1.数据集
现实生活中遇到的问题
- 车牌识别
- 身份证号码识别
- 快递单的识别
都会涉及到数字识别
MNIST(收集了很多人手写的0到9数字的图片)
- 每个数字拥有7000个图像
- train/test splitting:60k vs 10k

图片大小28 × 28
数据集划分成训练集和测试集合的意义:如果全部用来训练,就会造成模型学习的很好,会造成一个假象,实质是对图片的一个记忆,对于新给的一些照片该模型可能会表现不佳
主要问题:如何把手写数字的识别和简单线性回归模型结合?
对于简单线性回归问题实质是找出一组最优的w和b使得预测值和实际值相近
问题1:对于一组图片来说x是什么?
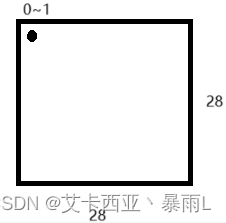
图片的表示方法,灰度图片为例子,可以理解为[28,28]的数组,可以用一个维度的向量[1,784]来表示,即一个图片可以用一个向量来表示。
对于手写数字识别来说,只使用一个简单的线性回归模型很难实现预测,所以使用三个线性函数的嵌套
X = [ v 1 , v 2 , . . . , v 784 ] X=[v1,v2,...,v784] X=[v1,v2,...,v784]
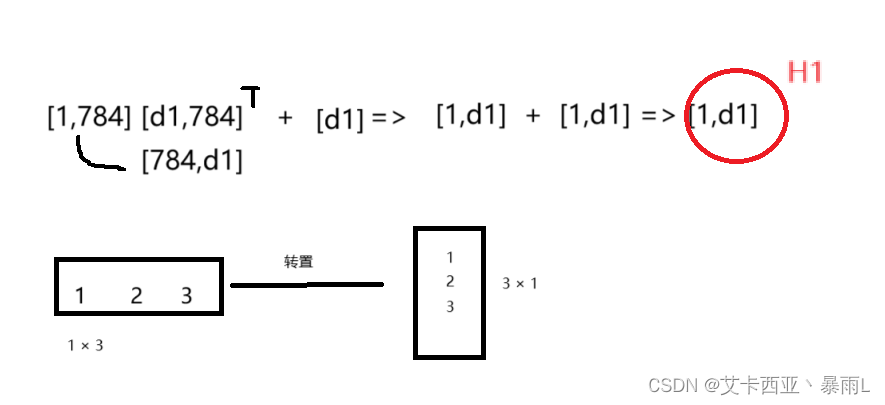
- X:[1,dx]
H 1 = X ∗ W 1 + b 1 H_{1}=X*W_{1} +b_{1} H1=X∗W1+b1
- W1:[d1,dx]
- b1:[d1]
H 2 = H 1 ∗ W 2 + b 2 H_{2}=H_{1}*W_{2} +b_{2} H2=H1∗W2+b2 - W2:[d2,d1]
- b2:[d2]

H 3 = H 2 ∗ W 3 + b 3 H_{3}=H_{2}*W_{3} +b_{3} H3=H2∗W3+b3
- W3:[10,d2]
- b3:[10]
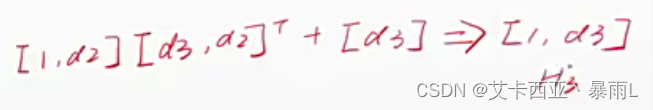
问题2:如何计算Loss?
- H3:[1,d3]
- Y:[0/1/…/9]
- eg.:1=>[0,1,0,0,0,0,0,0,0,0]
- eg.:3=>[0,0,0,3,0,0,0,0,0,0]
- Euclidean Distance: H 3 H_{3} H3 vs Y
要计算Loss,首先要知道H3作为最后的输出,它要如何表达我们想要表达的label信息呢
因为label是0~9,那就用一个维度来表达这个输出到底是哪个label,因此H3输出可以变成[1,1]第一个1表示的是照片数量,第二个1表示的是0到9的一个数字 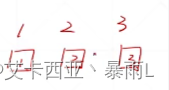
对于图片来说,label是1或者是2是没有任何相关性的,但是如果把label编码成1,2,3的话就会存在1<2<3,这样的数字之间的关系,因此这种方式不是适合于label的编码。
另一种编码方式是one-hot编码方式,比如label为1的照片把它展开成全部都是0的10维(10取决于类别总数)的向量,如果label是1就把第二个位置变成1,如果label是3的话就把第4个位置变成3,这样label1和label3就没有1<2<3这样的大小关系了
总结
- p r e d = W 3 ∗ { W 2 [ W 1 X + b 1 ] + b 2 } + b 3 pred = W_3 *\{W_2[W_1X+b_1]+b_2\}+b_3 pred=W3∗{W2[W1X+b1]+b2}+b3
- Linear Combination?
