一、前言
数据存储是Hive的基础,选择合适的底层数据存储格式,可以在不改变Hql的前提下得到大的性能提升。类似mysql选择适合场景的存储引擎。
Hive支持的存储格式有
文本格式(TextFile)
二进制序列化文件 (SequenceFile)
行列式文件(RCFile)
优化的行列式文件(ORCFile)
Apache Parquet
其中,ORCFile和Apache Parquet,以其高效的数据存储和数据处理性能得以在实际的生产环境中大量运用。
创建表时可以使用 row format 参数说明SerDe(Serializer/Deserializer 序列化和反序列化)的类型
二、文本格式(TextFile)
Hive的默认格式,数据不做压缩,可以直接使用命令查看,磁盘开销大,数据解析开销大。可以使用Gzip、Bzip2进行压缩,Hive会自动进行解压解析。但是压缩后的文件不在进行分割,一个压缩文件只能由一个Mapper任务处理。且需要解压缩后一个一个字符读取判断是否是换行符。一般不对TextFile进行压缩。
TextFile文件可以直接使用load方式加载数据,其它格式则不能使用load直接导入数据,因为需要借助mapreduce的压缩方式实现。所以TextFile的加载速度是最高的。
三、二进制序列化文件 (SequenceFile)
SequenceFile是HadoopAPI提供的一种二进制文件支持
源码类:org.apache.hadoop.io.SequenceFile
/** * SequenceFiles是由二进制键/值*对组成的平面文件* * SequenceFile提供了{@link SequenceFile.Writer},{@link SequenceFile.Reader}和 *{@link-Sorter}类用于写入、分别读取和排序。* * 基于用于压缩键/值对的压缩类型,有三种写的方式* 1、Writer : 不压缩* 2、记录压缩Writer : 记录压缩的文件,仅压缩值* 3、块压缩Writer : Block-compressed 文件, 键和值都收集在“块”中:分别压缩。“块”的大小是* 可配置的。* * 用于压缩键和/或值的实际压缩算法可以通过使用适当的{@link CompressionCodec}来指定* * 建议使用静态 createWriter 方法。由SequenceFile提供,以选择首选格式* * SequenceFile.Reader充当桥接器,可以读取上述SequenceFile格式中的任何一种** SequenceFile 格式化* * 本质上,SequenceFile 有三种不同的格式取决于指定的 CompressionType。它们都共享下面描述的 * 公共标* SequenceFile 头文件* version - 3个字节的魔术头SEQ,后面跟着1个字节的实际版本号(例如SEQ4或SEQ6)* keyClassName -key class* valueClassName - value class* compression - 一个布尔值,用于指定是否对此文件中的键/值启用压缩。* blockCompression - 一个布尔值,用于指定是否为此文件中的键/值启用块压缩。* compression codec - CompressionCodec 类,用于压缩键和/或值(如果启用了压缩)* metadata - 该二进制文件的元数据(文件的元数据是Text类型的属性名称/值对的列表)* sync - 一种同步标记,用于表示标头的末尾。* * 未压缩的 SequenceFile * 记录* Record length* Key length* Key* Value* 每隔100千字节(100M)左右一个同步标记.** 行压缩的 SequenceFile * 记录* Record length* Key length* Key (key不压缩)* Compressed Value* 每隔100千字节(100M)左右一个同步标记.* * 块压缩的 SequenceFile * 记录 Block* Uncompressed number of records in the block 块中未压缩的记录数* Compressed key-lengths block-size 压缩 key 长度块大小* Compressed key-lengths block 压缩 key 长度块* Compressed keys block-size 压缩 keys 块大小* Compressed keys block 压缩 keys 块* Compressed value-lengths block-size 压缩 value 长度块大小* Compressed value-lengths block 压缩 value 长度块* Compressed values block-size 压缩 value 块大小* Compressed values block 压缩 value 块* 每个块都有一个同步标记* * 密钥长度和值长度的压缩块由以ZeroCompressedInteger格式编码的单个密钥/值的实际长度组成* * @see CompressionCodec*/
@InterfaceAudience.Public
@InterfaceStability.Stable
public class SequenceFile {//......省略......
}使用Hive提供的标准二进制格式:
CREATE TABLE binary_table(id INT,......
