这个也是一个补充文,前9章基本把该讲的讲了,今天这个内容主要是因为Meta出了一个Chameleon,这个以后可能会成为LLaMA的一个很好的补充,或者说都有可能统一起来,叫LLaMA或者Chamleon或者什么别的,另外我司把Florence的第二个版本开源了,google的paligemma瞬间啥也不是了!
Chameleon 5月16日就发了论文,昨天才正式开源
论文地址:2405.09818 (arxiv.org)
github地址:facebookresearch/chameleon: Repository for Meta Chameleon, a mixed-modal early-fusion foundation model from FAIR. (github.com)
其实现在多模态的模型特别多,为什么拿它出来说事,主要原因是它是目前开源世界里面第一个实现和GPTo一样的架构也就是所有的模态共有一套端到端网络(但是它似乎没全实现,feature deleliver进度上来讲)
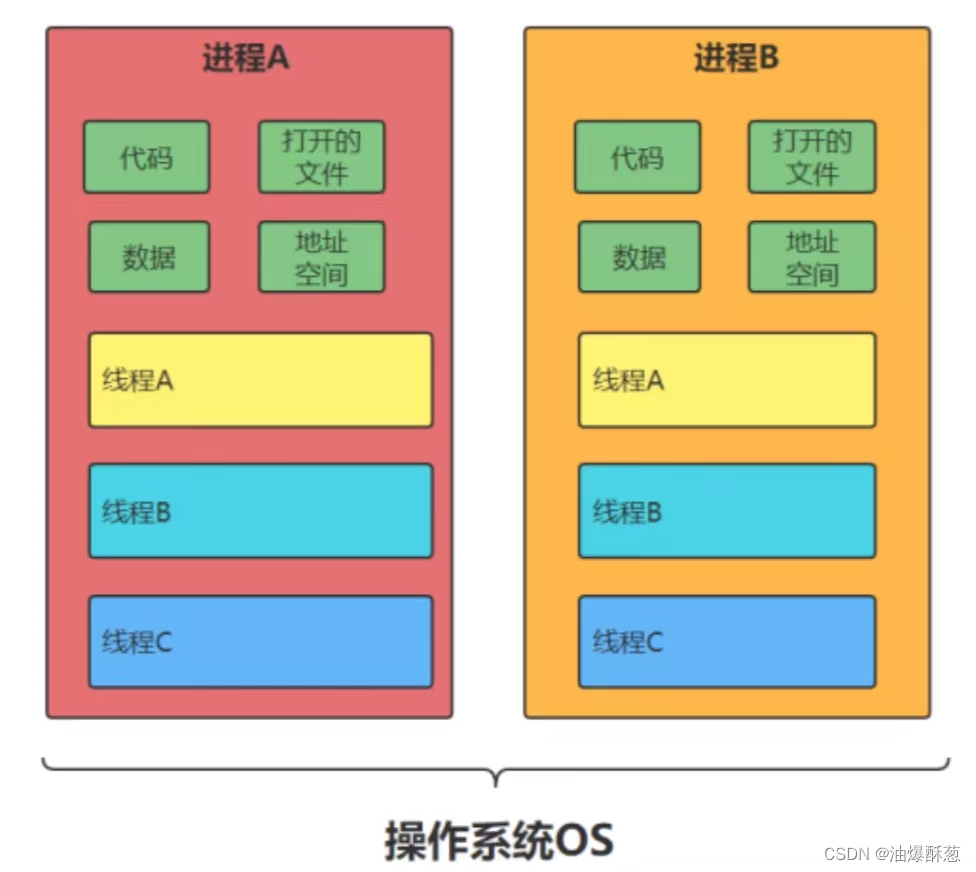
我们先看一个反面教材LLaVA
也不算反面教材吧,市面上大多数的多模态都是这样的,这种方式叫后融合。
怎么理解后融合呢?
