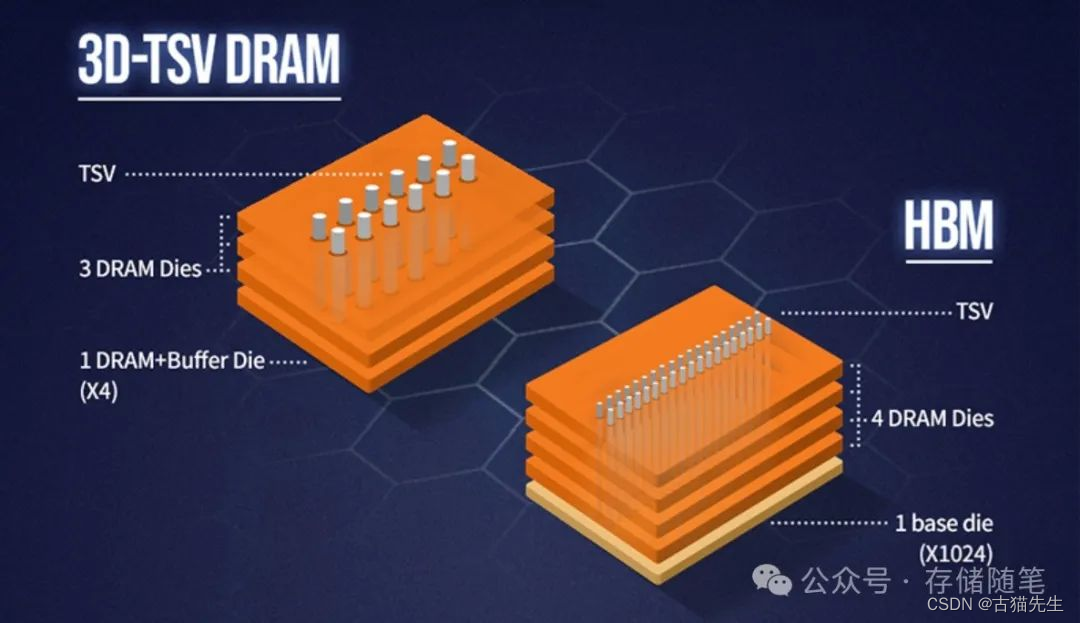
文章目录
- 文章前言
- 机器学习在GPT-5中的具体应用
- 模型训练与优化
- 机器翻译与跨语言交流:
- 情感分析与问答系统:
- 集成机器学习功能:
- 文本生成
- 语言理解
- 任务适应
- 机器学习对GPT-5性能的影响
- 存在的挑战及解决方案
- 技术细节与示例
文章前言

GPT-5是OpenAI公司开发的一种先进的自然语言处理模型,它是GPT(Generative Pre-trained Transformer)系列的最新成员。GPT-5代表了当前自然语言处理领域的最前沿技术,通过深度学习和机器学习技术,GPT-5能够在海量文本数据上进行预训练,学习并理解人类语言的复杂性和多样性。GPT-5拥有庞大的模型规模和超强的生成能力,能够生成连贯、流畅且富含信息的文本,广泛应用于文本生成、问答系统、机器翻译、文本摘要等自然语言处理任务中。GPT-5的出现不仅推动了人工智能技术的发展,也为各行各业带来了革命性的变革。
机器学习在GPT-5中发挥着至关重要的作用,为GPT-5赋予了强大的文本生成和语言理解能力。以下将详细解释机器学习在GPT-5中的应用、对性能的影响、存在的挑战及解决方案,并提供相关的技术细节和示例。
机器学习在GPT-5中的具体应用

模型训练与优化
- GPT-5采用了大规模的预训练数据,通过机器学习算法进行训练,使模型能够学习到人类语言的复杂性和多样性。
- GPT-5的模型规模预计将达到近百万亿参数的级别,远超GPT-4的10万亿参数,这得益于机器学习算法在处理大规模数据时的效率。
- GPT-5通过机器学习不断优化模型参数,使预测结果尽可能接近真实文本,从而提升模型的准确性和泛化能力。
示例伪代码:
# 假设我们有一个预训练模型GPT5Model和一个训练数据集train_data # 初始化GPT-5模型
gpt5_model = GPT5Model() # 定义损失函数和优化器
loss_function = ... # 具体的损失函数,如交叉熵损失
optimizer = ... # 具体的优化器,如Adam优化器 # 训练循环
for epoch in range(num_epochs): for batch in train_data: # 前向传播 outputs = gpt5_model(batch) # 计算损失 loss = loss_function(outputs, batch['targets']) # 反向传播和优化 loss.backward() optimizer.step() optimizer.zero_grad() # 保存训练好的模型
gpt5_model.save('gpt5_trained_model.pth')