pred不采用0~9的数字来表示,而是用包含10维向量表示,会与真实的y做一个差,优化这个差来找到最优解
有一个很小的问题
每一个模型都是线性的,即使通过嵌套来增强表达能力,但总体的模型还是线性模型,对于一个手写数字来说比如1(会有各种各样的倾斜、字体、大小,以及各种各样的噪声)人之所以可以识别为1,因为人脑具有很强的非线性的表达能力,对于一个线性模型来说很难完成手写数字体识别这种现实生活中遇到的简单的问题的(因为手写数字体具有非线性性),我们可以在每个函数之后添加一个非线性的部分来解决这个问题。
这个非线性性的部分是怎么来的呢?
来源于生物学的神经元,神经元有多个输入,一个输出,输出不是输入简单的线性求和,而是有一个阈值,当输入非常小的时候输出可能是0,输入在一个范围内就会有一个线性变化关系,输入很大时,输出也不会变得很大,会慢慢趋于平稳。
非线性因子
- ReLu(梯度很好计算,不是0就是1)
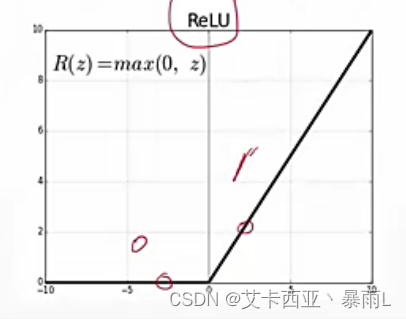
- H 1 = r e l u ( X ∗ W 1 + b 1 ) H_{1}=relu(X*W_{1}+b1) H1=relu(X∗W1+b1)
- H 2 = r e l u ( H 1 ∗ W 2 + b 2 ) H_{2}=relu(H_{1}*W_{2}+b2) H2=relu(H1∗W2+b2)
- H 3 = f ( H 2 ∗ W 3 + b 3 ) H_{3}=f(H_{2}*W_{3}+b3) H3=f(H2∗W3+b3)
Gradient Descent
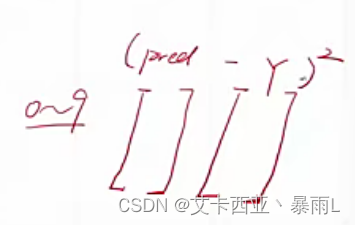
- l o s s = ∑ ( p r e d − Y ) 2 \mathrm{loss}=\sum(pred -Y)^2 loss=∑(pred−Y)2
- minimize loss
- [ W 1 , W 2 , W 3 ] [W_{1},W_{2},W_{3}] [W1,W2,W3]
- [ b 1 , b 2 , b 3 ] [b_{1},b_{2},b_{3}] [b1,b2,b3]
目的:找得一组w,b使得预测的值越接近真实y,loss越小越好
这里的w和b不在是具体的一个值,而是由三组参数构成的,分别来自三个非线性模型(加了relu的)
这三组参数求得以后三如何做预测?
