在第 6 章中,我们大概了解了如何通过 JDBC 来进行简单的数据库操作。通过 SQL 来执行操作虽然不算复杂,但在面向对象的语言中,这类操作多少显得有些格格不入,毕竟我们都是在与“对象”打交道。把对象与关系型数据库关联起来,就有了我们要讨论的对象关系映射(Object-Relational Mapping,ORM)。而 Hibernate 和 MyBatis 是目前较为主流的两种 ORM 框架,本章主要介绍如何在项目中使用它们。
7.1 通过 Hibernate 操作数据库
如果我们希望用 Java 来开发一个 MVC 模型的应用,就一定离不开 SSH 组合。早期三个字母 SSH 分别代表了应用的核心框架 Spring Framework、开发 Web 功能的 Struts,以及开发数据层的 Hibernate ORM。随着时间的推移,Struts 慢慢淡出了人们的视野,Spring MVC 取代了这个 S 的位置,新的 SSH 变为 Spring Framework、Spring MVC 与 Hibernate。在这个组合中,Hibernate 的角色与地位一直没有发生过变化,因此,本章我们会先来了解一下 Hibernate。由于本书的主要对象是 Spring 而非 Hibernate,所以这里我们不会过多地深入讨论,对 Hibernate 感兴趣的同学,可以访问它的官网了解更多细节。
7.1.1 Hibernate 与 JPA
Hibernate 是一款基于 Java 语言的开源对象关系映射框架。所谓 对象关系映射,简单来说就是将面向对象的领域模型与关系型数据库中的表互相映射起来。对象关系映射很好地解决了对象与关系间的阻抗不匹配(impedance mismatch)问题。虽然有一些不太协调的地方,但两者之间还是可以相互融合的,表 7-1 简单进行了一些对比。
表 7-1 面向对象与关系型数据库的简单对比
| 对比维度 | 面向对象概念 | 关系型数据库 |
|---|---|---|
| 粒度 | 接口、类 | 表、视图 |
| 继承与多态 | 有 | 没有 |
| 唯一性 | a == b 或 a.equals(b) | 主键 |
| 关联关系 | 引用 | 外键 |
Hibernate 不仅将 Java 对象与数据表互相映射起来,还建立了 Java 数据类型到 SQL 数据类型的映射,提供了数据查询与操作的能力,能够自动根据操作来生成 SQL 调用。它将开发者从大量繁琐的数据层操作中释放了出来,提升了大家的开发效率。
说到 Hibernate 的历史,还得追溯到 2001 年。当时开发 Java EE(那时还叫 J2EE)应用程序需要使用 EJB,而澳大利亚程序员 Gavin King 对 EJB 中的实体 Bean 并无好感,于是他在 2001 年开发了 Hibernate 的第一个版本。后来随着 Spring Framework 创始人 Rod Johnson 的那本 Expert One-on- One J2EE Development without EJB 的出版,作为轻量级框架代表之一的 Hibernate 也逐步得到了大家的认可。
2006 年,Java 的持久化标准 JPA(Java Persistent API,Java 持久化 API)正式发布。它的目标就是屏蔽不同持久化 API 之间的差异,简化持久化代码的开发工作。当时的 JPA 标准基本就是以 Hibernate 作为蓝本来制定的,而 Gavin King 也当仁不让地在这个规范的专家组中。Hibernate 从 3.2 版本开始兼容 JPA。2010 年,Hibernate 3.5 成为了 JPA 2.0 的认证实现。表 7-2 对 Hibernate 与 JPA 的接口做了一个比较。
表 7-2 Hibernate 与 JPA 接口的对应关系与实现
| JPA 接口 | Hibernate 接口 | 实现类 | 作用 |
|---|---|---|---|
EntityManagerFactory | SessionFactory | SessionFactoryImpl | 管理领域模型与数据库的映射关系 |
EntityManager | Session | SessionImpl | 基本的工作单元,封装了连接与事务相关的内容 |
EntityTransaction | Transaction | TransactionImpl | 用来抽象底层的事务细节 |
虽然 SessionFactory 或 EntityManagerFactory 的创建成本比较高,好在它们是线程安全的。一般应用程序中只有一个实例,而且会在程序中共享。
Spring Framework 对 Hibernate 提供了比较好的支持,后来有了 Spring Data JPA 项目,更是提供了统一的 Repository 操作封装,开发者只需定义接口就能自动实现简单的操作。在后续的内容中,我们会了解到相关的使用方法。现在,第一步要做的就是在 pom.xml 的 <dependencies/> 中引入 Hibernate 与 JPA 相关的依赖。这一步通过 Spring Boot 的起步依赖就能做到:
<dependency> <groupId>org.springframework.boot</groupId><artifactId>spring-boot-starter-data-jpa</artifactId></dependency>
7.1.2 定义实体对象
在早期,开发者们都是通过 XML 来做各种配置的,其中也包括 Hibernate 的映射配置。但时至今日,大家早就习惯了使用注解来进行配置,甚至会“ 约定优于配置”(convention over configuration),追求“零”配置。在这一节中,我们只会涉及注解的配置方式,看看如何通过 JPA 的注解来进行常规的配置,其中还会结合少许 Hibernate 的特有注解。
-
实体及主键
既然是对象关系映射,那自然需要定义清楚“对象”与“关系”之间的关系。这层关系是由实体对象及其上添加的注解来承载的,表 7-3 中展示了用来定义实体及其主键的四个注解。
表 7-3 定义实体及其主键的注解
注解 作用 重点属性说明 @Entity标识类是实体类 name,默认为非限定类名,用在 HQL(Hibernate query language,Hibernate 查询语言)查询中标识实体@Table指定实体对应的数据表,不加的话默认将类名作为表名 name,默认是实体名;schema,默认是用户的默认 Schema@Id指定字段是实体的主键 @GeneratedValue指定主键的生成策略 strategy,指定生成策略,共有四种策略—TABLE、SEQUENCE、IDENTITY和AUTO;generator,指定生成器,用于TABLE和SEQUENCE这两种策略中
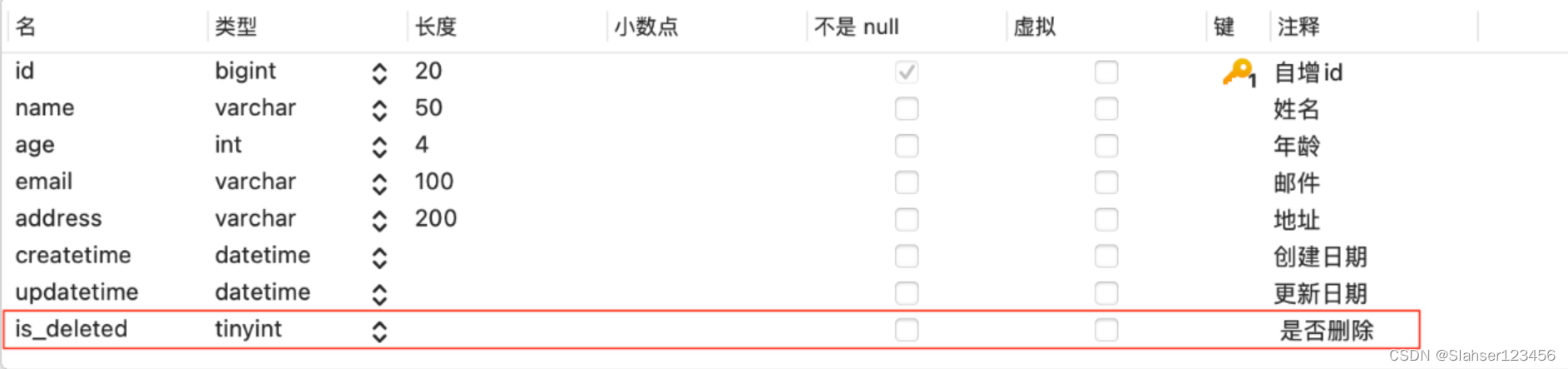
我们可以将之前的 MenuItem 类稍作修改,用 JPA 注解来进行标注,具体如代码示例 7-1 所示。类上共有六个注解,前四个注解都是 Lombok 的,用来减少模板化的代码,为类增加构建器、构造方法、 Getter 与 Setter 等方法; @Entity 说明这是一个实体类; @Table 指定该实体类对应的数据表是 t_menu。 id 上的注解表明了它是表的主键,并且是自动生成主键值的——通常像 MySQL 这样的数据库我们都会定义一个自增主键,默认策略就是 IDENTITY。
代码示例 7-1 增加了 JPA 注解的 MenuItem 类代码片段
@Builder@Data@AllArgsConstructor@NoArgsConstructor@Entity@Table(name = "t_menu")public class MenuItem {@Id@GeneratedValueprivate Long id;// 以下省略}
除了自增主键,还可以用 @SequenceGenerator 和 @TableGenerator 来指定基于序列和表生成主键。以 @SequenceGenerator 为例,假设我们有个序列 seq_menu,上面的 MenuItem 可以调整成代码示例 7-2 这样。至于 @TableGenerator,就留给大家查阅文档去了解吧。
代码示例 7-2 根据注解生成主键的 MenuItem 类片段
@Builder@Data@AllArgsConstructor@NoArgsConstructor@Entity@Table(name = "t_menu")public class MenuItem {@Id@GeneratedValue(strategy = GenerationType.SEQUENCE, generator = "sequence-generator")@SequenceGenerator(name = "sequence-generator", sequenceName = "seq_menu")private Long id;// 以下省略}
-
字段
在定义完实体和主键后,就该轮到各个字段了。表 7-4 罗列了一些字段相关的常用注解。
表 7-4 一些字段相关的常用注解
注解 作用 重点属性说明 @Basic映射简单类型,例如 Java 原子类型及其封装类、日期时间类型等,一般不用添加该注解,默认就有同样的效果 @Column描述字段信息 name,字段名称,默认同属性名;unique是否唯一;nullable是否可为null;insertable是否出现在INSERT语句中;updatable是否出现在UPDATE语句中@Enumerated映射枚举类型 value,映射方式,默认是ORDINAL,使用枚举的序号,也可以用STRING,使用枚举值@Type定义 Hibernate 的类型映射,这是 Hibernate 的注解 type,Hibernate 类型实现的全限定类名;parameters,类型所需的参数@Temporal映射日期与时间类型,适用于 java.util.Date和java.util.Calendarvalue,要映射的内容,DATE对应java.sql.Date,TIME对应java.sql.Time,TIMESTAMP对应java.sql.Timestamp@CreationTimestamp插入时传入当前时间,这是 Hibernate 的注解 @UpdateTimestamp更新时传入当前时间,这是 Hibernate 的注解 在了解了映射字段信息的注解后,我们再对
MenuItem类做进一步的调整,具体改动后的情况如代码示例 7-3 所示。
代码示例 7-3 新增的杯型 Size 枚举与修改后的 MenuItem 类
public enum Size {SMALL, MEDIUM, LARGE}@Builder@Data@AllArgsConstructor@NoArgsConstructor@Entity@Table(name = "t_menu")public class MenuItem {@Id@GeneratedValueprivate Long id;private String name;@Enumerated(EnumType.STRING)private Size size;@Type(type = "org.jadira.usertype.moneyandcurrency.joda.PersistentMoneyMinorAmount",parameters = {@org.hibernate.annotations.Parameter(name = "currencyCode", value = "CNY")})private Money price;@Column(updatable = false)@Temporal(TemporalType.TIMESTAMP)@CreationTimestampprivate Date createTime;@Temporal(TemporalType.TIMESTAMP)@UpdateTimestampprivate Date updateTime;}
上面的代码有几处具体的变动。
(1) size 从 String 类型改为了枚举。通过 @Enumerated(EnumType.STRING) 指明用枚举值来做映射,也就是说数据库里的值会是 SMALL、 MEDIUM 和 LARGE。
(2) price 从 BigDecimal 换成了 Joda-Money 库中的 Money 类型。通过 @Type 声明了如何将数据库中 Long 类型的值转换为 Money,这里用到了一个开源的转换类,如果数据库里存的是小数类型,可以考虑把 PersistentMoneyMinorAmount 替换为 PersistentMoneyAmount。
(3) createTime 标记为不可修改的,在创建时会填入当前时间戳。 @CreationTimestamp 是 Hibernate 的注解,在此处 @Temporal(TemporalType.TIMESTAMP) 其实是可以省略的。
(4) updateTime 会在每次修改时填入当前时间戳。 @UpdateTimestamp 是 Hibernate 的注解,在此处 @Temporal(TemporalType.TIMESTAMP) 也是可以省略的。
关于 Joda-Money 和对应的 Hibernate 类型 PersistentMoneyMinorAmount,两者均需要在 pom.xml 中加入下面两个依赖:
<dependency><groupId>org.joda</groupId><artifactId>joda-money</artifactId><version>1.0.1</version></dependency><dependency><groupId>org.jadira.usertype</groupId><artifactId>usertype.core</artifactId><version>6.0.1.GA</version></dependency>
usertype.core 里还有不少其他有用的类,实用性非常强。
茶歇时间:为什么一定要用
Money类来表示金额在处理金额时,千万不要想当然地使用