机器翻译与跨语言交流:
- GPT-5具备强大的机器翻译能力,能够实现多种语言间的互译,为跨语言交流提供便利。
- 机器学习算法使得GPT-5在翻译过程中能够准确捕捉语言的语义和上下文信息,确保翻译结果的准确性和流畅性。
示例伪代码:
# 假设我们有一个加载好的GPT-5翻译模型gpt5_translator # 加载GPT-5翻译模型
gpt5_translator = load_translator('gpt5_translator_model.pth') # 输入待翻译的文本和源语言、目标语言
source_text = "你好,世界!"
source_lang = 'zh'
target_lang = 'en' # 使用GPT-5翻译模型进行翻译
translated_text = gpt5_translator.translate(source_text, source_lang, target_lang) # 打印翻译结果
print(translated_text)
情感分析与问答系统:
- GPT-5可以应用于情感分析任务,通过机器学习算法识别文本中的情感倾向和情绪表达。
- 在问答系统方面,GPT-5可以理解用户的问题或需求,并给出相应的回答或建议。这种能力同样依赖于机器学习算法对语言理解和处理的能力。
示例伪代码:
# 假设我们有一个加载好的GPT-5情感分析模型gpt5_sentiment_analyzer和一个问答模型gpt5_qa_model # 加载情感分析模型
gpt5_sentiment_analyzer = load_model('gpt5_sentiment_analyzer_model.pth') # 输入待分析的文本
text_to_analyze = "这部电影太棒了!" # 使用GPT-5情感分析模型进行分析
sentiment = gpt5_sentiment_analyzer.analyze_sentiment(text_to_analyze) # 打印情感分析结果
print(sentiment) # 输出可能是 "positive" 或其他情感标签 # 加载问答模型
gpt5_qa_model = load_model('gpt5_qa_model.pth') # 输入问题和上下文
question = "这部电影的导演是谁?"
context = "这部电影是由张艺谋执导的..." # 使用GPT-5问答模型回答问题
answer = gpt5_qa_model.answer_question(question, context) # 打印回答结果
print(answer)
集成机器学习功能:
- GPT-5集成了机器学习功能,使得AI能够从用户的反馈和数据中不断学习和改进,提供更好的服务。
- 用户可以给GPT-5提供正面或负面的评价,或者指定一些优化目标或约束条件,让GPT-5根据这些信息来调整自己的行为和输出。
文本生成
GPT-5通过机器学习技术,特别是深度学习中的自然语言处理(NLP)技术,能够生成高质量的文本内容。它可以根据输入的文本或主题,自动编写文章、新闻、小说等,具有与人类相似的写作风格和语言表达能力。
示例代码:
from transformers import GPT2LMHeadModel, GPT2Tokenizer
import torch # 加载模型和分词器
model_name = "gpt2-medium" # 假设我们使用GPT-2的medium版本作为示例
tokenizer = GPT2Tokenizer.from_pretrained(model_name)
model = GPT2LMHeadModel.from_pretrained(model_name) # 输入文本
input_text = "今天天气真好,"
input_ids = tokenizer.encode(input_text, return_tensors='pt') # 生成文本
generated = model.generate(input_ids, max_length=50, pad_token_id=tokenizer.eos_token_id) # 将生成的ID转换为文本
output_text = tokenizer.decode(generated[0], skip_special_tokens=True)
print(output_text)
语言理解
GPT-5还能够理解并解释自然语言文本的含义。它可以通过学习大量的文本数据,掌握语言的语法、语义和上下文信息,从而实现对文本内容的深入理解。
示例代码:
# 假设我们有一个预训练的GPT模型和一个分类头
# (注意:GPT本身不直接用于分类,但我们可以添加额外的层) # ...(加载模型和分词器的代码与上面相同)... # 假设的文本分类函数(这里只是一个示意,GPT本身不提供分类功能)
def classify_text(text, model, tokenizer, classifier_head): input_ids = tokenizer.encode(text, return_tensors='pt') with torch.no_grad(): gpt_output = model(input_ids)[0] # 获取GPT模型的最后一层输出 # 假设classifier_head是一个预训练的分类头模型 class_logits = classifier_head(gpt_output[:, 0, :]) # 取第一个token的输出进行分类 predicted_class = torch.argmax(class_logits, dim=-1).item() return predicted_class # 示例文本
text_to_classify = "我喜欢看电影"
predicted_class = classify_text(text_to_classify, model, tokenizer, classifier_head)
print(f"预测的类别是:{predicted_class}")
任务适应
GPT-5具备自适应学习能力,能够根据不同的任务需求调整自身的参数和模型结构。这使得GPT-5能够应用于各种自然语言处理任务,如问答系统、情感分析、机器翻译等。
示例代码:
from transformers import Trainer, TrainingArguments
