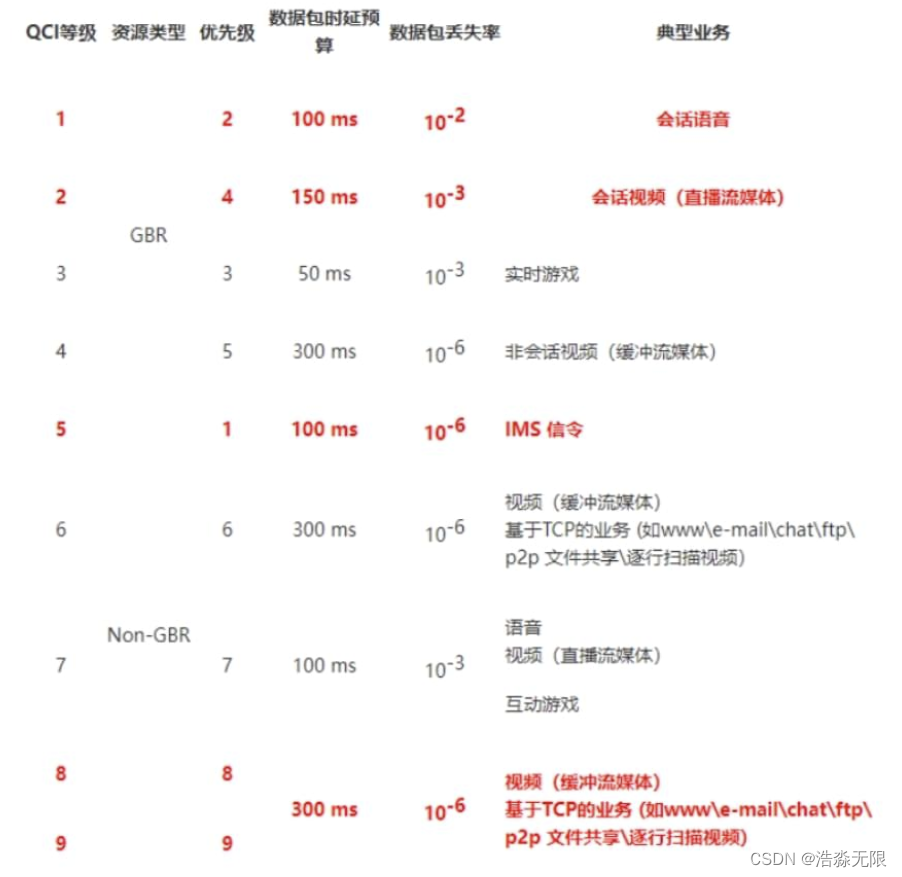
不同于string只实现一个最简单的版本,vector在此处我们要实现的是模版类,类模版的声明和定义分离非常不方便(会在链接时报错),所以我们都只在一个vector.h下去实现声明和定义。后续我们提及到的库里面实现的vector也是只有.h,没有.cpp
不过库中会将短的函数放在类里,如size、begin等(直接作为inline函数),大的如insert_aux就会放在类外面
目录
1.浅浅的阅读源码来学习容器vector
2.观察常见函数
2.1构造函数
2.2push_back
3. 实现自己的vector
迭代器失效 (finish找不到正确值)
insert
迭代器失效(it在外部无法使用,更新返回值来解决):
find
erase:
1.浅浅的阅读源码来学习容器vector
string和vector的底层都是顺序表(具有连续的物理结构):
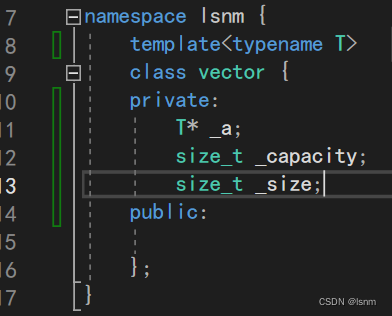
vector内部真的就和我们设计的string的逻辑(如上)完全一致吗?我们通过观察源码来学习。
源码有很多版本,比较常见的包括P.J版本和SGI版本,后者是Linux所用,并且是开源的,用于GCC编译器;前者是VS所用,不开源。
具体可参考:STL版本介绍:HP STL、SGI STL、STL Port、PJ STL、RW STL_stl port和sgi stl-CSDN博客
对于VS下的PJ版本:
VS自带编译器中的vector可在如下文件路径中找到:

