一、重复消费问题出现的原因
导致重复消费的原因可能出现在生产者,也可能出现在 MQ 或 消费者。这里说的重复消费问题是指同一个数据被执行了两次,不单单指 MQ 中一条消息被消费了两次,也可能是 MQ 中存在两条一模一样的消费。
- 生产者:生产者可能会重复推送一条数据到 MQ 中,为什么会出现这种情况呢?也许是一个 Controller 接口被重复调用了 2 次,没有做接口幂等性导致的;也可能是推送消息到 MQ 时响应比较慢,生产者的重试机制导致再次推送了一次消息。
- MQ:在消费者消费完一条数据响应 ack 信号消费成功时,MQ 突然挂了,导致 MQ 以为消费者还未消费该条数据,MQ 恢复后再次推送了该条消息,导致了重复消费。
- 消费者:消费者已经消费完了一条消息,正准备但是还未给 MQ 发送 ack 信号时,此时消费者挂了,服务重启后 MQ 以为消费者还没有消费该消息,再次推送了该条消息。
二、解决方案
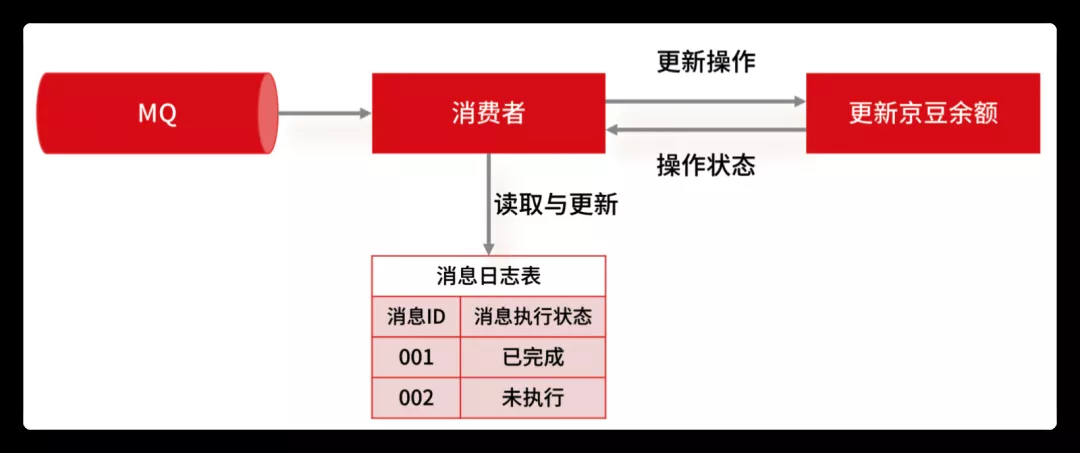
最简单的实现方案,就是在数据库中建一张消息日志表, 这个表有两个字段:消息 ID 和消息执行状态。这样,我们消费消息的逻辑可以变为:在消息日志表中增加一条消息记录,然后再根据消息记录,异步操作更新用户京豆余额。
因为我们每次都会在插入之前检查是否消息已存在,所以就不会出现一条消息被执行多次的情况,这样就实现了一个幂等的操作。当然,基于这个思路,不仅可以使用关系型数据库,也可以通过 Redis 来代替数据库实现唯一约束的方案。
在这里我多说一句,想要解决“消息丢失”和“消息重复消费”的问题,有一个前提条件就是要实现一个全局唯一 ID 生成的技术方案。这也是面试官喜欢考察的问题,你也要掌握。
在分布式系统中,全局唯一 ID 生成的实现方法有数据库自增主键、UUID、Redis,Twitter-Snowflake 算法,我总结了几种方案的特点,你可以参考下。
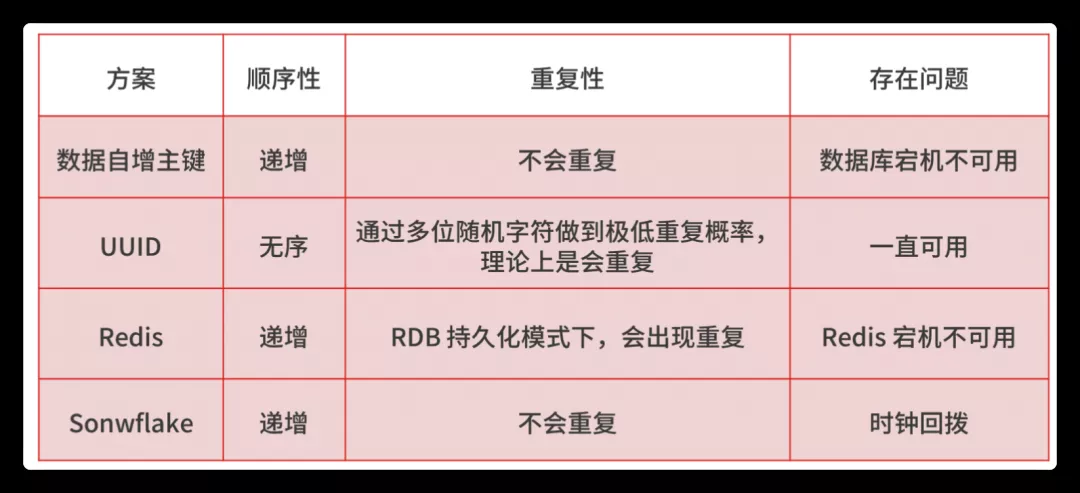
我提醒你注意,无论哪种方法,如果你想同时满足简单、高可用和高性能,就要有取舍,所以你要站在实际的业务中,说明你的选型所考虑的平衡点是什么。我个人在业务中比较倾向于选择 Snowflake 算法,在项目中也进行了一定的改造,主要是让算法中的 ID 生成规则更加符合业务特点,以及优化诸如时钟回拨等问题。





![[保姆级教程]uniapp实现底部导航栏](https://img-blog.csdnimg.cn/direct/7692da0dd5fe47d0a9ba14f45bbc47c4.png)