float或者double类型。原因是在遇到浮点数运算时,精度的丢失可能带来巨大的差异,甚至会造成资金损失。虽然BigDecimal在计算时能顺利过关,但金额的内容却不止是一个数值,还有与之关联的币种(ISO-4217)、单位等内容。以人民币为例,标准的币种简写是 CNY,最小单位(代码中用
Minor表示)是分,主要单位(代码中用Major表示)是元。美元、欧元、日元等货币都有各自的规范。在不同的货币之间,还有货币转换的需求。所以说,我们需要一个专门用来表示金额的类,而 Joda-Money 就是一个好的选择。举个例子,我们可以通过Money.ofMinor(CurrencyUnit.of("CNY"), 1234),创建代表人民币 12.34 元的对象,Money.of(CurrencyUnit.of("CNY"), 12.34)与之等价。
-
关联关系
我们在学习数据库的范式时,为了适当地降低冗余,提升操作效率,会去设计不同的表之间的关系。在做对象关系映射时,这种关系也需要体现出来。表 7-5 中罗列了常用的几种关系及其对应的注解。
表 7-5 常见关系及其对应的注解
关系 数据库的实现方式 注解 1:1 外键 @OneToOne1: n 外键 @OneToMany、@JoinColumn、@OrderByn:1 外键 @ManyToOne、@JoinColumnn: n 关联表 @ManyToMany、@JoinTable、@OrderBy为了方便大家理解这些注解的用法,我们结合二进制奶茶店的例子来看看。
需求描述 在二进制奶茶店中,我们会将顾客点单的信息记录在订单(即
Order)里。店内主要流转的信息就是订单,我们通过订单来驱动后续的工作。一个订单会有多个条目(即MenuItem),每个订单又会由一名调茶师(即TeaMaker)负责完成。它们之间的关系如图 7-1 所示,订单与调茶师是多对一关系,而订单与条目是多对多关系。
图 7-1 订单类与其他类的主要关联关系
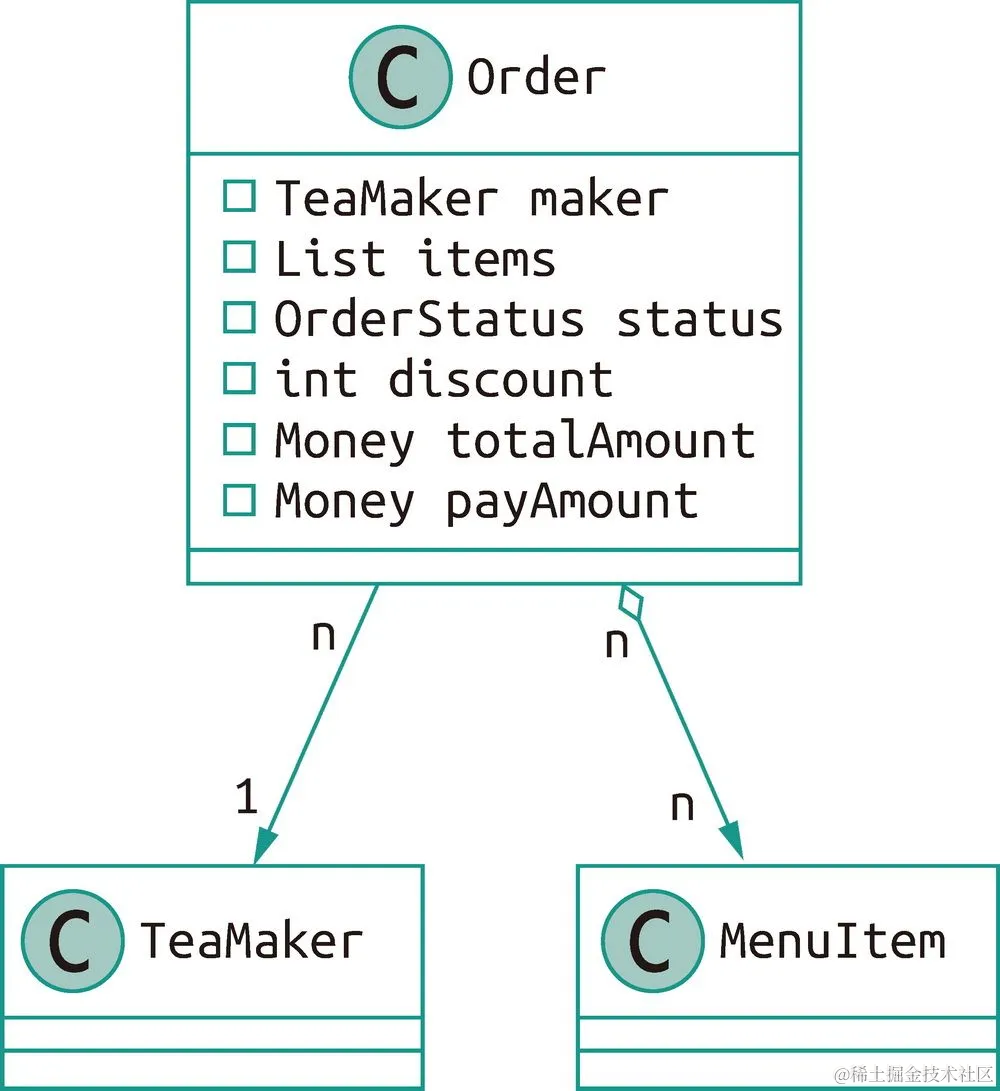
其中, TeaMaker 类的代码如代码示例 7-4 所示,大部分内容与 MenuItem 大同小异,但其中有一个一对多关系的 orders 属性需要特别说明一下。 orders 属性可以直接获取与当前调茶师关联的订单列表。 @OneToMany 的获取方式默认是懒加载,即在使用时才会加载, mappedBy 标明了根据 Order.maker 属性来进行映射。 @OrderBy 会对取得的结果进行排序,默认按主键排序,也可以指定多个字段,用逗号分隔,默认是升序(即 asc)。
代码示例 7-4 TeaMaker 的主要代码
@Builder@Getter@Setter@AllArgsConstructor@NoArgsConstructor@Entity@Table(name = "t_tea_maker")public class TeaMaker {@Id@GeneratedValueprivate Long id;private String name;@OneToMany(mappedBy = "maker")@OrderBy("id desc")private List<Order> orders = new ArrayList<>();@Column(updatable = false)@CreationTimestampprivate Date createTime;@UpdateTimestampprivate Date updateTime;}
接着,让我们来定义订单对象。每笔订单都有自己的状态,因此要先定义一个枚举来表示订单的状态机。 OrderStatus 中有五种状态,分别是已下单、已支付、制作中、已完成和已取货,实际情况中可能还有退款、取消等状态,在本例中就一切从简了。订单及其枚举的定义如代码示例 7-5 所示。
代码示例 7-5 订单对象及订单状态枚举
public enum OrderStatus {ORDERED, PAID, MAKING, FINISHED, TAKEN;}@Builder@Getter@Setter@AllArgsConstructor@NoArgsConstructor@Entity@Table(name = "t_order")public class Order {@Id@GeneratedValueprivate Long id;@ManyToOne(fetch = FetchType.LAZY)@JoinColumn(name = "maker_id")private TeaMaker maker;@ManyToMany@JoinTable(name = "t_order_item", joinColumns = @JoinColumn(name = "item_id"),inverseJoinColumns = @JoinColumn(name = "order_id"))@OrderByprivate List<MenuItem> items;@Embeddedprivate Amount amount;@Enumeratedprivate OrderStatus status;@Column(updatable = false)@CreationTimestampprivate Date createTime;@UpdateTimestampprivate Date updateTime;}
maker 指向了订单的调茶师,通过 @ManyToOne 指定了多对一的关系,这里的 fetch 默认是积极加载( EAGER)的,我们将其设定为了懒加载( LAZY)。 @JoinColumn 标明了数据表中记录映射关系的字段名称。 items 是订单中的具体内容,与 MenuItem 是多对多关系,二者通过关联表 t_order_item 进行关联,我们指定了表中用到的具体字段,还要求对 List 进行排序。
请注意 Lombok 的
@Data注解相当于添加了好多注解。其中之一是@ToString注解,即提供了更可读的toString()方法,输出的内容会包含成员变量的内容。为了避免toString()触发 Hibernate 加载那些懒加载的对象,在TeaMaker和Order上将@Data改为了@Getter和@Setter。
订单的金额信息被我们剥离到了单独的一个对象里,此时的 amount 就是一个嵌套对象,用 @Embedded 来加以说明。而在 Amount 对象上也需要加上 @Embeddable,说明它是可以被嵌套到其他实体中的。具体见代码示例 7-6,其中也用到了前面说到的金额类型转换器 PersistentMoneyMinorAmount。
代码示例 7-6 订单的金额信息
@Builder@Data@AllArgsConstructor@NoArgsConstructor@Embeddablepublic class Amount {@Column(name = "amount_discount")private int discount;@Column(name = "amount_total")@Type(type = "org.jadira.usertype.moneyandcurrency.joda.PersistentMoneyMinorAmount",parameters = {@org.hibernate.annotations.Parameter(name = "currencyCode", value = "CNY")})private Money totalAmount;@Column(name = "amount_pay")@Type(type = "org.jadira.usertype.moneyandcurrency.joda.PersistentMoneyMinorAmount",parameters = {@org.hibernate.annotations.Parameter(name = "currencyCode", value = "CNY")})private Money payAmount;}
茶歇时间:OpenSessionInView 问题
Hibernate 的懒加载机制有时就像一把双刃剑,虽然性能有所提升,但偶尔也会带来些麻烦,比如 OpenSessionInView 这个问题。
所谓 OpenSessionInView,是指 Hibernate 在加载时并未把数据加载上来就关闭了 Session,在要用到这些数据时,Hibernate 就会尝试使用之前的 Session,但此时 Session 已经关闭,所以会导致报错。这种情况在传统的 MVC 结构应用中会比较常见,OpenSessionInView 中的 View 指的就是 MVC 中的视图层,也就是视图层会尝试加载之前被延时加载的内容,随后报错。
Spring Framework 为我们提供了对应的解决方案:在 web.xml 中配置
OpenSessionInViewFilter,或者在 Spring 的 Web 上下文中配置OpenSessionInViewInterceptor,两者都可以实现在视图层处理结束后才关闭 Session 的效果。如果用的是 JPA,那 Spring Framework 中也有对应的
OpenEntityManagerInViewInterceptor拦截器可供开发者使用。
7.1.3 通过 Hibernate API 操作数据库
有了定义好的实体对象后,就可以通过对应的 API 来操作它们,从而实现对数据库的操作。但在使用前,我们需要先在 Spring 上下文中做一些简单的配置。由于 Hibernate 也是 JPA 的参考实现,两者有很多配置都是相似的,因而表 7-6 将 Hibernate 与 JPA 所需的配置放到一起来展示。
表 7-6 Hibernate 与 JPA 需要配置的内容
| 配置内容 | Hibernate | JPA |
|---|---|---|
| 会话工厂 | LocalSessionFactoryBean | LocalEntityManagerFactoryBean / LocalContainerEntityManagerFactoryBean |
| 事务管理器 | HibernateTransactionManager | JpaTransactionManager |
Spring Boot 的 HibernateJpaConfiguration 提供了一整套完整的自动配置。如果我们不想自己动手,可以把配置的工作交给 Spring Boot,只需要确保有一个明确的主 DataSource Bean 即可。代码示例 7-7 演示了如何手动配置 Hibernate 的相关 Bean, LocalSessionFactoryBean 中设置了要扫描的包路径,在这个路径中查找要映射的实体,除此之外,还设置了一些 Hibernate 的属性:
hibernate.hbm2ddl.auto,自动根据实体类生成 DDL 语句并执行。一般在生产环境中,数据库都是由 DBA 来运维的,不会用程序创建表结构,但开发者在开发时偶尔还是会用到这个功能。在本节的演示中我们就需要靠它来生成表结构;hibernate.show_sql,打印 Hibernate 具体执行的 SQL 语句;hibernate.format_sql,对要打印的 SQL 进行格式化。
Hibernate 有很多可以设置的属性,各位读者如果想要了解更多内容,可以查询 Hibernate 的官方文档。
代码示例 7-7 手动在主类中配置 Hibernate 相关 Bean
@SpringBootApplicationpublic class BinaryTeaApplication {public static void main(String[] args) {SpringApplication.run(BinaryTeaApplication.class, args);}@Beanpublic LocalSessionFactoryBean sessionFactory(DataSource dataSource) {Properties properties = new Properties();// 在H2内存数据库中生成对应表结构properties.setProperty("hibernate.hbm2ddl.auto", "create-drop");properties.setProperty("hibernate.show_sql", "true");properties.setProperty("hibernate.format_sql", "true");LocalSessionFactoryBean factoryBean = new LocalSessionFactoryBean();factoryBean.setDataSource(dataSource);factoryBean.setHibernateProperties(properties);factoryBean.setPackagesToScan("learning.spring.binarytea.model");return factoryBean;}@Beanpublic PlatformTransactionManager transactionManager(SessionFactory sessionFactory) {return new HibernateTransactionManager(sessionFactory);}}
在第 6 章中,我们介绍了 Spring Framework 为各种模板化的操作提供了模板类,事务操作有 TransactionTemplate,JDBC 操作有 JdbcTemplate,而 Hibernate 操作也有专门的 HibernateTemplate。为了方便使用,Spring Framework 还更进一步提供了一个 HibernateDaoSupport 辅助类。代码示例 7-8 和代码示例 7-9 演示了如何通过 Spring Framework 的辅助类进行增删改查操作。
代码示例 7-8 通过 Hibernate 重新实现 MenuRepository 的查询操作
