前言
本部分博客需要先阅读博客:
《Transformer实现以及Pytorch源码解读(一)-数据输入篇》
作为知识储备。
Embedding使用方式
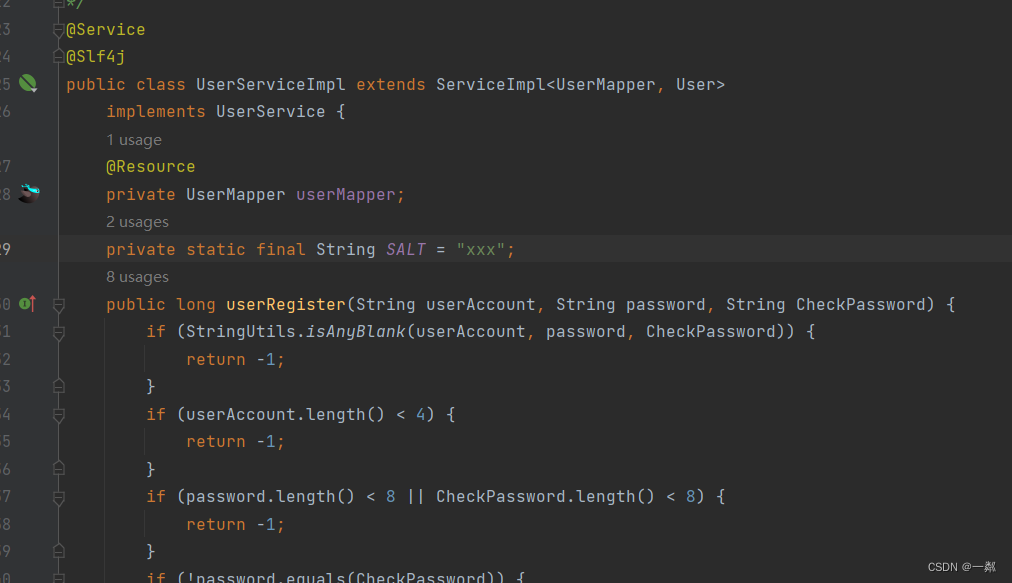
如下面的代码中所示,embedding一般是先实例化nn.Embedding(vocab_size, embedding_dim)。实例化的过程中输入两个参数:vocab_size和embedding_dim。其中的vocab_size是指输入的数据集合中总共涉及多少个去重后的单词;embedding_dim是指,每个单词你希望用多少维度的向量表示。随后,实例化的embedding在forward中被调用self.embeddings(inputs)。
class Transformer(nn.Module):def __init__(self, vocab_size, embedding_dim, hidden_dim, num_class,dim_feedforward=512, num_head=2, num_layers=2, dropout=0.1, max_len=512, activation: str = "relu"):super(Transformer, self).__init__()# 词嵌入层self.embedding_dim = embedding_dimself.embeddings = nn.Embedding(vocab_size, embedding_dim)self.position_embedding = PositionalEncoding(embedding_dim, dropout, max_len)# 编码层:使用Transformerencoder_layer = nn.TransformerEncoderLayer(hidden_dim, num_head, dim_feedforward, dropout, activation)self.transformer = nn.TransformerEncoder(encoder_layer, num_layers)# 输出层self.output = nn.Linear(hidden_dim, num_class)def forward(self, inputs, lengths):inputs = torch.transpose(inputs, 0, 1)hidden_states = self.embeddings(inputs)hidden_states = self.position_embedding(hidden_states)attention_mask = length_to_mask(lengths) == Falsehidden_states = self.transformer(hidden_states, src_key_padding_mask=attention_mask).transpose(0, 1)logits = self.output(hidden_states)log_probs = F.log_softmax(logits, dim=-1)return log_probs数据被怎样变换了?