)
ROW FORMAT DELIMITED
FIELDS TERMINATED BY ','
STORED AS sequencefile;也可以使用自定义的格式处理
ADD JAR /path/my-serde.jar;CREATE TABLE binary_table(id INT,name STRING,data BINARY
)
ROW FORMAT SERDE 'MyBinarySerDe'
STORED ASINPUTFORMAT 'org.apache.hadoop.mapred.SequenceFileInputFormat'OUTPUTFORMAT 'org.apache.hadoop.hive.ql.io.HiveSequenceFileOutputFormat';设置压缩格式为块压缩:
set mapred.output.compression.type=BLOCK;
优点:
支持基于记录(Record)或块(Block)的数据压缩
支持Mapper任务的分片
缺点:
合并文件需要过程,且不方便查看数据
四、行列式文件(RCFile)
源码类:org.apache.hadoop.hive.ql.io.RCFile
/*** RCFiles是Record Columnar File的缩写,是由二进制键/值对组成的平面文件,* 与SequenceFile非常相似** RCFile以记录列的方式存储表的列。它首先将行水平划分为行拆分。* 然后它垂直地划分以柱状方式分割的每一行。* RCFile首先将行拆分的元数据存储为记录的关键部分,将行拆分后的所有数据存储为值部分。* 写入时,RCFile.Writer首先将记录的值字节保存在内存中,* 并在缓冲记录的原始字节大小溢出给定参数(Writer.columnsBufferSize)时确定行拆分* 该参数可以设置为:conf.setInt(COLUMNS_BUFFER_SIZE_CONF_STR,4*1024*1024)* * RCFile分别提供了{@link Writer}、{@link Reader}和用于写入和读取的类** * RCFile以记录列的方式存储表的列。它首先将行水平划分为行拆分。* 然后它垂直地划分以柱状方式分割的每一行。* RCFile首先将行拆分的元数据存储为记录的关键部分,将行拆分后的所有数据存储为值部分** RCFile以比记录级压缩更细粒度的方式压缩值。然而,它目前还不支持压缩 key。* 用于压缩键和/或值的实际压缩算法可以通过使用适当的{@link CompressionCodec}来指定。* * {@link Reader}用于读取和解释RCFile的字节数。* ** RCFile Formats** RC Header* version - 3字节的魔术头(RCF) + 1个字节的实际版本号 (例如:RCF1)* compression - 一个布尔值,用于指定是否对此文件中的keys/values启用压缩* compression codec - 如果开启压缩,使用CompressionCodec 类来对 keys/values 进行压缩* metadata - 元数据* sync - 表示标头末尾的同步标记** RCFile Format* Header* Record* Key part* 记录长度(字节)* Key 长度(字节)* 这条记录中的行号vint)* Column_1_在磁盘中的长度(vint)* Column_1_row_1 值的绝对长度* Column_1_row_2_值的绝对长度* ...* Column_2_在磁盘中的长度(vint)* Column_2_row_1_值的绝对长度* Column_2_row_2_值的绝对长度* ...* Value part* 压缩或原始的列数据 [column_1_row_1_value,column_1_row_2_value,....]* 压缩或原始的列数据 [column_2_row_1_value,column_2_row_2_value,....]* * 以下是RCFile的伪BNF语法. 注释以破折号为前缀** rcfile ::=* <file-header>* <rcfile-rowgroup>+** file-header ::=* <file-version-header>* <file-key-class-name> (only exists if version is seq6)* <file-value-class-name> (only exists if version is seq6)* <file-is-compressed>* <file-is-block-compressed> (only exists if version is seq6)* [<file-compression-codec-class>]* <file-header-metadata>* <file-sync-field>** -- Hive中包含的标准RCFile实现实际上是基于Hadoop的SequenceFile代码的修改版本。* -- 有些本应修改的内容没有修改,包括写出文件版本头的代码。* -- 因此,RCFile和SequenceFile最初共享相同的版本头。较新版本创建了一个唯一的版本字符串。** file-version-header ::= Byte[4] {'S', 'E', 'Q', 6}* | Byte[4] {'R', 'C', 'F', 1}** -- 负责读取行组的 key 缓冲区组件的Java类的名称。** file-key-class-name ::=* Text {"org.apache.hadoop.hive.ql.io.RCFile$KeyBuffer"}** -- 负责读取行组的 value 缓冲区组件的Java类的名称。** file-value-class-name ::=* Text {"org.apache.hadoop.hive.ql.io.RCFile$ValueBuffer"}** -- 布尔变量,指示文件是否对 key 缓冲区和 column 缓冲区部分使用压缩。** file-is-compressed ::= Byte[1]** -- 一个布尔字段,指示文件是否被块压缩。此字段始终为false。