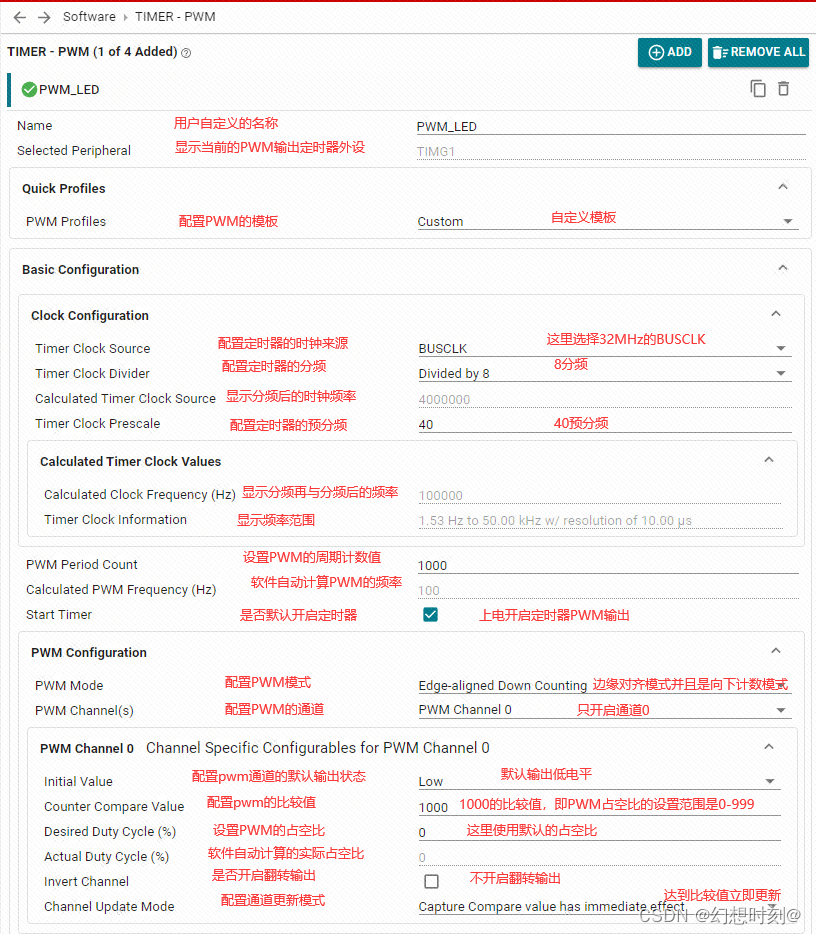
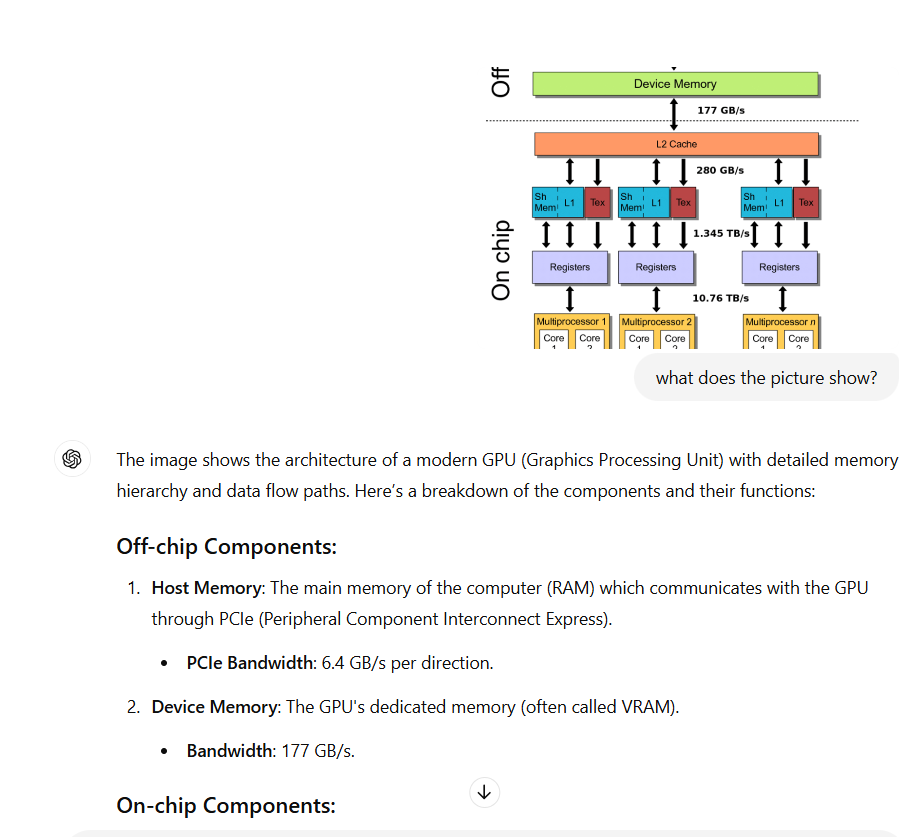
如上图所示是一个实际的LLaVA架构,
根据上面图,我们一起来定义啥叫后融合:
-
视觉编码器与语言模型分开:图中左侧的LLAVA架构将视觉编码器(Vision encoder)和语言模型的encoder(Language model )分开显示,这表明图像和语言的特征提取是独立进行的。(标粗标红)
-
融合在后续步骤进行:在视觉编码器处理完图像生成视觉特征ZvZ_v 后,这些特征通过投影(Projection W)得到视觉特征表示HvH_v(升降维和语言模型的token一个维度比如4096)。然后这些视觉特征𝐻𝑣与语言指令XqX_q被tokenizer给embedding出来的 HqH_q在语言模型的LLaMA里面训练,这就叫后融合(Late Fusion)。
-
其实还是LLM:最后的训练其实还是LLM的训练模式,即把把视觉转换的语言维度的token和语言的token都当成语言token,本质上还是LLM的训练机制,然后你生成的东西其实也只有语言这种任务,说白了只能做VQA
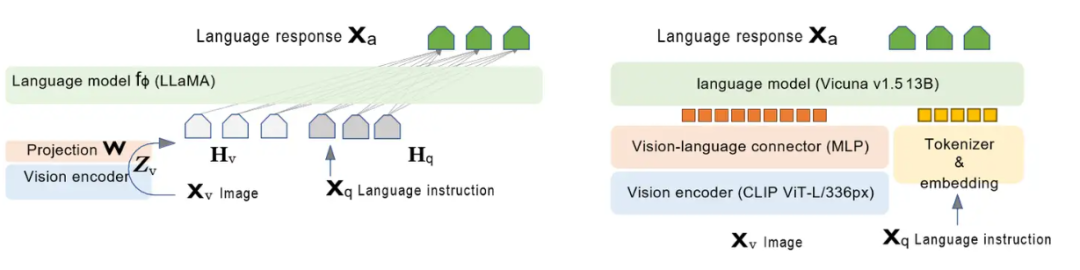
那啥叫前融合?
