最近在看面试题,看到了hashmap相关的知识,面试中问的也挺多的,然后我这里记录下来,供大家学习。
Hashmap为什么线程不安全
-
jdk 1.7中,在扩容的时候因为使用头插法导致链表需要倒转,从而可能出现循环链表问题或者数据丢失的问题
-
jdk 1.8中,在put方法中,假设A,B两个线程都插入相同的值到同一个下标,这个下标对应的值此时为null,假设线程A进行方法后挂起,而线程B顺利执行,此时该下标对应的值为B插入的值,然后A线程获得时间轮,此时线程A不再进行hash判断了,直接进行插入,就会导致覆盖了原来B插入到该下标的值
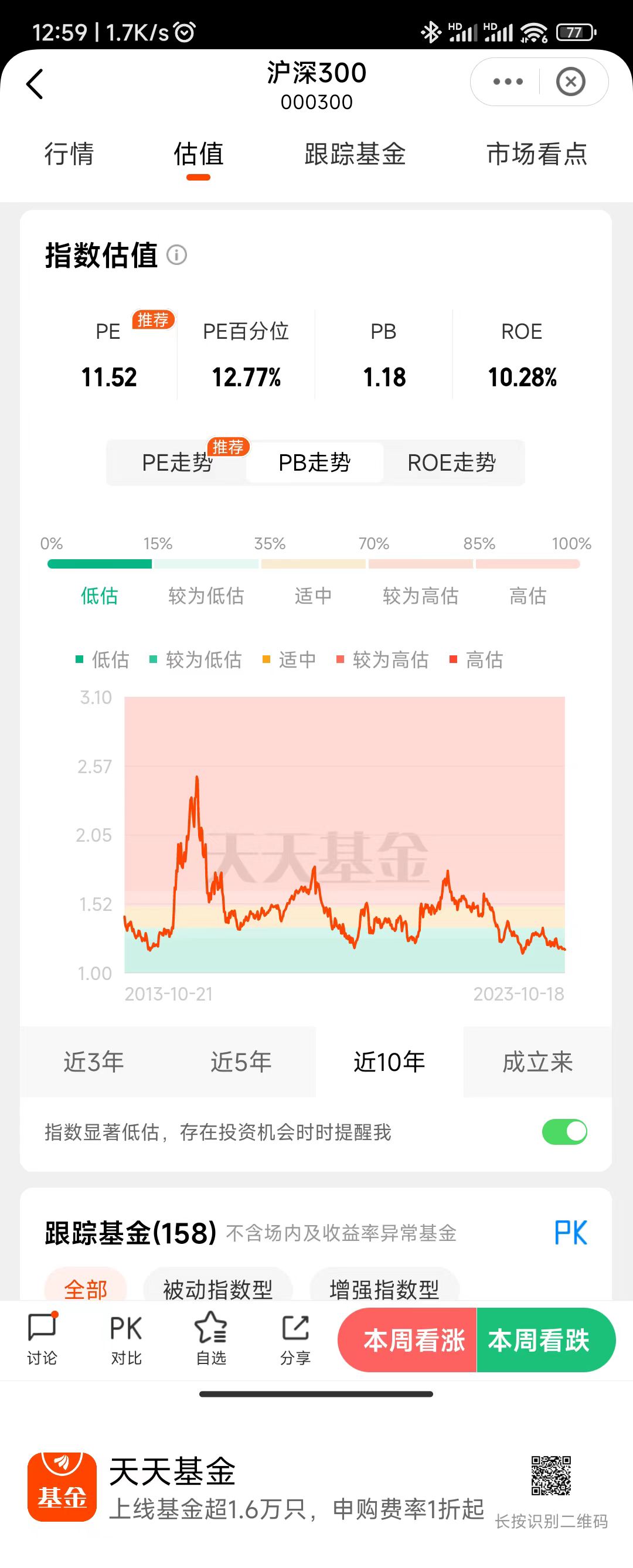
HashMap类(底层为数组+链表+红黑树)
扩容机制
在java8以后,满足扩容机制的只需要笑傲一个条件即可,即当加入的新的数据和其他数据大于或者等于阈值就会发生扩容,且这种扩容形式也是在先插入新值后,再进行扩容。
在java7中,每个节点存放一个Entry,每个Entry后面跟着一个链表,链表的每个节点存放一个Entry,这个Entry上保存有相应的key/Value,且存放着下一个节点的地址;在java8之后,因为引入了红黑树,所以把Entry改成了Node,其他的存放的内容都和Entry上面存放的一样。
但是,在java8后虽然底层结构变成了数组+链表+红黑树,但是不一定会用到红黑树,只有当总的数据量大于64或者链表长度大于8的时候会将链表转换为红黑树。
扩容满足的条件(什么时候扩容)
在java7中,扩容需要满足以下两个条件(任意一个满足都会发生扩容)
-
存放当前元素前,数据个数大于等于阈值
-
存放当前元素时发生hash冲突
在java8后,扩容只需要满足--》存放当前元素后,数据量大于等于阈值,且扩容是在插入新数据后进行扩容
为什么在JDK 1.8后hashmap底层要添加红黑树
当hash冲突过多的时候,数据插入到链表后面就会越来越多,就会导致链表链化严重,对于CRUD这些操作会造成较高的复杂度(O(n)),所以为了解决这一问题,在java8后使用红黑树来处理这种链化的情况。