- 新的X,在train中没有见过的
- 把X送到包含激活函数的预测函数里面(这里没写出来激活函数,但实际是有的) p r e d = W 3 ∗ { W 2 [ W 1 X + b 1 ] + b 2 } + b 3 pred = W_3 *\{W_2[W_1X+b_1]+b_2\}+b_3 pred=W3∗{W2[W1X+b1]+b2}+b3得到一个pred的值,是[1,10]这样的一个向量
- argmax(pred)
max = 0.8
argmax = 1 (0.8这个值所对应的索引号)
label = 1作为预测的值
2. 实战
步骤
- 加载图片
- 建立模型
- 训练
- 测试
import torch
from torch import nn
from torch.nn import functional as F
from torch import optim
import torchvision
from matplotlib import pyplot as plt
from util import plot_image,plot_curve,one_hot
util类
#!/usr/bin/env python
# encoding: utf-8import torch
from matplotlib import pyplot as pltdef plot_curve(data):"""下降曲线的绘制:param data::return:"""fig = plt.figure()plt.plot(range(len(data)), data, color='blue')plt.legend(['value'], loc='upper right')plt.xlabel('step')plt.ylabel('value')plt.show()def plot_image(img, label, name):"""可视化识别结果:param img::param label::param name::return:"""fig = plt.figure()for i in range(6):plt.subplot(2, 3, i + 1)plt.tight_layout()plt.imshow(img[i][0] * 0.3081 + 0.1307, cmap='gray', interpolation='none')plt.title("{}: {}".format(name, label[i].item()))plt.xticks([])plt.yticks([])plt.show()def one_hot(label, depth=10):"""one_hot编码:param label::param depth::return:"""out = torch.zeros(label.size(0), depth)idx = torch.LongTensor(label).view(-1, 1)out.scatter_(dim=1, index=idx, value=1)return out第一步:加载数据集
GPU性能强大,一次可以处理多张图片,处理一张图片(3ms)和处理100张图片(4ms)相差不大,通过并行处理多张图片,可以大大的节省计算时间,此处设置一次性处理512张图片
torch.utils.data.DataLoader是 PyTorch 库中的一个类,它提供了一种便捷的方式来加载数据集。DataLoader 可以迭代地加载数据集,并且支持多线程加载,这可以显著提高数据加载的效率。
