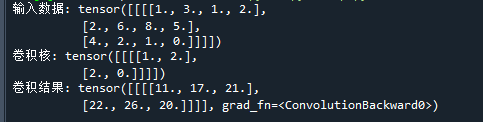
pip下载 MediaPipe
pip install mediapipe -i

手部特征点模型包包含一个手掌检测模型和一个手部特征点检测模型。手掌检测模型在输入图片中定位手部,手部特征点检测模型可识别手掌检测模型定义的被剪裁手掌图片上的特定手部特征点。
由于运行手掌检测模型非常耗时,因此在视频或直播跑步模式下,手部特征点会在一帧中使用手部特征点模型定义的边界框,以便为后续帧定位手部区域。仅当手部特征点模型不再识别出手部的存在或未能跟踪画面中的手部时,手部特征点才会重新触发手掌检测模型。这样可以减少手动标志器触发手掌检测模型的次数。
姿态检测
import cv2
import mediapipe as mp
# 获取pose模块
mp_pose = mp.solutions.pose
# 绘图工具模块
mp_draw = mp.solutions.drawing_utils
a=mp_draw.DrawingSpec((255,0,0),-1,2)#绘制节点圆圈的大小颜色
b=mp_draw.DrawingSpec((0,0,255),4)#绘制线条的粗细和颜色
# 获取Pose对象
pose = mp_pose.Pose(static_image_mode=True)cv2.namedWindow("img", cv2.WINDOW_NORMAL)
cv2.resizeWindow("img", (800, 600))
img = cv2.imread("img.png")img_rgb = cv2.cvtColor(img, cv2.COLOR_BGR2RGB)
# 使用Pose对象处理图像,得到姿态的关键点
results = pose.process(img_rgb)
pose_landmarks = results.pose_landmarks
if pose_landmarks:mp_draw.draw_landmarks(img, pose_landmarks, mp_pose.POSE_CONNECTIONS,a,b)
cv2.imshow("img", img)
cv2.waitKey(0)
cv2.destroyAllWindows()效果图:

mp_draw.DrawingSpec() 用于定义绘图的样式,包括颜色、线条粗细、圆形半径等。以下是 mp_draw.DrawingSpec 的一些常用参数:
-
color:指定绘图的颜色,可以是一个整数表示的 BGR 颜色值,也可以是一个包含三个元素的列表或元组表示的 RGB 颜色值。 -
thickness:指定绘图的线条粗细,默认为 1。 -
circle_radius:指定绘图中圆形的半径,默认为 1。
mp_pose.Pose()的参数用于配置人体姿态估计的行为,以下是一些常用参数:
-
static_image_mode:表示输入的是静态图像还是连续帧视频。如果设置为True,则表示输入为静态图像;如果设置为False,则表示输入为连续帧视频。 -
model_complexity:表示人体姿态估计模型的复杂度。可以选择0、1或2,其中0表示速度最快但精度最低,1表示速度和精度平衡,2表示速度最慢但精度最高。 -
smooth_landmarks:表示是否平滑关键点。如果设置为True,则会对关键点进行平滑处理,使姿态估计更加流畅。 -
enable_segmentation:表示是否对人体进行抠图。如果设置为True,则会在输出中包含人体的分割掩码。 -
min_detection_confidence:表示检测置信度的阈值。只有当检测到的人体姿态的置信度高于该阈值时,才会被认为是有效的姿态估计。 -
min_tracking_confidence:表示跟踪置信度的阈值。在连续帧视频中,只有当跟踪到的人体姿态的置信度高于该阈值时,才会继续使用该姿态估计。
mp_draw.draw_landmarks()函数用于在图像上绘制手部关键点和连接,其参数如下:
-
image:要绘制关键点和连接的图像。 -
landmark_list:检测到的手部关键点坐标。 -
connections:要绘制的连接线,需要指定哪些关键点之间进行连接。 -
landmark_drawing_spec:关键点的绘制样式,包括颜色、粗细等。 -
connection_drawing_spec:连接线的绘制样式,包括颜色、粗细等。
姿态检测(3D)
import cv2
import mediapipe as mp
# 获取pose模块
mp_pose = mp.solutions.pose