或者在vector转到定义中后右击vector.h,并打开文件所在列表:

代码相对比较难且比较多(三千七百行),不适宜我们新手观看。
同理,其他的所有容器的PJ版本源码都可以通过此方法查看。
博主在网上下载了一个GCC的编译器使用的远古STL版本(SGI版本): ![]()
(有需要压缩包的可以在评论区留言)
这个版本相对简单,我们浅浅阅读一下vector:
该头文件又包了头文件,我们只返回文件目录找出最重要的两个头文件(最下面两个)
这也是阅读代码的技巧,不是所有的项目都需要从头到尾全部学习并理解代码,只挑重点学习即可。
目标是vector就直奔vector,不要等到什么都看懂再往下看。
开始阅读压缩包中的stl_vector.h:
前面的绿字是源码声明,表明开源是可以用于商业等用途的。
31~32 是一个条件编译,表示如果宏定义过这段就不再宏定义,避免多文件中重复宏定义。
34~38 是版本相关的问题,不用管。
40 开始切入正题,如果Alloc等内存池没有了解过可以先略过,知道他是用于提升效率的即可
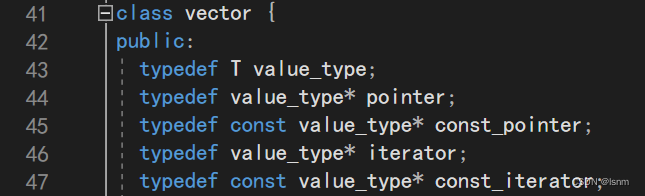
41开始的后面的一大堆typedef也略过,直接找成员变量和核心成员函数,并且标准的原码都有规范的命名,所以:
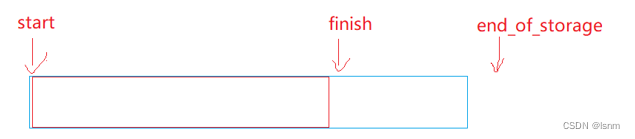
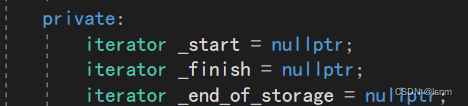
然后我们发现,成员变量是三个迭代器:start finish end_of_storage
再返回在一大堆typedef中找iterator的定义来阅读:
稍加总结:
由此可知,SGI版本下的vector的本质就是用原生指针实现的。



2.观察常见函数
2.1构造函数
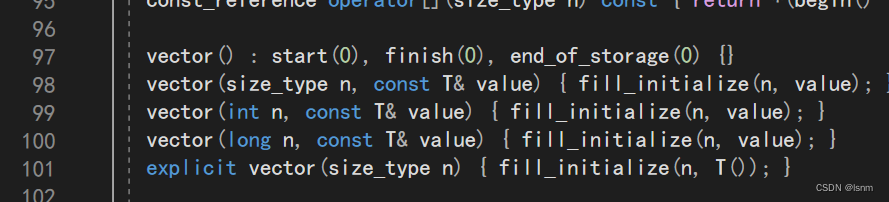
重点观察前两排
除了默认构造,都调用了一个initialize,头文件中有相关的头文件(第二张黑图的33行)。