@Repository@Transactionalpublic class MenuRepository extends HibernateDaoSupport {// 传入SessionFactorypublic MenuRepository(SessionFactory sessionFactory) {super.setSessionFactory(sessionFactory);}public long countMenuItems() {// 这里的是HQL,不是SQL语句return getSessionFactory().getCurrentSession().createQuery("select count(t) from MenuItem t", Long.class).getSingleResult();}public List<MenuItem> queryAllItems() {return getHibernateTemplate().loadAll(MenuItem.class);}public MenuItem queryForItem(Long id) {return getHibernateTemplate().get(MenuItem.class, id);}// 省略插入、修改、删除方法}
上面的代码演示了通过 getHibernateTemplate() 获取 HibernateTemplate 后进行的各种查询类操作,而 countMenuItems() 里则直接可以获取 Session(通过 HQL 语句进行操作)。我们在 MenuRepository 上添加了 @Transactional 注解,开启了事务。实践中我们一般会把事务加在 Service 层上,这里也只是为了演示,此外, getCurrentSession() 也需要运行在事务里。代码示例 7-9 是 MenuRepository 中的增加、修改和删除操作。
代码示例 7-9 通过 Hibernate 重新实现 MenuRepository 的增删改操作
@Repository@Transactionalpublic class MenuRepository extends HibernateDaoSupport {public void insertItem(MenuItem item) {getHibernateTemplate().save(item);}public void updateItem(MenuItem item) {getHibernateTemplate().update(item);}public void deleteItem(Long id) {MenuItem item = getHibernateTemplate().get(MenuItem.class, id);if (item != null) {getHibernateTemplate().delete(item);}}}
为了演示这个 MenuRepository 的使用效果,我们需要一个简单的单元测试,可以对 MenuRepositoryTest 稍作修改。代码示例 7-10 是对插入操作的测试。这个测试的逻辑大致是这样的:先通过 MenuRepository 来进行操作,随后再用 JdbcTemplate 执行 SQL 语句来验证执行的效果。 testInsertItem() 先插入了 3 条记录,通过 Lombok 生成的 Builder 来创建 MenuItem。在设置 price 时,我们演示了如何创建代表人民币 12 元的 Money 对象。明细核对的方法被单独放在了 assertItem() 里,以便后面的用例中能够复用。此处,与第 6 章的例子有一个区别,当时我们使用 schema.sql 和 data.sql 来初始化表结构和数据,这里为了保证测试数据不受外部影响,Spring Boot 的初始化,由 Hibernate 来实现表结构的初始化。
代码示例 7-10 MenuRepositoryTest 中针对插入操作的单元测试
@SpringBootTest(properties = {"spring.sql.init.mode=never", "spring.jpa.hibernate.ddl-auto=create-drop"})@TestMethodOrder(MethodOrderer.OrderAnnotation.class)class MenuRepositoryTest {@Autowiredprivate MenuRepository menuRepository;@Autowiredprivate DataSource dataSource;private JdbcTemplate jdbcTemplate;@BeforeEachpublic void setUp() {jdbcTemplate = new JdbcTemplate(dataSource);}@AfterEachpublic void tearDown() {jdbcTemplate = null;}@Test@Order(1)void testInsertItem() {List<MenuItem> items = Stream.of("Go橙汁", "Python气泡水", "JavaScript苏打水").map(n -> MenuItem.builder().name(n).size(Size.MEDIUM).price(Money.ofMinor(CurrencyUnit.of("CNY"), 1200)).build()).peek(m -> menuRepository.insertItem(m)).collect(Collectors.toList());for (int i = 0; i < 3; i++) {assertEquals(i + 1, items.get(i).getId());assertItem(i + 1L, items.get(i).getName());}}private void assertItem(Long id, String name) {Map<String, Object> result = jdbcTemplate.queryForMap("select * from t_menu where id = ?", id);assertEquals(name, result.get("name"));assertEquals(Size.MEDIUM.name(), result.get("size"));assertEquals(1200L, result.get("price"));}// 省略其他测试用例}
代码示例 7-11 是针对查询方法的相关测试,我们可以看到其中的核对大部分复用了 assertItem()。
代码示例 7-11 MenuRepositoryTest 中针对查询操作的单元测试
@SpringBootTest(properties = {"spring.sql.init.mode=never", "spring.jpa.hibernate.ddl-auto=create-drop"})@TestMethodOrder(MethodOrderer.OrderAnnotation.class)class MenuRepositoryTest {@Test@Order(2)void testCountMenuItems() {assertEquals(3, menuRepository.countMenuItems());}@Test@Order(3)void testQueryForItem() {MenuItem item = menuRepository.queryForItem(1L);assertNotNull(item);assertItem(1L, "Go橙汁");}@Test@Order(4)void testQueryAllItems() {List<MenuItem> items = menuRepository.queryAllItems();assertNotNull(items);assertFalse(items.isEmpty());assertEquals(3, items.size());}// 省略其他代码}
代码示例 7-12 是与修改和删除相关的测试用例: testUpdateItem() 中先查出了 ID 为 1 的菜单项,将其中的价格修改为了 11 元,更新回数据库后又用 jdbcTemplate 把记录查询出来进行了核对; testDeleteItem() 则比较简单,直接删除 ID 为 2 的记录,随后再通过查询操作来看一下数据在不在。
代码示例 7-12 MenuRepositoryTest 中针对修改和删除操作的单元测试
@SpringBootTest(properties = {"spring.sql.init.mode=never", "spring.jpa.hibernate.ddl-auto=create-drop"})@TestMethodOrder(MethodOrderer.OrderAnnotation.class)class MenuRepositoryTest {@Test@Order(5)void testUpdateItem() {MenuItem item = menuRepository.queryForItem(1L);item.setPrice(Money.ofMinor(CurrencyUnit.of("CNY"), 1100));menuRepository.updateItem(item);Long price = jdbcTemplate.queryForObject("select price from t_menu where id = 1", Long.class);assertEquals(1100L, price);}@Test@Order(6)void testDeleteItem() {menuRepository.deleteItem(2L);assertNull(menuRepository.queryForItem(2L));}// 省略其他代码}
需要注意两点:第一,这个测试必须按照指定的顺序执行,因为测试数据是通过 testInsertItem() 插入的;第二,这只是一个演示用的单元测试,在实际工作中,我们还要考虑各种边界条件。
Spring Framework 针对涉及数据库的操作还提供了专门的测试支持,可以在每个测试执行后回滚数据库中的各种修改,此处暂且通过简单的方式来做。更复杂的用法大家可以通过 Spring Framework 的官方手册进行了解。
7.1.4 通过 Spring Data 的 Repository 操作数据库
虽然与直接使用 SQL 的方式相比,Hibernate 方便了不少,但广大开发者对效率的追求是无止境的。不少日常增删改查操作的代码都“长得差不多”,而且对关系型数据库、NoSQL 数据库都有类似的操作,那么是否还可以进一步简化呢?答案是肯定的,Spring Data 项目就为不同的常见数据库提供了统一的 Repository 抽象层。我们可以通过约定好的方式定义接口,使用其中的方法来声明需要的操作,剩下的实现工作完全交由 Spring Data 来完成。Spring Data 的核心接口是 Repository<T, ID>, T 是实体类型, ID 是主键类型,一般我们会使用它的子接口 CrudRepository<T, ID> 或者 PagingAndSortingRepository<T, ID>。 CrudRepository<T, ID> 的定义如下所示:
@NoRepositoryBeanpublic interface CrudRepository<T, ID> extends Repository<T, ID> {<S extends T> S save(S var1);<S extends T> Iterable<S> saveAll(Iterable<S> var1);Optional<T> findById(ID var1);boolean existsById(ID var1);Iterable<T> findAll();Iterable<T> findAllById(Iterable<ID> var1);long count();void deleteById(ID var1);void delete(T var1);void deleteAll(Iterable<? extends T> var1);void deleteAll();}
可以看到其中已经包含了一些通用的方法,比如新增和删除实体,还有根据 ID 查找实体等。 PagingAndSortingRepository<T, ID> 则是在此基础之上又增加了分页和排序功能。
Spring Data JPA 是专门针对 JPA 的。在 pom.xml 中引入 org.springframework.boot:spring-boot-starter-data-jpa 就能添加所需的依赖。其中提供了一个专属的 JpaRepository<T, ID> 接口,可以在配置类上增加 @EnableJpaRepositories 来开启 JPA 的支持,通过这个注解还可以配置一些个性化的信息,比如要扫描 Repository 接口的包。
Spring Boot 的 JpaRepositoriesAutoConfiguration 提供了 JpaRepository 相关的自动配置,只要符合条件就能完成配置。它通过 @Import 注解导入了 JpaRepositoriesRegistrar 类,其中直接定义了一个静态内部类 EnableJpaRepositoriesConfiguration,上面添加了 @EnableJpaRepositories,所以在 Spring Boot 项目里无须自己添加该注解,只要有相应的依赖,Spring Boot 的自动配置就能帮忙完成剩下的工作:
@Configuration(proxyBeanMethods = false)@ConditionalOnBean(DataSource.class)@ConditionalOnClass(JpaRepository.class)@ConditionalOnMissingBean({ JpaRepositoryFactoryBean.class, JpaRepositoryConfigExtension.class })@ConditionalOnProperty(prefix = "spring.data.jpa.repositories", name = "enabled", havingValue = "true",matchIfMissing = true)@Import(JpaRepositoriesRegistrar.class)@AutoConfigureAfter({ HibernateJpaAutoConfiguration.class, TaskExecutionAutoConfiguration.class })public class JpaRepositoriesAutoConfiguration { ... }