如下图所示,第一个tensor表示input,该input表示一个句子( sentence),只是该句子中的单词用整数进行了代替,相同的整数表示相同的单词。而每个1在embedding之后,变成了相同过的向量。
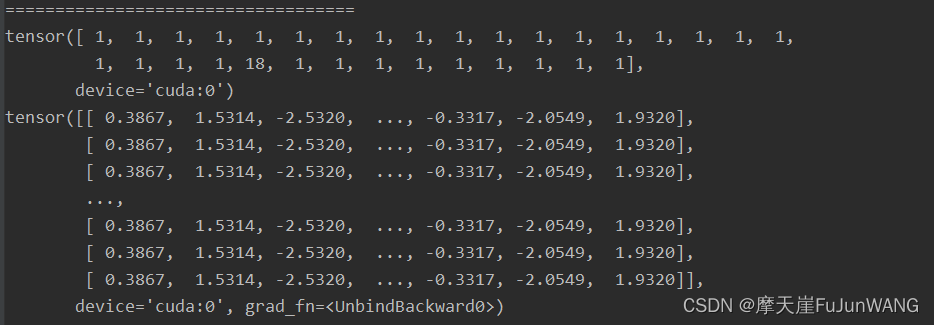
我们将以上的代码重新的运行一遍,发现表示1的向量改变了,这说明embedding 的过程不是确定的,而是随机的。

数据是怎样被变化的?
Embedding类在调用过程中主要涉及到以下几个核心方法:_
init
,rest_parameters,forward:
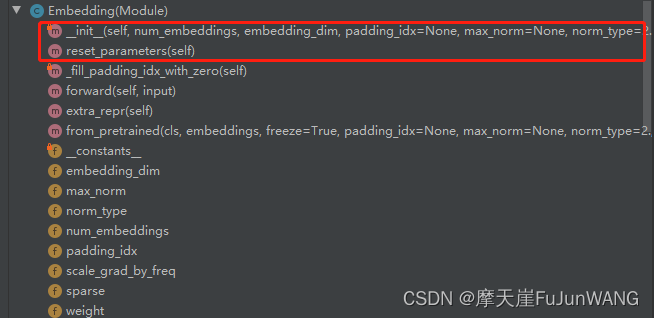
Embedding类的初始化过程如下所示。当_weight没有的情况下调用Parameter初始化一个空的向量,该向量的维度与输入数据中的去重单词个数(num_bembeddings)一样。然后调用reset_parameters方法。
def __init__(self, num_embeddings: int, embedding_dim: int, padding_idx: Optional[int] = None,max_norm: Optional[float] = None, norm_type: float = 2., scale_grad_by_freq: bool = False,sparse: bool = False, _weight: Optional[Tensor] = None,device=None, dtype=None) -> None:factory_kwargs = {'device': device, 'dtype': dtype}super(Embedding, self).__init__()self.num_embeddings = num_embeddingsself.embedding_dim = embedding_dimif padding_idx is not None:if padding_idx > 0:assert padding_idx < self.num_embeddings, 'Padding_idx must be within num_embeddings'elif padding_idx < 0:assert padding_idx >= -self.num_embeddings, 'Padding_idx must be within num_embeddings'padding_idx = self.num_embeddings + padding_idxself.padding_idx = padding_idxself.max_norm = max_normself.norm_type = norm_typeself.scale_grad_by_freq = scale_grad_by_freqif _weight is None:self.weight = Parameter(torch.empty((num_embeddings, embedding_dim), **factory_kwargs))# print("===========================================1")# print(self.weight)#将self.weight进行nornal归一化self.reset_parameters()print("===========================================2")print(self.weight)else:assert list(_weight.shape) == [num_embeddings, embedding_dim], \'Shape of weight does not match num_embeddings and embedding_dim'self.weight = Parameter(_weight)self.sparse = sparsereset_parameters的实现如下所示,主要是调用了init.norma_方法。
def reset_parameters(self) -> None:init.normal_(self.weight)self._fill_padding_idx_with_zero()init.normal_又调用了torch.nn.init中的normal方法。该方法将空的self.weight矩阵填充为一个符合 (0,1)正太分布的矩阵。
N
(
mean
,
std
2
)
.