* 根据原始RCFile实现中的注释,保留该字段是为了与SequenceFile格式向后兼容。** file-is-block-compressed ::= Byte[1] {false}** -- 压缩编解码器的Java类名* -- 如果是 true. 那么类必须实现 org.apache.hadoop.io.compress.CompressionCodec.* -- 最好是 org.apache.hadoop.io.compress.GzipCodec.** file-compression-codec-class ::= Text** -- 定义文件元数据值的键值对的集合。Map使用标准JDK序列化进行序列化,* -- 即对应于键值对数量的Int,后面是Text键值对。以下元数据属性对于所有RC文件都是强制性的:* --* -- hive.io.rcfile.column.number: RCFile中的列数** file-header-metadata ::= Map<Text, Text>** -- 由写入程序生成的16字节标记。此标记以规则的间隔出现在行组标头的开头,* -- 用于使读取器能够跳过损坏的行组。** file-sync-hash ::= Byte[16]** -- 每个行组分为三个部分:* -- 一个头、一组 key 缓冲区和一组 列 缓冲区。* -- 标头部分包括一个可选的同步哈希、有关行组大小的信息以及行组中的总行数。* -- 每个 key 缓冲区由 RLE (run-length encoding 游程编码) 数据组成,* -- 该数据用于解码相应 列 缓冲区中各个字段的长度和偏移量。** rcfile-rowgroup ::=* <rowgroup-header>* <rowgroup-key-data>* <rowgroup-column-buffers>** rowgroup-header ::=* [<rowgroup-sync-marker>, <rowgroup-sync-hash>]* <rowgroup-record-length>* <rowgroup-key-length>* <rowgroup-compressed-key-length>** -- rowgroup-key-data 如果列数据被压缩,则被压缩。* rowgroup-key-data ::=* <rowgroup-num-rows>* <rowgroup-key-buffers>** -- 一个整数(总是-1),表示同步哈希字段的开始** rowgroup-sync-marker ::= Int** -- 一个16字节的同步字段。这必须与文件头中读取的<file sync hash>值相匹配。** rowgroup-sync-hash ::= Byte[16]** -- 记录长度是用于存储 key 和 column 部分的字节数之和,即当前行组的总长度** rowgroup-record-length ::= Int** -- 行组的 key 的总长度(以字节为单位)** rowgroup-key-length ::= Int** -- 行组的 key 的压缩总长度(以字节为单位)。** rowgroup-compressed-key-length ::= Int** -- 当前行组中的行数。** rowgroup-num-rows ::= VInt** -- 与RCFile中的每一列相对应的一个或多个列的 key 缓冲区。** rowgroup-key-buffers ::= <rowgroup-key-buffer>+** -- 每个 column 缓冲区中的数据使用 RLC 方案来存储,* -- 该方案旨在降低重复列字段值的成本。以下条目将更详细地描述这种机制。** rowgroup-key-buffer ::=* <column-buffer-length>* <column-buffer-uncompressed-length>* <column-key-buffer-length>* <column-key-buffer>** -- 磁盘上相应列缓冲区的序列化长度。.** column-buffer-length ::= VInt** -- 相应列缓冲区的未压缩长度。如果未压缩RCFile,这相当于列缓冲区长度。** column-buffer-uncompressed-length ::= VInt** -- 当前列 key 缓冲区的长度(以字节为单位)** column-key-buffer-length ::= VInt** -- column-key-buffer 包含与对应行组列缓冲区中的序列化列字段的字节长度* -- 相对应的序列化VInt值序列。* -- 例如,考虑一个包含连续值1、2、3、44的整数列。* -- RCFile格式将这些值作为字符串存储在列缓冲区中,例如“12344”。* -- 每个列字段的长度记录在 column-key-buffer 中,作为VInts:1,1,1,2的序列。* -- 然而,如果相同的长度重复出现,那么我们将重复的游程长度替换为重复次数的补码(即负),* -- 因此1,1,1,2变为1,~2,2。** column-key-buffer ::= Byte[column-key-buffer-length]** rowgroup-column-buffers ::= <rowgroup-value-buffer>+** -- RCFile将所有列数据存储为字符串,而与基础列类型无关。* -- 字符串既不是以长度为前缀的,也不是以null结尾的,* -- 将它们解码为单独的字段需要使用相应 column-key-buffer. 中包含的游程长度信息。** rowgroup-column-buffer ::= Byte[column-buffer-length]** Byte ::= An eight-bit byte** VInt ::= 可变长度整数。每个字节的高阶位指示是否还有更多字节需要读取。* 低阶七位被附加为所得整数值中越来越高的有效位。** Int ::= big-endian格式的四字节整数。** Text ::= VInt, Chars (前缀为UTF-8字符的长度)*/
public class RCFile {//......省略......