要定义自己的 Repository 只需扩展 CrudRepository<T, ID>、 PagingAndSortingRepository<T, ID> 或 JpaRepository<T, ID>,并明确指定泛型类型即可。例如, MenuItem 和 TeaMaker 的 Repository 大概就是代码示例 7-13 这样的。
代码示例 7-13 MenuItem 和 TeaMaker 的 Repository 定义
public interface MenuRepository extends JpaRepository<MenuItem, Long> {}public interface TeaMakerRepository extends JpaRepository<TeaMaker, Long> {}
通用的方法基本能满足大部分需求,但是总会有一些业务所需的特殊查询需要是通用的方法所不能满足的。在 Spring Data 的帮助下,我们只需要根据它的要求定义方法,无须编写具体的实现,这就省却了很多工作。以下几种形式的方法名都可以视为有效的查询方法:
find...By...read...By...query...By...get...By...
如果只是想要统计数量,不用返回具体内容,可以使用 count...By... 的形式。
其中,第一段“ ...”的内容是限定返回的结果条数,比如用 TopN、 FirstN 表示返回头 N 个结果,还可以用 Distinct 起到 SQL 语句中 distinct 关键词的效果。第二段“ ...”的内容是查询的条件,也就是 SQL 语句中 where 的部分,条件所需的内容与方法的参数列表对应,可以通过 And、 Or 关键词组合多个条件,用 Not 关键词取反。Spring Data 方法支持多种形式的条件,具体见表 7-7。
表 7-7 Spring Data 查询方法支持的关键词
| 作用 | 关键词 | 例子 |
|---|---|---|
| 相等 | Is、 Equals,不写的话默认就是相等 | findByNameIs(String name) |
| 比较 | LessThan、 LessThanEqual、 GreaterThan、 GreaterThanEqual | findByNumberLessThan(int number) |
| 比较 | Between,用于日期时间的比较 | findByStartDateBetween(Date d1, Date d2) |
| 比较 | Before、 After,用于日期时间的比较 | findByEndDateBefore(Date date) |
| 是否为空 | Null、 IsNull、 NotNull、 IsNotNull | findBySizeIsNotNull() |
| 相似 | Like、 NotLike | findByNameNotLike(String name) |
| 字符串判断 | StartingWith、 EndingWith、 Containing | findByNameContaining(String name) |
| 忽略字符串大小写进行判断 | IgnoreCase、 AllIgnoreCase | findByLastnameAndFirstnameAllIgnoreCase(String lastname, String firstname) |
| 集合 | In、 NotIn | findBySizeIn(List<Size> sizeList) |
| 布尔判断 | True、 False | findByActiveFalse() |
对于会返回多条结果的方法,可以在方法名结尾处增加 OrderBy 关键词指定排序的字段,通过 Asc 和 Desc 指定升序或者降序(默认为 Asc)。例如 findByNameOrderByIdDesc(String name),这里也支持多个字段排序的组合,例如 findByNameOrderByUpdateTimeDescId(String name)。也可以在参数中增加一个 Sort 类型的参数来灵活地传入期望的排序方式,例如:
Sort sort = Sort.by("name").descending().and(Sort.by("id").ascending());
另一个常见的需求是分页。方法的返回值可以是 Page<T> 或集合类型,通过传入 Pageable 类型的参数来指定分页信息。
Spring Data 的 Repository 接口方法支持很多种返回类型:单个返回值的,除了常见的 T 类型,也可以是 Optional<T>;集合类型除了 Iterable 相关的类型,还可以是 Streamable 的,方便做流式处理。
既然这里用的是 JPA 的 Repository 接口,自然就要用 JPA 相关的配置。之前我们做的 Hibernate 的配置就可以替换一下,最简单的就是把配置都删了,完全靠 Spring Boot 的自动配置。之前 Hibernate 配置的一些属性,可以写到 application.properties 里,如代码示例 7-14 所示。
代码示例 7-14 application.properties 中的一些配置片段
spring.jpa.hibernate.ddl-auto=create-dropspring.jpa.properties.hibernate.format_sql=true#spring.jpa.properties.hibernate.show_sql=truespring.jpa.show-sql=true
这三个配置的效果,等同于代码示例 7-7 中用代码做的配置,其中 spring.jpa.properties.hibernate.show_sql 与 spring.jpa.show-sql 的效果相同。
对于订单的操作,我们可以定义一个 OrderRepository 接口,具体如代码示例 7-15 所示。
代码示例 7-15 操作订单的 OrderRepository 接口
public interface OrderRepository extends JpaRepository<Order, Long> {List<Order> findByStatusOrderById(OrderStatus status);List<Order> findByMaker_NameLikeIgnoreCaseOrderByUpdateTimeDescId(String name);}
上面的第一个方法根据 Order.status 进行查找,结果按照 id 升序排列;第二个方法比较复杂,根据 Order.maker.name 进行相似匹配,且忽略大小写,结果先按照 updateTime 降序排列,如果相同再按 id 升序排列。对于 Order.maker.name 这样的属性,可以像上面这样用 _ 明确地表示 name 是 Maker 的属性,也可以不加 _,让 Spring Data 自行判断。大家可以尝试写一下这个接口的单元测试,也可以参考我们提供的代码示例中的 OrderRepositoryTest 类,此处就不再展开了。在取到 Order 后,其中懒加载的内容有可能没有被加载上来,因此我们在访问时需要增加一个事务,保证在操作时能够取得当前会话。
如果有一些公共的方法希望能剥离到公共接口里,但又不希望这个公共接口被创建成 Repository 的 Bean,这时就可以在接口上添加 @NoRepositoryBean 注解。 JpaRepository 接口就是这样的:
@NoRepositoryBeanpublic interface JpaRepository<T, ID> extends PagingAndSortingRepository<T, ID>, QueryByExampleExecutor<T> {}
这里,我们同样要为 OrderRepository 中的两个方法添加一些简单的单元测试,这些测试需要用到一些测试数据,它们可以和 TeaMakerRepository 的测试复用,因此可以将测试数据的准备工作单独剥离出来,放到 src/test/java 对应的位置,代码内容具体如代码示例 7-16 所示。具体的逻辑是先插入 3 条 MenuItem 和 2 条 TeaMaker 记录,随后用它们来创建订单,两条订单之间间隔 200 毫秒,这样在按照订单时间排序时可以有明确的顺序。
代码示例 7-16 进行测试数据准备的 DataInitializationRunner 类
public class DataInitializationRunner implements ApplicationRunner {@Autowiredprivate TeaMakerRepository makerRepository;@Autowiredprivate MenuRepository menuRepository;@Autowiredprivate OrderRepository orderRepository;@Override@Transactionalpublic void run(ApplicationArguments args) throws Exception {List<MenuItem> menuItemList = Stream.of("Go橙汁", "Python气泡水", "JavaScript苏打水").map(n -> MenuItem.builder().name(n).size(Size.MEDIUM).price(Money.ofMinor(CurrencyUnit.of("CNY"), 1200)).build()).map(m -> {menuRepository.save(m);return m;}).collect(Collectors.toList());List<TeaMaker> makerList = Stream.of("LiLei", "HanMeimei").map(n -> TeaMaker.builder().name(n).build()).map(m -> {makerRepository.save(m);return m;}).collect(Collectors.toList());Order order = Order.builder().maker(makerList.get(0)).amount(Amount.builder().discount(90).totalAmount(Money.ofMinor(CurrencyUnit.of("CNY"), 1200)).payAmount(Money.ofMinor(CurrencyUnit.of("CNY"), 1080)).build()).items(List.of(menuItemList.get(0))).status(OrderStatus.ORDERED).build();orderRepository.save(order);try {Thread.sleep(200);} catch (InterruptedException e) {}order = Order.builder().maker(makerList.get(0)).amount(Amount.builder().discount(100).totalAmount(Money.ofMinor(CurrencyUnit.of("CNY"), 1200)).payAmount(Money.ofMinor(CurrencyUnit.of("CNY"), 1200)).build()).items(List.of(menuItemList.get(1))).status(OrderStatus.ORDERED).build();orderRepository.save(order);}}
上面的 DataInitializationRunner 类上并未添加任何 Spring Bean 相关的注解,所以它并不会被自动扫描加载为 Bean。由于代码示例 7-12 中的 MenuRepositoryTest 并不需要它的数据,让它跑起来反而还会破坏原来的测试,所以我们可以有条件地选择性执行这段初始化逻辑。代码示例 7-17 就是对应的配置类,通过 @ConditionalOnProperty 可以实现根据 data.init.enable 属性的值来确定是否创建 DataInitializationRunner Bean:只有值为 true 时才会创建,为其他值或没有设置时都不会有任何效果。
代码示例 7-17 根据特定属性生效的 DataInitializationConfig 配置类
@Configuration@ConditionalOnProperty(name = "data.init.enable", havingValue = "true")public class DataInitializationConfig {@Beanpublic DataInitializationRunner dataInitializationRunner() {return new DataInitializationRunner();}}
代码示例 7-18 就是针对 OrderRepository 的测试类,在 @SpringBootTest 上增加了一个 data.init.enable=true 的属性配置,这样就能用上前面准备的测试数据初始化逻辑了。随后的两个测试方法内容比较直观,就不再做过多说明了。
代码示例 7-18 针对 OrderRepository 的测试类