\mathcal{N}(\text{mean}, \text{std}^2).
N
(
mean
,
std
2
)
.
def normal_(tensor: Tensor, mean: float = 0., std: float = 1.) -> Tensor:r"""Fills the input Tensor with values drawn from the normaldistribution :math:`\mathcal{N}(\text{mean}, \text{std}^2)`.Args:tensor: an n-dimensional `torch.Tensor`mean: the mean of the normal distributionstd: the standard deviation of the normal distributionExamples:>>> w = torch.empty(3, 5)>>> nn.init.normal_(w)"""return _no_grad_normal_(tensor, mean, std)继续追踪_no_grad_normal_(tensor, mean, std)我们发现,该方法是通过c++实现,所在的源码文件目录为:
namespace torch {
namespace nn {
namespace init {
namespace {
struct Fan {explicit Fan(Tensor& tensor) {const auto dimensions = tensor.ndimension();TORCH_CHECK(dimensions >= 2,"Fan in and fan out can not be computed for tensor with fewer than 2 dimensions");if (dimensions == 2) {in = tensor.size(1);out = tensor.size(0);} else {in = tensor.size(1) * tensor[0][0].numel();out = tensor.size(0) * tensor[0][0].numel();}}int64_t in;int64_t out;
};
Tensor normal_(Tensor tensor, double mean, double std) {NoGradGuard guard;return tensor.normal_(mean, std);
}forward方法的c++实现如下所示。
torch::Tensor EmbeddingImpl::forward(const Tensor& input) {return F::detail::embedding(input,weight,options.padding_idx(),options.max_norm(),options.norm_type(),options.scale_grad_by_freq(),options.sparse());
}继续追踪,发现weight中的每个变量被下面的c++代码填充了正太分布的随机数。
void normal_kernel(const TensorBase &self, double mean, double std, c10::optional<Generator> gen) {CPUGeneratorImpl* generator = get_generator_or_default<CPUGeneratorImpl>(gen, detail::getDefaultCPUGenerator());templates::cpu::normal_kernel(self, mean, std, generator);
}随机数的生成调用如下的代码,首先询问:目前代码是在什么设备上运行,并调用cpu或者gup上的随机数生成方法。
template <typename T>
static inline T * check_generator(c10::optional<Generator> gen) {TORCH_CHECK(gen.has_value(), "Expected Generator but received nullopt");TORCH_CHECK(gen->defined(), "Generator with undefined implementation is not allowed");TORCH_CHECK(T::device_type() == gen->device().type(), "Expected a '", T::device_type(), "' device type for generator but found '", gen->device().type(), "'");return gen->get<T>();
}/*** Utility function used in tensor implementations, which* supplies the default generator to tensors, if an input generator* is not supplied. The input Generator* is also static casted to* the backend generator type (CPU/CUDAGeneratorImpl etc.)*/
template <typename T>
static inline T* get_generator_or_default(const c10::optional<Generator>& gen, const Generator& default_gen) {return gen.has_value() && gen->defined() ? check_generator<T>(gen) : check_generator<T>(default_gen);
}至此,embedding的每个随机数的生成过程都清楚了。
总结
Embedding的过程,其实就是为每个单词对应一个向量的过程。该向量为(0,1)正太分布,该矩阵在Embedding的实例化过程就已经被初始化完成。在调用Embedding示例的时候即forward开始工作的时候,只是做了一个匹配的过程,也就是将<字典,向量>的对应关系应用到input上。前期解读该部分源码的困惑是一只找不到forward中的对应处理过程,以为embedding的处理逻辑是在forward的阶段展开的,显然这种想法是不对的。Pytorch的架构设计的的确优雅!











![[个人感悟] MySQL应该考察哪些问题?](https://img-blog.csdnimg.cn/direct/3f01cb100b09427994ea5d60f7395be1.png#pic_center)