}五、 优化的行列式文件(ORCFile)
1、概览
诞生时间:2013年1月
目的:加速Hive和Hadoop数据处理速度,减少文件大小。例如Facebook使用了ORC为其减少了10PB的存储空间
ORC是Apache顶级项目
存储格式:二进制,不可直接读、自描述特性(本身存储有文件数据、数据类型、编码信息)不依赖Hive的metastore
官网:Apache ORC • High-Performance Columnar Storage for Hadoop
功能:支持ACID、内置索引、支持Hive所有类型
说明:更准确的标题应该是HDFS的文件格式,因为ORC可以用于MapReduce、Hive、Spark、Flink等等,只是本文章主要讲在Hive中的使用,因此这里这样命名
2、ORC文件结构
ORC文件是一个行列式存储结构
ORC文件结构由三部分组成:条带(stripe)、·文件脚注(file footer)和 postscript
条带(stripe):ORC文件存储数据的地方
文件脚注(file footer):包含了文件中stripe的列表,每个stripe的行 数,以及每个列的
数据类型。它还包含每个列的最小值、最大值、行计数、 求和等聚合信息
postscript:含有压缩参数和压缩大小相关的信息
stripe结构同样可以分为三部分:index data、rows data和stripe footer
index data:保存了所在条带的一些统计信息,以及数据在stripe中的位置索引信息
rows data:数据存储的地方,由多个行组构成,数据以流(stream)的形式进行存储
数据分多个 rows group 存放,每个rows group 存储两部分的数据,即:
metadata stream:用于描述每个行组的元数据信息
data stream:存储数据的地方
stripe footer:保存数据所在的文件目录

综上所述,orc在每个文件中提供了3个级别的索引
文件级:记录文件中所有stripe的位置信息,以及文件中存储的每列数据的统计信息
条带级:记录每个stripe所存储的数据统计信息
行组级:在stripe中,每10000行构成一个组,该级索引记录这个行组中存储数据的统计信息
3、源码查看
源码类:org.apache.hadoop.hive.ql.io.orc.OrcFile
父类:org.apache.orc.OrcFile
package org.apache.orc;import java.io.*;
import java.nio.*;
import java.util.*;
import org.apache.hadoop.*;
import org.apache.orc.impl.*;/***包含读取或写入ORC文件的工厂方法。
*/public class OrcFile {//ORC文件的魔数为 "ORC"public static final String MAGIC = "ORC";public enum Version {V_0_11("0.11", 0, 11),V_0_12("0.12", 0, 12),UNSTABLE_PRE_2_0("UNSTABLE-PRE-2.0", 1, 9999),//所有未知版本的通用标识符。FUTURE("future", Integer.MAX_VALUE, Integer.MAX_VALUE);//当前版本public static final Version CURRENT = V_0_12;//.......省略......}//可以看出 ORC 是支持 Java 、C++ 、Presto 、Go 的public enum WriterImplementation {ORC_JAVA(0), // ORC Java writerORC_CPP(1), // ORC C++ writerPRESTO(2), // Presto writerSCRITCHLEY_GO(3), // Go writer from https://github.com/scritchley/orcUNKNOWN(Integer.MAX_VALUE);//.......省略......}//记录已修复错误的编写器版本。当您修复了编写器中没有更改文件格式的错误//(或进行了实质性更改)时,请在此处添加一个新版本,而不是version。//每个WriterImplementation从6开始按顺序分配id,//以便ORC-202之前的读取器正确对待其他写入程序。