@SpringBootTest(properties = {"data.init.enable=true","spring.sql.init.mode=never", "spring.jpa.hibernate.ddl-auto=create-drop"})@TestMethodOrder(MethodOrderer.OrderAnnotation.class)class OrderRepositoryTest {@Autowiredprivate OrderRepository orderRepository;@Test@Transactionalpublic void testFindByStatusOrderById() {assertTrue(orderRepository.findByStatusOrderById(OrderStatus.FINISHED).isEmpty());List<Order> list = orderRepository.findByStatusOrderById(OrderStatus.ORDERED);assertEquals(2, list.size());assertEquals("Go橙汁", list.get(0).getItems().get(0).getName());assertEquals("Python气泡水", list.get(1).getItems().get(0).getName());assertTrue(list.get(0).getId() < list.get(1).getId());assertEquals("LiLei", list.get(0).getMaker().getName());assertEquals("LiLei", list.get(1).getMaker().getName());}@Testpublic void testFindByMaker_NameLikeOrderByUpdateTimeDescId() {assertTrue(orderRepository.findByMaker_NameLikeIgnoreCaseOrderByUpdateTimeDescId("%han%").isEmpty());List<Order> list = orderRepository.findByMaker_NameLikeIgnoreCaseOrderByUpdateTimeDescId("%lei%");assertEquals(2, list.size());assertTrue(list.get(0).getUpdateTime().getTime() >= list.get(1).getUpdateTime().getTime());assertTrue(list.get(0).getId() > list.get(1).getId());}}
茶歇时间:
JpaRepository背后的原理在正文中有提到,Spring Boot 的自动配置导入了
JpaRepositoriesRegistrar,这个类的内部类添加了@EnableJpaRepositories,开启了对 JPARepository的支持。相关的扩展配置则是由JpaRepositoryConfigExtension提供的,其中注册了很多 Bean,例如:
EntityManagerBeanDefinitionRegistrarPostProcessorJpaMetamodelMappingContextFactoryBeanPersistenceAnnotationBeanPostProcessorDefaultJpaContextJpaMetamodelCacheCleanupJpaEvaluationContextExtension此外,扫描找到的
Repository接口都会对应地配置一个JpaRepositoryFactoryBean类型的工厂 Bean。可以通过这个工厂 Bean 来获得具体的JpaRepositoryFactory,它是RepositoryFactorySupport的子类,其中的getRepository(Class<T> repositoryInterface, RepositoryFragments fragments)会返回最终的Repository实现。
getRepository()方法为我们的接口创建了一个扩展了SimpleJpaRepository<T, ID>的实现,它包含了最基础的增删改查方法的实现。另外getRepository()返回的 Bean 还添加了一层动态代理,其中添加了一些 AOP 通知,根据不同情况,可能会有以下几种:
MethodInvocationValidatorExposeInvocationInterceptorDefaultMethodInvokingMethodInterceptorQueryExecutorMethodInterceptorImplementationMethodExecutionInterceptor在这些通知中,
QueryExecutorMethodInterceptor就负责为我们自定义的各种查询方法提供实现。PartTree定义了查询方法该如何解析,关键词信息如下:private static final String KEYWORD_TEMPLATE = "(%s)(?=(\p|\P))"; private static final String QUERY_PATTERN = "find|read|get|query|search|stream"; private static final String COUNT_PATTERN = "count"; private static final String EXISTS_PATTERN = "exists"; private static final String DELETE_PATTERN = "delete|remove";
Part类中的内部枚举Type中定义了各式条件:private static final List<Part.Type> ALL = Arrays.asList(IS_NOT_NULL, IS_NULL, BETWEEN, LESS_THAN,LESS_THAN_EQUAL, GREATER_THAN, GREATER_THAN_EQUAL, BEFORE, AFTER, NOT_LIKE, LIKE,STARTING_WITH, ENDING_WITH, IS_NOT_EMPTY, IS_EMPTY, NOT_CONTAINING, CONTAINING, NOT_IN, IN,NEAR, WITHIN, REGEX, EXISTS, TRUE, FALSE, NEGATING_SIMPLE_PROPERTY, SIMPLE_PROPERTY);
AbstractJpaQuery子类中的execute(Object[] parameters)方法负责执行具体的查询。经过这样的一路分析,可以发现整个 JPA 的
Repository的实现并没有太多高深的地方,依靠动态代理和对各种情况的预先编码,最后的效果就是我们看到的:通过定义接口来实现格式操作。
7.2 通过 MyBatis 操作数据库
MyBatis 是一款优秀的持久化框架,它支持自定义 SQL、存储过程和高级映射。与 Hibernate 一样,我们几乎不再需要手写 JDBC 代码,就能完成常见的数据库操作。表 7-8 对两种对象关系映射框架做了一个简单的对比。
表 7-8 MyBatis 与 Hibernate 的简单对比
| MyBatis | Hibernate | |
|---|---|---|
| XML 方式配置映射 | 支持 | 支持 |
| 注解方式配置映射 | 支持 | 支持 |
| 自动生成目标 SQL | 不支持 | 支持 |
| 复杂的 SQL 操作 | 支持 | 部分支持 |
| SQL 优化难易程度 | 方便 | 不方便 |
| 底层数据库的可移植性 | 映射 SQL 与数据库绑定 | 有灵活的“方言”支持 |
通过 Google Trends,我们可以看到一个有趣的现象:过去 5 年里,在全球范围内,Hibernate 的搜索热度是 MyBatis 的 5.7 倍;而在中国,情况恰恰相反,MyBatis 的搜索热度是 Hibernate 的 2.7 倍左右。按照对 MyBatis 关键词的关注度排序的话,前 5 个城市分别是杭州、北京、深圳、上海和广州。
其实,这个现象还是比较容易解释的,在中国,互联网大厂普遍更喜欢使用 MyBatis。在阿里,绝大多数 Java 项目都使用 MyBatis 而非 Hibernate,若配合一些工具,MyBatis 的方便程度不亚于 Hibernate,而且专业的 DBA 可以对 SQL 做各种优化,灵活度很高。
因此,这一节,我们会一起来简单看一下如何在 Spring 项目中使用 MyBatis。更多详细的内容,感兴趣的同学可以查阅官方文档。官方也有比较详细的中文版本。
7.2.1 定义 MyBatis 映射
MyBatis 支持通过 XML 和注解两种方式来配置映射。从早期的 iBatis 开始,XML 的功能就已经很齐全了,注解的方式是后来才出现的。因为在介绍 JPA 时我们就使用了注解的方式,所以这里我们也通过注解来做映射。
-
通过注解定义常用操作映射
在使用 JPA 时,我们的映射关系是定义在实体类上的;但在 MyBatis 中,我们对实体类没有什么要求,也无须添加特定的注解,各种映射都是通过
Mapper接口来定义的。代码示例 7-19 是与代码示例 7-3 对应的实体类,只保留了 Lombok 注解,没有其他额外的内容,其他几个实体类的改动是一样的,就不再说明了。
代码示例 7-19 MyBatis 中使用的部分实体类定义
public enum Size {SMALL, MEDIUM, LARGE}@Builder@Data@AllArgsConstructor@NoArgsConstructorpublic class MenuItem {private Long id;private String name;private Size size;private Money price;private Date createTime;private Date updateTime;}
与之匹配的 Mapper 接口如代码示例 7-20 所示,其中包含了常用的增删改查方法,两种实现方式下它们的功能是基本类似的。
代码示例 7-20 添加了 MyBatis 注解的 Mapper 接口
@Mapperpublic interface MenuItemMapper {@Select("select count(*) from t_menu")long count();@Insert("insert into t_menu (name, price, size, create_time, update_time) " +"values (#, #, #, now(), now())")@Options(useGeneratedKeys = true, keyProperty = "id")int save(MenuItem menuItem);@Update("update t_menu set name = #, price = #, size = #, update_time = now() " +"where id = #")int update(MenuItem menuItem);@Select("select * from t_menu where id = #")@Results(id = "menuItem", value = {@Result(column = "id", property = "id", id = true),@Result(column = "size", property = "size", typeHandler = EnumTypeHandler.class),@Result(column = "price", property = "price", typeHandler = MoneyTypeHandler.class),@Result(column = "create_time", property = "createTime"),@Result(column = "update_time", property = "updateTime")})MenuItem findById(@Param("id") Long id);@Delete("delete from t_menu where id = #")int deleteById(@Param("id") Long id);@Select("select * from t_menu")List<MenuItem> findAll();@Select("select m.* from t_menu m, t_order_item i where m.id = i.item_id and i.order_id = #")List<MenuItem> findByOrderId(Long orderId);}
接下来,让我们详细地了解一下上述代码中用到的注解,具体如表 7-9 所示。
表 7-9 MyBatis 中的常用注解
| 注解 | 作用 | 重点属性说明 |
|---|---|---|
@Insert | 定义插入操作 | value 为具体使用的 SQL 语句 |
@Delete | 定义删除操作 | 同上 |
@Update | 定义更新操作 | 同上 |
@Select | 定义查询操作 | 同上 |
@Param | 指定参数名称,方便在 SQL 中使用对应参数(一般不用指定) | |
@Results | 指定返回对象的映射方式,具体内容通过 @Result 注解设置 | id 用来设置结果映射的 ID,以便复用 |
@Result | 指定具体字段、属性的映射关系 | |
@ResultMap | 引用其他地方已事先定义好的映射关系 | |
@Options | 设置开关和配置选项 | useGeneratedKeys——使用生成的主键, keyProperty——主键属性名, fetchSize——获取结果集的条数, timeout——超时时间 |
@One | 指定复杂的单个属性映射 | Select——指定查询使用的 Java 方法 |
@Many | 指定复杂的集合属性映射 | 同上 |
-
自定义类型映射
MyBatis 是通过
TypeHandler来实现特殊类型的处理的。在代码示例 7-17 中,有一段代码定义了特殊类型的映射,具体代码如下:
@Result(column = "size", property = "size", typeHandler = EnumTypeHandler.class),@Result(column = "price", property = "price", typeHandler = MoneyTypeHandler.class),
size 属性是一个枚举,通常枚举在数据库中有两种保存方式,一种是保存枚举名,用的就是 EnumTypeHandler,例如, size 枚举的 SMALL、 MEDIUM 和 LARGE;另一种是保存枚举的顺序,用的是 EnumOrdinalTypeHandler,例如, 0、 1 和 2 分别对应了前面 size 枚举的 SMALL、 MEDIUM 和 LARGE。MyBatis 中默认使用 EnumTypeHandler 来处理枚举类型。
price 属性的类型是 Money,这个类 MyBatis 没有提供内置的 TypeHandler,因此需要我们自己来实现一个针对 Money 类型的处理器。MyBatis 提供了 BaseTypeHandler 抽象类,通过它可以方便地实现 TypeHandler。 MoneyTypeHandler 的代码如代码示例 7-21 所示,它的作用是将金额按分为单位,转换为 Long 类型保存到数据库中,在取出时则以人民币为币种还原为 Money。
代码示例 7-21 处理 Money 类型的 MoneyTypeHandler 代码片段
public class MoneyTypeHandler extends BaseTypeHandler<Money> {@Overridepublic void setNonNullParameter(PreparedStatement ps, int i,Money parameter, JdbcType jdbcType) throws SQLException {ps.setLong(i, parameter.getAmountMinorLong());}@Overridepublic Money getNullableResult(ResultSet rs, String columnName) throws SQLException {return parseMoney(rs.getLong(columnName));}@Overridepublic Money getNullableResult(ResultSet rs, int columnIndex) throws SQLException {return parseMoney(rs.getLong(columnIndex));}@Overridepublic Money getNullableResult(CallableStatement cs, int columnIndex) throws SQLException {return parseMoney(cs.getLong(columnIndex));}private Money parseMoney(Long value) {return Money.ofMinor(CurrencyUnit.of("CNY"), value);}}
-
一对多与多对多关系
在处理对象时,我们还有一对一、一对多和多对多这样的关系,在 JPA 中有对应的注解可以进行配置,在 MyBatis 中也有类似的功能。表 7-9 中已经介绍过了
@One和@Many注解,现在就让我们一起来看一下它们的具体使用方法。TeaMaker中的orders列表保存的是这位调茶师所负责的订单信息,在Order中则通过maker属性保存了订单所对应的调茶师信息。这是一个典型的一对多映射,这个关系在数据库中是由t_order表的maker_id字段来做持久化的。代码示例 7-22 演示了如何定义TeaMaker以及该如何加载orders集合。可以看到@Many中给定的是具体获取方法的全限定类名加方法名,方法的参数就是指定的字段内容。
代码示例 7-22 在 TeaMakerMapper 中定义一对多的一方
@Mapperpublic interface TeaMakerMapper {@Select("select * from t_tea_maker where id = #")@Results(id = "teaMakerMap", value = {@Result(column = "id", property = "id"),@Result(column = "id", property = "orders",many = @Many(select = "learning.spring.binarytea.repository.OrderMapper.findByMakerId"))})TeaMaker findById(Long id);// 省略其他方法}
代码示例 7-23 演示了在 Order 中如何根据 maker_id 加载 TeaMaker, @One 中同样提供了具体的查询方法。此外,订单的具体条目和订单之间是一个多对多关系,即 Order 对象和 MenuItem 对象之间存在多对多关系,具体的关系保存在 t_order_item 表中。我们可以看到 Order 的 items 列表使用了 @Many 来指定查询 MenuItem 集合的方法,这个 MenuItemMapper.findByOrderId() 已经在代码示例 7-20 中提供了。代码示例 7-23 的 findByMakerId() 方法还演示了 @ResultMap 注解的用法。
代码示例 7-23 在 OrderMapper 中定义多对一和多对多关系
@Mapperpublic interface OrderMapper {@Select("select * from t_order where id = #")@Results(id = "orderMap", value = {@Result(column = "status", property = "status", typeHandler = EnumOrdinalTypeHandler.class),@Result(column = "amount_discount", property = "amount.discount"),@Result(column = "amount_total", property = "amount.totalAmount"),@Result(column = "amount_pay", property = "amount.payAmount"),@Result(column = "maker_id", property = "maker",one = @One(select = "learning.spring.binarytea.repository.TeaMakerMapper.findById")),@Result(column = "id", property = "items",many = @Many(select = "learning.spring.binarytea.repository.MenuItemMapper.findByOrderId"))})Order findById(Long id);@Select("select * from t_order where maker_id = #")@ResultMap("orderMap")List<Order> findByMakerId(Long makerId);// 省略其他方法}
除了查询,多对多关系的保存也需要特殊处理,代码示例 7-24 就是具体的内容。 OrderMapper 的 save() 方法可以直接保存大部分的订单信息,包括其中与 TeaMaker 的关系。 t_order 表在保存 status 时就是使用的 EnumOrdinalTypeHandler 类型处理器,它能够保存序号。 addOrderItem() 方法用来添加订单中的具体条目,具体的 SQL 则是向 t_order_item 表中插入记录。
代码示例 7-24 在 OrderRepository 中保存订单及对应内容
@Mapperpublic interface OrderMapper {@Insert("insert into t_order " +"(maker_id, status, amount_discount, amount_pay, amount_total, create_time, update_time) " +"values (#, #, " +"#, #, #, now(), now())")@Options(useGeneratedKeys = true, keyProperty = "id")int save(Order order);@Insert("insert into t_order_item (order_id, item_id) values (#, #)")int addOrderItem(Long orderId, MenuItem item);// 省略其他方法}
7.2.2 在 Spring 中配置并使用 MyBatis
定义好了映射关系,接下来的问题就是如何在工程中使用它们。MyBatis-Spring 为 MyBatis 提供了与 Spring Framework 无缝集成的能力,其中包括:
- 与 Spring 事务的集成,主要靠
SpringManagedTransaction与SpringManagedTransactionFactory来实现; SqlSession的构建,主要靠SqlSessionFactoryBean实现;Mapper的构建,手动构建靠MapperFactoryBean,也可以通过MapperScannerConfigurer来自动扫描;- 异常的解析与转换,由
MyBatisExceptionTranslator实现。
在实际使用时,我们只需要在 Spring Framework 的上下文中配置几个 Bean 就可以了,例如:
<bean id="sqlSessionFactory" class="org.mybatis.spring.SqlSessionFactoryBean"><property name="dataSource" ref="dataSource" /></bean><!-- 按需定义Mapper Bean --><bean id="menuItemMapper" class="org.mybatis.spring.mapper.MapperFactoryBean"><property name="mapperInterface" value="learning.spring.binarytea.repository.MenuItemMapper" /><property name="sqlSessionFactory" ref="sqlSessionFactory" /></bean>
在 Mapper 多的时候,可以直接通过扫描来实现 Mapper 的自动注册:
<beans xmlns="http://www.springframework.org/schema/beans"xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"xmlns:mybatis="http://mybatis.org/schema/mybatis-spring"xsi:schemaLocation="http://www.springframework.org/schema/beans http://www.springframework.org/schema/beans/spring-beans.xsdhttp://mybatis.org/schema/mybatis-spring http://mybatis.org/schema/mybatis-spring.xsd"><mybatis:scan base-package="learning.spring.binarytea.repository" /><bean id="sqlSessionFactory" class="org.mybatis.spring.SqlSessionFactoryBean"><property name="dataSource" ref="dataSource" /></bean><!-- 其他Bean配置 --></beans>
当然,还有更方便的注解,可以用来指定扫描范围:
@MapperScan("learning.spring.binarytea.repository")public class Config {}
关于 MyBatis-Spring 的更多配置细节就留给大家慢慢去官方文档 15 中探索吧。其实这样的配置已经十分简单了,但是在 Spring Boot 的加持下,配置还可以进一步简化。于是就该 MyBatis-Spring-Boot-Starter 登场了,它可以帮助我们几乎消除模板式的代码和 XML 配置文件。而我们需要做的只是在 pom.xml 文件中增加相关的依赖,剩下的就交给 MybatisAutoConfiguration 和 MybatisLanguageDriverAutoConfiguration 来做自动配置即可:
<dependency><groupId>org.mybatis.spring.boot</groupId><artifactId>mybatis-spring-boot-starter</artifactId><version>2.2.2</version></dependency>
我们可以通过 application.properties 来定制一些配置,例如表 7-10 中罗列的这些。
表 7-10 MyBatis-Spring-Boot-AutoConfigure 支持的一些配置项
| 配置项 | 说明 |
|---|---|
mybatis.type-aliases-package | 映射的 POJO 类型放置的包路径 |
mybatis.type-handlers-package | 类型映射所需的 TypeHandler 放置的包路径 |
mybatis.config-location | MyBatis 配置文件的位置 |
mybaits.mapper-locations | 映射文件的位置 |