hash冲突怎么解决
hash冲突表示的是当插入一个新值的时候通过hash函数计算出的下标值已经存入得对应数据,这个时候再插入一个值的时候就会出现hash冲突。
开放地址法
线性探测
根据hash函数计算下标值,如果当前下标已经有值存在,那就去判断下一个下标是否存值,通过这样的方式来解决hash冲突,但是这样的方式可能会引起聚集,即连续找了多次下标都是有值的情况,这样会在后续的操作中增加复杂度。

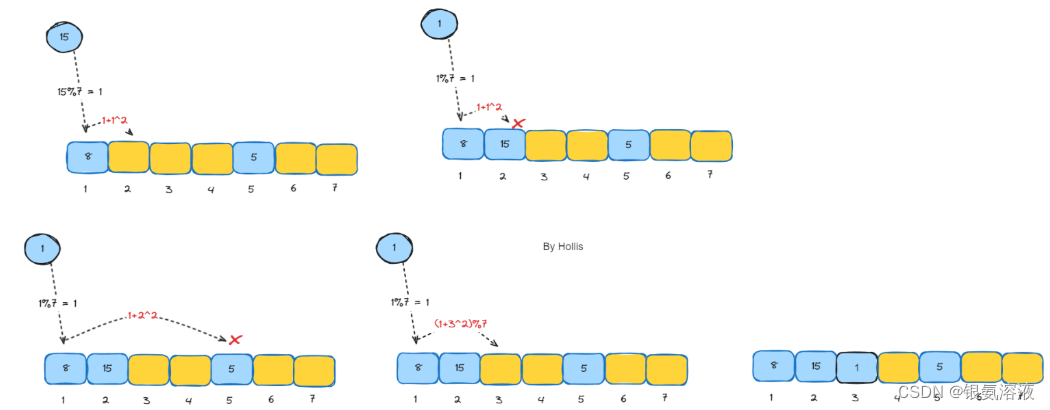
二次探测
即根据hash下标的二次方进行探测(1,4,9.......),这样的做法可以减少聚集的问题
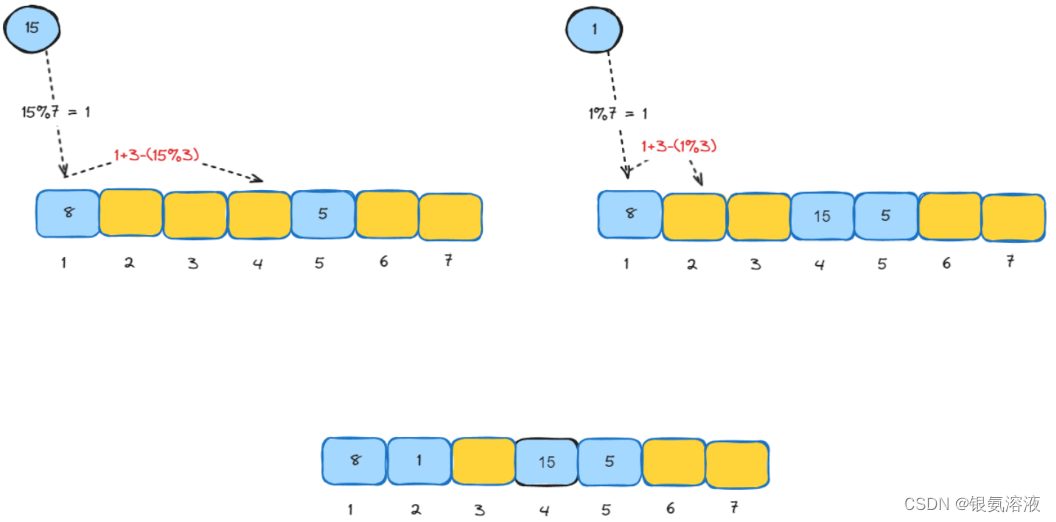
双重散列
如果当前通过hash散列函数计算出的下标已经存入了值,那就在用另外的hash散列函数再次进行计算
链地址法
每一个hash桶后面都会跟着一个链表,当通过hash函数找到对应桶,如果当前值对应下标在链表中已经存入了值,那么就会将该值放在链表末尾然后进行存储。
再哈希
再哈希是指当前的哈希函数计算出来的下标值已经被占用,这时就会使用一个新的哈希函数来进行再次计算。
双重散列和再哈希的区别
双重散列和再哈希都是需要使用多个hash函数来解决hash冲突,但是对于双重散列而言,每一次的hash函数都是新的hash函数,不会根据前一个hash函数计算出来的下标值为基础进行计算,而再哈希的每一个hash函数会根据前一个hash函数计算出来的下标值为基础进行计算,这样对于下一次计算出来的下标肯定不会和前一个hash函数计算出来的下标相重合。
hashmap和hashtable的区别
-
hashmap是线程不安全的,而hashtable是线程安全的
-
hashmap可以存储null键和null值,hashtable不能存储null键和null值
-
hashmap在jdk1.8之后底层结构为数组+链表+红黑树,hashtable底层数据结构为数组+链表
以上为自己学习过程中列出来的知识点,当然还存在很多不足,各位有补充的可以在评论区进行留言我们共同学习~