public enum WriterVersion {// Java ORC WriterORIGINAL(WriterImplementation.ORC_JAVA, 0),//固定条带/文件最大统计信息&字符串统计信息使用utf8表示最小值/最大值HIVE_8732(WriterImplementation.ORC_JAVA, 1),//使用 Hive 表中的实际列名HIVE_4243(WriterImplementation.ORC_JAVA, 2),//矢量化写入器HIVE_12055(WriterImplementation.ORC_JAVA, 3), //小数正确写入当前流HIVE_13083(WriterImplementation.ORC_JAVA, 4),//bloom 过滤器使用utf8ORC_101(WriterImplementation.ORC_JAVA, 5),//时间戳统计使用utcORC_135(WriterImplementation.ORC_JAVA, 6),//decimal64 min/max是固定的ORC_517(WriterImplementation.ORC_JAVA, 7), //C++ ORC WriterORC_CPP_ORIGINAL(WriterImplementation.ORC_CPP, 6),// Presto WriterPRESTO_ORIGINAL(WriterImplementation.PRESTO, 6),// Scritchley Go WriterSCRITCHLEY_GO_ORIGINAL(WriterImplementation.SCRITCHLEY_GO, 6),// 除了以下数字外,不要在此处使用任何幻数://除了以下数字外,不要在此处使用任何幻数://来自未来的版本FUTURE(WriterImplementation.UNKNOWN, Integer.MAX_VALUE); //.......省略......}//当前版本的WriterVersion。public static final WriterVersion CURRENT_WRITER = WriterVersion.ORC_517;//编码策略 public enum EncodingStrategy {SPEED, COMPRESSION}//压缩策略public enum CompressionStrategy {SPEED, COMPRESSION}//用于创建ORC文件读取器的选项。public static class ReaderOptions {//.......省略......}public static Reader createReader(Path path,ReaderOptions options) throws IOException {return new ReaderImpl(path, options);}public interface WriterContext {Writer getWriter();}public interface WriterCallback {void preStripeWrite(WriterContext context) throws IOException;void preFooterWrite(WriterContext context) throws IOException;}public enum BloomFilterVersion {}//用于创建ORC文件编写器的选项。public static class WriterOptions implements Cloneable {//.......省略......}//创建一个ORC文件编写器。这是用于创建编写器的公共接口,新选项只会添加到该方法中。public static Writer createWriter(Path path,WriterOptions opts) throws IOException {//.......省略......}//合并所有具有相同架构的多个ORC文件以生成单个ORC文件。//合并将拒绝与合并文件不兼容的文件,因此输出列表可能比输入列表短。//条带被复制为串行字节缓冲区。用户元数据被合并,对与键相关联的值不一致的文件将被拒绝。public static List<Path> mergeFiles(Path outputPath,WriterOptions options,List<Path> inputFiles) throws IOException {//.......省略......}}
六、 Apache Parquet /pɑːrˈkeɪ/
1、概览
Parquet也是Apache顶级项目
官网:Parquet (apache.org)
源码下载地址:Release apache-parquet-format-2.10.0 · apache/parquet-format · GitHub
(里面又源码和说明文档)
Parquet也是一种行列式存储结构
