数据持久化层
冷热分离
-
冷热分离:将常用的“热”数据和不常使用的“冷”数据分开存储
-
冷热分离就是在处理数据时将数据库分成冷库和热库,冷库存放那些走到终态、不常使用的数据,热库存放还需要修改、经常使用的数据
-
业务需求出现了以下情况,就可以考虑使用冷热分离的解决方案。
-
1)数据走到终态后只有读没有写的需求,比如订单完结状态。
-
2)用户能接受新旧数据分开查询,比如有些电商网站默认只让查询3个月内的订单,如果要查询3个月前的订单,还需要访问其他的页面
-
冷热分离的实际操作过程中,需要考虑以下问题。
-
1)如何判断一个数据是冷数据还是热数据?
主要采用主表里一个字段或多个字段的组合作为区分标识
如果一个数据被标识为冷数据,业务代码不会再对它进行写操作。
不会同时存在读取冷、热数据的需求。 -
2)如何触发冷热数据分离?
1)直接修改业务代码,使得每次修改数据时触发冷热分离
建议在业务代码比较简单,并且不按照时间区分冷热数据时使用
2)通过监听数据库变更日志binlog的方式来触发。
具体方法就是另外创建一个服务,这个服务专门用来监控数据库的binlog,一旦发现ticket表有变动,
就将变动的工单数据发送到一个队列,这个队列的订阅者将会取出变动的工单,触发冷热分离逻辑
建议在业务代码比较复杂,不能随意变更,并且不按时间区分冷热数据时使用
3)通过定时扫描数据库的方式来触发。
这个方式就是通过quartz配置一个本地定时任务,或者通过类似于xxl-job的分布式调度平台配置一个定时任务。
这个定时任务每隔一段时间就扫描一次热数据库里面的工单表,找出符合冷数据标准的工单数据,进行冷热分离建议在按照时间区分冷热数据时使用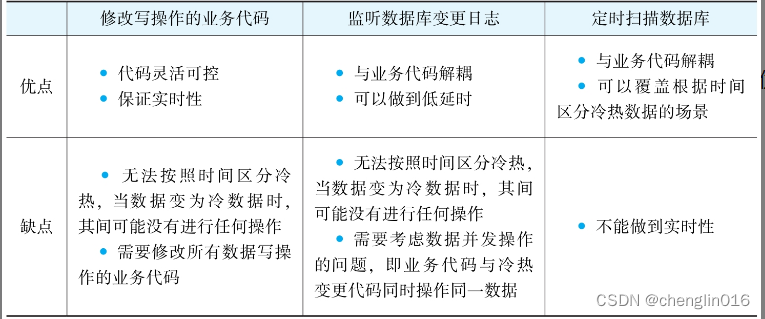 -
3)如何实现冷热数据分离?
分离冷热数据的基本逻辑:
1)判断数据是冷是热。
2)将要分离的数据插入冷数据库中。
3)从热数据库中删除分离的数据。
注意数据的“最终一致性”,保持每一步操作的幂等性,操作的原子性,锁,多线程等。 -
4)如何使用冷热数据?
-
在判断是冷数据还是热数据时,必须确保用户没有同时读取冷热数据的需求 -
5)历史数据如何迁移?
