前言
(这篇文章是给那些打算接触AI绘画和还不太了解的人写的)什么是AI绘画?什么配置才能AI绘画?要怎样部署文件、输入咒语?你是否有着这样的疑问,在这个系列我会写一下我近一个多月的学习成果,作为科普和教程分享给大家。
AI绘画发展的重要节点
几年前就有论文提出来两种算法GAN和diffusion,像谷歌等公司一直致力于把这些论文里的技术落地实践。而今年2022正是AI绘画技术突然增速落地的一年——去年前年的产品(DALL·E、GauGAN等,大多基于GAN)效果并不好或不能满足多样化的需求,今年突然就技术大爆炸,一堆质量说得过去的AI绘画算法雨后春笋般涌现,我们按照时间线梳理一下他们的发展和优缺点。
22年2月先出现的是Disco Diffusion(CLIP+diffusion,开源,简称DD),在生成场景方面比之前的算法有明显进步,但是应用面太窄,能画的东西太少,比如糟糕的人像。
4月OpenAI 也发布了新模型 DALL·E 2(CLIP+diffusion,不开源),它对语义的理解极为优秀,可以拼凑出完全不存在的事物,比如宇航员骑马的经典图像。
5月MidJourney(CLIP+diffusion,不开源,简称MJ)在discord测试,用户直接用机器人对话就可以获取图片,有用户拿着MJ生成数字油画参加比赛,在裁判不知情的条件下获得了第一。(MJ不开源,但是也一直在吸纳开源的技术不断迭代)官网https://www.midjourney.com/home/
7月底Stable Diffusion(CLIP+diffusion+VAE,开源,简称SD)横空出世,这个迄今为止最强AI绘画算法模型一经发布就快速占据大半市场份额。用户可以部署在自己的电脑上或云端服务器上,用一般的英伟达游戏显卡就可以运行,且比之前的几种算法快多了,后来还有A卡甚至CPU运行的版本。WebUI开源,模型可以由用户自行训练,每种画风、人物、内容都可以针对性训练,达到通用模型无法达到的效果。这些都是SD能快速占领市场的原因。https://beta.dreamstudio.ai/dream
