一、简述
论文《神经语言模型的缩放定律》包含对交叉熵损失的语言模型性能的经验缩放定律的研究,重点关注Transformer架构。
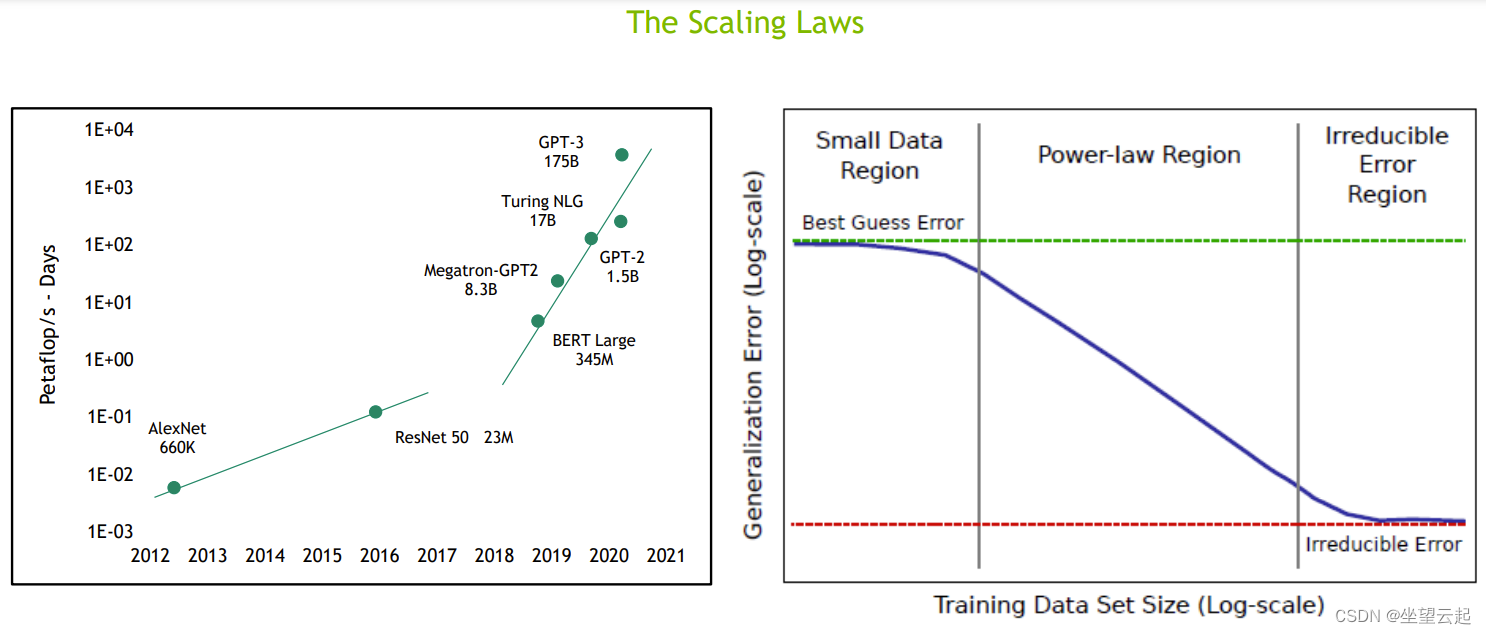
https://arxiv.org/pdf/2001.08361.pdf![]() https://arxiv.org/pdf/2001.08361.pdf 实验表明,测试损失与模型大小、数据集大小和用于训练的计算量呈幂律关系,某些趋势跨越超过七个数量级。这意味着简单的方程控制着这些变量之间的关系,这些方程可用于创建最有效的训练配置,以训练非常大的语言模型。此外,网络宽度或深度等其他架构细节似乎在很大范围内影响甚微。
https://arxiv.org/pdf/2001.08361.pdf 实验表明,测试损失与模型大小、数据集大小和用于训练的计算量呈幂律关系,某些趋势跨越超过七个数量级。这意味着简单的方程控制着这些变量之间的关系,这些方程可用于创建最有效的训练配置,以训练非常大的语言模型。此外,网络宽度或深度等其他架构细节似乎在很大范围内影响甚微。
从实验和推导的方程可以看出,更大的模型具有更高的样本效率,即最佳计算效率训练涉及在相对适量的数据上训练非常大的模型,并在收敛之前显著停止。
二、实验
为了研究语言模型的扩展,人们利用不同的因素训练了各种模型,包括:
- 模型大小(N):大小范围从 768 到 15 亿个非嵌入参数。
- 数据集大小(D):范围从 2200 万到 230 亿个标记。
- 模型形状:包括深度、宽度、注意头、前馈维度。
- 上下文长度:大多数运行为 1024,但也有一些实验使用较短的上下文。
- 批次大小:大多数运行的批次大小为 2^19,但有一些变化来衡量临界批次大小。以临界批次大小进行训练可在时间和计算效率之间实现大致最佳的折衷。
我们还定义以下训练变量:令L为测试交叉熵损失。令C为训练模型所使用的计算量。
三、主要发现
- 性能在很大程度上取决于模型规模,而与模型形状的关系较弱:模型性能在很大程度上取决于规模,它由三个因素组成:模型参数数量N(不包括嵌入)、数据集大小D以及用于训练的计算量C。在合理的范围内,性能对其他架构超参数(例如深度与宽度)的依赖性非常弱。