其实做的比较早的是Gemini,所谓前融合通俗易读点,就是我不需要先让每个模态的encoder去提取自己的特征向量,然后再拉齐,就一套tokenizer干所有的事,啥都被我embedding成token,(也不用比如拿cv的特征图再给转)我也不管它是什么输入,然后统一进transformer(这里面肯定是VIT+DIT了)
Chameleon是同源架构,但是比Gemini做的更甚一些,因为Gemini的视觉的decoder是跟其他的没啥关系的,说白了,在视觉部分,比如video,picture啥的,它还得独立路由到单独的模型生成,Chameleon是完全的端到端但是没做完,这个版本的模型是不支持的


我是连测带问才知道的,所以说你们不能光看论文,你得上手啊,老铁!
讲到这估计大家可能对前融合后融合还是有点理不清,那看我下面的截图应该能明白了。
比如对于和Llava架构差不多的phi3-V,你去查它的tokenizer
就是还是text的,也只针对text的。
视觉的token实际还是视觉的组件来管理和处理(开源大多用clip其实是用里面的vit),只不过被一个线性层或者MLP给硬拉到语义token的维度

但是再看看Chameleon的tokenizer,一些奇怪的东西就出现了
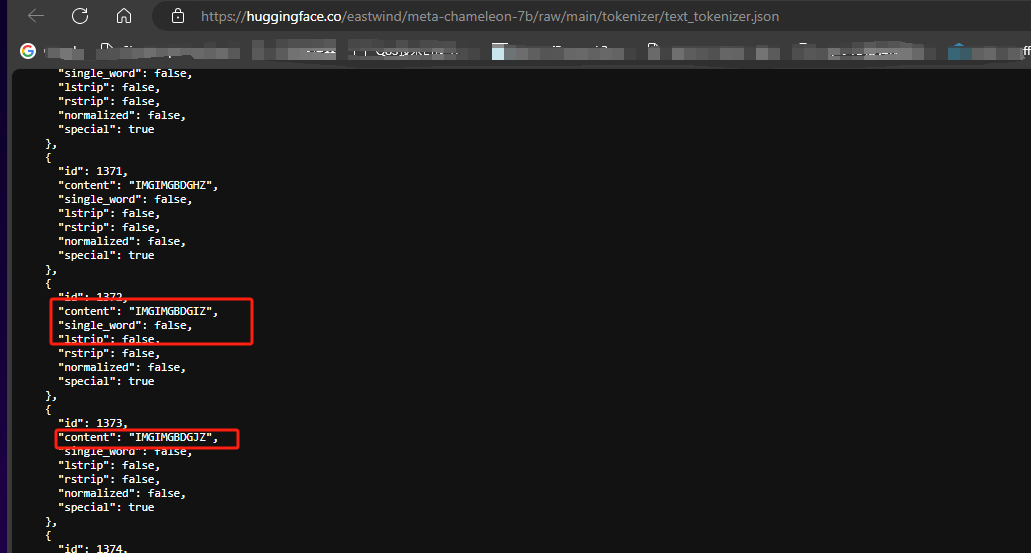