10月NovelAI公司在拿着Stable Diffusion开源的数据训练出来的专门画二次元anime模型和naifu和被黑客泄露,更是加剧了Stable Diffusion成为当今占有率最高的进程。(未开源,但是被黑客公开)https://novelai.net/
另外,除了上述算法,还有很多其他公司拿着Stable Diffusion进行二次开发和本地化,比如百度飞桨6pen.artDreambyWombo等。
什么是AI绘画
看完发展历程,我们可能还是不理解什么是AI绘画。AI绘画的字面意思是我给AI一个描述,它给我生成一张图片。那它是上网检索或在数据库里找到图片给你拼接出来一张吗?
想要真正理解AI绘画,必须先“简单”扯两句GAN、diffusion、CLIP和VAE。(比较枯燥,如果看不懂可以直接跳到本小结最后的黑色加粗的总结)
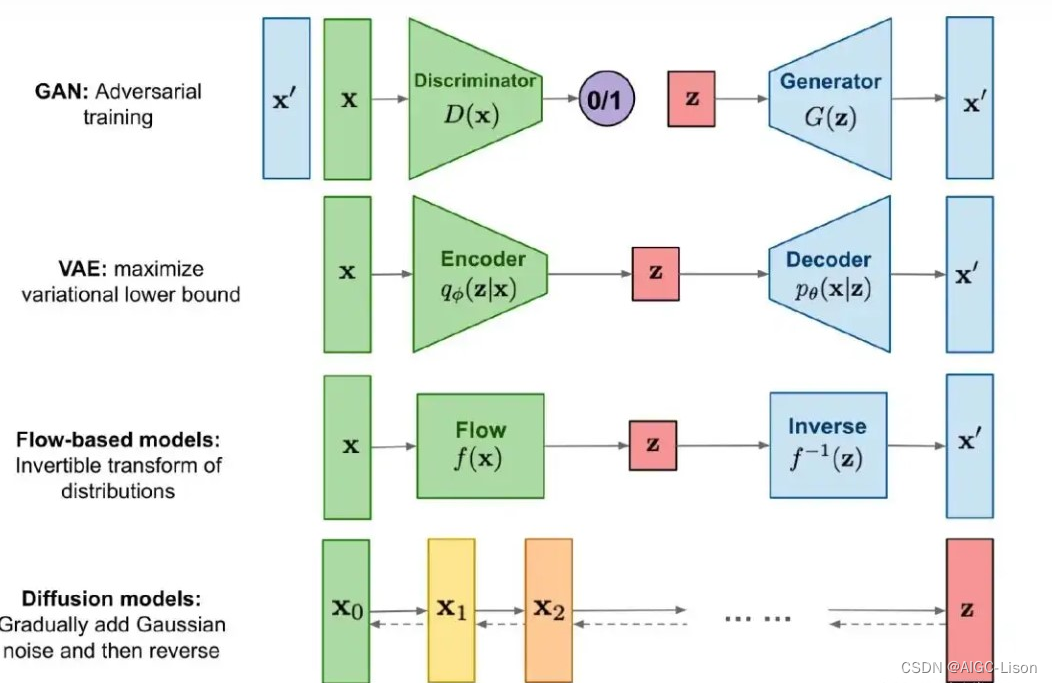
GAN(Generative adversarial network 生成对抗网络,2014年提出)生成网络(Generator)负责生成模拟数据。生成网络要不断优化自己生成的数据让判别网络判断不出来。判别网络(Discriminator)负责判断输入的数据是真实的还是生成的。判别网络也要优化自己让自己判断得更准确。但是由于生成-对抗的关系,生成器更倾向于生成已有风格和事物,而不是创新,即无法生成域外(Out-Of-Domain)结果,比如“鲜花构成的眼镜”。(GAN通病,在很多GAN的自动游戏开发中,如果奖励不够AI也更倾向于躺平挂机而不是努力拿分)
Diffusion(扩散模型,2015年提出)不同于GAN在除了绘画以外的AI领域也广泛应用,diffusion算法是专门为处理图片、音频和视频而生的。Diffusion的本质是对图片加噪声和去噪声,也分为扩散过程(forward/diffusion process)和逆扩散过程(reverse process)。
● 扩散过程(X 0 − X T ):逐步对图像加噪声,这一逐步过程可以认为是参数化的马尔可夫过程。
● 逆扩散过程(X T − X 0 ):从噪声中反向推导,逐渐消除噪声以逆转生成图像。
