训练模型
学习心得
- 构建数据集。这通常包括训练集、验证集(可选)和测试集。训练集用于训练模型,验证集用于调整超参数和监控过拟合,测试集用于评估模型的泛化能力。
(mindspore提供数据集https://www.mindspore.cn/docs/zh-CN/r2.3.0rc2/api_python/mindspore.dataset.html) - 定义神经网络模型。这通常涉及到选择适当的网络架构(如卷积神经网络CNN、循环神经网络RNN、全连接网络等)和激活函数。
创建模型类:使用mindspore.nn.Cell作为基类,创建一个自定义的神经网络模型类。
义网络层:定义所需的网络,如卷积层、全连接层、激活函数和池化层等
实现construct方法:在construct方法中,使用定义好的网络层构建前向网络 - 定义超参、损失函数和优化器。
设置超参数:设置超参数,如学习率、批次大小、训练轮数等。
定义损失函数:选择适当的损失函数,如均方误差(MSE)用于回归问题,交叉熵损失(Cross-Entropy Loss)用于分类问题等。
设置优化器:选择合适的优化器,如随机梯度下降(SGD)、Adam等,用于根据损失函数的梯度更新模型参数。 - 训练和评估。
循环输入数据来训练模型。一次数据集的完整迭代循环称为一轮(epoch)。每轮执行训练时包括两个步骤:
训练:迭代训练数据集,并尝试收敛到最佳参数。
验证/测试:迭代测试数据集,以检查模型性能是否提升。
笔记
import mindspore
from mindspore import nn
from mindspore.dataset import vision, transforms
from mindspore.dataset import MnistDataset# Download data from open datasets
from download import downloadurl = "https://mindspore-website.obs.cn-north-4.myhuaweicloud.com/" \"notebook/datasets/MNIST_Data.zip"
path = download(url, "./", kind="zip", replace=True)def datapipe(path, batch_size):image_transforms = [vision.Rescale(1.0 / 255.0, 0),vision.Normalize(mean=(0.1307,), std=(0.3081,)),vision.HWC2CHW()]label_transform = transforms.TypeCast(mindspore.int32)dataset = MnistDataset(path)dataset = dataset.map(image_transforms, 'image')dataset = dataset.map(label_transform, 'label')dataset = dataset.batch(batch_size)return datasettrain_dataset = datapipe('MNIST_Data/train', batch_size=64)
test_dataset = datapipe('MNIST_Data/test', batch_size=64)class Network(nn.Cell):def __init__(self):super().__init__()self.flatten = nn.Flatten()self.dense_relu_sequential = nn.SequentialCell(nn.Dense(28*28, 512),nn.ReLU(),nn.Dense(512, 512),nn.ReLU(),nn.Dense(512, 10))def construct(self, x):x = self.flatten(x)logits = self.dense_relu_sequential(x)return logitsmodel = Network()epochs = 3