没错,就是它的tokenizer已经不是纯语言的了,视觉(现在只有图片),也是直接被同一个tokenizer来处理的,但是干活的时候还得由视觉的encoder来干,它用的vq-gan

VQGAN的作用:
-
图像编码:
-
VQGAN使用卷积神经网络(CNN)将输入图像分解成小块(patches)。
-
这些小块被进一步编码为一组离散的tokens,通过向量量化(Vector Quantization)将连续的特征映射到预定义的代码簇(codebook)。
-
-
图像生成(现在做不了):
-
在生成过程中,VQGAN可以将这些离散tokens解码回图像。
-
-
结合多模态任务:
-
在多模态任务中(如图像-文本联合建模),VQGAN可以用来将图像数据表示为离散的tokens,这些tokens可以与文本tokens(原生就全是token,不用硬去拉齐维度)一起输入到一个联合模型中进行处理,如Transformer架构中。
-
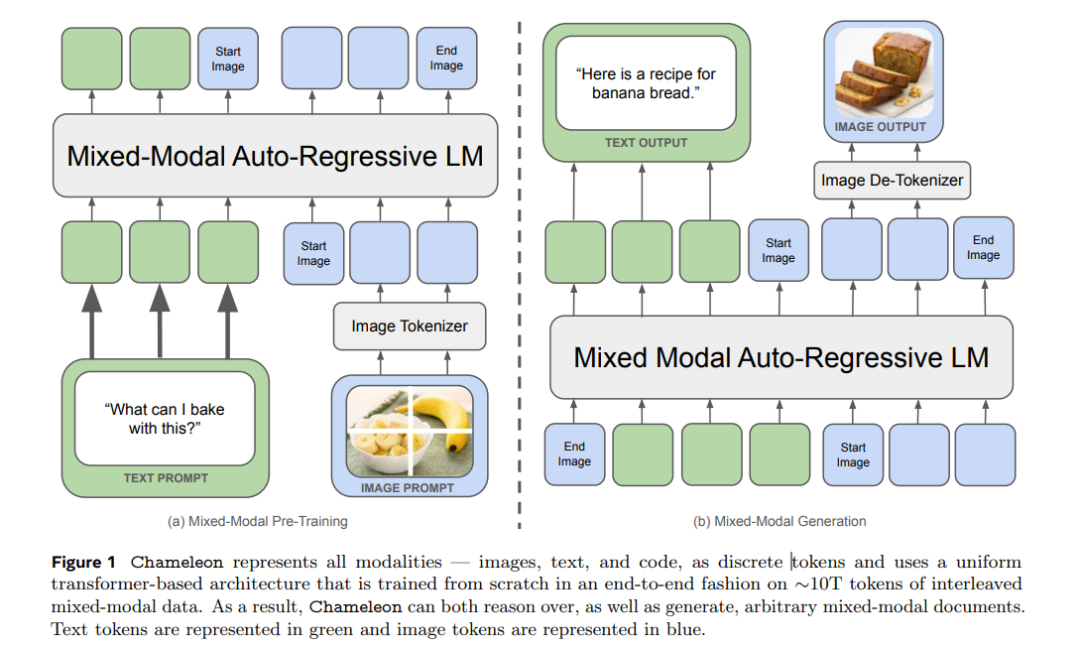
为什么要这么做呢?因为大家知道所有的特征提取以后,是有自己的表征空间的,后融合比如llava,它就是自己玩自己的,然后强行拉到一个空间,这倒也行,也能训练,但是我们人类在接触信息的时候,是怎样的多模态呢?