CLIP(Contrastive Language-Image Pre-Training比文本-图像预训练模型)是对比文本-图像预训练模型,只需要提供图像类别的文本描述,就能将图像进行分类。CLIP用作做通用的图像分类,负责自然语言理解和计算机视觉分析。 CLIP可以决定图像和文字提示的对应程度, 比如把猫的图像和"猫"这个词完全匹配起来。
VAE(Variational AutoEncoder变分自编码器)是深度学习中常用的无监督学习方法,可以用来做数据生成,表征学习,维度压缩等一系列应用。VAE由解码器、隐变量和编码器构成,可以去燥和降维,它学习如何将输入编码为更低的维数,然后再次解码和重构数据以尽可能有效地接近输入。
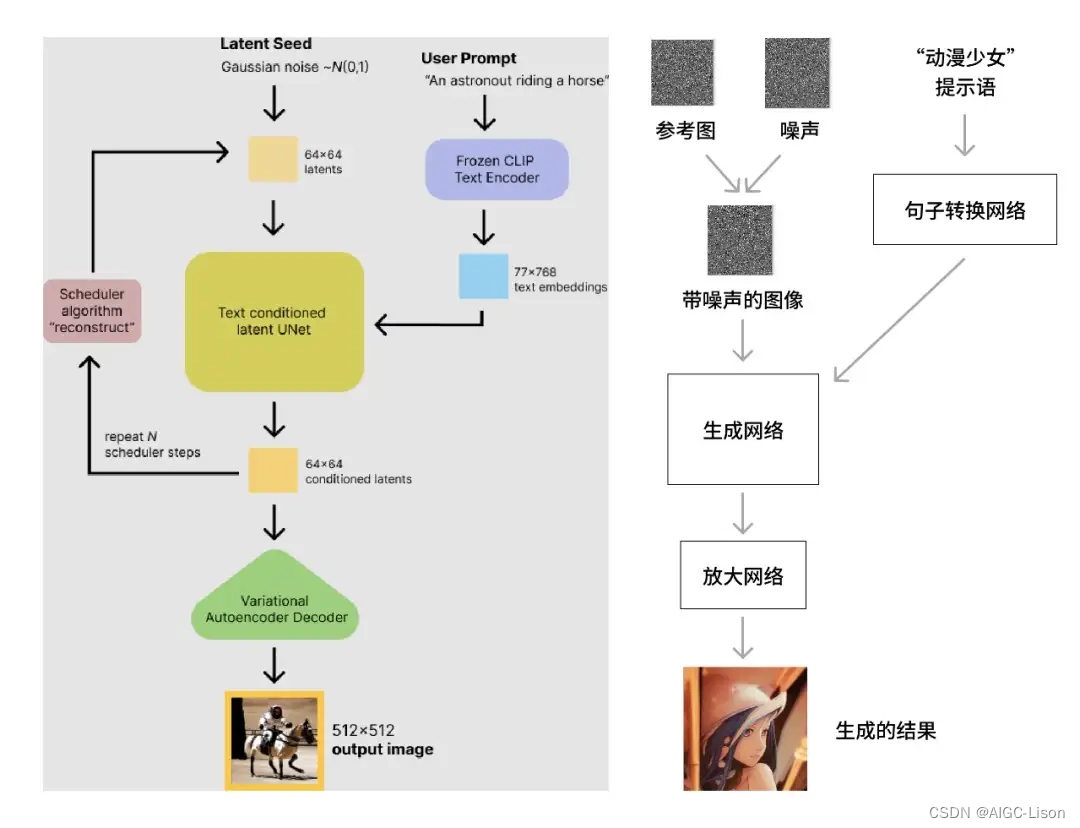
而上述几种今年推出的AI绘画方法(Disco Diffusion、DALL·E 2、MidJourney、Stable Diffusion)都用到了CLIP+diffusion,比之前GAN效果好太多了。GAN的生成-判别是通过判别器检测生成的图片是否是人类的绘画或者真实物品来训练和生成。而CLIP+Diffusion的方法则是训练时在加噪声的过程中学会文本对应的图片特征,生成时先加噪声后在噪声中还原输入文本对应的特征。以stable diffusion为例,具体流程如下图。
让我们一句话总结,比如SD这样的AI绘画,是训练时逐步加噪声留下最强的特征再和文字描述匹配,生成时先加噪声后向噪声中加入文字描述对应的特征生成新的图片。所以AI绘画不是从素材库里缝合了一张出来给你,而是像人一样记住了每个人物/物品/风格的特征,再把这些特征组合在一起,就像画师们做的那样。
但是这不意味着不存在违规和版权问题,举个例子,一个人直接临摹他人画作并拿来用作商业用途也是侵权,AI最容易出现侵权的环节就是训练阶段的图片数据库,如果都是无版权作品没问题,但是如果作者声明版权就是侵权,需要受到道德、行业规则和法律的约束。现在很多私人制作的模型是完全没有考虑版权问题的,但是这些模型也在世面上流传。
关于AI绘画技术储备
学好 AI绘画 不论是就业还是做副业赚钱都不错,但要学会 AI绘画 还是要有一个学习规划。最后大家分享一份全套的 AI绘画 学习资料,给那些想学习 AI绘画 的小伙伴们一点帮助!