Parquet旨在支持非常高效的压缩和编码方案
Parquet也同ORC一样记录这些数据的元数据(表结构、行数、列的情况以及偏移量等等)
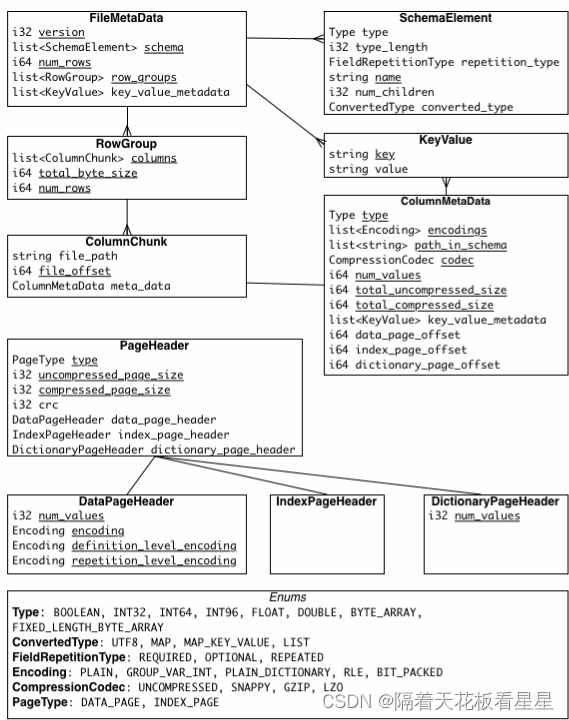
2、Parquet文件结构
和ORC一样,数据被分为多个行组,不同的是Parquet把每个列由分为若干个Page
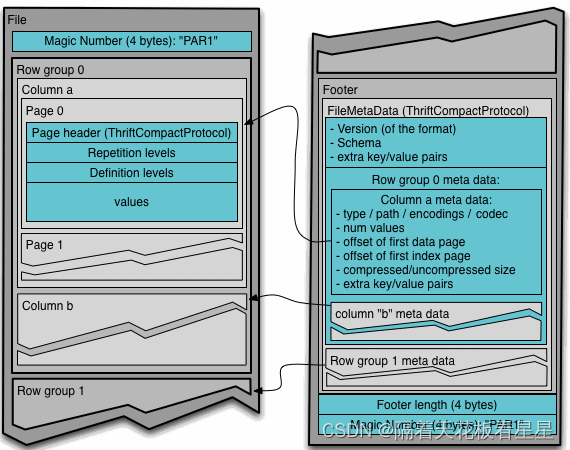

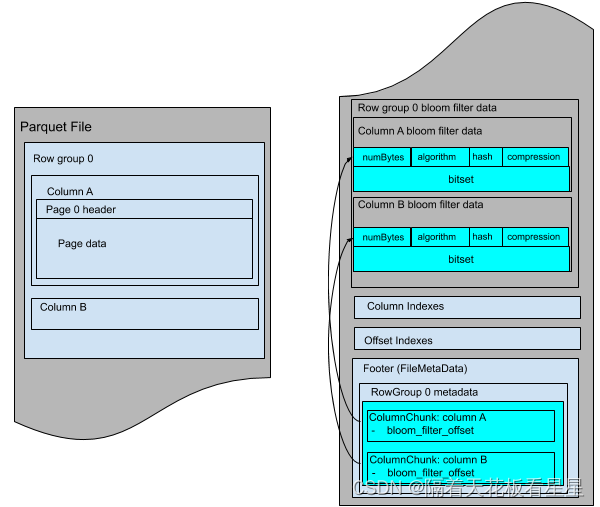
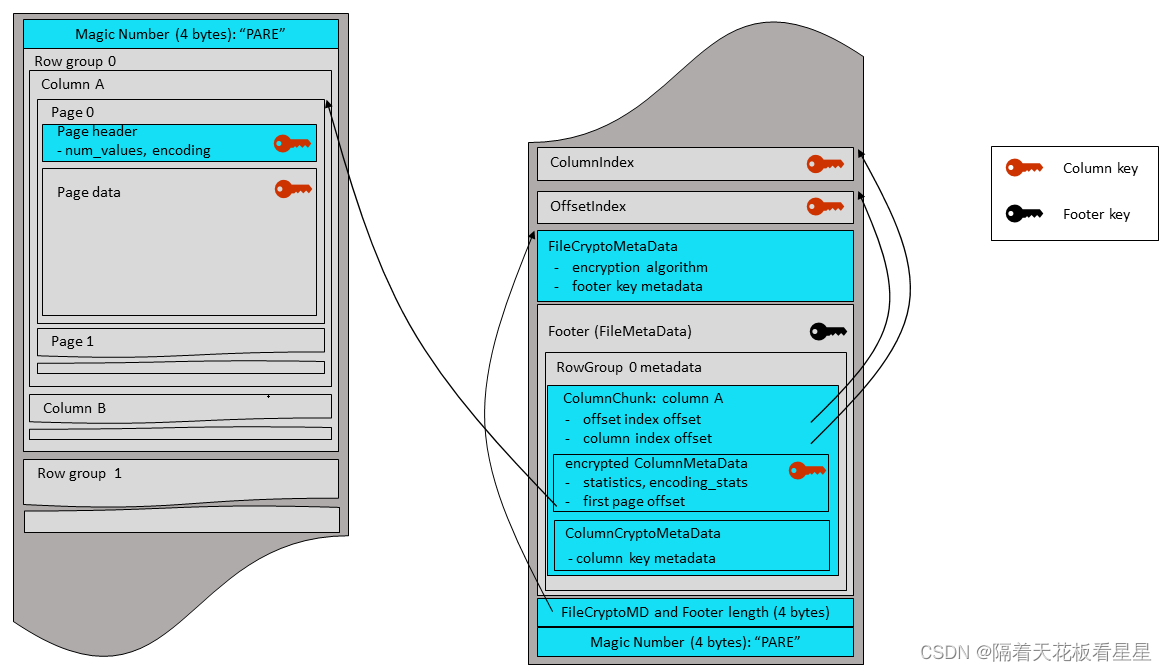


七、五种文件格式对比
1、建表
-----textfile格式建表-----
create table test.user_msg_text(id string,telno string,visit_url string,status string,visit_time int,visit_num int)
partitioned by (dt string)
row format delimited
fields terminated by ','
stored as textfile ;-----sequencefile格式建表-----
create table test.user_msg_sequencefile(id string,telno string,visit_url string,status string,visit_time int,visit_num int)
partitioned by (dt string)
row format delimited
fields terminated by ','
stored as sequencefile ;-----rcfile格式建表-----
create table test.user_msg_rcfile(id string,telno string,visit_url string,status string,visit_time int,visit_num int)
partitioned by (dt string)
row format delimited
fields terminated by ','
stored as rcfile ;-----orc格式建表-----
create table test.user_msg_orc(id string,telno string,visit_url string,status string,visit_time int,visit_num int)
partitioned by (dt string)
row format delimited
fields terminated by ','
stored as orc ;-----parquet格式建表-----
create table test.user_msg_parquet(id string,telno string,visit_url string,status string,visit_time int,visit_num int)
partitioned by (dt string)
row format delimited
fields terminated by ','
stored as parquet ;
2、制作数据
vi 111.csv
134xxxx6398,weixin.qq.com,200,6941611,2984
cat 100.csv >> 1000.csv
cat 100.csv >> 1000.csv
cat 100.csv >> 1000.csv
cat 100.csv >> 1000.csv
cat 100.csv >> 1000.csv
cat 100.csv >> 1000.csv
cat 100.csv >> 1000.csv
cat 100.csv >> 1000.csv
cat 100.csv >> 1000.csv
cat 100.csv >> 1000.csv
wc 1000.csv
#1000
cat 1000.csv >> 10000.csv
cat 1000.csv >> 10000.csv
cat 1000.csv >> 10000.csv
cat 1000.csv >> 10000.csv
cat 1000.csv >> 10000.csv
cat 1000.csv >> 10000.csv
cat 1000.csv >> 10000.csv
cat 1000.csv >> 10000.csv
cat 1000.csv >> 10000.csv
cat 1000.csv >> 10000.csv
wc 10000.csv