mybatis.configuration.* | MyBatis 核心配置,例如下面两个,不能和 mybatis.config-location 一起使用 |
mybatis.configuration.map-underscore-to-camel-case | 是否将下划线映射为驼峰规则 |
mybatis.configuration.default-statement-timeout | 默认语句超时时间 |
例如,在我们的 application.properties 配置文件里就可以像下面这样做配置,再结合带有 @MapperScan 注解的配置类:
mybatis.type-handlers-package=learning.spring.binarytea.support.handlermybatis.type-aliases-package=learning.spring.binarytea.modelmybatis.configuration.map-underscore-to-camel-case=true
为了让程序能够顺利执行,我们还需要事先新建好对应的表,插入几条测试数据。既然使用了 H2 内嵌数据库,自然就可以依赖 6.1.2 节中的内嵌数据库初始化逻辑。schema.sql 中的表结构是根据 7.1 节 Hibernate 自动创建的表结构简单修改而来的,如代码示例 7-25 所示。
代码示例 7-25 用于 MyBatis 演示的 src/main/resources/schema.sql 文件
drop table if exists t_menu;drop table if exists t_order;drop table if exists t_order_item;drop table if exists t_tea_maker;create table t_menu (id bigint not null auto_increment, name varchar(255), price bigint, size varchar(255),create_time timestamp, update_time timestamp, primary key (id));create table t_order (id bigint not null auto_increment, amount_discount integer, amount_pay bigint, amount_total bigint,status integer, maker_id bigint, create_time timestamp, update_time timestamp, primary key (id));create table t_order_item (item_id bigint not null, order_id bigint not null);create table t_tea_maker (id bigint not null auto_increment, name varchar(255), create_time timestamp, update_time timestamp,primary key (id));
而初始化的数据则放在 data.sql 中,具体如代码示例 7-26 所示。
代码示例 7-26 用于 MyBatis 演示的 src/main/resources/data.sql 文件
insert into t_menu (name, size, price, create_time, update_time) values ('Java咖啡', 'MEDIUM', 1200, now(), now());insert into t_menu (name, size, price, create_time, update_time) values ('Java咖啡', 'LARGE', 1500, now(), now());insert into t_tea_maker (name, create_time, update_time) values ('LiLei', now(), now());insert into t_tea_maker (name, create_time, update_time) values ('HanMeimei', now(), now());insert into t_order (maker_id, status, amount_discount, amount_pay, amount_total, create_time, update_time) values (1, 0, 100, 1200, 1200, now(), now());insert into t_order_item (order_id, item_id) values (1, 1);
和之前一样,我们使用一段单元测试来验证我们的代码。代码示例 7-27 的逻辑是这样的:
(1) 构建并保存一个订单对象 Order;
(2) 插入对应的订单内容;
(3) 根据第 (1) 步返回的订单 ID,重新查询获得订单对象,验证对应的值是否正确。
代码示例 7-27 用于测试 OrderMapper 的单元测试片段
@SpringBootTestclass OrderMapperTest {@Autowiredprivate OrderMapper orderMapper;@Autowiredprivate TeaMakerMapper makerRepository;@Autowiredprivate MenuItemMapper menuItemMapper;@Test@Transactional@Rollbackpublic void testSaveAndFind() {TeaMaker maker = makerRepository.findById(2L);Order order = Order.builder().status(OrderStatus.ORDERED).maker(maker).amount(Amount.builder().discount(90).totalAmount(Money.ofMinor(CurrencyUnit.of("CNY"), 1200)).payAmount(Money.ofMinor(CurrencyUnit.of("CNY"), 1080)).build()).build();assertEquals(1, orderMapper.save(order));Long orderId = order.getId();assertNotNull(orderId);assertEquals(1, orderMapper.addOrderItem(orderId, menuItemMapper.findById(2L)));order = orderMapper.findById(orderId);assertEquals(OrderStatus.ORDERED, order.getStatus());assertEquals(90, order.getAmount().getDiscount());assertEquals(maker.getId(), order.getMaker().getId());assertEquals(1, order.getItems().size());assertEquals(2L, order.getItems().get(0).getId());}// 省略其他测试}
在上面的代码中,需要特别说明一下加在 testSaveAndFind() 上的 @Rollback 注解。Spring Framework 为测试提供了强大的支持,在涉及数据库操作的时候,为了保证每个测试的运行不会给别的测试带来影响,它直接可以回滚测试中的操作,而且这也是默认的逻辑,也就是说我们不用添加 @Rollback 也是一样的效果。如果希望能够让测试代码的变动被提交到数据库中,可以使用 @Commit 或者 @Rollback(false)。当然,这里一切的前提是先有事务,这也就是为什么会在 testSaveAndFind() 上添加 @Transactional 的原因。
7.2.3 提升 MyBatis 的开发效率
通过前面的内容,相信大家也隐约感觉到了,相比 JPA,MyBatis 需要自己实现的内容多了一点点。但其实在一些开源工具的帮助下,MyBatis 的开发效率也不亚于 JPA。有些工具是官方提供的,也有一些是非官方的社区提供的,大家的目的都是让开发体验“如丝般顺滑”。
-
MyBatis 映射生成工具
MyBatis 的使用离不开大量的配置,尤其是 XML 或注解形式都需要手写 SQL。那么是否有什么办法能让这个过程不那么繁琐呢?答案是肯定的。MyBatis 官方为此提供了一套生成工具—— MyBatis Generator。
这套工具可以根据数据库的元数据和配置文件,为我们生成如下内容。
- 与数据表对应的 POJO 类。
- Mapper 接口,如果用注解或混合方式配置映射,接口上会有对应的注解。
- SQLMap 映射 XML 文件(仅在 XML 方式或混合方式时生成)。
其中会包含各种常用的操作,从某种程度上能减少开发的工作量。该工具在使用时需要提供一个 XML 配置文件,与代码示例 7-28 类似。
代码示例 7-28 MyBatis Generator 配置示例
<?xml version="1.0" encoding="UTF-8"?><!DOCTYPE generatorConfiguration PUBLIC "-//mybatis.org//DTD MyBatis Generator Configuration 1.0//EN""http://mybatis.org/dtd/mybatis-generator-config_1_0.dtd"><generatorConfiguration><context id="H2Tables" targetRuntime="MyBatis3"><plugin type="org.mybatis.generator.plugins.FluentBuilderMethodsPlugin" /><plugin type="org.mybatis.generator.plugins.ToStringPlugin" /><plugin type="org.mybatis.generator.plugins.SerializablePlugin" /><plugin type="org.mybatis.generator.plugins.RowBoundsPlugin" /><jdbcConnection driverClass="org.h2.Driver" connectionURL="jdbc:h2:mem:testdb" userId="sa" password=""></jdbcConnection><javaModelGenerator targetPackage="learning.spring.binarytea.model" targetProject="./src/main/java"><property name="enableSubPackages" value="true" /><property name="trimStrings" value="true" /></javaModelGenerator><sqlMapGenerator targetPackage="learning.spring.binarytea.repository"targetProject="./src/main/resources/mapper"><property name="enableSubPackages" value="true" /></sqlMapGenerator><javaClientGenerator type="MIXEDMAPPER" targetPackage="learning.spring.binarytea.repository"targetProject="./src/main/java"><property name="enableSubPackages" value="true" /></javaClientGenerator><table tableName="t_menu" domainObjectName="MenuItem" ><generatedKey column="id" sqlStatement="CALL IDENTITY()" identity="true" /><columnOverride column="price" javaType="org.joda.money.Money" jdbcType="BIGINT"typeHandler="learning.spring.binarytea.support.handler.MoneyTypeHandler"/></table></context></generatorConfiguration>
<context/> 中的内容需要按照顺序配置,从上往下分别为:
(1) <plugin/>,插件配置,例子中配置了生成构建器的插件(类似 Lombok 的 @Builder)、生成 toString() 方法的插件、分页插件等;
(2) <jdbcConnection/>,JDBC 连接信息;
(3) <javaModelGenerator/>,POJO 对象生成信息;
(4) <sqlMapGenerator/>,SQLMap 生成信息;
(5) <javaClientGenerator/>,Java 客户端,即 Mapper 接口的生成信息;
(6) <table/>,要生成的数据表配置。
值得注意的是配置中的目标位置既可以是绝对路径,也可以是相对当前执行目录的相对路径,而且 在生成前需要先确保目录存在。
MyBatis Generator 支持多种运行方式,例如,命令行工具、Maven 插件、ANT 任务、Eclipse 插件等。在命令行里可以运行如下命令,JAR 包需要为具体版本的包,同时提供配置文件:
java -jar mybatis-generator-core-x.x.x.jar -configfile generatorConfig.xml
关于这个工具的更多详细内容,大家可以通过官方文档进一步了解,本书就不展开了。
-
MyBatis 分页插件