那肯定是全编全解,比如你一边看电视一边聊微信,所有模态是一起进到你大脑来处理的,你一定有多个encoder,比如眼睛,耳朵,但是你不太可能有多个tokenzier,不同的模态天然在人类里面就是在一个表征空间里被表示的,也就是前融合。
对于模型来讲,在一个表征空间里也以为着进入到Transformer层训练天然能学到不同模态的一些关联信息,那效果自然是要比分着来,然后硬拉到一个维度好,因为每次tensor变形,实际上都是折损。
在帮着修了一个VQA的bug以后,体验了一下现阶段的进展,当然现阶段其实还是原型期,多模态也就做到VQA的级别,有几点可以说一下。
1- 没用任何现行的推理框架,但是真的超级快(我挺期待这部分的一些后续信息披露)
2- 不支持中文
3- VQA任务表现我个人觉得一般,可能也是新模型语料上也没充分准备,微调也不够,皮卡丘它都不认识

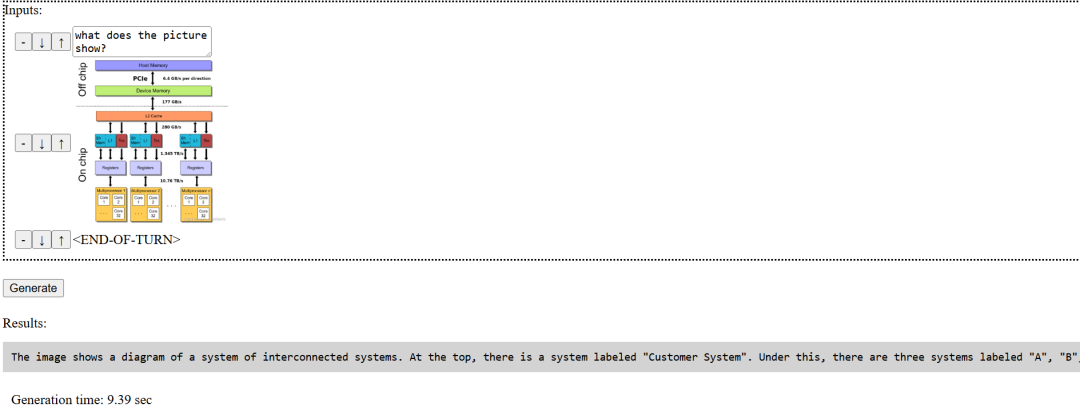
如下面的例子所示,同样的任务在同源模型GPT4o上执行简直天差地别,当然你可以说它小,这个我不反对,我也不否认它的方式一定代表多模态的未来。但是它出来的过于高调了,宣称出道即和GPT4o的多模态能力平起平坐,这个纯扯淡了目前,属于是。(其实phi3-V目前它也比不了,我就是懒得开机器了)
当然还有很多具体的训练和模型的设计细节,例如文本的表征token,这玩意是离散的,而图像的表征,天生是连续的。
为了支持这些它在具体模型上也做了一些调整,一个关键的引入是QK-norm,这个到也常见,就是进softmax之前的QK值归一化一下,这样就防止了不稳定,防止梯度爆炸和消失
至于drop-out最后的结论似乎是加不加就那么回事。
这里有个trick,在7b的模型下面,QK-norm能显著的解决了不稳定,但是34b白扯,所以又把layer-norm给后撤了

其实这个就是swin Transformer的思想,具体来说,在transformer模块中使用了后撤LN的策略。Swin transformer规范化策略的优点在于,它可以限制前馈模块norm growth,而前馈即FFN,或者叫MLP模块的norm growth在SwiGLU激活函数的倍增效应下可能会变得非常麻烦。说白了就是给你MLP的时候就后撤步的norm一下,这样MLP拿到的值就小,好控制。
Chameleon我目前看不完美,还得进化,不过因为它是第一个把商用多模态的思路引入开源的小模型,(Meta就故意的,总整这事,因为小,所以玩的人多,自然就开源翘楚了,这个策略,屡试不爽)它和LLaMA一样,会成为一个开源世界的里程碑,这个到是应该按着剧本写的。
下面介绍一下我司新开源的模型Florence-2
如果我没记错,1没开源(我说错了的话,请纠正我),2突然就开了,也莫名其妙,简单说它就是比google的paligemma强很多倍的多CV任务的多模态。
什么是多CV任务呢?
其实你们现在玩的这种有一个算一个只能算是VQA任务。就是你问它图是啥,它回答一下,但是在CV计算机视觉领域,这只是一个很小的分支,比如你让GPT4o你说你把图给我分割一下,然后打框,对象检测啥啥的,它都干不了。
论文地址:2311.06242 (arxiv.org)
我为啥说它牛B呢
-
它和Chameleon不一样,它不是前融合,这个理论上来说是减分项
-
弱点就是只能做图文,且不能生成(其实chameleon现在也就这个进度)
-
但是!
-
它能做好几个CV任务,你能想到的它都能做
-
然后最大的才0.77b....
