在这个数字化时代,文本识别技术变得越来越重要,它广泛应用于文档自动化处理、内容审核、智能交互等场景。本文将引导你如何使用Python结合PaddleOCR库,轻松实现图片中的文字识别功能。
必备工具包安装
在开始编写代码之前,你需要安装以下几个Python库:
- PyQt5:用于构建图形用户界面
- PaddleOCR:百度开发的文字识别库,支持多语言和多场景的文字检测与识别
- colorama:用于在终端输出彩色文本
你可以通过以下命令安装这些库:
pip install PyQt5 paddleocr colorama确保你的环境中已经安装了这些包,否则程序将无法正常运行。
代码与逻辑简介
#!/usr/bin/env python3
# coding:utf-8
from PyQt5.QtCore import QObject
from paddleocr import PaddleOCR
import logging
from colorama import Fore, Style# 设置 PaddleOCR 日志级别为 ERROR
logging.getLogger("ppocr").setLevel(logging.ERROR)class OcrQt(QObject):def __init__(self, parent=None):super(OcrQt, self).__init__(parent)self.img_path = "./0001.png"self.use_angle = Trueself.cls = Trueself.default_lan = "ch"self.result = []self.ls = []self.dic = {}def set_task(self, img_path='', use_angle=True, cls=True, lan="ch"):self.img_path = img_pathself.use_angle = use_angleself.cls = clsself.default_lan = landef start(self):self.ocr(self.img_path, self.use_angle, self.cls, self.default_lan)self.grouping()def ocr(self, img_path, use_angle=True, cls=True, lan="ch", use_gpu=0):ocr = PaddleOCR(use_angle_cls=use_angle, use_gpu=use_gpu, lang=lan)try:result = ocr.ocr(img_path, cls=cls)self.result = resultexcept PermissionError:print(Fore.RED + '权限错误:' + Style.RESET_ALL)exit()except FileNotFoundError:print(Fore.RED + '图片路径错误:' + Style.RESET_ALL, self.img_path)exit()for line in self.result:ls = [j[0] for i in line for j in i]dic = {}self.ls = lsself.dic = dicfor index, info in enumerate(ls):if index % 2 == 0:dic[tuple(info)] = ls[index + 1]def grouping(self):print('\n'.join([info for index, info in enumerate(self.ls) if index % 2 == 1]))if __name__ == "__main__":path = r'' # 这里换成需要图区文本的图片链接即可,如不修改则使用默认图片ocrObj = OcrQt()if path:print('=' * 30, '提取用户上传图片文本', '=' * 30)ocrObj.set_task(path)else:print('=' * 30, '使用默认测试图片', '=' * 30)ocrObj.start()
该程序是一个基于PyQt5和PaddleOCR的图形界面应用,主要包括以下几个部分:
-
初始化OCR引擎:在
OcrQt类的构造函数中,通过PaddleOCR初始化OCR引擎,可以设置是否使用角度分类器、是否使用GPU加速、语言等参数。 -
设置识别任务:通过
set_task方法设置图片路径、是否使用角度分类器、是否进行文字区域检测等。 -
启动识别:
start方法中调用ocr方法对指定图片进行文字识别,并通过grouping方法对识别结果进行简单处理。 -
识别与结果处理:
ocr方法中使用PaddleOCR对象进行OCR识别,grouping方法则负责输出识别结果。
如何使用
- 确保你已经安装了所有必要的库。
- 将上述代码保存为Python文件(例如ExtractText.py)。
- 修改
path变量为你需要识别的图片路径。 - 运行程序,程序将输出图片中识别到的文字。
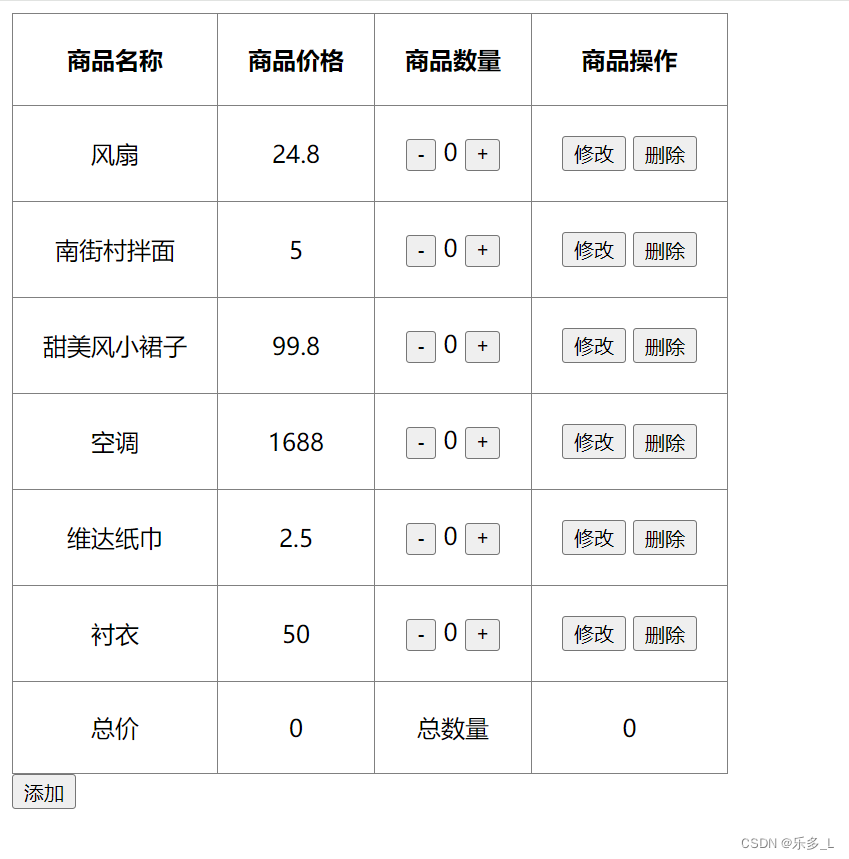
运行截图


Gitee仓库下载地址
为了方便大家的使用和修改,我已经将项目代码上传至Gitee,你可以通过以下链接进行访问和下载:
python实用脚本: 欢迎访问“Python实用脚本”仓库!本仓库汇集了各种实用的Python脚本,旨在帮助开发者提高开发效率,解决日常编程问题。脚本涵盖了数据处理、图像识别、自动化任务等多个领域,每个脚本都附有详细的使用说明和示例代码。无论你是初学者还是经验丰富的开发者,这里都能找到适合你的工具和解决方案。欢迎下载、试用并提出宝贵意见!![]() https://gitee.com/fantasy_5/python-practical-script
https://gitee.com/fantasy_5/python-practical-script
结语
通过本文,你已经学会了如何使用Python和PaddleOCR库来识别图片中的文字。这只是PaddleOCR强大功能的冰山一角,它还支持多种语言,可以适应不同的识别场景。希望本文能够帮助你在项目中快速实现文字识别功能。