# 绘图工具模块
mp_draw = mp.solutions.drawing_utils
# 获取Pose对象
pose = mp_pose.Pose(static_image_mode=True)img = cv2.imread("yj.jpg")img_rgb = cv2.cvtColor(img, cv2.COLOR_BGR2RGB)
# 使用Pose对象处理图像,得到姿态的关键点
results = pose.process(img_rgb)
pose_landmarks = results.pose_world_landmarks
#pose_landmarks是一个包含多个关键点的数组或数据结构,每个关键点可能包含坐标信息(如 x、y、z 坐标)以及其他相关属性。这些关键点可以表示人体的关节、部位或其他特征点。
if pose_landmarks:mp_draw.plot_landmarks(pose_landmarks, mp_pose.POSE_CONNECTIONS)cv2.destroyAllWindows()效果图:
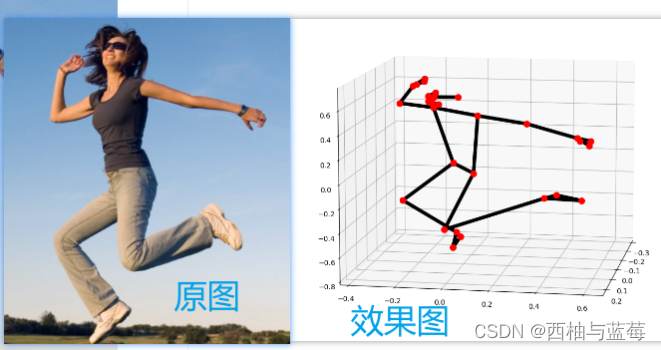
mp_draw.plot_landmarks()函数用于在图像或视频帧上绘制姿态估计的关键点和连接。以下是该函数的参数说明:
-
landmarks:要绘制的关键点列表。 -
connections:要绘制的连接列表,指定哪些关键点之间进行连接。 -
landmark_drawing_spec:关键点的绘制样式,包括颜色、大小等。 -
connection_drawing_spec:连接线的绘制样式,包括颜色、粗细等。
人体抠图换背景
import cv2
import mediapipe as mp
import numpy as np# 获取pose模块
mp_pose=mp.solutions.pose
# 绘图工具模块
mp_draw=mp.solutions.drawing_utils
# 获取Pose对象
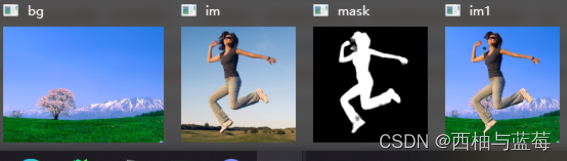
pose=mp_pose.Pose(static_image_mode=True, enable_segmentation=True)# 获取背景,原图
bg=cv2.imread('bg.png')
im=cv2.imread('img.png')
cv2.imshow('bg',bg)
cv2.imshow('im',im)
# 将背景的size设置和原图size一致
w,h,c=im.shape
bg=cv2.resize(bg,(h,w))# 使用Pose对象处理图像,得到姿态的关键点
im_rgb=cv2.cvtColor(im,cv2.COLOR_BGR2RGB)
result=pose.process(im_rgb)
# cv2.imshow('result',result)# segmentation_mask中的数据值是0.0-1.0,值越大,表示越接近是人
mask=result.segmentation_mask
cv2.imshow('mask',mask)#
# 将单通道的mask变成三通道
mask=np.stack((mask,mask,mask),-1)
# 大于0.5的才是人
mask=mask>0.5
img1=np.where(mask,im,bg)
cv2.imshow('im1',img1)cv2.waitKey(0)
cv2.destroyAllWindows()效果嘎嘎棒
pose.process(img_rgb)返回值的属性
-
pose_landmarks:这是一个包含人体姿态关键点的数组,每个关键点都有一个对应的坐标。这些关键点可以用于表示人体的关节位置,例如头部、肩膀、手臂、腿部等。通过分析这些关键点的位置和运动,可以实现人体姿态的识别、动作捕捉等功能。 -
pose_world_landmarks:与pose_landmarks类似,pose_world_landmarks也是一个关键点数组。不同的是,pose_world_landmarks中的关键点坐标是在真实世界坐标系中的位置,而不是图像坐标系中的位置。这意味着pose_world_landmarks可以提供更准确的人体姿态信息,适用于需要与真实世界进行交互的应用场景。 -
segmentation_mask:segmentation_mask是姿态跟踪结果中的一个数组,它的大小与跟踪的图像相同。每个像素的值在0.0到1.0之间,其中较暗的值表示背景,较亮的值表示被跟踪的身体。通过分析segmentation_mask,可以将人体从背景中分离出来,实现人体的分割和提取。