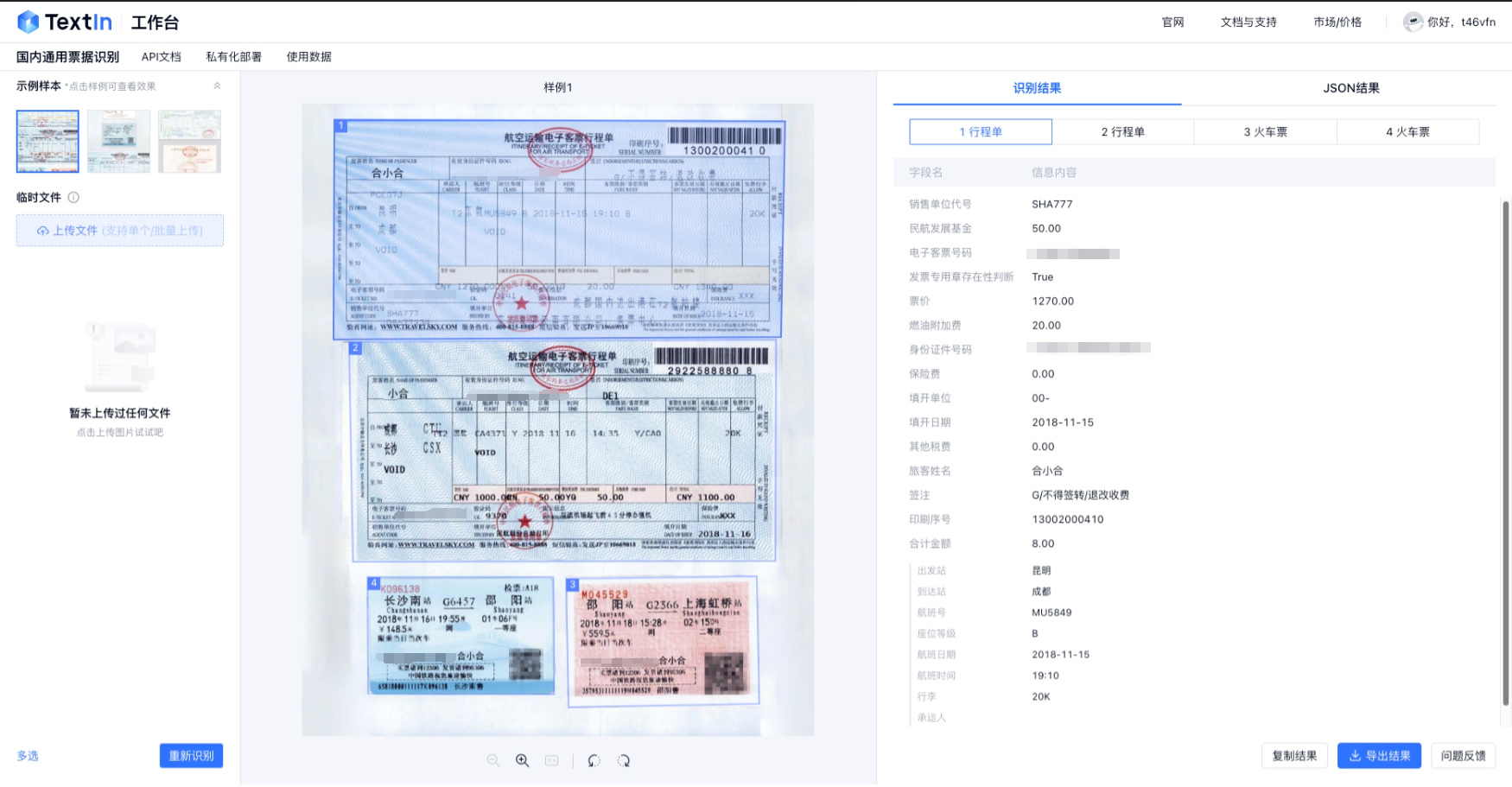
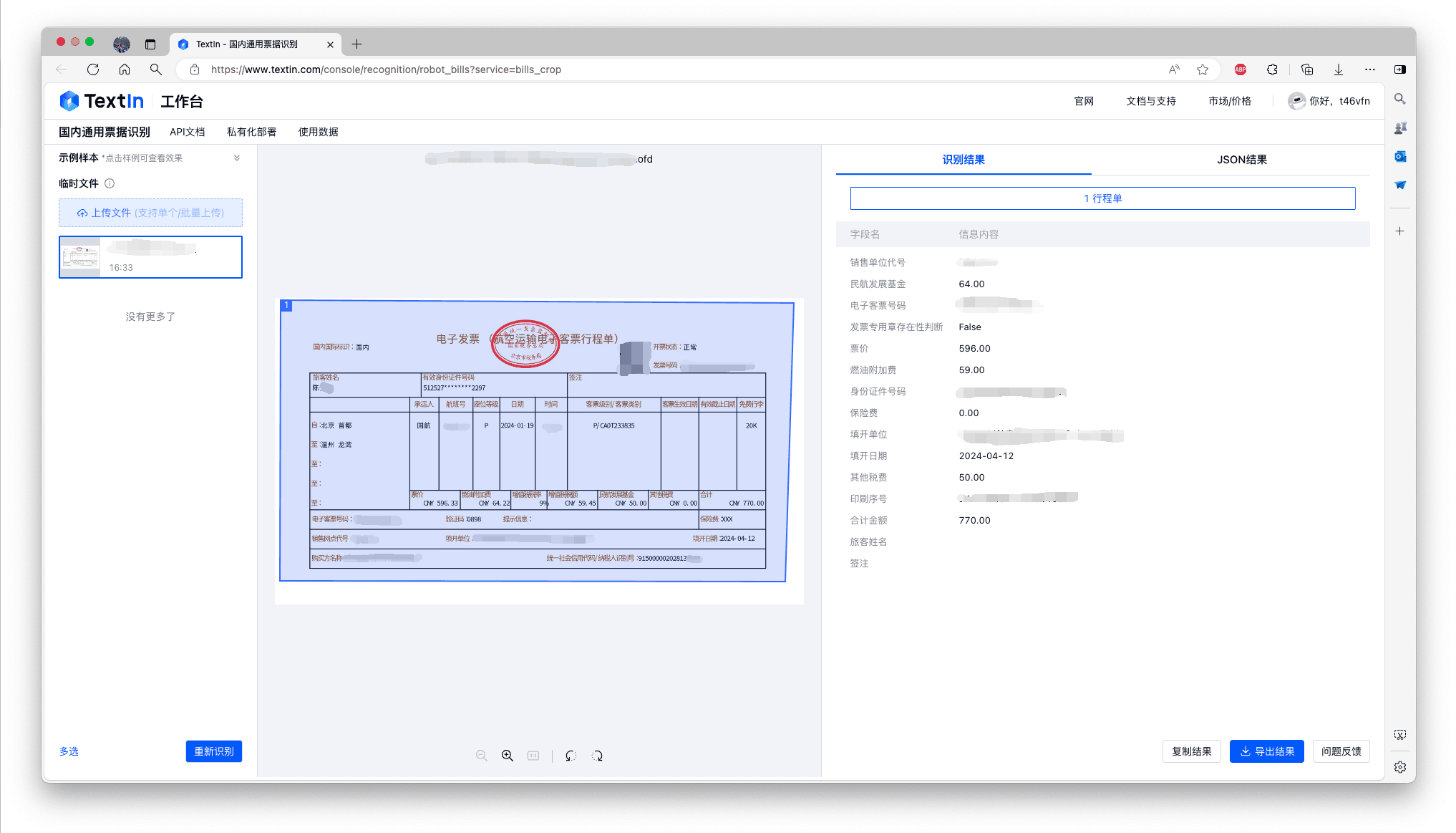
功能演示
- Web前端直接调用,便于试用、体验
- 多票混贴能够清晰区分,精准识别、定位到票面,也可以便捷地切换识别结果展示
- OFD格式同样支持识别
业务场景
- 保险理赔快人一步:
- 在保险行业中,OCR技术广泛应用于保单信息提取、理赔资料审核等领域。通过OCR技术,可以快速识别保单上的文字信息,提取关键信息,如投保人姓名、保险类型、保险金额等。
- 传统保险理赔流程中,由于对原始单据人工录入的依赖,周期通常需要几周到一个月不等,涉及多家保险公司混合理赔耗时更长。
- 通过多票识别2.0,无论业务流程是由用户端还是理赔公司发起,信息录入和校对的耗时都将大幅降低,提高业务吞吐量的同时显著优化用户体验,提高用户粘性。此外,更精准的大量票据数据也为保险机构提供了更全面的数据分析和挖掘基础,从而更好地了解客户需求,制定更精准的市场策略。
- 财务报销效率提升:
- 无论对于大型企业还是中小微企业,企业内报销业务对于财务部门都是一大重要任务。
- 传统的人工录入报销单据信息存在低效、易出错等问题,不仅降低员工工作积极性,还会导致一系列管理成本的上升。
- OCR识别技术可以自动高精度识别单据信息,减少人工干预,降低人力成本,提高了企业财务工作的整体运营效率,为更有附加价值的企业财务工作腾出时间和精力,进一步赋能企业效率升级。
即刻试用
目前,所有用户都可以拥有每日100次前端试用额度,注册用户更可以享受100次API接口或工作台批量调用,欢迎大家前来体验~!