每次迭代返回一对值,分别是
- 数据 (data): 这是一个包含多个样本的批次,通常是张量(tensor)的形式。如果数据集中包含多个特征,data 可能是一个元组(tuple),每个元素对应一个特征的批次。
- 标签 (target 或者 label): 这是与数据相对应的标签或目标值,用于训练或评估模型。标签的格式取决于数据集的类型,可能是标量、向量、张量等。
torchvision.datasets.MNIST指定加载MNIST数据集
- mnist_data:下载后存储的路径(数据会存放到这儿)
- train:指定数据是用来做训练还是预测(70k的图片中有60k是训练数据,10k是预测数据),这个参数决定了下载的是60k还是10k
- download:如果当前mnist_data文件是没有MNIST文件的话会自动从网上下载
- transform:一般来说下载得到的文件是Numpy格式
- ToTensor():我们先把Numpy格式转化为Tensor(torch的数据载体)
- Normalize((0.1307,), (0.3081,):这个正则化过程的意思是用神经网络接收的数据最好是在0附近均匀的分配,但是图片的像素是从0到1的,是一直在0的右侧分布的,我们通过减去0.1307,再除以0.3081,使得数据能够在0附近均匀的分布,更加方便神经网络去优化,这一行可以注释掉(注释掉性能会差)
- batch_size:一次加载多少张图片
- shuffle:设置为True是要将数据做一个随机的打散
train_loader = torch.utils.data.DataLoader(torchvision.datasets.MNIST('mnist_data', train=True, download=True,transform=torchvision.transforms.Compose([torchvision.transforms.ToTensor(),torchvision.transforms.Normalize((0.1307,), (0.3081,))])),batch_size=batch_size, shuffle=True)
# step1 .load dataset
'''GPU性能强大,一次可以处理多张图片,处理一张图片(3ms)和处理100张图片(4ms)
相差不大,通过并行处理多张图片,可以大大的节省计算时间一次处理图片的数量'''
#一次处理图片的数量
batch_size = 512
train_loader = torch.utils.data.DataLoader(torchvision.datasets.MNIST('mnist_data', train=True, download=True,transform=torchvision.transforms.Compose([torchvision.transforms.ToTensor(),torchvision.transforms.Normalize((0.1307,), (0.3081,))])),batch_size=batch_size, shuffle=True)#预测数据集是没必要打散的
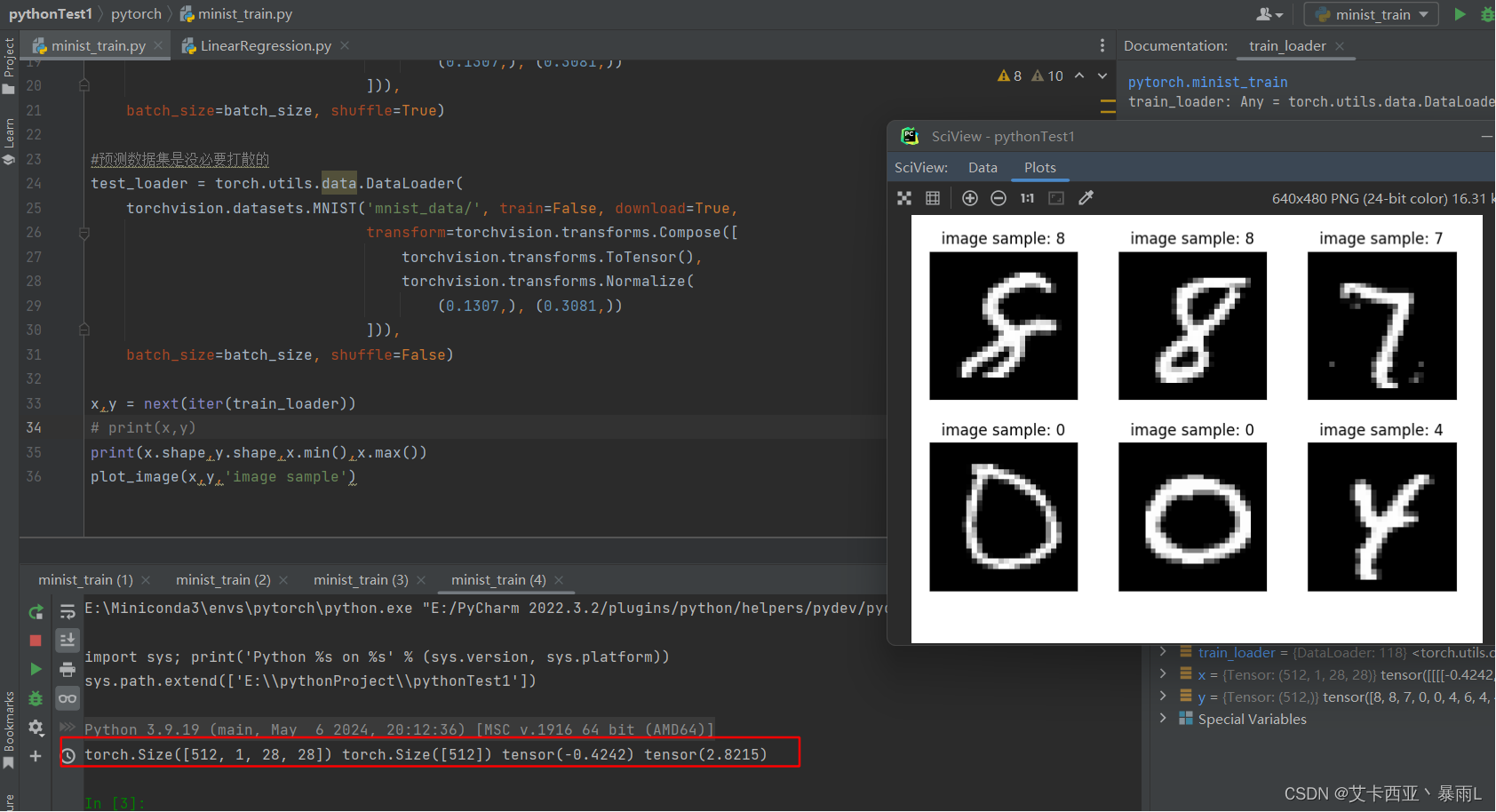