- 平滑幂律:当不受其他两个因子的瓶颈影响时,性能与三个比例因子N、D、C中的每一个都具有幂律关系,趋势跨越六个数量级以上。
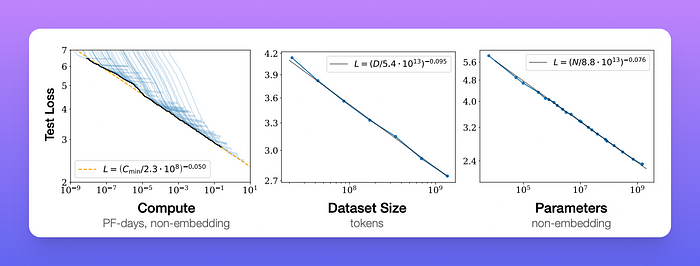
随着我们增加用于训练的计算量、数据集大小和模型大小,语言建模性能会平稳提升。为了获得最佳性能,必须同时扩大这三个因素。
论文区分了嵌入参数和非嵌入参数,因为它们的大小与模型性能的相关性不同。当包含嵌入参数时,性能似乎除了参数数量外,还在很大程度上取决于层数。当排除嵌入参数时,不同深度的模型的性能会收敛到单一趋势。
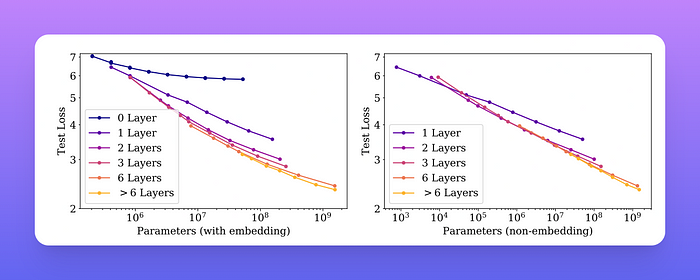
左图:当包含嵌入参数时,性能似乎除了参数数量外,还在很大程度上取决于层数。右图:当排除嵌入参数时,不同深度的模型的性能收敛到单一趋势。
- 过度拟合的普遍性:只要我们同时扩大N和D ,性能就会可预测地提高,但如果N或D保持不变而另一个增加,就会进入收益递减的阶段。
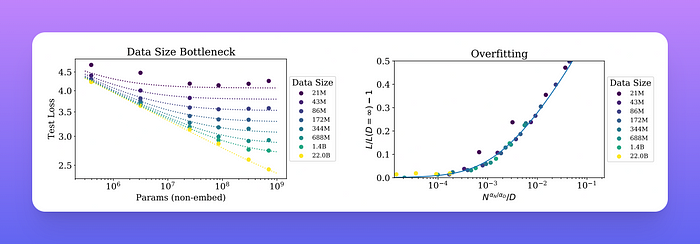
早期停止测试损失可预测地取决于数据集大小 D 和模型大小 N。左图:对于较大的 D,性能是 N 的直接幂律。对于较小的固定 D,随着 N 的增加,性能停止改善,模型开始过拟合。右图:过拟合的程度主要取决于 N 和 D 之间的关系。
- 训练的普遍性:训练曲线遵循可预测的幂律,其参数大致与模型大小无关。通过推断训练曲线的早期部分,可以粗略地预测如果训练更长时间将产生的损失。
- 样本效率:大型模型比小型模型具有更高的样本效率,可以用更少的优化步骤和使用更少的数据点达到相同的性能水平。
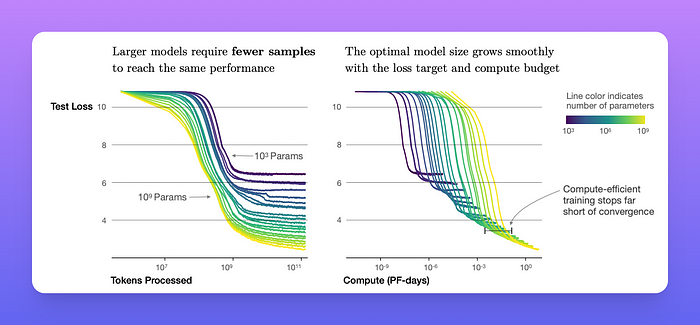
一系列语言模型训练运行,模型大小从 10^3 到 10^9 个参数(不包括嵌入)。
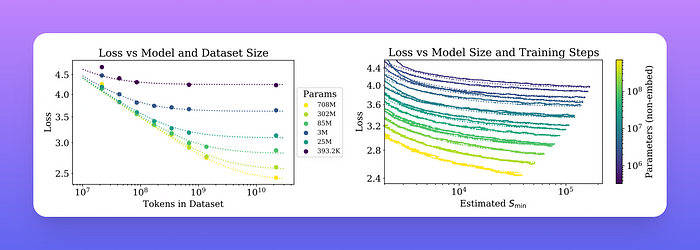
左图:早期停止测试损失 L(N, D) 随数据集大小 D 和模型大小 N 可预测地变化。右图:在初始过渡期之后,当以大批量进行训练时,所有模型大小 N 的学习曲线都可以用以步数 (Smin) 为参数的方程拟合。