对于0基础小白入门:
如果你是零基础小白,想快速入门AI绘画是可以考虑的。
一方面是学习时间相对较短,学习内容更全面更集中。
二方面是可以找到适合自己的学习方案
包括:stable diffusion安装包、stable diffusion0基础入门全套PDF,视频学习教程。带你从零基础系统性的学好AI绘画!点击下方小卡片领取~
Stable Diffusion介绍
尽管上面讲了那么多算法模型,但是现阶段掀起狂潮,使人人都在AI绘画的是stable diffusion。它有两个公司运营研发,WebUI和sd的ckpt文件都是他们开发的且开源的。而NovelAI公司本来是研发文本生成AI的(从名字也能看出来专门写小说的),后来拿着stable diffusion开源的东西自己研发出了naifu和anime二次元专用的模型。
现在市面上所有的东西都是基于开源的stable diffusion二次/三次开发的,SD有两个框架,分别是WebUI和naifu,有成千上万种模型(.ckpt文件)。如果要完全复现别人的图片,要保证框架和模型都一样,所以尽量不要简单地说用的是NovelAI还是sd,而是应该说是(naifu/webui)+(模型名称或简称.ckpt)
功能描述和使用方法简介
AI绘画最基本功能有两个,text-to-image(文生图,txt2img)和image-to-image(图生图,img2img),都是字面意思,文生图是输入文字描述输出图片,图生图是根据描述文字更改你提交的图片。
想要实现最基本的功能文生图和图生图,就必须有环境(WebUI/naifu)、模型(.ckpt文件)、提示词(prompt)。打一个比方,环境就是丹炉,模型是丹药,描述词就是咒语,三者在炼丹的过程中缺一不可。
环境(框架)
环境(框架)在sd里现在流行的有两种,一个是SD官方在github上开源的WebUI,另一个是NovelAI公司泄露的naifu。WebUI可调整参数更多,上手门槛稍高,但是功能更多,且一直在更新,不断地有新功能作为拓展(extensions)和脚本(scripts)被添加进来,上限更高。naifu也叫官网版(NovelAI官网),操作简单,入门方便,但是功能局限,比如不能生成新的模型、不能在网页端一键切换模型等等等等。WebUI和naifu的安装、整合包、内部结构我们在后续的文章会详细讲解。
模型(.ckpt文件)
当我们讨论AI绘画的时候,我们说的模型一般是Disco Diffusion、DALL·E2、MidJourney、Stable Diffusion这些算法。当我们具体到SD的应用中,模型指的是.ckpt文件。模型是你需要下载的文件里面选择最多的,我们上文讲述了SD开源的有Stable Diffusion v1.5/v1.4等版本,也有NovelAI泄露出来的animefull-final-pruned.ckpt或者animefull-latest.ckpt等(NovelAI还有一些没有泄露出来的模型,等一个好心的黑客)。除了上述两批可以被称作官方版本的.ckpt模型以外,还有成百上千的私人模型,每个模型都有自己的哈希值(可以理解为身份证号),这些模型大都是基于开源的模型融合出来的(融丹),融合的方法现在有几种(Checkpoint Merger、Dreambooth、hypernetworks、textual inversion炼embedding、美学梯度,后续文章会讲)。**总体来说现阶段.ckpt文件大概有三个大小档位,对应了不同的炼丹方式,7.1G、3.5~3.9G,1.97G。一个完善的模型应该是会提供prompt列表的,请在使用之前先阅读prompt列表。**模型.ckpt下载方式、优劣对比、信息查看等我们在后面的文章会详细讲解。
prompt关键词
prompt关键词(也叫tag、咒语、描述词、提示词)prompt是开始绘画后接触最多的东西,分为正prompt关键词(正面tag)和负prompt关键词(负面tag),很好理解,正面的是你希望AI加进去的内容和特征,负面是你不希望AI加进去的特征。prompt有着自己的语法,强调、分隔、顺序等,在不同的版本中可能不一样。prompt也有分类,有画师、风格、内容、行为、视角等等。值得注意的是,由于每个模型.ckpt文件是基于不同的内容训练而来的,所以一个模型的prompt是不能直接套用在另外一个模型上的,要具体模型具体分析,比如如果两个模型的训练图集都是一样的,prompt列表差不多,那大概率是可以借鉴咒语的。prompt的语法和查找方式我们在后续的文章也会详细讲解。
其他参数
除了上述三个关键内容,还有一些其他参数,只有所有的参数都相同才能保证你能和别人生成一张一样的图片。常见的有**采样步数(Sampling steps)、采样方法(Sampling method)、图片分辨率(宽*高)、提示词相关性(CFG Scale)、生成批次(batch count)、每批数量(batch size)、种子(seed)**等。这些内容的区别我们在后面的文章会详细讲解。
再强调一遍,除非上下文大家都知道你用的啥丹炉、模型和咒语,否则在描述自己用啥画出来的时候一定要说**(naifu/webui)+(模型名称或简称.ckpt)+(咒语prompt)+(其他参数)**,如果是在PNGinfo或者画廊等复制出来的信息一般是包含了正负关键词和各种参数以及模型哈希值的,这时候自己描述的时候加上WebUI/naifu就好了。
重要的事情说三遍!!!(naifu/webui)+(模型名称或简称.ckpt)+(咒语prompt)+(其他参数)!!!有些人只说一句用SD或者NovelAI,你用的是SD的啥!是sd的模型SD v1.4或v1.5或v2.0.ckpt还是WebUI?为什么要让我猜!你用的是NovelAI的啥!是anime.ckpt的模型啊还是naifu还是模型+naifu!每次跟别人聊天遇到语焉不详的真让人高血压!
