1.服务器环境以及配置
| 处理器: | Intel |
| 内存: | 126G |
【内核版本】
4.19.90-25.16.v2101.ky10.x86_64
【银河麒麟操作系统镜像版本】
Kylin-Server-10-SP2-Release-Shenzhen-Metro-x86-Build01-20220619
Kylin-HA-10-SP2-Release-Shenzhen-Metro-Build01-20220620-x86_64
【第三方软件】
传统售票业务软件、互联网售票业务软件,k8s
2.问题现象描述
近期站点存在站点频繁重启问题,分析查看日志,查看高可用心跳link频繁存在up \down问题,触发fence导致重启。临时调整了token值,但是目前效果不明显,软件厂家表示各厂家占用内存不高,不是导致oom问题的原因。
3.问题分析
通过收集的2套,近期出现过HA集群服务器被fence的系统sosreport日志,可知,主机ZP1403SV01在2024.04.10 09:35:37和主机ZP1417SV02在2024.04.01 11:40:39左右,被fence,发生过系统重启。如图1和图2:


图1

图2
分析主机ZP1417SV02系统日志,可知,系统在2024.04.01 11:40:39左右,系统被fence重启之前,有检测到corosync检测心跳状态服务,有4秒超时响应的日志信息输出,“Token has not been received in 4634 ms”,如图3:
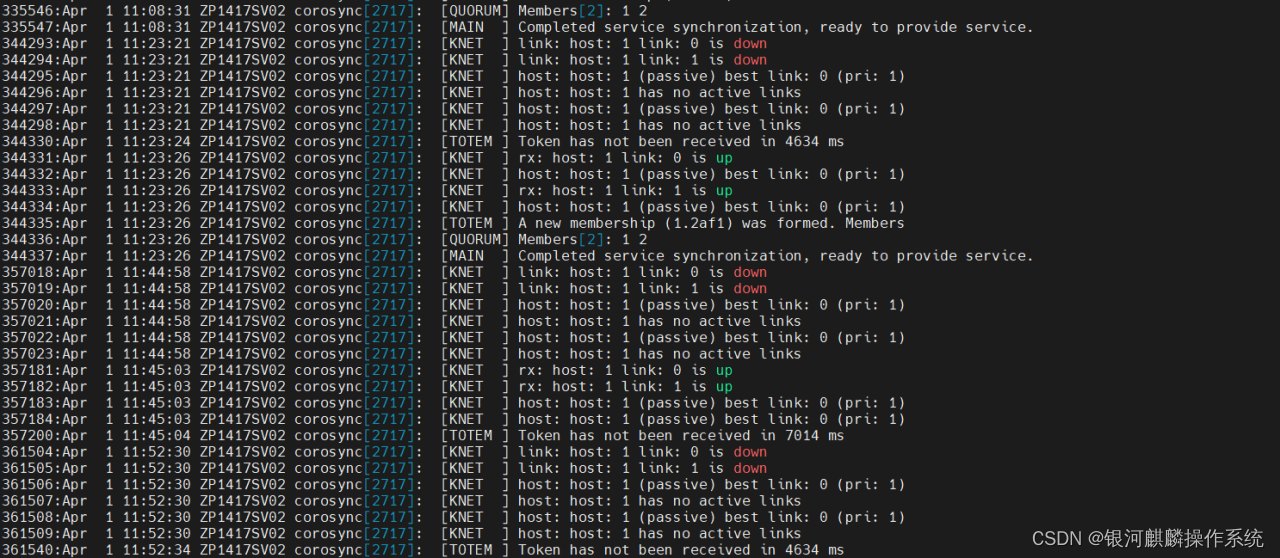
图3
进一步分析主机ZP1417SV02系统日志,可以看到,在corosync服务报出检测心跳超时的同时,也有很多k8s服务相关进程被oom-killer的日志信息输出,报出的堆栈信息基本一致。分析其中一个,堆栈报错。可知,elastic-operato进程,在申请内存的时候,显示内核进入到mem_cgroup_out_of_memory这个路径后,分配不到内存,导致oom产生选择elastic-operato进程kill掉,如图4和图5:
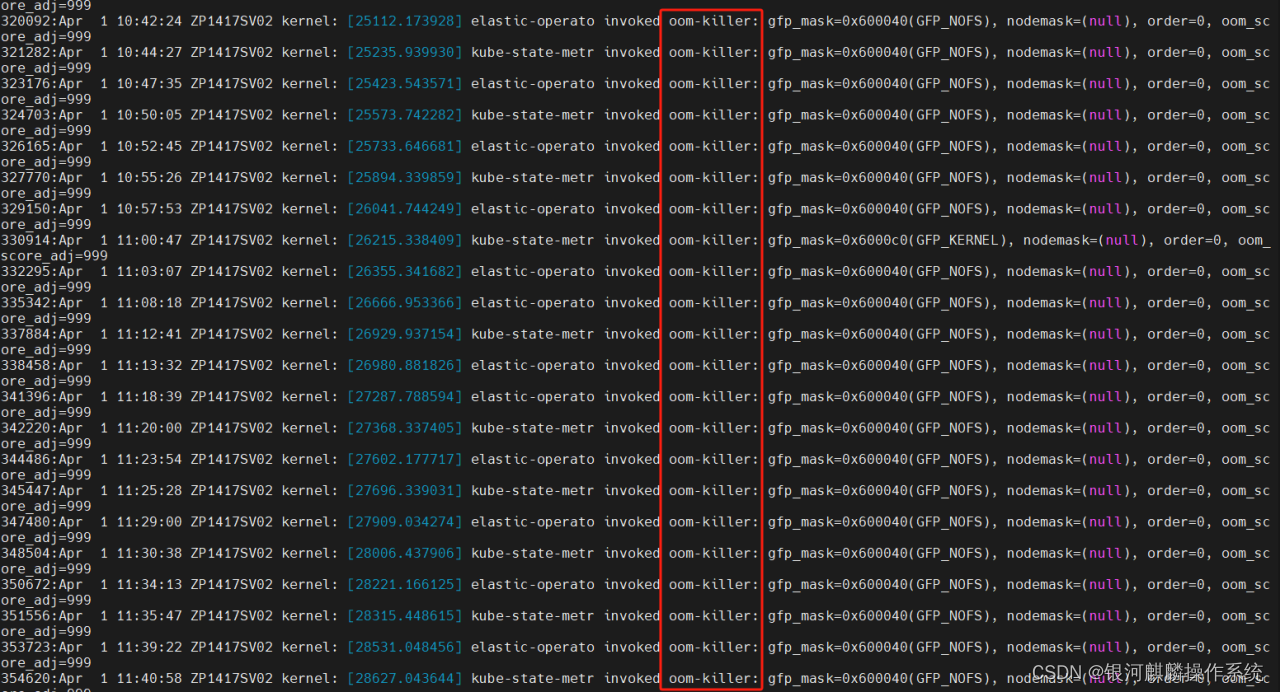
图4
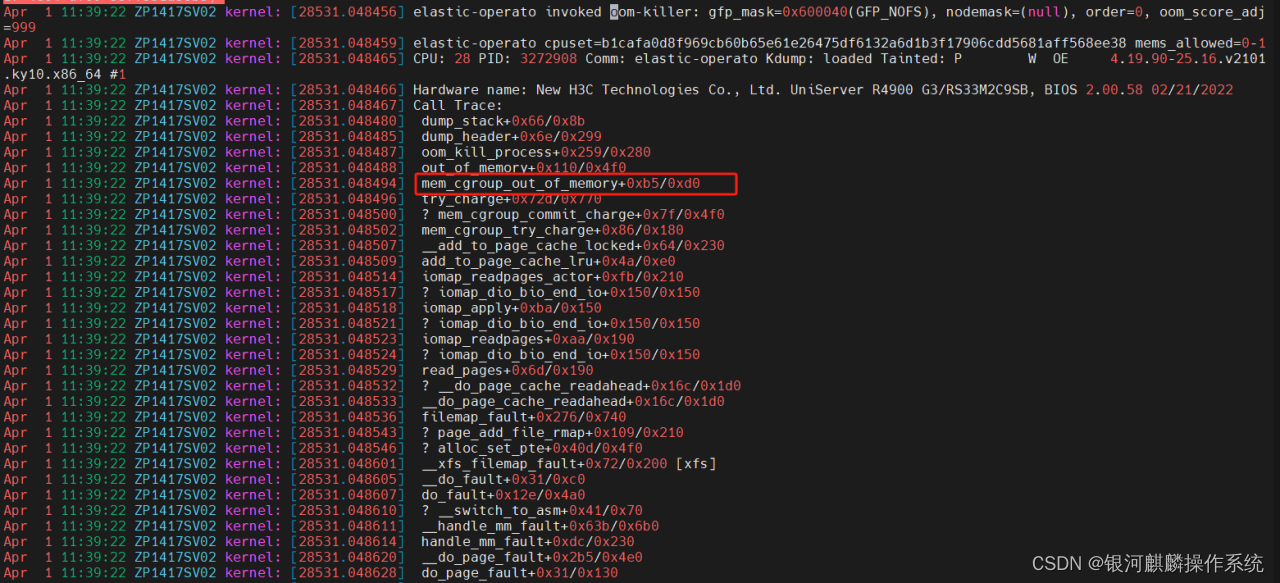
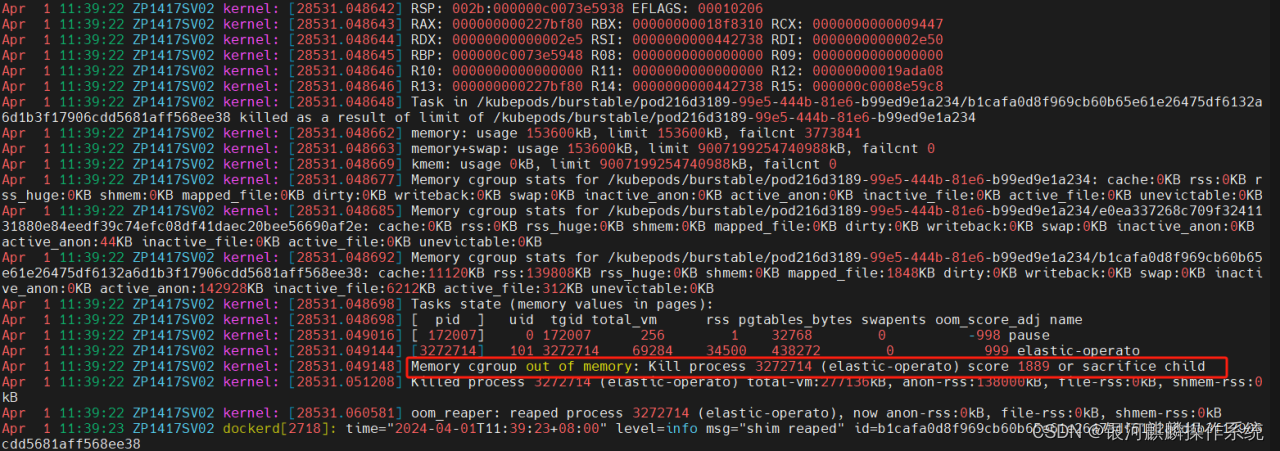
图5
由此oom-killer报错信息,联想到,有一个已知系统内核bug,对于银河麒麟操作系统V10 SP1/SP2低版本内核内存水位线计算不准确,会频繁OOM这一问题。
进一步,分别查看分析,4台系统节点的Zone Normal的内存水位线。查看/proc/zoneinfo,发现这4台主机节点ZP1403SV01、ZP1403SV02、ZP1417SV01和ZP1417SV02,Node 0和Node1,zone Movable显示不正常,spanned ,present为0,但是managed 很大。正常应spanned=present=managed=0,或者spanned>present>managed。如图6至图9:
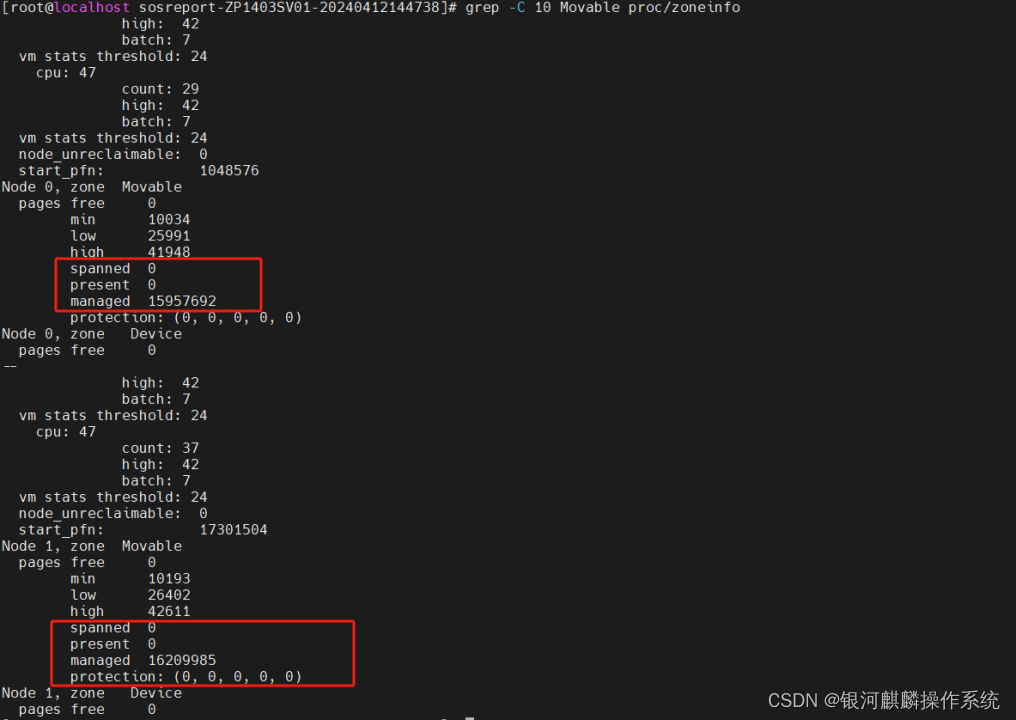
图6 ZP1403SV01
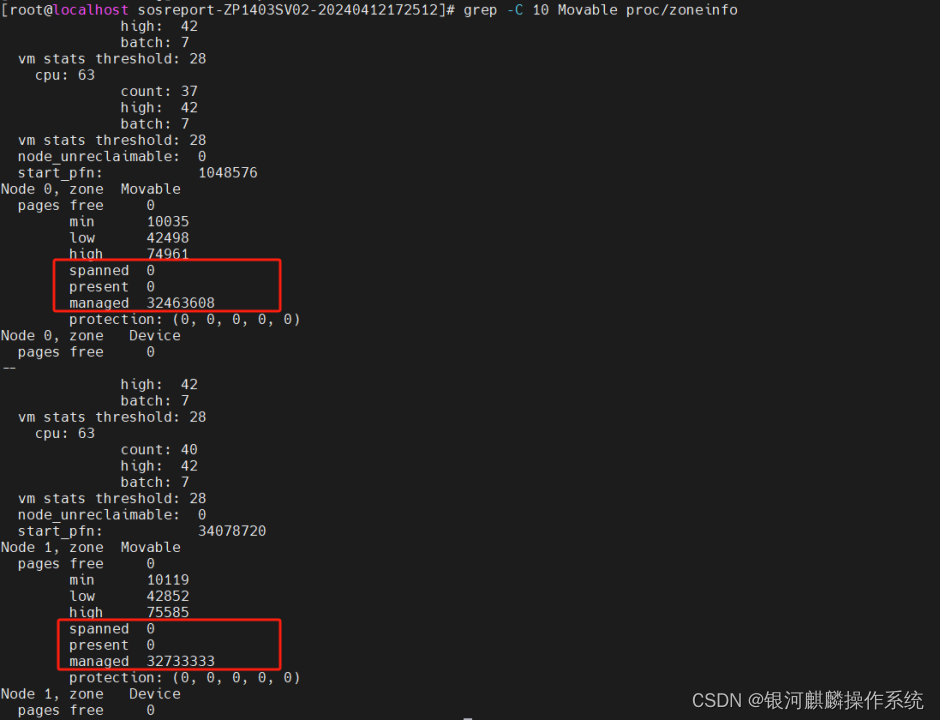
图7 ZP1403SV02
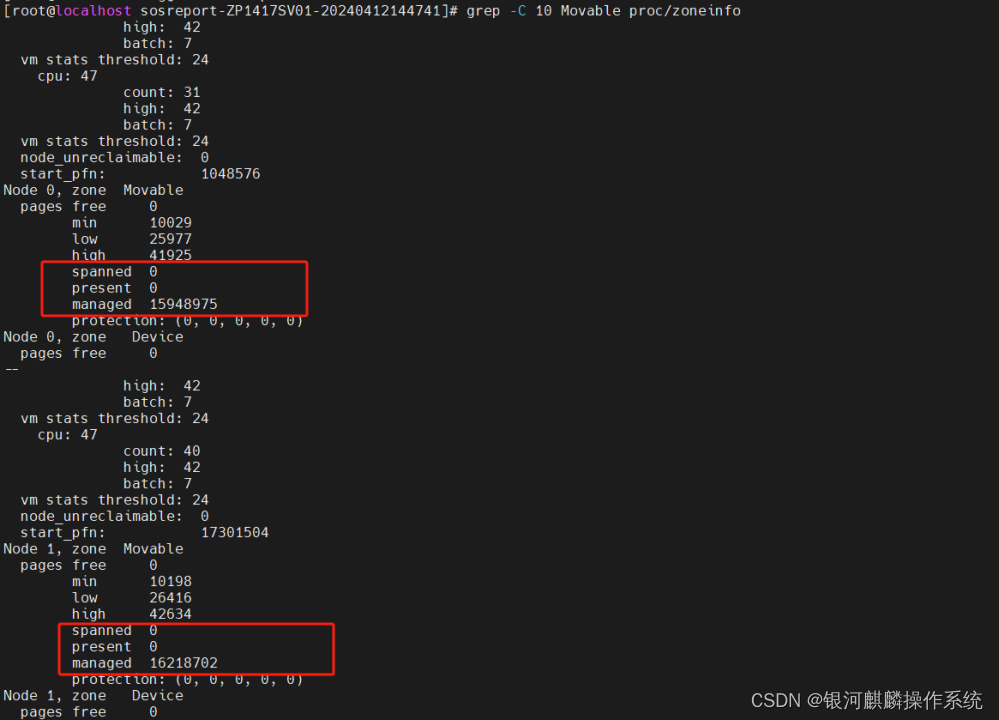
图8 ZP1417SV01
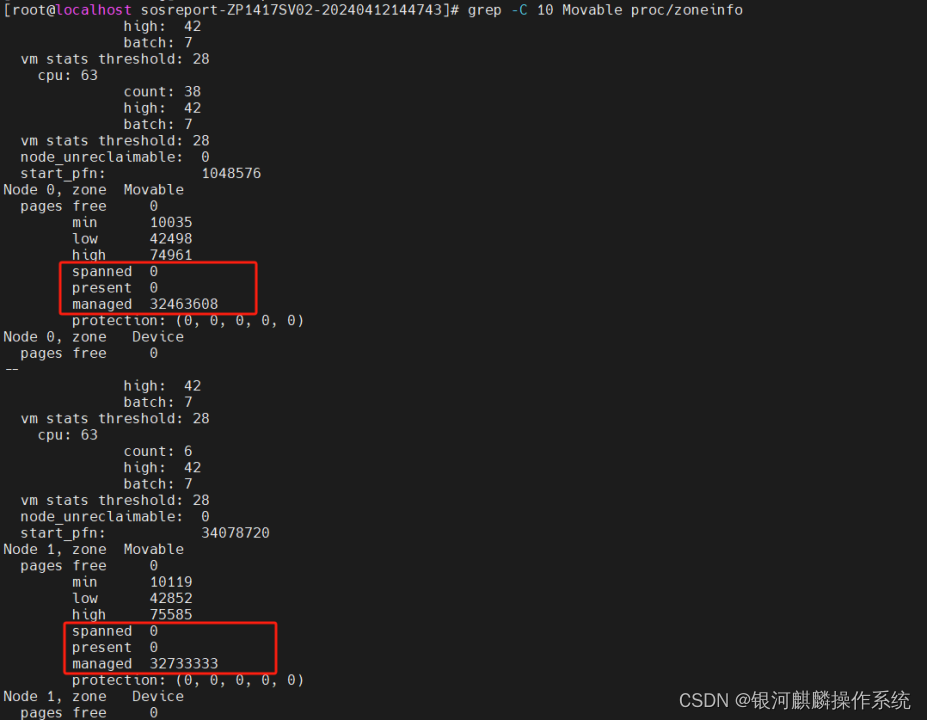
图9 ZP1417SV02
对于银河麒麟V10 SP1/SP2低版本内核内存水位线计算不准确,会频繁OOM这一问题,为已知bug。该bug是由于openeuler内核(麒麟内核基于openeuler内核开发)在优化内存时引入了一个bug(commit eb761d6521c32c006a4987260394a61c6684fb35: mm: parallelize deferred struct page initialization within each node),其会导致内存zone的managed_pages统计出现错位。
目前麒麟软件及openeuler都已在官网发布了内核修复公告,麒麟内核在SP1 23.30、SP2 25.22版本得到修复,SP3内核不存在这个BUG。
公告链接地址:KYBA-202212-1011 - 国产操作系统、麒麟操作系统——麒麟软件官方网站
4.此内核bug的分析说明
1)内核bug对水位线计算错误的原理以及是否影响所有内存区
