第1关:句法分析概述
任务描述
本关任务:通过对句法分析基本概念的学习,完成相应的选择题。
相关知识
为了完成本关任务,你需要掌握:
-
句法分析的基础概念;
-
句法分析的数据集和评测方法。
句法分析简介
句法分析( syntactic parsing )是自然语言处理中的关键技术之一,它是对输入的文本句子进行分析以得到句子的句法结构的处理过程。对句法结构进行分析,一方面是语言理解的自身需求,句法分析是语言理解的重要一环,另一方面也为其它自然语言处理任务提供支持。例如句法驱动的统计机器翻译需要对源语言或目标语言(或者同时两种语言)进行句法分析。
从20世纪50年代初机器翻译课题被提出时算起,自然语言处理研究已经有60余年的历史,句法分析一直是自然语言处理前进的巨大障碍。句法分析主要有以下两个难点:
-
歧义。自然语言区别于人工语言的一个重要特点就是它存在大量的歧义现象。人类自身可以依靠大量的先验知识有效地消除各种歧义,而机器由于在知识表示和获取方面存在严重不足,很难像人类那样进行句法消歧;
-
搜索空间。句法分析是一个极为复杂的任务,候选树个数随句子增多呈指数级增长,搜索空间巨大。因此,必须设计出合适的解码器,以确保能够在可以容忍的时间内搜索到模型定义最优解。
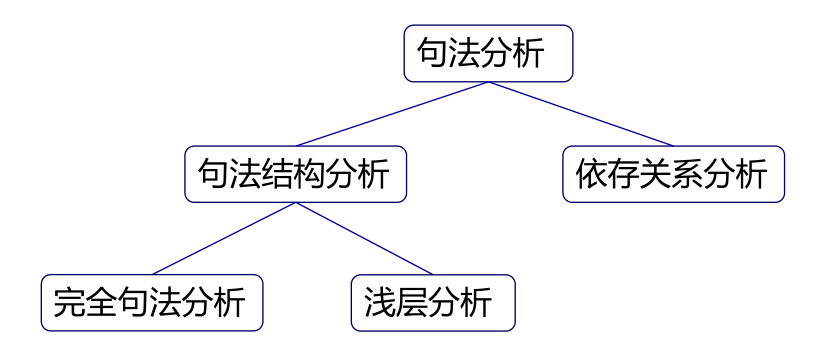
图 1 句法分析的结构
句法分析( Parsing )是从单词串得到句法结构的过程,而实现该过程的工具或程序被称为句法分析器( Parser )。句法分析的种类很多,如图1所示,这里我们根据其侧重目标将其分为完全句法分析和局部句法分析两种。两者的差别在于,完全句法分析以获取整个句子的句法结构为目的;而局部句法分析只关注于局部的一些成分,例如常用的依存句法分析就是一种局部分析方法。
句法分析中所用方法可以简单地分为基于规则的方法和基于统计的方法两大类。两种方法的特点有:
-
基于规则的方法:处理大规模真实文本时,存在语法规则覆盖有限、系统可迁移差等问题;
-
基于统计的方法:最典型的是 PCFG ,本质是一套面向候选树的评价方法,给正确的句法树赋予一个较高分值不合理的句法树赋予一个较低分支,从而借用分值进行消歧。
句法分析的数据集
统计学习方法多需要语料数据的支撑,统计句法分析也不例外。相较于分词或词性注,句法分析的数据集要复杂很多,其是一种树形的标注结构,因此又称树库。
目前的树库有:
-
英文:英文宾州树库,前身为 ATIS 和 WSJ 树库,具有较高的一致性和标注准确率;
-
中文:中文宾州树库、清华树库、台湾中研院树库等。
| 序号 | 标记代码 | 标记名称 |
|---|---|---|
| 1 | np | 名词短语 |
| 2 | tp | 时间短语 |
| 3 | sp | 空间短语 |
| 4 | vp | 动词短语 |
| 5 | ap | 形容词短语 |
| 6 | bp | 区别词短语 |
| 7 | dp | 副词短语 |
如上表所示,不同的树库有着不同的标记体系,使用时切忌使用一种树库的句法分析器,然后用其他树库的标记体系来解释。
句法分析的任务
语义分析通常以句法分析的输出结果作为输入以便获得更多的指示信息,根据句法结构的表示形式不同,最常见的句法分析任务可以分为以下三种:
-
句法结构分析,作用是识别出句子中的短语结构以及短语之间的层次句法关系;
-
依存关系分析,又称依存句法分析,简称依存分析,作用是识别句子中词汇与词汇之间的相互依存关系;
-
深层文法句法分析,即利用深层文法,例如词汇化树邻接文法、词汇功能文法、组合范畴文法等,对句子进行深层的句法以及语义分析。
句法分析的评测方法
句法分析评测的主要任务是评测句法分析器生成的树结构与手工标注的树结构之间的相似程度。其主要考虑两方面的性能:满意度和效率。其中满意度是指测试句法分析器是否适合或胜任某个特定的自然语言处理任务;而效率主要用于对比句法分析器的运行时间。
目前流行的是 PARSEVAL 评测体系,主要指标有准确率(分析正确的短语个数在句法分析结果中所占比例,即分析结果中与标准句法树相匹配的短语个数占分析结果中所有短语个数的比例)、召回率(分析得到的正确短语个数占标准分析树全部短语个数的比例)、交叉括号数(分析得到的某一短语覆盖范围与标准句法分析结果的某一短语的覆盖范围存在重叠而不存在包含关系,从而构成一个交叉括号)。
作答要求
根据相关知识,按照要求完成右侧选择题任务。作答完毕,通过点击“测评”,可以验证答案的正确性。
-
1、
句法分析的主要难点有:
A、分词
B、歧义
C、词性标注
D、搜索空间
BD
-
2、
下列哪个不属于 PARSEVAL 评测体系的主要指标
A、准确率
B、交叉括号数
C、符号数
D、召回率
C