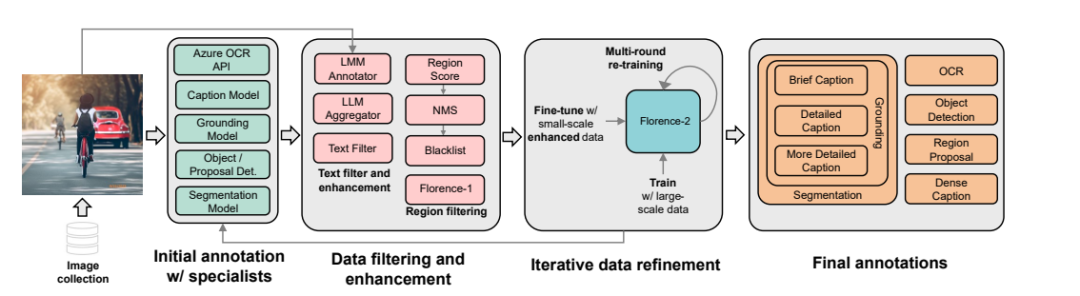
然后它的数据优化流程和反复训练的流程,其实某种程度上有点像NV的Nemotron-4 ,从时间线的角度上来讲,是Nemotron-4学它,毕竟它是先出的,就是没开源
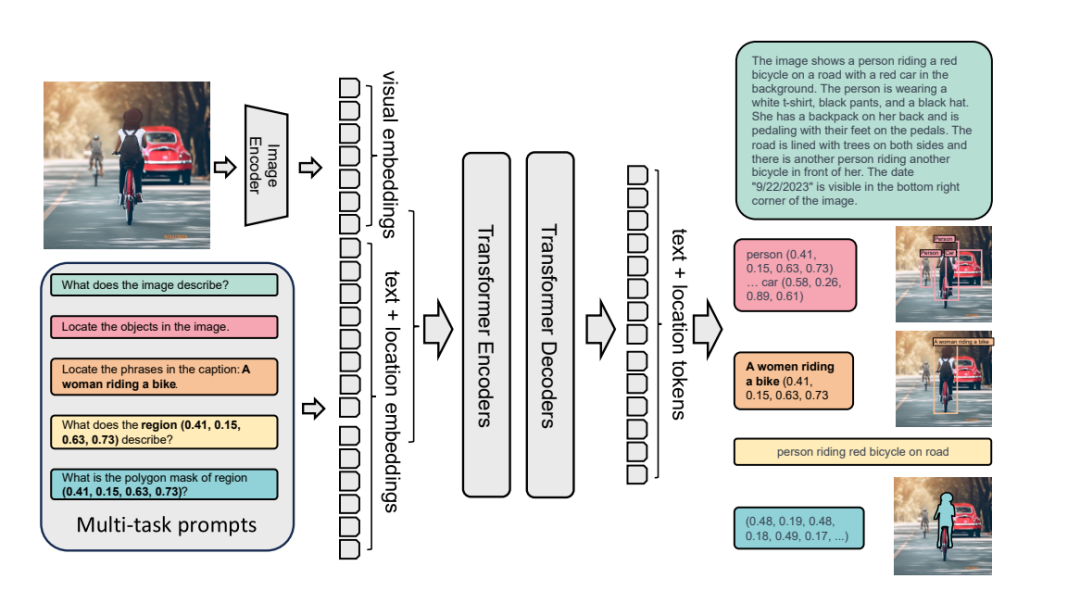
它训练的时候本来就是多任务的prompts,恨不得把一张图能干的事都给榨干,比如下面的
1-标准VQA

2- Visual Granding

3- Dense Region Caption(从这就开始上强度了)

4- 开放词随便问的OD(比泛化)
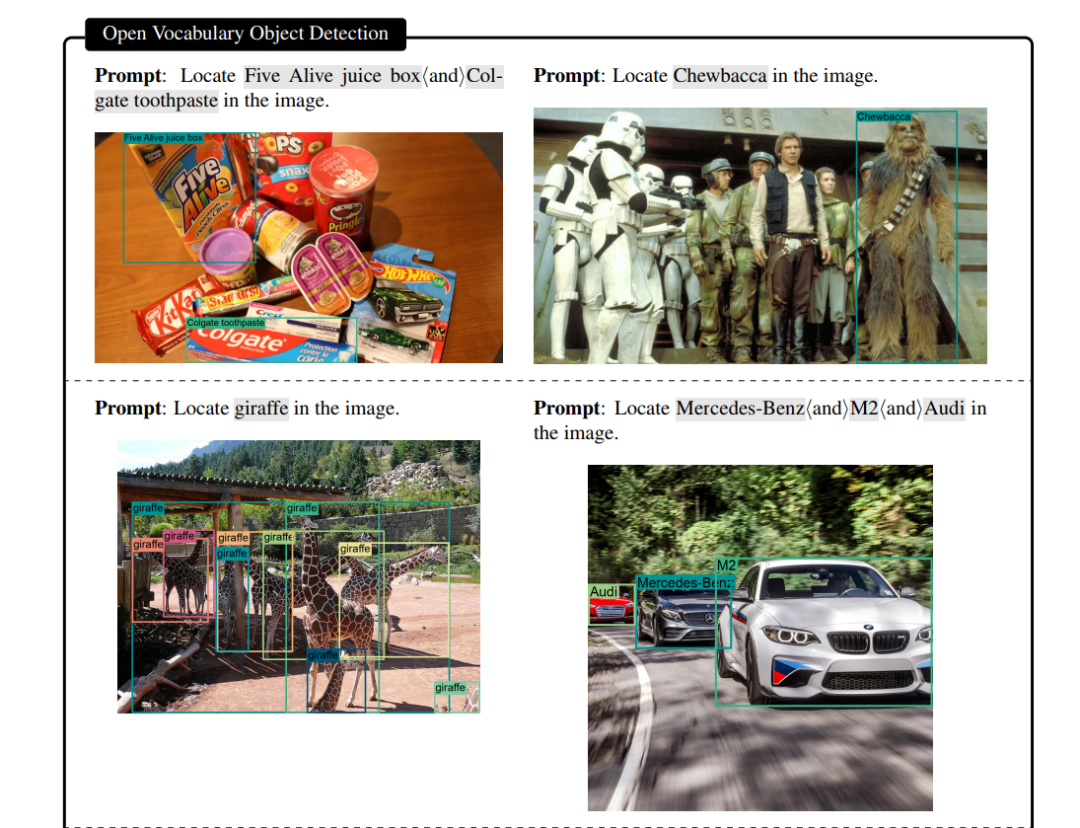
5- OCR

6- 分割