软硬件环境
看完上面的介绍,心动了,也想尝试一下?别急,先看搭建框架需要的软硬件环境。首先是看本地部署,最早的SD只能在显存大于8G的显卡上运行,之后升级了,几乎全系30、20、16系显卡都可以跑了。后来增加了对A卡的支持A卡,甚至连CPU运行的程序都有人开发出来,不过就是速度感人罢了。显卡越好同样参数下出图就更快,比如我的3060lp在WebUI上就是13it/s,naifu大概是13s/it,所以从这个角度来看WebUI性能比naifu要好(图片迭代步数越多,需要的it就越多,一般512*512steps65的图像需要60it左右)
如果硬件实在是跟不上或者用的苹果电脑,那可以考虑一下服务器,常见的有SD官网、NovelAI官网、谷歌colab、百度腾讯阿里华为的云服务器或者是百度飞桨和6pen.art等第三方服务。SD官网、NovelAI官网是不用自己部署的,直接注册账号交钱就能用,但是不方便更换模型。对于需要自己部署的第三方服务器,其中colab是可以每天白嫖的,其他的基本都要收费,相关的教程和价格在B站也很好搜到。百度飞桨和6pen.art等第三方服务也是部署好的,但是可能有一些违禁词限制和其他规则。
快速上手
这里介绍一些网站大家可以去搜索看看,首先是B站,对新手友好,很多up把资料都打包好了恨不得把知识都嚼碎了喂给你。其次是github和huggingface,前者是很多开源信息的仓库,后者是AI绘画届的github,很多技术细节也有讨论,但是这两个都是有一定英语和编程门槛的,如果你想进一步学习可以用这两个。还有模型下载站https://rentry.org/sdmodels#除了NovelAI的模型没有收录(版权原因)以外常见的模型收录了一百五十多个(截止写稿日期),除了模型下载,介绍和tag还有示例都记得看看。
还可以看我接下来的文章,我自己写也好,翻译搬运也罢,争取让人人都能看懂(任重道远)。
关于AI绘画技术储备
学好 AI绘画 不论是就业还是做副业赚钱都不错,但要学会 AI绘画 还是要有一个学习规划。最后大家分享一份全套的 AI绘画 学习资料,给那些想学习 AI绘画 的小伙伴们一点帮助!
对于0基础小白入门:
如果你是零基础小白,想快速入门AI绘画是可以考虑的。
一方面是学习时间相对较短,学习内容更全面更集中。
二方面是可以找到适合自己的学习方案
包括:stable diffusion安装包、stable diffusion0基础入门全套PDF,视频学习教程。带你从零基础系统性的学好AI绘画!
零基础AI绘画学习资源介绍
👉stable diffusion新手0基础入门PDF👈
(全套教程文末领取哈)

👉AI绘画必备工具👈

温馨提示:篇幅有限,已打包文件夹,获取方式在:文末
👉AI绘画基础+速成+进阶使用教程👈
观看零基础学习视频,看视频学习是最快捷也是最有效果的方式,跟着视频中老师的思路,从基础到深入,还是很容易入门的。

温馨提示:篇幅有限,已打包文件夹,获取方式在:文末
👉12000+AI关键词大合集👈

这份完整版的AI绘画全套学习资料已经上传CSDN,朋友们如果需要可以微信扫描下方CSDN官方认证二维码免费领取【保证100%免费】