#10000
cat 10000.csv >> 100000.csv
cat 10000.csv >> 100000.csv
cat 10000.csv >> 100000.csv
cat 10000.csv >> 100000.csv
cat 10000.csv >> 100000.csv
cat 10000.csv >> 100000.csv
cat 10000.csv >> 100000.csv
cat 10000.csv >> 100000.csv
cat 10000.csv >> 100000.csv
cat 10000.csv >> 100000.csv
wc 100000.csv
#100000
cat 100000.csv >> 1000000.csv
cat 100000.csv >> 1000000.csv
cat 100000.csv >> 1000000.csv
cat 100000.csv >> 1000000.csv
cat 100000.csv >> 1000000.csv
cat 100000.csv >> 1000000.csv
cat 100000.csv >> 1000000.csv
cat 100000.csv >> 1000000.csv
cat 100000.csv >> 1000000.csv
cat 100000.csv >> 1000000.csv
wc 1000000.csv
#1000000
cat 1000000.csv >> 10000000.csv
cat 1000000.csv >> 10000000.csv
cat 1000000.csv >> 10000000.csv
cat 1000000.csv >> 10000000.csv
cat 1000000.csv >> 10000000.csv
cat 1000000.csv >> 10000000.csv
cat 1000000.csv >> 10000000.csv
cat 1000000.csv >> 10000000.csv
cat 1000000.csv >> 10000000.csv
cat 1000000.csv >> 10000000.csv
wc 10000000.csv
#10000000
cat 10000000.csv >> 100000000.csv
cat 10000000.csv >> 100000000.csv
cat 10000000.csv >> 100000000.csv
cat 10000000.csv >> 100000000.csv
cat 10000000.csv >> 100000000.csv
cat 10000000.csv >> 100000000.csv
cat 10000000.csv >> 100000000.csv
cat 10000000.csv >> 100000000.csv
cat 10000000.csv >> 100000000.csv
cat 10000000.csv >> 100000000.csv
wc 100000000.csv
#100000000awk '{printf("%d,%s\n",NR,$0)}' 100000000.csv>> test_data_1y.csv3、加载数据
load data local inpath '/root/temp/test_data_1y.csv' into table test.user_msg partition(dt='20240627');
Time taken: 38.869 seconds
insert into test.user_msg_sequencefile partition(dt='20240627') select
id ,telno ,visit_url ,status ,visit_time ,visit_num from test.user_msg_text where dt='20240627' ;
Time taken: 48.752 seconds
insert into test.user_msg_rcfile partition(dt='20240627') select
id ,telno ,visit_url ,status ,visit_time ,visit_num from test.user_msg_text where dt='20240627' ;
Time taken: 40.362 seconds
insert into test.user_msg_orc partition(dt='20240627') select
id ,telno ,visit_url ,status ,visit_time ,visit_num from test.user_msg_text where dt='20240627' ;