from your_custom_dataset import YourCustomDataset # 假设你有一个自定义的数据集类 # ...(加载模型和分词器的代码与上面相同)... # 定义训练参数
training_args = TrainingArguments( output_dir='./results', # 输出目录 num_train_epochs=3, # 训练轮次 per_device_train_batch_size=16, # 批量大小 warmup_steps=500, # 学习率预热步数 weight_decay=0.01, # 权重衰减 logging_dir='./logs', # TensorBoard日志目录 logging_steps=10,
) # 加载数据集
train_dataset = YourCustomDataset(tokenizer=tokenizer, mode='train')
eval_dataset = YourCustomDataset(tokenizer=tokenizer, mode='eval') # 初始化Trainer
trainer = Trainer( model=model, # 模型 args=training_args, # 训练参数 train_dataset=train_dataset, # 训练数据集 eval_dataset=eval_dataset, # 评估数据集 # ... 其他可选参数 ...
) # 开始训练
trainer.train()
机器学习对GPT-5性能的影响
机器学习对GPT-5性能的影响是多方面的,从提升模型的准确性、泛化能力,到优化计算效率等方面都起到了关键作用。以下是详细的分析:
-
提升准确性:
- GPT-5通过大量的文本数据训练,能够学习到更多的语言知识和模式,从而提升其生成文本和理解语言的准确性。
- 斯坦福大学的研究发现,虽然使用AI生成的数据训练模型会导致性能下降,即所谓的“模型自噬障碍”(MAD),但这是因为模型未能得到“新鲜的数据”,即人类标注的数据。这强调了真实数据在提升模型准确性中的重要性。
- GPT-5的训练数据预计将达到近百万亿参数的级别,远超GPT-4的10万亿参数,这将使GPT-5能够处理更复杂的任务,生成更精确和流畅的文本。
-
提高泛化能力:
- GPT-5经过充分的机器学习训练,能够处理各种复杂的自然语言场景,具备较强的泛化能力。它的多模态能力将支持视频、音频等其他媒体形式的输入和输出,进一步扩大了其应用场景。GPT-5的更新还包括长期记忆和增强上下文意识,这将使模型能够处理需要长期记忆和连贯性的任务,如写长篇小说或进行深入对话,进一步提高了其泛化能力。
-
优化计算效率:
- GPT-5采用了先进的分布式计算技术和轻量级模型,这些技术能够在保持高性能的同时,降低对计算资源的需求,提高计算效率。尽管GPT-5的算力集群更庞大,训练成本更高,但通过这些优化技术,可以在一定程度上缓解成本问题。
-
数据依赖与解决方案:
- GPT-5的性能高度依赖于训练数据的质量和数量。为了解决这个问题,需要采用高质量、多样化的训练数据,并对数据进行预处理和过滤。
- 牛津、剑桥等机构的研究人员发现,如果在训练时大量使用AI内容,会引发模型崩溃。因此,为模型的训练准备由人类生产的真实数据变得尤为重要。
-
挑战与未来方向:
- 数据安全和隐私问题是GPT-5面临的重要挑战之一。由于GPT-5需要大量的数据进行训练和优化,因此确保数据的安全性和隐私性至关重要。
- 偏见和误导问题也是GPT-5需要解决的问题。GPT-5生成的内容受训练数据的影响,如果这些数据中存在偏见或误导,那么生成的内容也可能存在类似问题。
- 未来的研究将探索如何更好地利用机器学习技术来提升GPT-5的性能,并解决上述挑战。例如,通过改进数据预处理和过滤技术来提高数据质量,或者通过引入新的算法和技术来减少偏见和误导问题。
存在的挑战及解决方案
数据依赖:GPT-5的性能高度依赖于训练数据的质量和数量。如果训练数据存在偏见或误导信息,将会影响GPT-5生成文本的质量。为了解决这个问题,需要采用高质量、多样化的训练数据,并对数据进行预处理和过滤。
计算资源:GPT-5的训练和推理过程需要大量的计算资源。为了解决这个问题,可以采用分布式计算、并行计算等技术手段,提高模型的训练和推理速度。
版权问题:GPT-5生成的文本可能存在版权问题。为了避免这种情况的发生,需要在使用GPT-5时遵守相关的法律法规和伦理标准,确保生成的内容不侵犯他人的知识产权。
技术细节与示例
GPT-5采用了Transformer架构作为其基础模型,该架构由多个自注意力机制和全连接层组成。通过堆叠多个Transformer层,GPT-5能够学习到更深层次的语言特征。以下是一个简化的GPT-5模型架构示意图(注意,由于GPT-5的复杂性,这里仅展示一个概念性的示例):
Input -> [ Embedding Layer ] -> [ Transformer Layer 1 ] -> ... -> [ Transformer Layer N ] -> [ Output Layer ]
其中,Embedding Layer用于将输入文本转换为模型可以处理的向量表示;Transformer Layer是模型的核心部分,负责学习文本中的语言特征;Output Layer则根据任务需求输出相应的结果。
由于GPT-5的复杂性和专业性,直接提供代码示例可能不太合适。但读者可以通过查阅相关的深度学习框架(如TensorFlow、PyTorch等)和NLP库(如Hugging Face的Transformers库)来了解如何构建和训练类似的模型。这些框架和库提供了丰富的API和工具,可以帮助读者更好地理解机器学习在GPT-5中的应用和实现过程。
–

![[数据集][目标检测]电力场景下电柜箱门把手检测数据集VOC+YOLO格式1167张1类别](https://img-blog.csdnimg.cn/direct/885fddbf0d7d4e6aa6cdb24587d695b9.png)






![[OtterCTF 2018]Graphic‘s For The Weak](https://img-blog.csdnimg.cn/img_convert/c0a13197becf2dd5b17b407afdd28634.png)