- 收敛效率低下:在固定的计算预算C内工作,但没有对模型大小N或可用数据D进行任何其他限制时,我们通过训练非常大的模型并在收敛前明显停止来获得最佳性能。
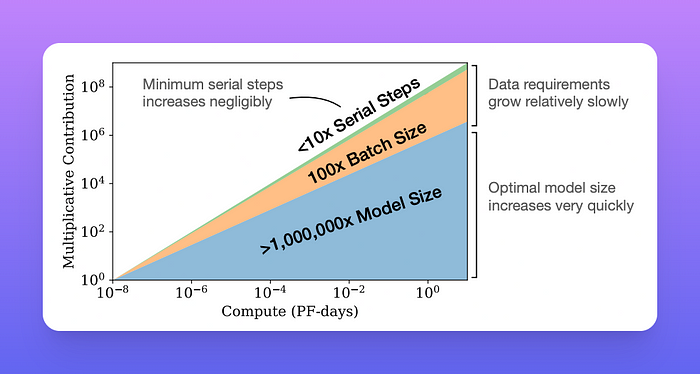
随着可用的计算能力不断增强,可以选择将多少资源分配给训练更大的模型、使用更大的批次以及训练更多步骤。此图说明了计算能力增加十亿倍的情况。为了实现计算效率最高的训练,大部分增加的资源应该用于增加模型大小。需要相对较少的数据增加以避免重复使用。在增加的数据中,大部分可用于通过更大的批次大小来增加并行性,而只需要非常小的增加串行训练时间。
综合这些结果表明,随着我们适当扩大模型规模、数据和计算能力,语言建模性能会平稳且可预测地提高。相反,我们发现对许多架构和优化超参数的依赖性非常弱。预计更大的语言模型将比当前模型表现更好,样本效率更高。
四、结论和后续步骤
在训练大型语言模型时,可以使用N、D和L之间的关系来推导计算缩放、过度拟合的程度、早期停止步骤和数据要求。
导出的缩放关系可用作预测框架。人们可能将这些关系解释为理想气体定律的类似物,该定律以通用方式关联气体的宏观属性,而不受其微观成分的大多数细节影响。
研究这些缩放关系是否适用于具有最大似然损失的其他生成建模任务,以及是否也适用于其他设置和领域(例如图像、音频和视频模型)将会很有趣。
在本文中,我们了解了语言模型性能与模型大小、模型形状和计算预算之间的关系。这些关系可用于推导出我们想要训练的固定大型语言模型的最佳效率计算预算,反之亦然,用于在给定固定计算预算的情况下推导出最佳效率模型(就模型大小和形状而言)。



![AGI 之 【Hugging Face】 的[ 简单介绍 ] [ 基础环境搭建 ] 的简单整理](https://img-blog.csdnimg.cn/direct/9f624d07d38a49028669c41f0115ac0a.png)



![[C++][数据结构][B-树][下]详细讲解](https://img-blog.csdnimg.cn/direct/0090930d3c0c4f86afd9d12bf4f871f7.png)