目录
引言
为什么不推荐使用 "+"
示例代码
更高效的替代方法
使用 join 方法
示例代码
使用格式化字符串(f-strings)
示例代码

引言
大家好,在 Python 编程中,我们常常需要对字符串进行拼接。你可能会自然地想到用 + 操作符将字符串连接起来,毕竟这看起来简单明了。
在 Python 中,字符串是不可变的数据类型,这意味着一旦字符串被创建,它就不能被修改。因此,当你尝试通过使用 + 来连接字符串时,实际上 Python 会创建新的字符串对象,并将旧字符串的内容复制到新字符串中,然后添加新内容。这个过程在处理大量数据或在循环中进行时,会导致性能问题。

为什么不推荐使用 "+"
在 Python 中,字符串是不可变的对象。这意味着每次使用 + 拼接字符串时,都会创建一个新的字符串对象,而不是在原有的字符串上进行修改。这会导致以下几个问题:
-
1. 性能问题:每次拼接都会创建一个新的字符串对象,这在大量拼接操作时,会带来性能上的损失。
-
2. 内存浪费:频繁的字符串拼接会导致大量的临时字符串对象的创建,增加内存的开销。
让我们通过一个例子来具体看看这个问题。
示例代码
def concatenate_with_plus(n):result = ""for i in range(n):result += str(i)return resultimport time
start_time = time.time()
concatenate_with_plus(100000)
end_time = time.time()
print(f"Using '+': {end_time - start_time} seconds")在这个例子中,我们通过 + 拼接字符串,测试其性能。试着运行这个代码,你会发现当 n 值很大时,运行时间明显增加。

更高效的替代方法
那么,有哪些更高效的字符串拼接方法呢?我们介绍以下几种:
-
1. 使用
join方法 -
2. 使用格式化字符串(f-strings)
-
3. 使用字符串模板
使用 join 方法
join 方法通过一个字符串作为分隔符,将一个可迭代对象中的元素连接成一个新的字符串。这种方法在拼接大量字符串时效率更高,因为它避免了频繁创建新的字符串对象。
示例代码
import time
def concatenate_with_join(n):result = ''.join(str(i) for i in range(n))return resultstart_time = time.time()
concatenate_with_join(100000)
end_time = time.time()
print(f"Using 'join': {end_time - start_time} seconds")
使用格式化字符串(f-strings)
Python 3.6 引入了格式化字符串(f-strings),它不仅使代码更简洁,而且在某些情况下也能提高性能。
示例代码
def concatenate_with_fstrings(n):result = ''.join(f'{i}' for i in range(n))return resultstart_time = time.time()
concatenate_with_fstrings(100000)
end_time = time.time()
print(f"Using f-strings: {end_time - start_time} seconds")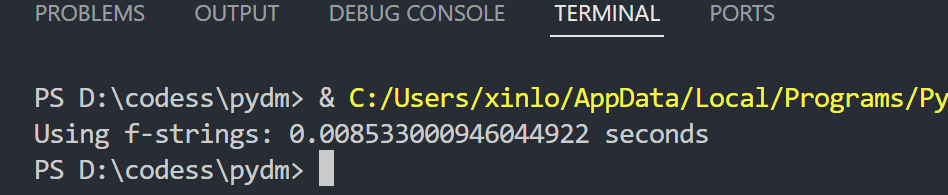
通过对比,我们可以看到 join 方法在大量字符串拼接时性能最优,而 f-strings 在代码简洁性和可读性上也有很大的优势。虽然在小规模拼接时,+ 操作符的性能差异不明显,但在处理大数据量时,选择高效的拼接方法尤为重要。

| 用Nuitka打包 Python,效果竟如此惊人!_为什么不能将nutika编译好的三方库直接使用-CSDN博客文章浏览阅读937次,点赞23次,收藏18次。Nuitka 是一个 Python 到 C 的编译器,它会将 Python 代码转换为等效的 C 代码,然后使用标准的 C 编译器(如 GCC)将其编译为二进制可执行文件。这一过程不仅提高了程序的执行效率,还能通过编译后的二进制文件保护代码的隐私。_为什么不能将nutika编译好的三方库直接使用 |
| Python 库PySpark,一个超级强大的数据处理引擎_python中pyspark库能运行吗-CSDN博客 |
| 用Python比较对象==与is,你还在用==?out啦,来看这个!-CSDN博客 |




![拓扑排序[讲课留档]](https://img-blog.csdnimg.cn/direct/0b8cfc92ecea4441b8020b2bd6d8c1cb.png)