Time taken: 73.569 seconds
insert into test.user_msg_parquet partition(dt='20240627') select
id ,telno ,visit_url ,status ,visit_time ,visit_num from test.user_msg_text where dt='20240627' ;
Time taken: 50.563 seconds4、存储对比
hadoop fs -du -h /user/hive/warehouse/test.db

5、性能对比
select count(1) from test.user_msg_text where dt = '20240627' ;
Time taken: 54.92 seconds, Fetched: 1 row(s)
select count(1) from test.user_msg_sequencefile where dt = '20240627' ;
Time taken: 44.623 seconds, Fetched: 1 row(s)
select count(1) from test.user_msg_rcfile where dt = '20240627' ;
Time taken: 35.356 seconds, Fetched: 1 row(s)
select count(1) from test.user_msg_orc where dt = '20240627' ;
Time taken: 36.07 seconds, Fetched: 1 row(s)
select count(1) from test.user_msg_parquet where dt = '20240627' ;
Time taken: 49.309 seconds, Fetched: 1 row(s)select sum(visit_num) from test.user_msg_text where dt = '20240627' ;
Time taken: 42.698 seconds, Fetched: 1 row(s)
select sum(visit_num) from test.user_msg_sequencefile where dt = '20240627' ;
Time taken: 45.819 seconds, Fetched: 1 row(s)
select sum(visit_num) from test.user_msg_rcfile where dt = '20240627' ;
Time taken: 39.971 seconds, Fetched: 1 row(s)
select sum(visit_num) from test.user_msg_orc where dt = '20240627' ;
Time taken: 37.584 seconds, Fetched: 1 row(s)
select sum(visit_num) from test.user_msg_parquet where dt = '20240627' ;
Time taken: 45.688 seconds, Fetched: 1 row(s)select * from test.user_msg_text where dt = '20240627' and id = '999999' ;
Time taken: 31.185 seconds, Fetched: 1 row(s)
select * from test.user_msg_sequencefile where dt = '20240627' and id = '999999' ;
Time taken: 55.459 seconds, Fetched: 1 row(s)
select * from test.user_msg_rcfile where dt = '20240627' and id = '999999' ;
Time taken: 44.476 seconds, Fetched: 1 row(s)
select * from test.user_msg_orc where dt = '20240627' and id = '999999' ;
Time taken: 46.568 seconds, Fetched: 1 row(s)
select * from test.user_msg_parquet where dt = '20240627' and id = '999999' ;
Time taken: 111.57 seconds, Fetched: 1 row(s)