test_loader = torch.utils.data.DataLoader(torchvision.datasets.MNIST('mnist_data/', train=False, download=True,transform=torchvision.transforms.Compose([torchvision.transforms.ToTensor(),torchvision.transforms.Normalize((0.1307,), (0.3081,))])),batch_size=batch_size, shuffle=False)x,y = next(iter(train_loader))
print(x,y)
print(x.shape,y.shape,x.min(),x.max())
plot_image(x,y,'image sample')
第二步:创建网络模型
三层非线性层的嵌套
class Net(nn.Module):def __init__(self):super(Net,self).__init__()# X*W+b# nn.Linear是一个线性层# 输入是28*28=784,输出是256(这个256是随机决定的,一般根据经验)self.fc1 = nn.Linear(28*28,256)# 第二层的输入是第一层的输出,64也是随机决定的self.fc2 = nn.Linear(256,64)# 第三层的输输入是第二层的输出,由于此时是一个10分类问题,所以需要10个输出节点self.fc3 = nn.Linear(64,10)# 计算过程会接收一张图片def forward(self,x):# x:[batch,1,28,28],一共有batch张图片# 第一层实例后面加一个括号会调用第一层的传播 即 h1 = relu(X*W+b1)x = F.relu(self.fc1(x))# h2 = relu(H1*W+b2)x = F.relu(self.fc2(x))# 第三层加不加激活函数取决于具体的任务,我们这里是简单的使用均方差损失来# 做一个十分类,是一个输出概率值,所以可以加一个softmax激活函数(不加也可以,# 取决于经验和具体任务的设定),一般来说分类问题使用softmax和crossEntry# h3 = H2*W+b3x = self.fc3(x)return x第三步:训练
enumerate()函数的基本语法:enumerate(iterable, start=0),其中iterable是要遍历的可迭代对象,start是起始索引,默认为0。如果不指定start参数,那么默认从0开始计数。如果指定了start参数,那么计数将从该值开始。
60k每一组512张图片共有0~117共118组
512 * 117(从0到116共有117组)+ 96 = 60k
#训练:每一次求导然后去更新(梯度下降)
#对整个数据集迭代3次
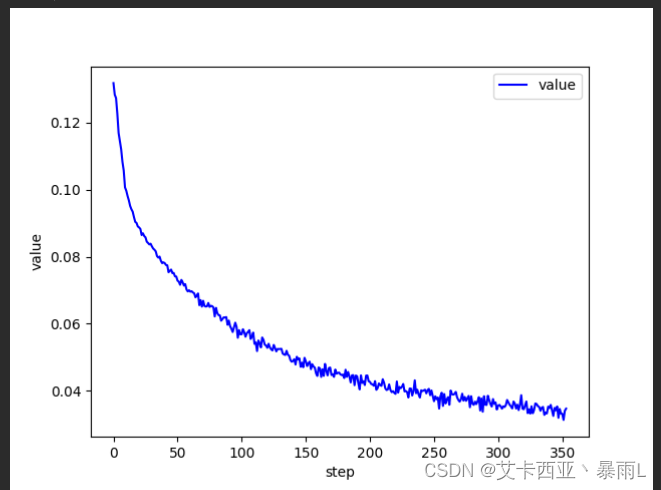
for epoch in range(3):# 每一次从数据集取样一个batch(一个batch是512张图片)# 会将整个数据集60k都取样一次# 即该循环会对整个数据集迭代一遍,一共对数据集迭代了3遍for batch_idx,(x,y) in enumerate(train_loader):# x:[batch,1,28,28],y:[512]# 这个print可以打开看看理解一下# print(batch_idx,x.shape,y.shape)'''net是全连接层且只能接受[batch,feature] 维度等于2的tensor,但是实际的图片x是4维的,所以需要把x 