本次BUG引发的原因是内核代码引入了不严谨的代码,在计算zone中管理的page的数量可能出现错位。
打个比方系统有3个zone,其管page数量分别如下:
1号zone 10个,page 2号zone是100个,page 3号zone是100000个page。而系统在计算水位是依据各个zone的page数量来计算, page数量越多,水位越高,如果page数据统计错误,比如3号zone的page数量算成了100,将导致3号zone的水位严重偏低 。
接着我们从问题patch代码的出错行来看看问题发生的原因:
WARN_ON(++zid < MAX_NR_ZONES && populated_zone(++zone)); VM_BUG_ON(nr_init != nr_free); zone->managed_pages += nr_free;
问题代码如上所示,这里本意是要统计zone中managed_pages的数量,将其加上nr_free,但是前面的WARN_ON(++zid < MAX_NR_ZONES && populated_zone(++zone));有可能将zone进行自加,将要统计的nr_free统计到下一个zone上面去了, 比如要统计的1号zone上面的,结果++zone后变成2号zone了,出现统计错位,这有可能会影向所有的zone的统计 。
2)水位线计算错误是否必定出现
对于不同机型,不一定必定出现,对于同一机型只要一台出问题,则其它的都有问题。
接着上一节的代码继续说明,产生这种现象的原因如下: 因为要出现统计错位,则必需要运行++zone这个代码才行, WARN_ON(++zid < MAX_NR_ZONES && populated_zone(++zone)); 如果++zid < MAX_NR_ZONES为假,则后面的++zone不会运行,也就不会出现问题,反之则出现问题。
3)高版本内核是否一定能完全解决内存水位计算异常
高版本内核一定能完全解决这个内存水位计算异常问题,因为这个bug非常明确,如上所说,只需把++zone这个操作放在zone->manage_pages += nr_free后面即可。
当前内核修改完成的代码如下:
zone->managed_pages += nr_free; /* Sanity check that the next zone really is unpopulated */
WARN_ON(++zid < MAX_NR_ZONES && populated_zone(++zone)); //++zone后,后面的代码没有出现引用
zone pr_info("node %d initialised, %lu pages in %ums\n", nid, nr_free, jiffies_to_msecs(jiffies - start)); pgdat_init_report_one_done(); return 0; }
4)managed不为0,spanned,present都为0与bug的关系
这个问题出现的原因也是如第一条问题的答复,内核在统计zone中managed_pages的数量时可能会出现zone进行自加,将要统计的nr_free统计到下一个zone上面。
