数据挖掘(Data Mining)就是从大量的,不完全的,有噪声的,模糊的,随机的实际应用数据中,提取隐含在其中的,人们事先不知道的,但又是潜在有用的信息和知识的过程.
预测性数据挖掘
分类
定义:分类就是把一些新的数据项映射到给定类别中的某一个类别
分类流程:①特征提取
②特征选择
③分类
常用的分类方法:
- 决策树
- 贝叶斯分类
- 神经网络
- 支持向量机(SVM)
- K近邻分类(KNN)
- CART算法
- ID3算法
- C4.算法
分类与聚类的最大区别在于,分类数据中的一部分的类别是已知的,而聚类数据的类别未知。
回归
应用现有的数值来预测其他数值是什么.
描述性数据挖掘
聚类
聚类的目的是把数据对象分成各个聚类,各个蔟.
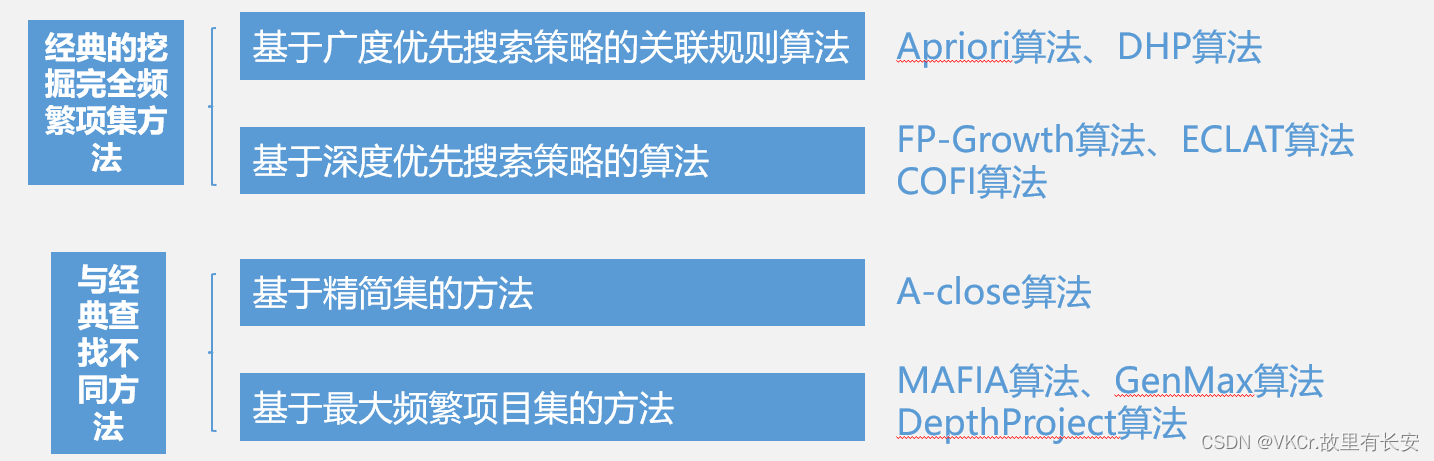
关联分析
帮助识别数据库中数值之间的关系
关联规则(Association rule):指从事务数据库、关系数据库和其他信息存储中的大量数据的项集之间发现有趣的、频繁出现的模式、关联和相关性。
关联分析(Association analysis):用于发现隐藏在大型数据集中的令人感兴趣的联系。所发现的联系可以用关联规则或者频繁项集的形式表示。关联规则挖掘就是从大量的数据中挖掘出描述数据项之间相互联系的有价值的有关知识。
关联规则分类
1)基于规则中处理的变量的类别,关联规则可以分为布尔型和数值型。
2)基于规则中数据的抽象层次,可以分为单层关联规则和多层关联规则。
3)基于规则中涉及到的数据的维数,关联规则可以分为单维的和多维的。







![[笔记] CCD相机测距相关的一些基础知识](https://img-blog.csdnimg.cn/direct/99dd73ba615345c1b2100f48592490ee.png)