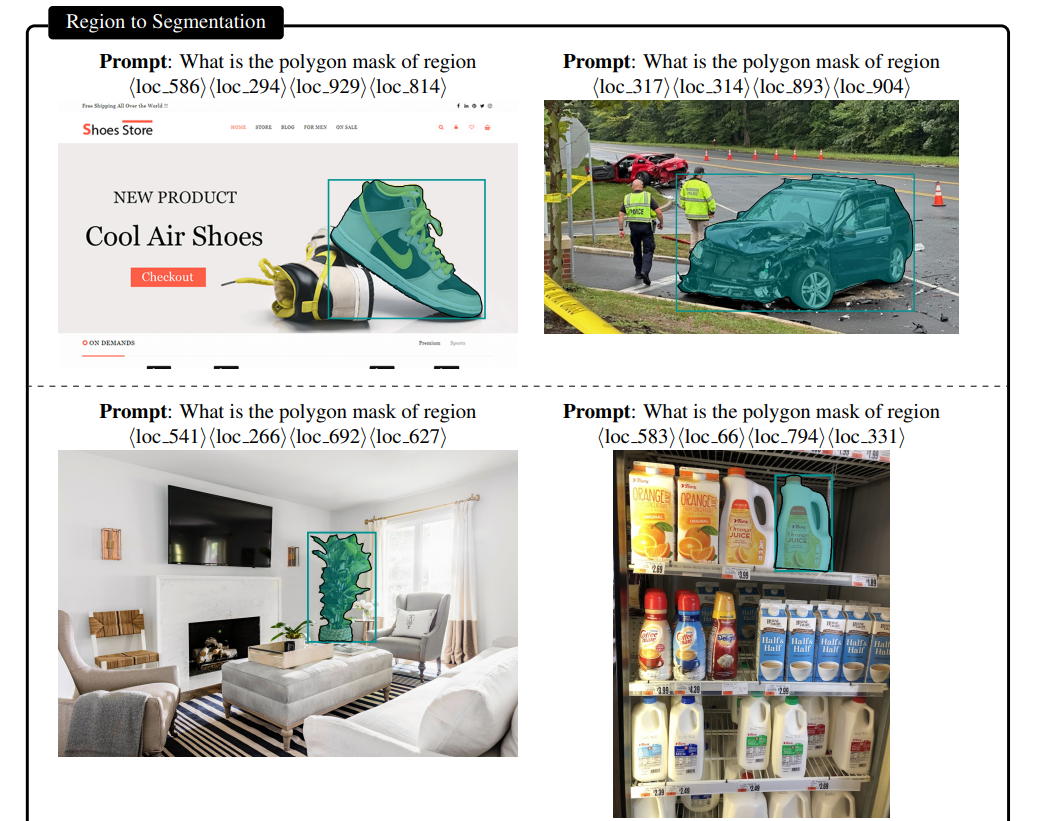
这些你在CV领域干的活儿,它都可以弄
下面对比一下和其他的模型

这个就很明显了,不对比别的,就对比GPT4-V, florence-2直接把这个实际文字都给撸了下来,属于OCR+VQA任务一起做了,当然GPT-4V的工作也还行,但是比如非常有感情的,替我给Amelia一个拥抱这种句子,都被消融掉了,从这个角度讲,Florence的任务做的应该是最出色的。
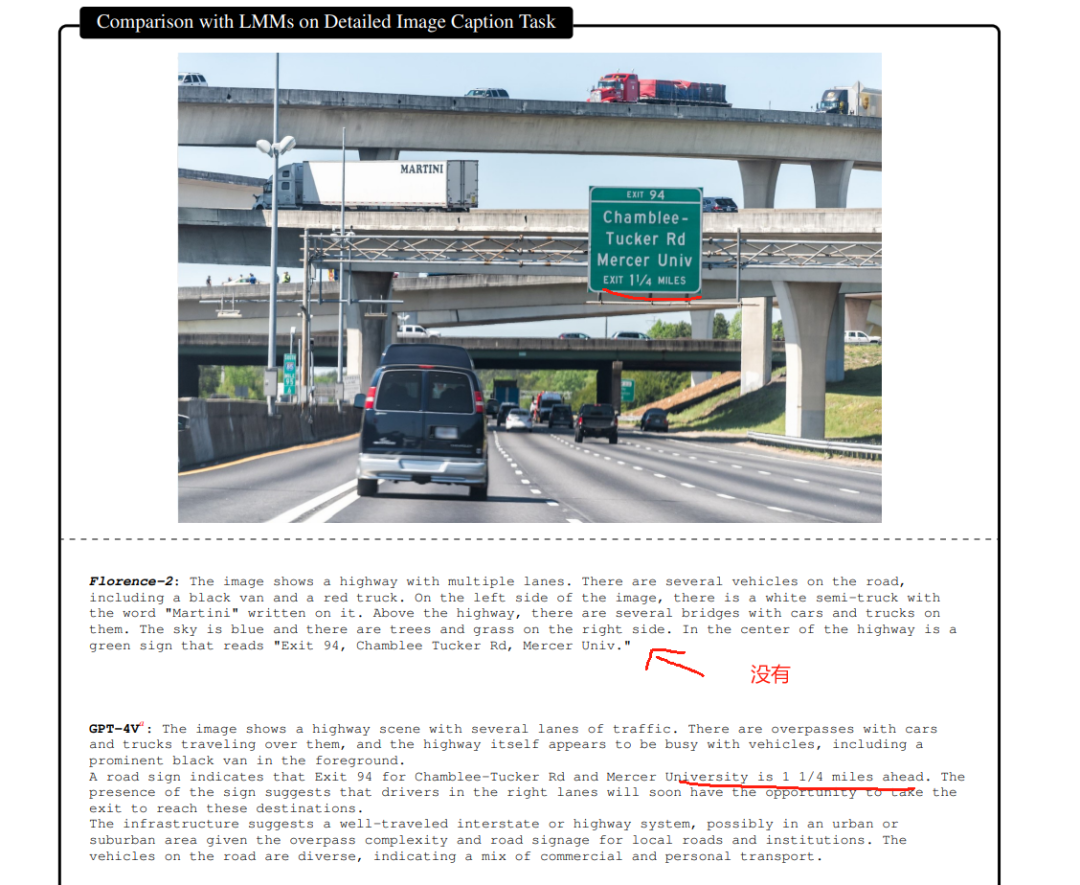
也不是每个VQA任务都能完胜,比如这个,感觉Florence就有点近视眼

,路牌上告诉1/4个mile就出,它就没看到。
别的也比不了了,和这些多模态只能比VQA,因为别的任务它们也做不了。
然后比如和我们自己的Kosmos-2对比(也开源了,但是我不讲了,我更看好florence-2,感兴趣的自己去玩,huggingface上都有),同样的对象检测,明显florence-2更胜一筹。

总结就是从趋势和新势力的角度,我觉得chameleon前融合必然是未来,以后多模态肯定都是前融合,但是你不能光概念好,细活儿也得拿的出手,另外一个维度就是florence的这种,传统CV复杂任务也会介入到多模态生意里面,比如你问一个搞自动驾驶的,它选florence还是GPT4o,他想都不想肯定选florence啊,因为这些任务是必须的,是和他手头现在的业务高相关的。
总而言之,Bye,下期见!

多模态8
多模态 · 目录
上一篇多模态MLLM都是怎么实现的(9)-时序LLM是怎么个事儿?