分页查询是一个很常见的需求,在 MyBatis 里的分页自然也不会很困难,它依托于插件机制,可以通过分页插件来实现分页查询。这里就要介绍一个国人编写的 MyBatis 分页插件 PageHelper,它支持 3.1.0 以上的 MyBatis 版本,支持十余种数据库的物理分页,还有对应的 Spring Boot Starter,仅需简单几个配置就能直接使用。
首先,在 pom.xml 中添加对应的依赖,例如:
<dependency><groupId>com.github.pagehelper</groupId><artifactId>pagehelper-spring-boot-starter</artifactId><version>1.4.1</version></dependency>
接下来,在 application.properties 中添加一些设置,常用的设置如表 7-11 所示,表中属性的默认值均为 false。我们无须手动设置分页要用到的语法,因为 PageHelper 会自动进行侦测。
表 7-11 PageHelper 在 Spring Boot 中的一些设置
| 配置项 | 说明 |
|---|---|
pagehelper.offsetAsPageNum | 在使用 RowBounds 作为分页参数时,将 offset 作为页码 |
pagehelper.rowBoundsWithCount | 在使用 RowBounds 作为分页参数时,也会执行 count 操作 |
pagehelper.pageSizeZero | 如果分页大小为 0,则返回所有结果 |
pagehelper.reasonable | 合理化分页,传入的页码小于等于 0 时返回第一页,大于最大页时返回最后一页 |
pagehelper.supportMethodsArguments | 从方法的参数中获取分页所需的信息 |
下面我们通过几个测试来了解一下 PageHelper 的具体用法。可以通过静态方法 PageHelper.startPage() 设置分页信息,该信息是保存在 ThreadLocal 变量中的,因此操作需要在一个线程中,例如像代码示例 7-29 的单元测试那样,查询第 1 页,每页 1 条记录。
代码示例 7-29 针对分页功能测试的 MenuItemMapperTest 代码片段
@SpringBootTestpublic class MenuItemMapperTest {@Autowiredprivate MenuItemMapper menuItemMapper;@Testpublic void testPagination() {// 不分页List<MenuItem> list = menuItemMapper.findAll();assertEquals(2, list.size());// 分页PageHelper.startPage(1, 1);list = menuItemMapper.findAll();assertEquals(1, list.size());assertTrue(list instanceof Page);PageInfo<MenuItem> pageInfo = new PageInfo<>(list);assertEquals(2, pageInfo.getPages()); // 总页数assertEquals(1, pageInfo.getPageSize()); // 每页大小assertEquals(1, pageInfo.getPageNum()); // 当前页码assertEquals(2, pageInfo.getNextPage()); // 下页页码}}
也可以换种用法,通过 RowBounds 对象或者直接在方法参数中指定分页信息。代码示例 7-30 是修改后的 TeaMakerMapper 的部分相关代码,在代码示例 7-31 中则是对应的使用方法,也是通过单元测试的形式来演示的。
代码示例 7-30 包含分页逻辑的 TeaMakerMapper 代码片段
@Mapperpublic interface TeaMakerMapper {@Select("select * from t_tea_maker")@ResultMap("teaMakerMap")List<TeaMaker> findAllWithRowBounds(RowBounds rowBounds);@Select("select * from t_tea_maker")@ResultMap("teaMakerMap")List<TeaMaker> findAllWithPage(int pageSize, int pageNum);// 省略其他方法}
如果 findAllWithPage() 中的参数使用其他名称,也可以用类似 @Param("pageNum") int pageNum 的方式来指定。
代码示例 7-31 针对 TeaMakerMapper 中分页逻辑的测试代码片段
@SpringBootTestpublic class TeaMakerMapperTest {@Autowiredprivate TeaMakerMapper teaMakerMapper;@Testpublic void testPagination() {List<TeaMaker> list = teaMakerMapper.findAllWithRowBounds(new RowBounds(1, 1));PageInfo<TeaMaker> pageInfo = new PageInfo<>(list);assertEquals(1, list.size());assertEquals(1, pageInfo.getPageNum());assertEquals(1, pageInfo.getPageSize());assertEquals(2, pageInfo.getPages());list = teaMakerMapper.findAllWithPage(1, 2);pageInfo = new PageInfo<>(list);assertEquals(2, pageInfo.getPageNum());assertEquals(1, pageInfo.getPrePage());assertEquals(0, pageInfo.getNextPage()); // 没有下一页}}
为了能够正确地运行上面的程序,还需要在 application.properties 文件中增加如下的一些配置:
pagehelper.offsetAsPageNum=truepagehelper.rowBoundsWithCount=truepagehelper.supportMethodsArguments=true
-
一站式的 MyBatis Plus
如果觉得又是生成器又是插件,写个东西要好几个工具配合特别麻烦,MyBatis 社区里也有一站式工具提供给大家。以国人开发的 MyBatis Plus 为例,它在 MyBatis 的基础上又增加了一些额外的功能,原生功能可以和扩展功能一起使用,例如:
- 提供支持通用增删改查功能的
Mapper; - 内置代码生成器;
- 内置分页插件;
- 支持 ActiveRecord 形式的操作。
在 MyBatis Plus 的帮助下,MyBatis 的开发体验可以接近于 Spring Data JPA,即只需要定义 POJO 类,再定义一个扩展了 BaseMapper<T> 的接口就能执行常规操作了,但还不能直接通过定义方法然后根据方法名进行扩展操作。
MyBatis Plus 也提供了自己的 Spring Boot Starter,只需在工程的 pom.xml 中增加如下依赖,就能引入 MyBatis Plus、MyBatis 和 MyBatis Spring 的依赖。
<dependency><groupId>com.baomidou</groupId><artifactId>mybatis-plus-boot-starter</artifactId><version>3.5.1</version></dependency>
这个 Starter 中的部分类是从 MyBatis Spring Boot Starter 里复制过来的,同时稍作调整,例如将配置项的前缀调整为 mybatis-plus,像下面这样:
mybatis-plus.type-handlers-package=learning.spring.binarytea.support.handlermybatis-plus.type-aliases-package=learning.spring.binarytea.modelmybatis-plus.configuration.map-underscore-to-camel-case=true
对于像 MenuItem 这样的简单对象,只需代码示例 7-33 中的接口就可以完成基本操作的映射。但由于我们的类名和表名不相同,所以还是需要在模型类上添加 @TableName("t_menu") 注解来声明一下,就像代码示例 7-32 那样。
代码示例 7-32 MenuItem 类的定义
@Builder@Data@AllArgsConstructor@NoArgsConstructor@TableName("t_menu")public class MenuItem {...}
代码示例 7-33 的接口包含了一个自定义的方法,映射关系的写法就是原生的方式。
代码示例 7-33 MenuItemMapper 接口的定义
public interface MenuItemMapper extends BaseMapper<MenuItem> {@Select("select m.* from t_menu m, t_order_item i where m.id = i.item_id and i.order_id = #")List<MenuItem> findByOrderId(Long orderId);}
接下来,我们仍然通过一个简单的单元测试来演示 MenuItemMapper 的用法。具体如代码示例 7-34 所示,其中包含统计数量、根据主键查找以及全量加载的演示。
代码示例 7-34 基本的查询方法测试用例
@SpringBootTestpublic class MenuItemMapperTest {@Autowiredprivate MenuItemMapper menuItemMapper;@Testpublic void testSelect() {assertEquals(2, menuItemMapper.selectCount(null));MenuItem item = menuItemMapper.selectById(1L);assertEquals(1L, item.getId());assertEquals("Java咖啡", item.getName());assertEquals(Size.MEDIUM, item.getSize());assertEquals(Money.ofMinor(CurrencyUnit.of("CNY"), 1200), item.getPrice());List<MenuItem> list = menuItemMapper.selectList(null);assertEquals(2, list.size());}// 省略其他方法}
MyBatis Plus 的 BaseMapper<T> 中带有分页的查询方法,但还需要配置分页插件才能完全发挥它的功能。在 Spring Boot 的配置类中增加如下 Bean,其中的 PaginationInnerInterceptor 就是分页插件,在早期的版本中也可以通过配置独立的 PaginationInterceptor 实现相同的功能:
@Beanpublic MybatisPlusInterceptor mybatisPlusInterceptor() {MybatisPlusInterceptor mybatisPlusInterceptor = new MybatisPlusInterceptor();mybatisPlusInterceptor.addInnerInterceptor(new PaginationInnerInterceptor());return mybatisPlusInterceptor;}
对应的测试代码如代码示例 7-35 所示,其中指定了按照 id 升序,每页 1 条记录,查询第 1 页。
代码示例 7-35 分页测试代码
@Testpublic void testPagination() {Page<MenuItem> page = menuItemMapper.selectPage(new Page<MenuItem>(1, 1).addOrder(OrderItem.asc("id")), null);assertEquals(1, page.getCurrent());assertEquals(1L, page.getRecords().get(0).getId());assertEquals(1, page.getRecords().size());assertEquals(2, page.getTotal());}
7.3 小结
数据库操作是大家日常工作中一定会遇到的操作,本章我们一同学习了流行的 Hibernate 和 MyBatis 在 Spring 项目中的用法。在介绍 Hibernate 时,除了讲解它本身如何与 Spring 结合,我们还说明了 Spring Data JPA 的 Repository 接口该如何使用,它那种通过方法名称就能定义操作的方式着实让人眼前一亮。在 MyBatis 的部分,也是一样的,除了其本身的用法,还介绍了几个让 MyBatis 如虎添翼的工具。
下一章,我们将一起了解一些与数据操作相关的进阶内容,有与连接池相关的点,也有与缓存相关的点,非常贴近实战需要。
二进制奶茶店项目开发小结
本章我们为二进制奶茶店完善了订单相关的操作,主要是定义了调茶师与订单的模型类,并添加了对应的增删改查操作。这从功能上来说并不复杂,但是在实现方式上,我们先后尝试使用了四种不同的方式,分别是 Hibernate 原生方式、Spring Data JPA Repository 接口、MyBatis 原生方式与 MyBatis Plus 扩展。