单独处理历史数据。 -
数据库的分区:并不是生成新的数据表,而是将表的数据均衡分配到不同的硬盘、系统或不同的服务器存储介质中,实际上还是一张表
-
数据库分区有以下优点。
-
1)比起单个文件系统或硬盘,分区可以存储更多的数据。
-
2)在清理数据时,可以直接删除废弃数据所在的分区。同样,有新数据时,可以增加更多的分区来存储新数据。
-
3)可以大幅度地优化特定的查询,让这些查询语句只去扫描特定分区的数据。比如,原来有2000万的数据,设计10个分区,每个分区存200万的数据,那么可以优化查询语句,让它只去查询其中两个分区,即只需要扫描400万的数据。
查询分离
-
即每次写数据时保存一份数据到其他的存储系统里,用户查询数据时直接从中获取数据
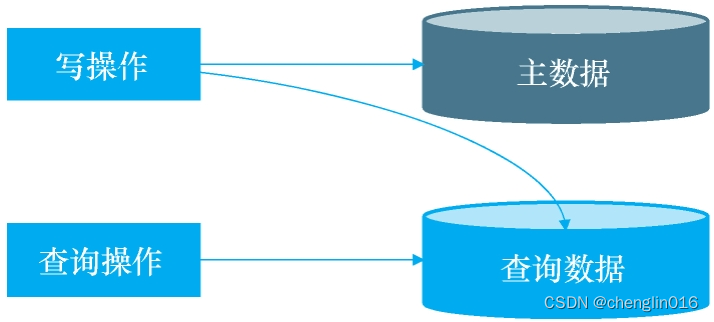
考虑使用查询分离场景:
1)数据量大:比如单个表的行数有上千万,当然,如果几百万就出现查询慢的问题,也可以考虑使用。
2)查询数据的响应效率很低:因为表数据量大,或者关联查询太过复杂,导致查询很慢的情况。
3)所有写数据请求的响应效率尚可:虽然查询慢,但是写操作的响应速度还可以接受的情况。
4)所有数据任何时候都可能被修改和查询:这一点是针对冷热分离的,因为如果有些数据走入终态就不再用到,就可以归档到冷数据库了,不一定要用查询分离这个方案 -
查询分离的实现思路:
1)如何触发查询分离?
2)如何实现查询分离?
3)查询数据如何存储?
4)查询数据如何使用?
5)历史数据如何迁移?

-如何触发查询分离?
-
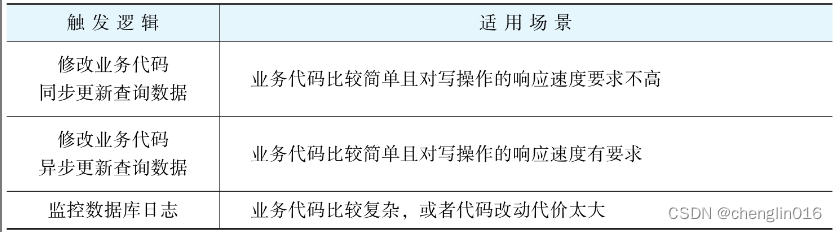
查询分离的触发逻辑分为3种
1)修改业务代码,在写入常规数据后同步更新查询数据
2)修改业务代码,在写入常规数据后,异步更新查询数据
3)监控数据库日志,如有数据变更,则更新查询数据

-
如何实现查询分离?
考虑使用MQ(Message Queue,消息队列):MQ的具体操作思路为,每次程序处理主数据写操作请求时,
都会发一个通知给MQ,MQ收到通知后唤醒一个线程来更新查询数据 -
3)查询数据如何存储?
Elasticsearch实现大数据量的搜索查询,当然还可能用到MongoDB、HBase这些技术 -
4 )查询数据如何使用
因Elasticsearch自带API,所以使用查询数据时,在查询业务代码中直接调用Elasticsearch的API即可。
数据查询更新完前,查询数据不一致怎么办?