而Linux系统并非所有node、zone都管理着内存,比如通常zone Movable、zone Device默认都不管理内存;一些开启了numa的机器在非node 0的节点上可能也只有一个zone管理着内存。这是要是触发了上述bug,就会将上一个zone的managed统计到这个spanned presend managed本该都为0的zone上。这时就会产生managed不为0,spanned,present都为0的现象。
5.问题分析结果
结合,之前出现过此问题的现象研发侧的分析情况,可知,空闲内存过小,在业务突然繁忙时大量的page cache会消耗掉free memory,容易导致corosync延迟处理。有可能,会导致心跳检测超时,触发fence。
对于银河麒麟V10 SP1/SP2低版本内核内存水位线计算不准确,会频繁OOM这一问题,会产生的影响有,机器长时间运行后都有概率出现,内存水位太低,长时间运行后碎片化严重,机器使用久了,所有申请大块内存的都会有问题。导致正常的内存申请,都有问题,从而可能会影响HA集群心跳监控服务corosync服务,延迟处理心跳事件,有风险触发fence动作,系统重启。
6.后续计划与建议
建议,升级银河麒麟V10-SP2-x86服务器系统的内核,到4.19.90-25.22.v2101.ky10.x86_64版本及其以上,运行观察一段时间。
外网源内核下载地址:
Index of /NS/V10/V10SP2/os/adv/lic/updates/x86_64/Packages/