batch_size = 64
learning_rate = 1e-2loss_fn = nn.CrossEntropyLoss()
optimizer = nn.SGD(model.trainable_params(), learning_rate=learning_rate)# Define forward function
def forward_fn(data, label):logits = model(data)loss = loss_fn(logits, label)return loss, logits# Get gradient function
grad_fn = mindspore.value_and_grad(forward_fn, None, optimizer.parameters, has_aux=True)# Define function of one-step training
def train_step(data, label):(loss, _), grads = grad_fn(data, label)optimizer(grads)return lossdef train_loop(model, dataset):size = dataset.get_dataset_size()model.set_train()for batch, (data, label) in enumerate(dataset.create_tuple_iterator()):loss = train_step(data, label)if batch % 100 == 0:loss, current = loss.asnumpy(), batchprint(f"loss: {loss:>7f} [{current:>3d}/{size:>3d}]")def test_loop(model, dataset, loss_fn):num_batches = dataset.get_dataset_size()model.set_train(False)total, test_loss, correct = 0, 0, 0for data, label in dataset.create_tuple_iterator():pred = model(data)total += len(data)test_loss += loss_fn(pred, label).asnumpy()correct += (pred.argmax(1) == label).asnumpy().sum()test_loss /= num_batchescorrect /= totalprint(f"Test: \n Accuracy: {(100*correct):>0.1f}%, Avg loss: {test_loss:>8f} \n")loss_fn = nn.CrossEntropyLoss()
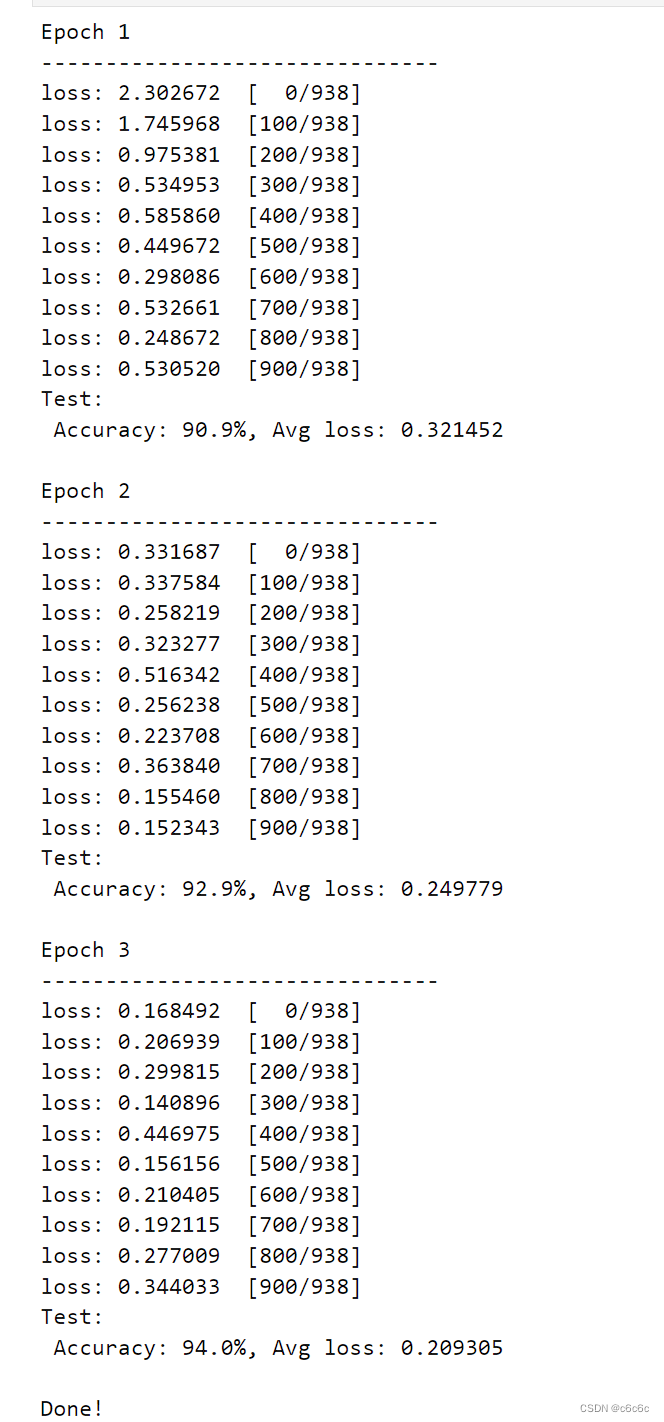
optimizer = nn.SGD(model.trainable_params(), learning_rate=learning_rate)for t in range(epochs):print(f"Epoch {t+1}\n-------------------------------")train_loop(model, train_dataset)test_loop(model, test_dataset, loss_fn)
print("Done!")
结果









![[20] Opencv_CUDA应用之 关键点检测器和描述符](https://img-blog.csdnimg.cn/direct/374e3465fb48409d9bfcd459f633e143.png)