变成 [b,feature]的tensor[batch,1,28,28] => [b,feature] feature = 784把整个图片看成[batch,784]的一个tensor'''x = x.view(x.size(0),28*28)# =>[b,10] 代表了属于每一个类的概率 目的是希望output接近y这个label(即真实值)out = net(x)# 将真实的y转换成一个one-hot [b,10]y_one_hot = one_hot(y)# loss是均方差loss = F.mse_loss(out,y_one_hot)# 清理梯度optimizer.zero_grad()# 计算梯度loss.backward()# optimizer.step() 梯度更新到的W和b中去,该方法会实现梯度下降 即 w' = w - lr * gradientoptimizer.step()# loss是一个tensor数据类型,但train_loss是一个numpy数据类型,所以把item()取出来转化成具体的数值类型train_loss.append(loss.item())# loss的下降趋势,基本上总体的趋势是一直在下降(会有些许上升但影响不大跟learning rate有关)if batch_idx % 10 == 0:print(epoch,batch_idx,loss.item())# 打印损失
plot_curve(train_loss)
损失函数打印
第四步:准确度测试
# 跳出循环之后,即完成了对数据集的迭代后会训练得到一个比较好的参数[w1,b1,w2,b2,w3,b3]
# loss并不是衡量性能的一个指标,只是训练的一个指标,最终的衡量该参数需要用accuracy(准确度)
total_correct = 0
for x, y in test_loader:x = x.view(x.size(0), 28 * 28)# out:[batch,10]out = net(x)# 预测值是从输出向量中间概率最大的那个index# argmax(dim=1) 取维度为1中最大值所在的索引# [batch,10] => [batch]pred = out.argmax(dim=1)# pred.eq(y)会变成一个全是0或1的tensor# 此时correct还是一个tensor类型 要用.item()转化为数值类型correct = pred.eq(y).sum().float().item()# total_correct是总体正确的数量total_correct += correct# test_loader总体的数量
total_num = len(test_loader.dataset)
print(total_num)
# 计算准确度
acc = total_correct / total_num
print('test acc:', acc)x, y = next(iter(test_loader))
out = net(x.view(x.size(0), 28 * 28))
pred = out.argmax(dim=1)
plot_image(x, pred, 'test')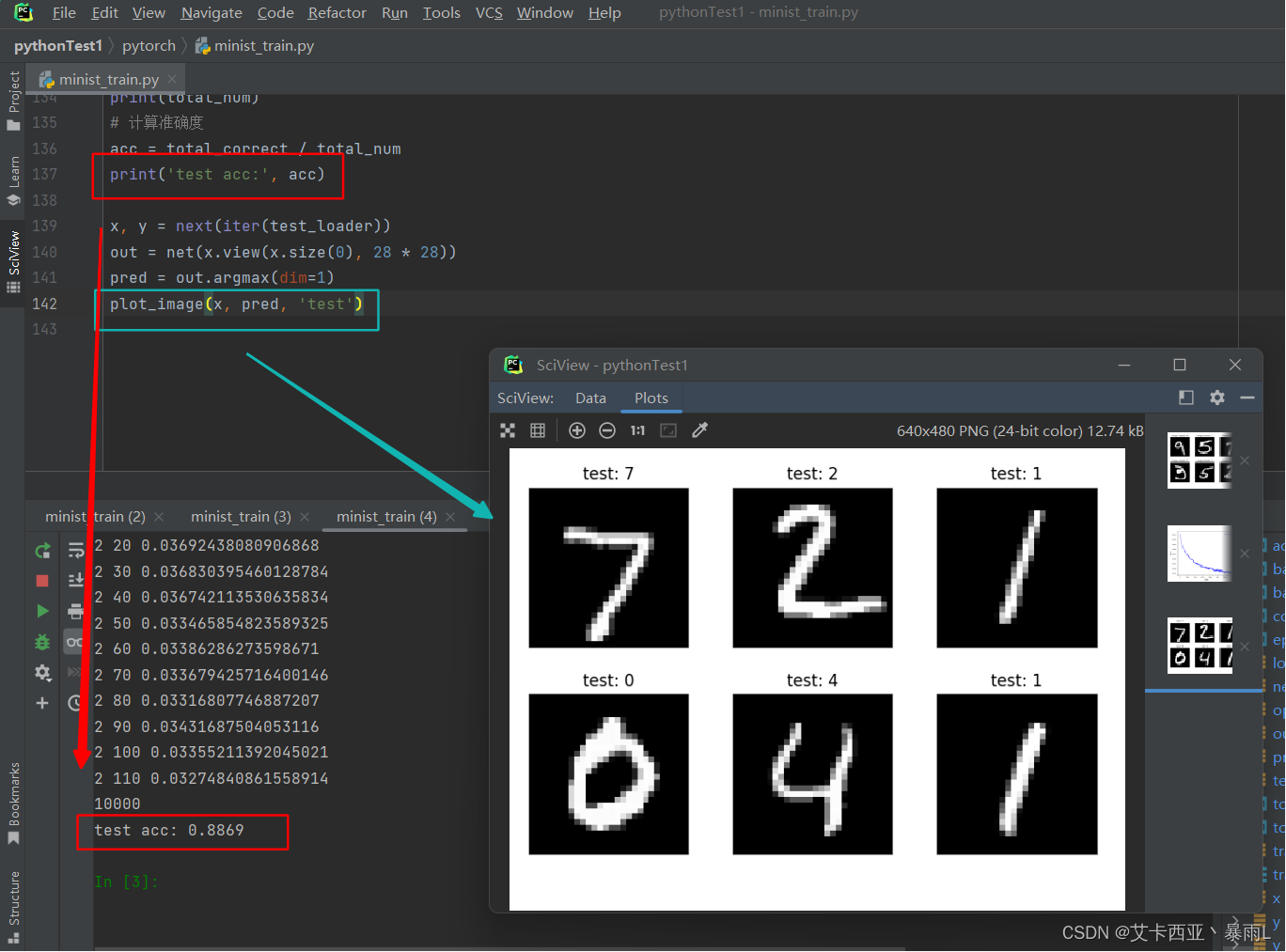
有兴趣可以将3层变成4层,然后第三层输出加softmax函数,loss使用的是均方差也可以用crossEntropy,learning rate也可以去调一调