2.2push_back
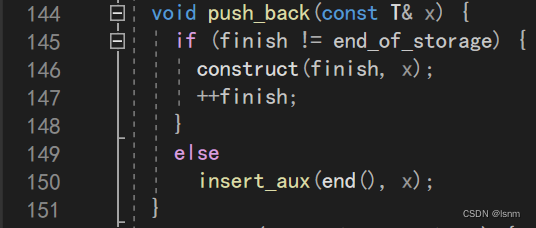
finish类似于size,end_of_storage类似于capacity(但是两者的实现都是迭代器):
我们大胆猜想,finish指向最后一个元素的下一个,end_of_storage指向已开空间的后一个位置(这样才能先在finish的位置加入x后面再++finish)
如果finish小于end_of_storage就直接在finish的位置加入一个x,如果finish已经等于end_of_storage了,那就必须扩容了,说明此时finish指向的空间已经不能再存储数据了,证明我们上面说到的猜想是成立的。
若需要扩容,则走声明定义相分离的insert_aux(该函数比较大,因此没有写在类里面):
虽然都在同一文件里,但还是将insert_aux的声明和定义分离。注意,就算在同一文件中,依然需要再写一次template<class T,class Alloc>
insert_aux能自动扩容:
由331行可知,从1个空间开始二倍扩容(如果原空间是0则给1字节大小,不是0开始二倍扩容)。
对于之前的push_back。没满就直接走323行的construct(此时在进行平移),满了就走insert_aux的else分支。
因此现在重点观察红框以内的代码
然后大胆猜测是使用内存池开辟了len个空间,也就是new T(len);
支线任务很重要,但是第一遍的时候目的是了解框架,走大逻辑,只看主线任务即可。
内存池就是支线任务,大概猜一猜就可以了。
我们无非是不使用内存池,效率低一点,new一个就可以了。
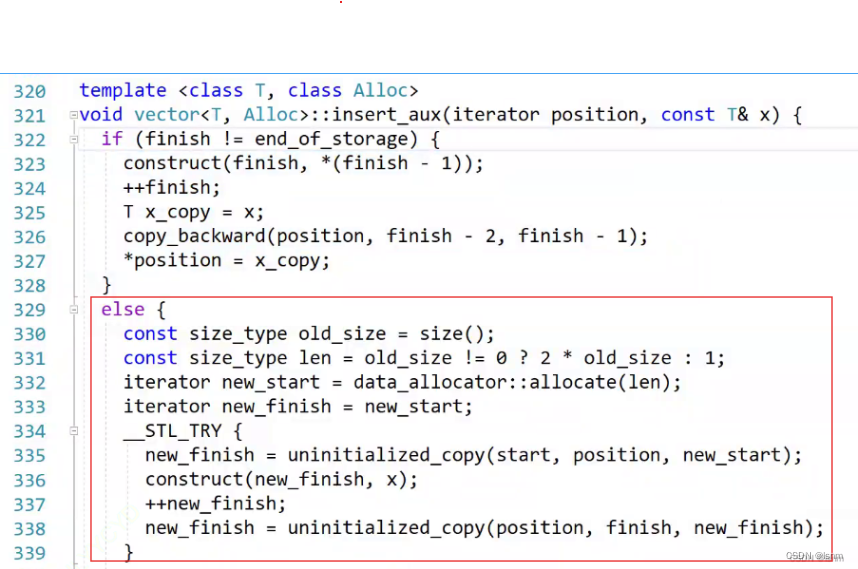
再往下读:
这个的逻辑应该就是先考前半部分,再拷x,最后拷后半部分。共拷贝三次
uninitialized_copy的作用就是拷贝,并且会返回新的末尾,前两个参数是要拷贝的范围,第三个参数是目标位置,返回值应该是拷贝完之后的下一个
关于construct,其定义在一个stl_construct.h的空间中(在压缩包中):
![]()
此处construct使用的就是对定位new的一个封装:

因为空间是内存池开出来的,需要显式调用构造函数,故使用定位new。
3. 实现自己的vector
由此,我们声明出自己的vector:
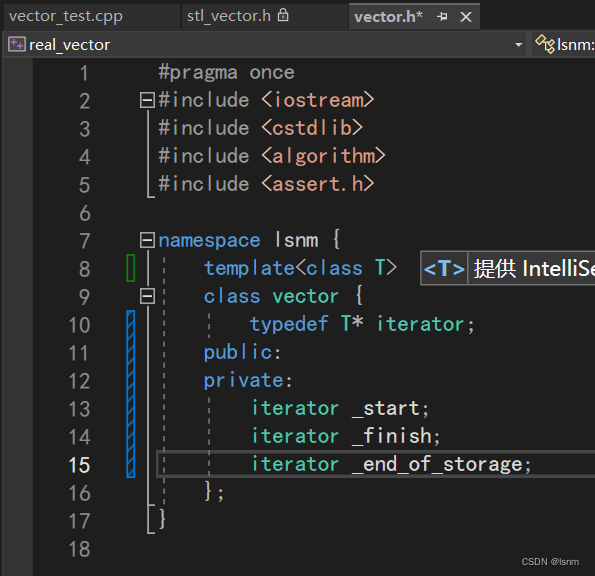
一些常见的接口:
inline size_t capacity() {return _end_of_storage - _start;
}
inline size_t size() {return _finish - _start;
}
inline iterator begin() {return _start;
}
inline iterator end() {return _finish;
}
T& operator[](size_t p) {assert(p < size());return *(_start + p);
}理应再实现push_back(因为我们从push_back了解了vector的大致结构),但是push_back需要使用reverse(我们不一定全部按照库中的实行),将这一个扩容的函数单独实现也是可行的。
实现reserve:
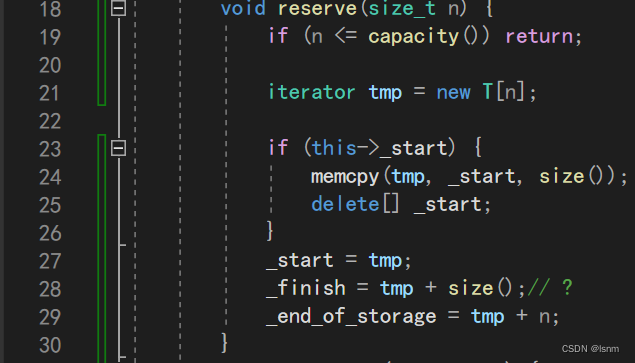
对于一个刚创建的变量,size函数一开始只会返回0,而n不出意外的话至少是1才会扩容,所以注定了在第一次扩容之后end_of_storage就是大于等于finish的。
if(this->_start)的目的是:如果start为空就不用拷贝了。
然后实现push_back:
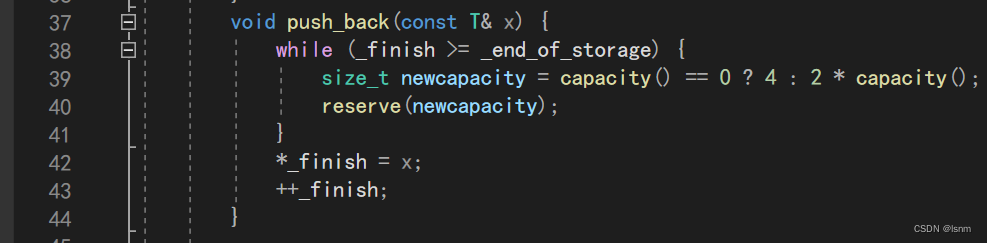
此处为什么可以直接解引用赋值 *_finish=x;
(压缩包中的SGI版本的finish是没有直接赋值的,他是通过调用construct实现的):

因为我们自己的空间是new出来的,new会根据元素类型(自动调用构造函数)初始化空间,而源码中使用的是内存池,只开出了空间而没有初始化,需要定位new再来显式调用一次构造函数。
此处不用像string那样根据len的长度决定扩容时空间加多少,因为除了char类型有“串”的概念,其他都没有此种概念,如“整形串”等。因此,pushback一定是只多了一个数据。
细心的读者可能已经发现,刚才的reverse处的_finish后面加了一个问号,这是一处bug,会造成:
迭代器失效 (finish找不到正确值)
测试函数:

如果要将类函数声明定义分离,则需要写在vector.h中,但是测试函数写在.h和.cpp中都是可以的,因为.h的本质是不会被编译的,而是放入.cpp之后被编译。
为了方便,我们直接写在.h中,不过刚开始会出现如下报错。