1)在查询数据更新到最新前,不允许用户查询。
2)给用户提示:“您目前查询到的数据可能是2秒前的数据,如果发现数据不准确,可以尝试刷新一下。”这种提示用户一般都能接受。 -
- 历史数据迁移
MQ+Elasticsearch的整体方案
1)使用异步方式触发查询数据的同步。当工单修改后,会异步启动一个线程来同步工单数据到查询数据库。
2)通过MQ来实现异步的效果。MQ还做了两件事:①服务的解耦,将工单主业务系统和查询系统的服务解耦;②削峰,当修改工单的并发请求太多时,通过MQ控制同步查询数据库的线程数,防止查询数据库的同步请求太大。
3)将工单的查询数据存储在Elasticsearch中。因为Elasticsearch是一个分布式索引系统,天然就是用来做大数据的复杂查询的。
4)因为查询数据同步到Elasticsearch会有一定的延时,所以用户可能会查询到旧的工单数据,所以要给用户一些提示。
5)关于历史数据的迁移,因为是用字段NeedUpdateQueryData来标识工单是否需要同步,所以只要把所有历史数据的标识改成true,系统就会自动批量将历史数据同步到Elasticsearch
分表分库
-
分表是将一份大的表数据进行拆分后存放至多个结构一样的拆分表中;
-
分库就是将一个大的数据库拆分成类似于多个结构的小数据库
-
如果使用分表分库,有3个通用技术需求需要实现。
1)SQL组合:因为关联的表名是动态的,所以需要根据逻辑组装动态的SQL。比如,要根据一个订单的ID获取订单的相关数据,Select语句应该针对(From)哪一张表?
2)数据库路由:因为数据库名也是动态的,所以需要通过不同的逻辑使用不同的数据库。比如,如果要根据订单ID获取数据,怎么知道要连接哪一个数据库?
3)执行结果合并:有些需求需要通过多个分库执行后再合并归集起来。假设需要查询的数据分布在多个数据库的多个表中(比如在order1里面的t_order_1,order2里面的t_order_9中),那么需要将针对这些表的查询结果合并成一个数据集 -
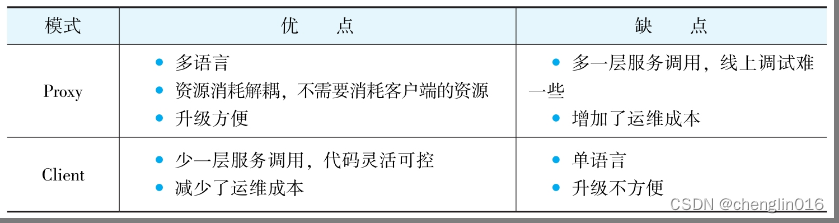
1)Proxy模式:
这种设计模式将SQL组合、数据库路由、执行结果合并等功能全部放在了一个代理服务中,
而与分表分库相关的处理逻辑全部放在了其他服务中,
其优点是对业务代码无侵入,业务只需要关注自身业务逻辑即可

-
2)Client模式:
这种设计模式将分表分库相关逻辑放在客户端,
一般客户端的应用会引用一个jar,然后在jar中处理SQL组合、数据库路由、执行结果合并等相关功能。

-
分表分库方案5个要点
1)使用什么字段作为分片主键?
2)分片的策略是什么?
分片策略分为根据范围分片、根据Hash值分片、根据Hash值及范围混合分片
3)业务代码如何修改?
4)历史数据如何迁移?
5)未来的扩容方案是什么? -
数据迁移方案的基本思路为:
旧架构继续运行,存量数据直接迁移,增量数据监听binlog,然后通过canal通知迁移程序迁移数据,等到新的数据库拥有全量数据且校验通过后再逐步切换流量到新架构。 -
数据迁移解决方案的详细步骤如下
1)上线canal,通过canal触发增量数据的迁移。
2)迁移数据脚本测试通过后,将老数据迁移到新的分表分库中。
3)注意迁移增量数据与迁移老数据的时间差,确保全部数据都被迁移过去,无任何遗漏。
4)此时新的分表分库中已经拥有全量数据了,可以运行数据验证程序,确保所有数据都存放在新数据库中。 -
扩容方案主要依赖以下两点。
1)分片策略是否可以让新表数据的迁移源只有一个旧表,而不是多个旧表?这就是前面建议使用2n分表的原因——以后每次扩容都能扩为2倍,都是把原来一张表的数据拆分到两张表中。
2)数据迁移。需要把旧分片的数据迁移到新的分片上,这个方案与上面提及的历史数据迁移一样,此处不再赘述