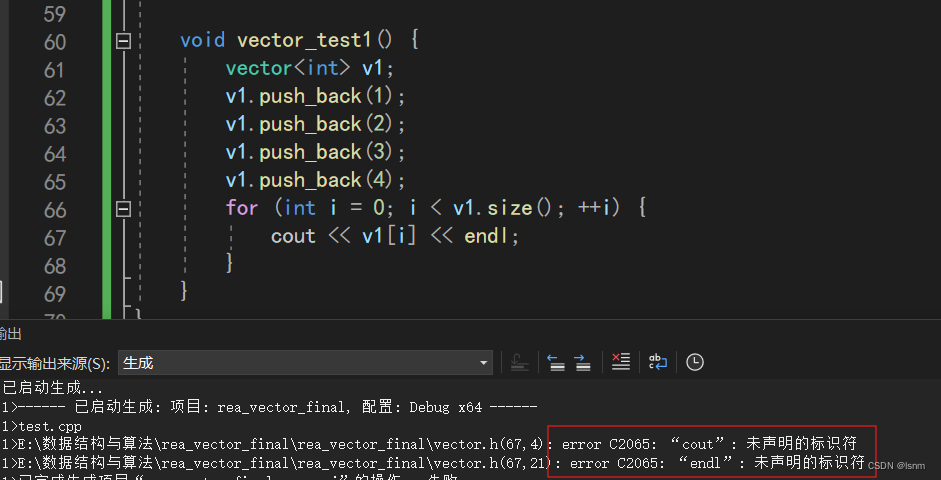
但是不用担心,因为所有的.h文件最后都会在.cpp中展开,这样一来,编译器在.cpp中向上查找时就能找到<iostream >(如下图)

在编译的章节我们提到过,头文件就是直接在.cpp文件中在相应的位置直接被展开
由于编译器向上查找的规则,如果写成:

vector.h向上找是没有展开std的,所以需要在展开std后再展开vector.h
还是崩溃了,_finish的值明显不正确,导致后面会对空指针解引用。
问题出在 size() , 因为size()是由finish和start计算出的(finish-start),而此时的_start已经被更新为新的tmp, 而旧的_finish是nullptr,所以会出错。
为什么旧的finish是nullptr(以及为什么没有实现构造函数):
这次的实现方式不同于之前,构造函数没有先开空间,而是等有需要的时候再扩容。
更改一下顺序即可:
不过要注意,将代码全部调整进n>capacity的分支中去。(怎么控制都可以)
或者,注意看源代码的同学会发现,源代码中使用变量oldsize记录了这个数据。
再加个_start控制拷贝
void reserve(size_t n) {if (n <= capacity()) return;size_t oldsize = size();iterator tmp = new T[n];if (this->_start) {//不为空就拷贝原数组中的内容memcpy(tmp, _start,sizeof(T)*size());delete[] _start;}_start = tmp;_finish = tmp + oldsize;_end_of_storage = tmp + n;
}源代码中:

很多检测越界等是在delete时进行(因为对同一个空间delete会报错),所以我们实现析构函数后再调试观察一次
~vector() {if (_start) {delete[]_start;_finish = _end_of_storage = nullptr;}
}再来看看vector的迭代器:
因为是连续的物理空间,所以直接用原生指针即可。
为了支持范围for,我们依然实现begin()和end()

就能实现范围for了:

pop_back:

insert
在指定的位置插入数据,其余数据向后挪。

先粗略实现一版(指定位置插入单个数据):
void insert(iterator it, const T& x) {assert(it >= begin() && it < end());if (_finish == _end_of_storage) {size_t newcapacity = capacity() == 0 ? 4 : 2 * capacity();reserve(newcapacity);}iterator end = _finish++;while (end != it) {*end = *(end - 1);--end;}*end = x;
}第一次测试 :
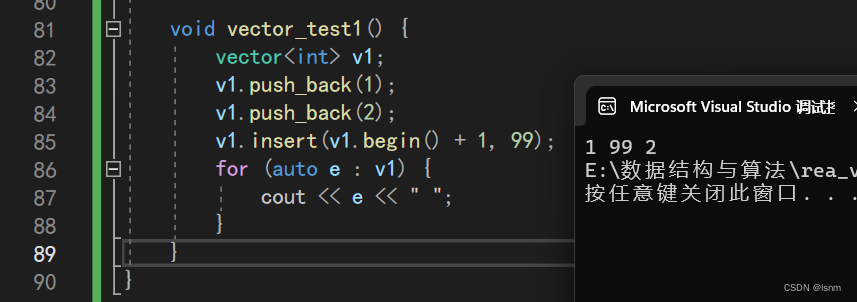
第二次测试:
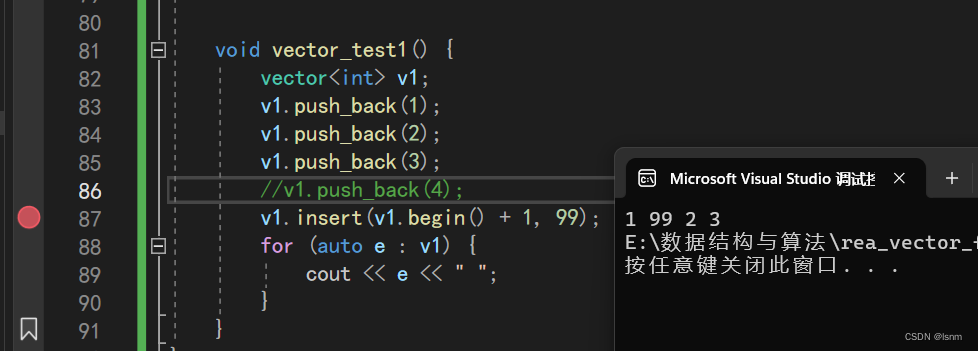
第三次测试:
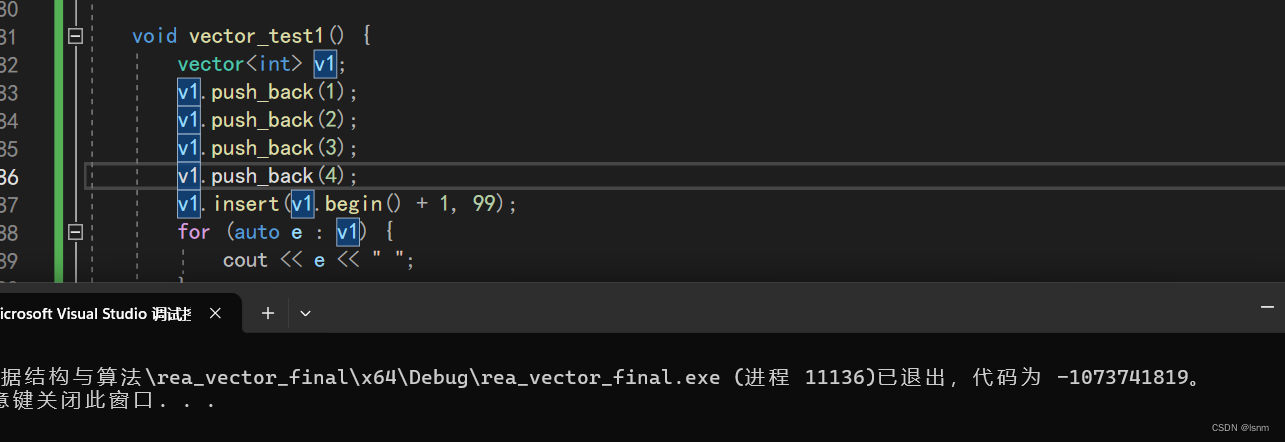
因为我们原来的第一次开空间就是四个,所以此处的insert会去扩容,而扩容时:
本来指向start finish两个位置的迭代器在扩容后都能改变到新的位置(原空间被释放)
然后it(也就是传进去的begin()+1)没有改变指向,it变成野指针,也就是迭代器失效
所以*it=x这一步是没有起作用的,vector此时扩了容但是没有东西进去,所以出现一个随机值。并且由于不满足end!=it,数据没有挪动。
记录一下it的位置,方便再赋值:
if (_finish == _end_of_storage) {size_t len = it - begin();size_t newcapacity = capacity() == 0 ? 4 : 2 * capacity();reserve(newcapacity);//在发生扩容后,it依然指向原来的数组位置,而finish和start等都已经指向新的位置了。it = begin() + len; }这样就没问题了:


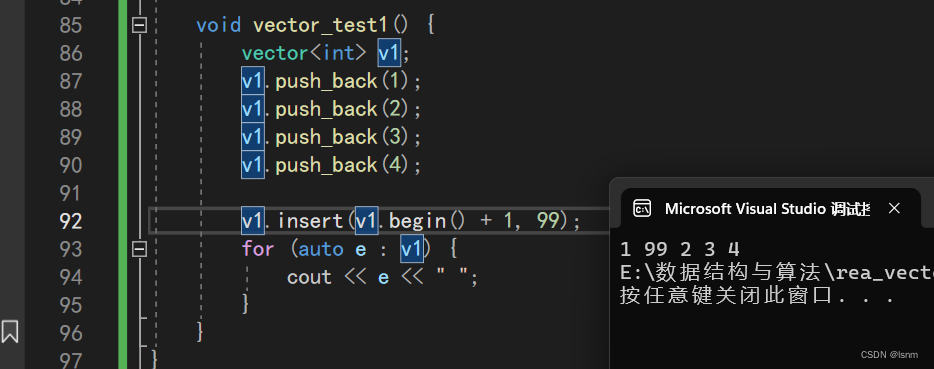
此时还是存在一个不会报错的迭代器失效:
迭代器失效(it在外部无法使用,更新返回值来解决):
外部作为实参的迭代器同样失效了(但是这次不会报错):

原因是,经过我们上一轮迭代器失效的修改,内部的pos已经指对了地方,但是由于是传值传参,所以it依然指不对地方
只要扩容,都会发生失效。
我们干脆认为不管发不发生扩容,都会失效(因为我们不清楚到底多久失效多久不失效)
一棍子打死即可,避免给自己埋坑。
结论:不要使用可能失效的迭代器。
为什么不加引用来解决![]() 呢?
呢?
加了引用就没法传这种:![]()
begin()返回的是一个拷贝,具有常性,传引用拷贝有权限的扩大问题。又不能将insert处的pos改为const iterator& pos,因为这样改的话,pos的值不能变,依然有失效。
不这样使用的目的就是让程序员们明白有迭代器失效这样一个环境,并且我们需要小心迭代器失效。
当然了,CPP肯定给出了解决方案:
不在参数处解决,在返回值处解决,相当于更新了一下失效的迭代器。
所以,以后在insert之后如果想访问pos,要谨慎,最好用Insert的返回值更新一下pos,否则时好(没有遇上扩容)时坏(遇上扩容),像一个定时炸弹一样不靠谱。
find
对于vector和list等,其查找函数都被归在算法库中(而非string那样在类中,因为string的查找比较特殊,如需要查找子串等,就单独实现了):

该函数实现在算法库:<algorithm.h>中
体现了复用的意义。这是一个函数模版 ,如果没有找到就返回Last(开区间)
所以这个find不止是适用于库中的vector或则list等,只要传适当的参数上去就行了。
传入一个左闭右开的区间,最后一个参数传一个想查找的数值。
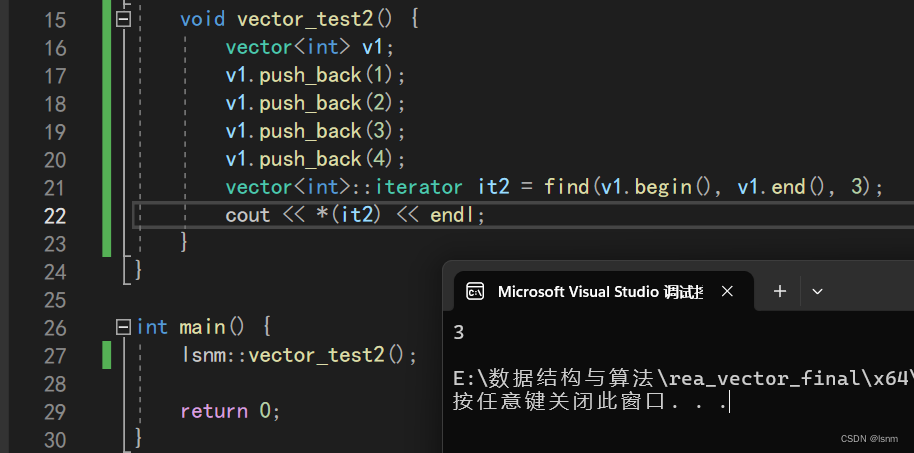
erase:
erase的迭代器失效问题比较复杂,我们先给出一个粗略版本。
void erase(iterator pos) {assert(pos >= _start && pos<_finish);while (pos + 1 < end()) {*(pos) = *(pos + 1);++pos;}--_finish;
}欲知后事如何,且听下回分解。